
1 Databases
Om Power BI te begrijpen is een basiskennis van databases of databanken vereist. Een database kan worden gedefinieerd als een gestructureerde verzameling van gegevens.
Databasesoftware bestaat in alle soorten en maten. Sommige oplossingen, zoals Microsoft Dataverse, zijn bedoeld voor kleinschalig tot middelgroot gebruik binnen het Microsoft Power Platform. Andere systemen richten zich op complexe en bedrijfskritische toepassingen. Het geheel van programma’s dat bestemd is voor het beheer van een databank wordt het database management system of DBMS genoemd.
Niet alleen qua doelgroep, maar ook qua onderliggende architectuur kent de term ‘databank’ verschillende invullingen. Een bekende categorie binnen databanksystemen is de relationele databank, waarbij gegevens zo worden gedefinieerd dat ze op diverse manieren kunnen worden gereorganiseerd en opgevraagd. Alternatieven voor het relationele model zijn onder meer het objectgeoriënteerde, het hiërarchische en het netwerkmodel1
Een relationele databank maakt gebruik van SQL (Structured Query Language) als standaardtaal om gegevens te bevragen en aan te passen.2
2 Relationele database
Vroeger werden gegevens opgeslagen in ‘platte bestanden’, in het Engels flat files. Dat zijn tekstbestanden waarin gegevens gescheiden door komma’s of tabs zijn opgenomen (CSV/TXT). Met behulp van een programma (bijvoorbeeld MS Excel) kunnen die gegevens uit het bestand worden gelezen. Het programma herkent de komma’s of tabs (scheidingstekens) en kan zo gegevens uit het bestand selecteren.
Figuur 1: CSV-bestand

In een relationele database worden gegevens geordend in tabellen. Een tabel bestaat uit records (~ rijen) en velden (~ kolommen):
1 Zie begrippenlijst.
2 Zie begrippenlijst.
Figuur 2: tabel

Het ontwerp van de database is onafhankelijk van het databasesysteem, zolang je een relationeel databasesysteem (RDBMS) gebruikt.
Om relationele databanken te ontwerpen gebruiken we vaak ER-diagrammen (Entity Relationship Diagrams). Een ERD is een soort stroomdiagram dat illustreert hoe tabellen binnen een systeem met elkaar verbonden zijn (wat-is-een-entity-relationship-diagram, 2020).
Een ERD bestaat uit entiteiten, attributen en relaties:
• Entiteit (~ tabel): een entiteit is een object dat bestaat en onderscheidbaar is van andere objecten. Voorbeelden hiervan zijn: klanten, contactmomenten en categorieën.
• Attribuut (~ veld): een entiteit wordt voorgesteld door een verzameling attributen. Mogelijke attributen voor de entiteit ‘klant’ zijn bijvoorbeeld klant_ID, bedrijf en straat.
• Relatie: een relatie is een verband tussen verschillende entiteiten. Men kan bijvoorbeeld een relatie definiëren die de klant ‘Gramalla S.L.’ associeert met het contactmoment met ID ‘33’ . Deze relatie specificeert dat er een contactmoment geweest is met de klant ‘Gramalla S.L.’.
Figuur 3: voorbeeld ERD (dit voorbeeld wordt verder uitgewerkt in ‘Ontwerp van een relationele database’)

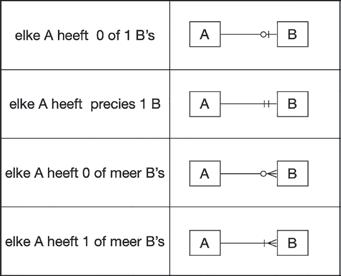
We kunnen verschillende ‘soorten relaties’ onderscheiden. We noemen dit de kardinaliteit. De kardinaliteit van de relatie beschrijft het aantal rijen in een tabel dat kan relateren met het aantal rijen in een andere tabel. Bijvoorbeeld: een klant kan veel contactmomenten hebben, maar een contactmoment kan bij maximaal één klant behoren. Kardinaliteit wordt meestal uitgedrukt als volgt:
• één op één (1:1)
Voorbeeld: elke werknemer heeft één bedrijfswagen.
• één op veel (1:*) of omgekeerd (*:1)
Voorbeeld: één klant kan meerdere contactmomenten hebben, maar een contactmoment is altijd gekoppeld aan één klant.
• veel op veel (*:*)
Voorbeeld: de tabel Orders bevat orders die zijn geplaatst door meerdere klanten (die vind je in de tabel Klanten), en een klant kan meerdere orders plaatsen. In dit geval moeten we werken met een ‘tussentabel’.
De kardinaliteit wordt in een ERD als volgt voorgesteld (logisch-model, 2019):
Figuur 4: notatie kardinaliteit
2.1 Databasenormalisatie
Normalisatie is het proces waarbij de gegevens in een database worden geordend. Concreet betekent dit tabellen maken en relaties tussen die tabellen leggen op basis van een aantal regels
Elke regel wordt een normaalvorm genoemd. Als aan de eerste regel wordt voldaan, bevindt de database zich in de eerste normaalvorm. Als aan de drie regels wordt voldaan, bevindt de database zich in de derde normaalvorm. Hoe hoger de normaalvorm, hoe meer eisen er gesteld worden aan het ontwerp. De vijfde normaalvorm is de hoogste. Wanneer aan geen van de regels voldaan is, wordt dat aangeduid met 0NF. In praktijk betekent dit dat de database niet goed ontworpen is en vaak beperkt bruikbaar.
De meeste toepassingen gebruiken databases die zijn genormaliseerd tot de eerste, tweede of derde normaalvorm.
Eerste normaalvorm (1NF)
De regels van de eerste normaalvorm zijn:
• Elk attribuut bevat slechts één waarde. Dus niet: ‘8000 Brugge’ in één veld, maar aparte velden voor postcode en gemeente.
• Geen enkel attribuut wordt herhaald.
Kortom, als alle data in een of meer tabellen zijn ondergebracht, is er al sprake van de eerste normaalvorm.
Tweede normaalvorm (2NF)
De regels van de tweede normaalvorm zijn:
• De database voldoet aan de regels van de eerste normaalvorm.
• Als bepaalde gegevens zich herhalen of bij meerdere records horen (bv. meerdere producten bij één bestelling), verplaats je die naar een aparte tabel en leg je een relatie.
Derde normaalvorm (3NF)
De regels van de derde normaalvorm zijn:
• De database voldoet aan de regels van de tweede normaalvorm.
• Informatie die afhankelijk is van andere gegevens, maar niet van de unieke ID (sleutel), moet ook in een aparte tabel. Bijvoorbeeld: als je in een klantentabel zowel de klant als de naam van de verkoper opslaat, en elke verkoper meerdere klanten heeft, dan hoort de verkoper beter in een eigen tabel. Zo vermijd je dat je bij elke klant opnieuw dezelfde informatie over de verkoper moet invullen.
2.2 Ontwerp van een relationele database
Situatieschets
Tex-Mex bv wil een database om contactmomenten met de klant op te slaan. Klantgegevens zijn bijvoorbeeld voornaam, naam en straat. Elke keer dat het bedrijf en een klant met elkaar communiceren, wordt beschouwd als een contactmoment.
We starten met het maken van een tabel. We houden daarbij rekening met de normalisatieregels en maken een attribuut voor iedere waarde (1NF).
Figuur 5: database contactmomenten
Onze database voldoet aan de eerste normaalvorm. Maar het adres van de klant moet bij ieder contactmoment weer ingevoerd worden, waardoor één adres wellicht honderden keren in de database voorkomt. De structuur kan dus beter.
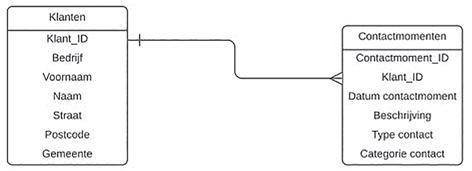
Om te voorkomen dat de klantgegevens meerdere keren ingevoerd of gewijzigd moeten worden, plaatsen we deze in een aparte tabel (2NF). In de tabel met de contactmomenten komt een verwijzing naar de klant (Klant_ID).
Figuur 6: tweede normaalvorm

Het ER-diagram ziet er als volgt uit:
Figuur 7: ER-diagram
Iedere entiteit heeft een sleutel of een uniek record om de records te identificeren en de gegevens in de verschillende tabellen aan elkaar te koppelen:
• Tabel Klanten: Klant_ID (primaire sleutel)
• Tabel Contactmomenten: Contactmoment_ID (primaire sleutel)
• Tabel Contactmomenten: Klant_ID (vreemde sleutel)
Primaire en vreemde sleutels
Een primaire sleutel is een attribuut dat aan de volgende voorwaarden voldoet:
• uniek,
• niet leeg,
• legt relaties tussen tabellen.
Een vreemde sleutel of een verwijzende sleutel is een attribuut in een tabel dat dient als verwijzing naar een andere tabel. Een vreemde sleutel bevat dus uitsluitend waarden van de primaire sleutel van die andere tabel.
In het voorbeeld hebben we een één-op-veelrelatie gelegd tussen de entiteit Klanten en de entiteit Contactmomenten op basis van het gemeenschappelijke attribuut Klant_ID.
Onze database voldoet tot nu toe aan de tweede normaalvorm
We gaan een stap verder en kijken naar de derde normaalvorm. Bij de tweede normaalvorm gaan we er nog van uit dat de gemeente en de postcode attributen zijn van de klant. In de derde normaalvorm worden de postcode en de gemeente als aparte entiteiten gezien.
Figuur 8: derde normaalvorm

Ook voor de categorie waartoe het contact behoort en het type contact maken we nieuwe entiteiten.
Figuur 9: derde normaalvorm

Het ERD in de derde normaalvorm ziet er als volgt uit:
Figuur 10: ERD
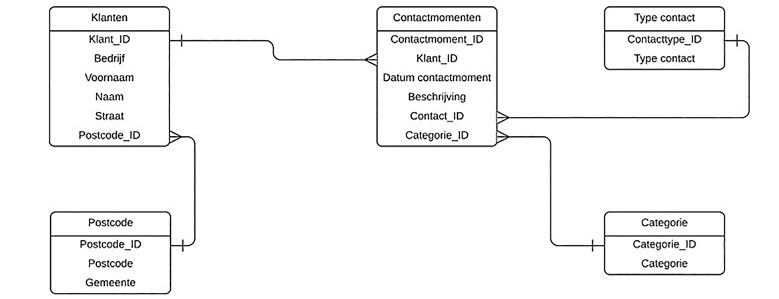
Onze database voldoet nu aan de derde normaalvorm. In het voorbeeld is geen enkel niet-sleutelattribuut nog afhankelijk van een ander niet-sleutelattribuut. Voordeel: de data zijn niet meer redundant (overtollig) opgeslagen en de structuur van de data is meteen duidelijk, ook wanneer men de data zelf nog niet kent.
3 Relationeel model in Power BI
Met de Modelweergave (Model View) in Power BI kun je heel complexe gegevenssets met meer dan honderd tabellen bekijken en gebruiken.
Gegevens modelleren is de derde stap in de data-ijsberg:

Dit hoofdstuk bouwt verder op het hoofdstuk ‘Gegevens opschonen en transformeren met Power Query Editor’. Je kunt dus verder werken in het bestand H4_Gegevensanalyse_Tex-Mex.pbix. Als je dat hoofdstuk nog niet hebt afgewerkt, vind je het bestand ook in de lijst met opgavebestanden onder de naam H5_Gegevensanalyse_Tex-Mex.pbix.
1 Open het bestand H5_Gegevensanalyse_Tex-Mex_opgave.pbix in Power BI Desktop (of werk verder in je eigen oplossing).
2 Klik in het linkerdeelvenster op het pictogram Model view. In de modelweergave worden alle tabellen, kolommen en relaties in je model weergegeven.
Je herkent onmiddellijk een ER-diagram!
Figuur 11: modelweergave

a Het lint in de modelweergave bestaat uit drie tabbladen: File (Bestand), Home en Help.
b In het linkerdeelvenster kun je schakelen tussen de Report View (Rapportweergave), de Table View (Tabelweergave), de Model View (Modelweergave) en DAX Query View Dat doe je door de pictogrammen te selecteren.
c In het middelste deelvenster kun je de relaties tussen de verschillende tabellen zien.
d In het deelvenster Properties (Eigenschappen) kun je algemene eigenschappen van één of meerdere tabellen instellen. Je kunt meerdere tabellen tegelijk selecteren met de CTRL-toets.
e In het deelvenster Data kun je mappen aanmaken om complexe modellen beter leesbaar te maken.
De deelvensters Properties en Data kunnen dichtgeklapt worden (>).
f Je kunt extra tabbladen toevoegen met een subset van de tabellen die je model bevat.
g Met de schuifregelaar kun je op het middelste deelvenster in- of uitzoomen.
3.1 Autodetectie tijdens het laden
Tijdens het laden van de gegevens heeft Power BI automatisch relaties tussen de tabellen gedetecteerd (functie Autodetect). In de meeste gevallen is het nodig om relaties te wijzigen of nieuwe relaties te leggen die Power BI niet automatisch gedetecteerd heeft. Hoe dan ook is het belangrijk om relaties in Power BI te begrijpen en te weten hoe je ze maakt en bewerkt.
Power BI Desktop kijkt naar kolomnamen van de tabellen die je laadt en het gegevenstype om te bepalen of er mogelijke relaties zijn. Als dat het geval is, worden de relaties automatisch gemaakt. Als Power BI Desktop niet met grote zekerheid kan vaststellen of er een overeenkomst is, wordt er niet automatisch een relatie gemaakt.
Het is aan te raden om de autodetectie uit te schakelen via File > Options and settings > Options > Data Load
Figuur 12: autodetectie uitschakelen

Notitie
Als er een relatie bestaat tussen twee tabellen, kun je in beide tabellen met de gegevens werken alsof ze één tabel vormen.
3.2 Actieve en niet-actieve relaties
Wanneer Power BI Desktop automatisch relaties maakt, wordt er soms meer dan één relatie tussen twee tabellen gedetecteerd. In een dergelijk geval wordt maar een van de relaties als actief ingesteld. De actieve relatie fungeert als de standaardrelatie. De niet-actieve relatie wordt aangeduid in stippellijn.
1 Klik in het lint op Home > Manage relationships (Relaties beheren) om een overzicht te krijgen van de automatisch gedetecteerde relaties.
Figuur 13: dialoogvenster Manage relationships

3.3 Relaties verwijderen
Selecteer de relatie die je wilt verwijderen en klik op Delete
Figuur 14: relatie verwijderen

3.4 Relaties toevoegen
Relaties toevoegen kan op twee verschillende manieren.
Om het aantal orders per verkoper te kunnen visualiseren, leggen we een relatie tussen de tabel Personeelsleden (veld Personeelslid_ID) en de tabel Orders (veld Verkoper).
Eerste manier
1 Klik op het plusteken om een extra tabblad toe te voegen.
Figuur 15: tabblad toevoegen

2 Sleep de tabellen Personeelsleden en Orders uit het deelvenster Data naar het middelste deelvenster.
Figuur 16: tabellen slepen

3 Sleep het veld Personeelslid_ID naar het veld Verkoper.
Figuur 17: relatie toevoegen

Tweede manier
1 Selecteer de tabel Personeelsleden en klik in het lint op Home > Manage Relationships.
2 Kies New relationship. Het dialoogvenster New relationship verschijnt.
3 Selecteer in de eerste keuzelijst een tabel (Personeelsleden) en selecteer vervolgens de kolom die je in de relatie wilt gebruiken (Personeelslid_ID).
4 Selecteer in de tweede keuzelijst de andere gewenste tabel voor de relatie (Orders); selecteer vervolgens de andere kolom die je wilt gebruiken (Verkoper).
Figuur 18: relatie toevoegen

5 Klik op OK en sluit het venster New relationship.
Notitie
Om een relatie te leggen moet ten minste één tabel in de relatie een kolom hebben met unieke sleutelwaarden. Dit is een algemene vereiste voor alle relationele databases.
6 Verberg de kolommen die niet zichtbaar mogen zijn in de rapportweergave. Klik in de tabel Orders op het oogje naast het veld Bestelnr..
Figuur 19: verbergen in de rapportweergave
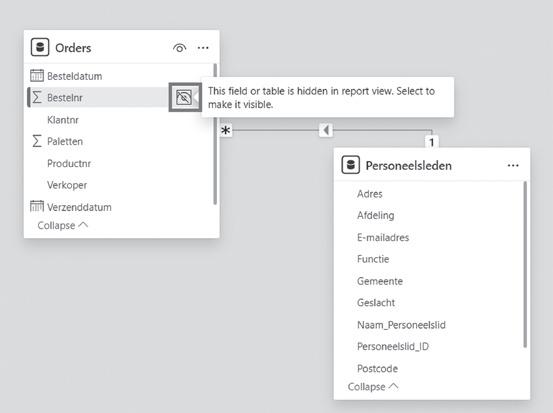
Tabellen of kolommen verbergen
Wanneer je een tabel of kolom verbergt, wordt die niet uit het model verwijderd. Het verbergen van tabellen of kolommen is alleen bedoeld om de lijst met tabellen en kolommen die zichtbaar zijn voor de eindgebruiker (in de rapportweergave) te vereenvoudigen.
3.5 Feiten en dimensies
Om het gegevensmodel goed te begrijpen verwijderen we alle automatisch aangemaakte relaties en voegen ze handmatig opnieuw toe. Zo krijg je beter inzicht in hoe de tabellen met elkaar verbonden zijn en hoe het model is opgebouwd.
Een gegevensmodel bestaat meestal uit twee soorten tabellen: feitentabellen en dimensietabellen
• Feiten zijn de meetbare gegevens, zoals omzet, aantal producten of ziekteverzuim.
• Dimensies geven context aan die feiten. Ze beantwoorden de vragen wie, wat, waar, wanneer
Een hulpmiddel om feiten en dimensies van elkaar te onderscheiden, is het gebruik van het woord ‘per’.
Als je zegt: ‘Ziekteverzuim per medewerker per maand’, dan is ziekteverzuim het feit. Medewerker en maand zijn de dimensies.
Of bij: ‘Omzet per land per smaak’, is omzet het feit, en land en smaak zijn de dimensies.
Hoofdstuk
In een goed opgebouwd gegevensmodel staat de feitentabel centraal. Die tabel bevat:
• sleutelkolommen die verwijzen naar de bijhorende dimensietabellen (zoals product-ID, klant-ID...);
• numerieke waarden die we willen analyseren (zoals omzet, kosten, aantal...).
Rond de feitentabel bevinden zich de dimensietabellen, die extra informatie bevatten over bijvoorbeeld producten, klanten of periodes.
In de praktijk bevatten dimensietabellen meestal minder rijen dan feitentabellen, maar wel meer beschrijvende velden.
De structuur van zo’n model lijkt op een ster: één centrale feitentabel met daaromheen meerdere dimensietabellen. Daarom noemen we dat een sterschema (star scheme).
Dat sterschema is een veelgebruikte en efficiënte manier van modelleren, vooral in relationele datawarehouses.
Figuur 20: sterschema

We passen dit toe in ons voorbeeld.
1 Klik in de modelweergave in het lint op Home > Manage relationships.
2 Verwijder alle relaties:
a Selecteer alle relaties met de SHIFT-toets.
b Klik op Delete
Figuur 21: relaties verwijderen

c Bevestig door te klikken op Delete.
d Klik op Close.
In een volgende stap controleren we welke tabel(len) de feiten bevatten en welke tabel(len) de dimensies:
Feitentabel(len)
Orders
Klachten
Dimensietabel(len)
Klanten
Personeelsleden
Producten
1 Plaats de feitentabel centraal en leg de volgende relaties door de velden te slepen.
Figuur 22: relaties
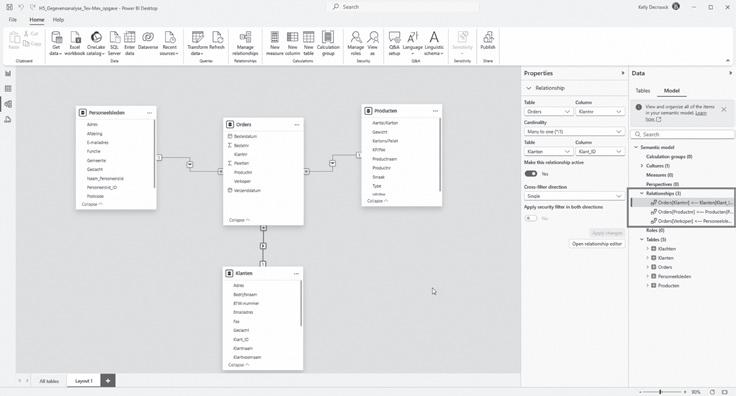
Figuur 23: sterschema

Een goed gestructureerd gegevensmodel bestaat idealiter uit tabellen die duidelijk te onderscheiden zijn als dimensietabellen of feitentabellen.In de praktijk is modelontwerp echter geen exacte wetenschap. Niet elk model volgt strikt die indeling, en dat is vaak helemaal prima. Het belangrijkste is dat het model logisch aanvoelt en aansluit bij de manier waarop je de gegevens wilt analyseren.
Zo kan een model bijvoorbeeld meerdere feitentabellen bevatten. In dat geval is het verstandig om voor elke feitentabel een afzonderlijk sterschema te ontwerpen, eventueel in verschillende weergaves of lay-outs. Dat helpt om het model overzichtelijk en onderhoudbaar te houden.
Figuur 24: nieuwe lay-out stermodel Klachten

2 Bewaar het bestand onder de naam H5_Gegevensanalyse_Tex-Mex.pbix.
Notitie
Het is aan te raden in de naamgeving van de tabellen de prefix Dim (dimensietabel) of Fact (feitentabel) te gebruiken. Dit kan helpen bij het modelleren.
Bij het leggen van relatie moeten we lussen vermijden. Als er bijvoorbeeld nog een relatie gelegd zou worden tussen de tabel Klachten (kolom Personeelslid_ID) en de tabel Personeelsleden (kolom Personeelslid_ID), ontstaat er een lus.
Een alternatief voor het sterschema is het snowflake scheme of sneeuwvlokschema. Daarbij worden de dimensietabellen verder genormaliseerd.
Het gegevensmodel begrijpen is cruciaal om tot een correcte gegevensanalyse te komen.
3.6 Kardinaliteit en kruisfilterrichting
Wanneer je een relatie maakt of bewerkt, kun je in Power BI extra opties configureren: de kardinaliteit (Cardinality, zie ook Relationele database) en de kruisfilterrichting (Cross filter direction).
Figuur 25: opties relaties

Power BI configureert automatisch de eigenschappen voor kardinaliteit en kruisfilterrichting. Maar je kunt ze wijzigen wanneer je dat nodig vindt.
Kardinaliteit
We onderscheiden vier soorten kardinaliteit:
Figuur 26: kardinaliteit

One to many of één op veel (1:*), of omgekeerd (*:1)
Dit type relatie komt heel vaak voor. Eén record in de eerste tabel is gerelateerd aan meerdere records in de tweede tabel. Voor elke klant (1) uit de tabel Klanten kunnen bijvoorbeeld meerdere (veel) orders in de tabel Orders opgeslagen zijn.
Figuur 27: één-op-veelrelatie


One to one of één op één (1:1)
Eén record in de eerste tabel is gerelateerd aan één record in de tweede tabel. Een personeelslid (1) uit de tabel Personeelsleden is bijvoorbeeld gerelateerd aan één wagen (1) uit de tabel Bedrijfswagens.
Many to many of veel op veel (*:*)
Meerdere records in een tabel zijn gekoppeld met meerdere records in een andere tabel. Tussen klanten en product bestaat er bijvoorbeeld een veel-op-veelrelatie. Klanten kunnen meerdere producten kopen en één product kan door meerdere klanten worden gekocht.
In dit geval kan er gewerkt worden met een samenvoegtabel, of de veel-op-veelrelatie wordt gesplitst in twee één-op-veelrelaties. Elke record in een samenvoegtabel bevat een vergelijkingsveld met de waarde van de primaire sleutels van de twee tabellen die worden samengevoegd.
Figuur 28: veel-op-veelrelatie
Hoofdstuk 5 Een gegevensmodel maken in power BI Desktop
Notitie
Power BI biedt ook ondersteuning voor veel-op-veelrelaties. Meer informatie over veel-op-veelrelaties kun je terugvinden op https://docs.microsoft.com/nl-nl/power-bi/transform-model/desktop-manyto-many-relationships.
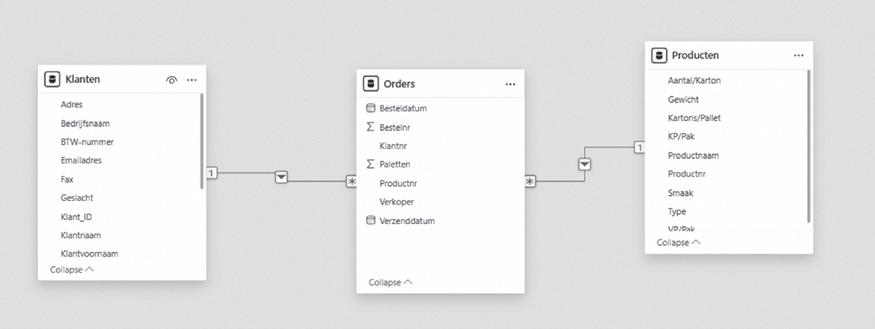
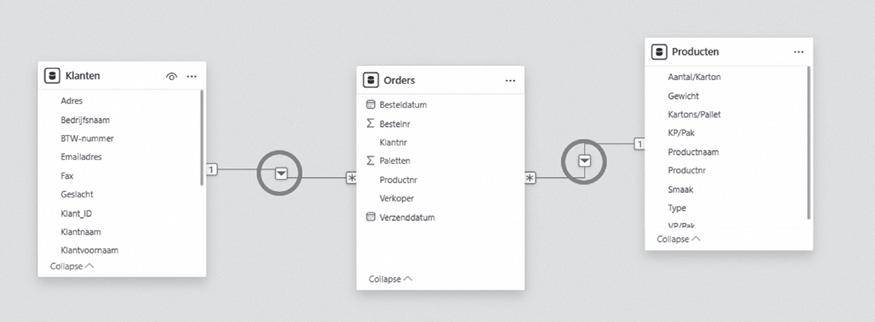
Kruisfilterrichting
De richting van de relatie speelt een hele belangrijke rol bij het modelleren in Power BI. Concreet betekent dit dat de tabel Producten of de tabel Klanten de tabel Orders kan filteren.
Figuur 29: richting relatie
We werken verder in het bestand H5_Gegevensanalyse_Tex-Mex.pbix
1 Klik op het pictogram Report om naar de rapportweergave te gaan.
2 Selecteer in het deelvenster Data in de tabel Producten het veld Smaak en in de tabel Orders het veld Palletten. Het resultaat is het aantal palletten per smaak.
Figuur 30: aantal palletten per smaak

Door de filterrichting kan de tabel Orders gefilterd worden door een dimensie uit de tabel Producten. Stel dat we het aantal klanten per smaak willen visualiseren:
1 Selecteer in het deelvenster Data in de tabel Producten het veld Smaak en in de tabel Klanten het veld KlantID.
2 Kies voor het veld KlantID de aggregatie Count (Distinct).
Figuur 31: Count (Distinct)

3 Hoewel de tabellen gerelateerd zijn (met een tussentabel), krijgen we niet het juiste resultaat.
Figuur 32: aantal klanten per smaak

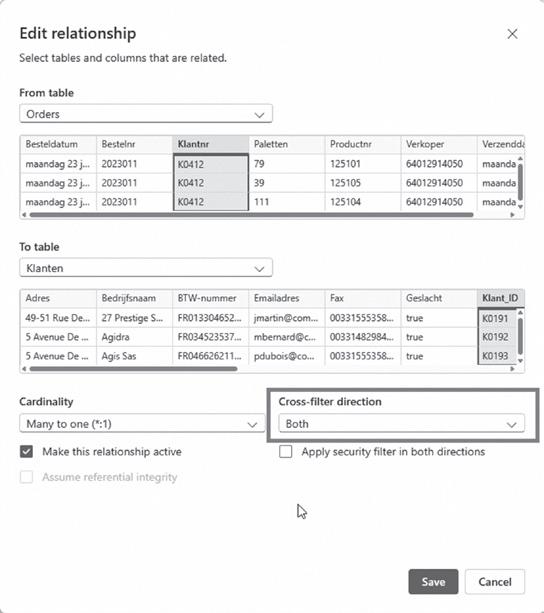
4 Wijzig de kruisfilterrichting tussen de tabel Orders en de tabel Klanten naar Both
Figuur 33: kruisfilterrichting Both
Figuur 34: kruisfilterrichting Both

Hoofdstuk
5 Ga naar de rapportweergave om het resultaat te bekijken.
Figuur 35: aantal klanten per smaak

Het resultaat is het correcte aantal klanten per smaak.
Notitie
Door de kruisfilterrichting te wijzigen kun je mogelijke problemen met visualisaties oplossen. We raden het niet aan, omdat het wijzigen van de kruisfilterrichting naar ‘Both’ negatieve gevolgen heeft voor de performantie van het model.
Betere oplossingen zijn het gegevensmodel wijzigen of gebruikmaken van de DAX-functie CROSSFILTER.