International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
1,2,3B.Tech Student, Department of Computer Science and Engineering, Walchand College of Engineering, Sangli, Maharashtra, India - 416415
4Faculty, Department of Computer Science and Engineering, Walchand College of Engineering, Sangli, Maharashtra, India – 416415 ***
ABSTRACT:
We know that intelligence department works hard to identify potential threats for integrity of our country. They identify suspsects by various. sources one of which is tapping phone calls of suspsects which are identified by them and detect potential threat caused by them for national .security. Now increase in the population makes this task very difficult identifying all the suspect and detecting threats through their conversation is too much of task to do. So, to simplify this task we propose a threat detection system which will take audio signals and identify threatful. Conversation from it. Here, we have used various techniques as a different modules in the project to achieve our goal of giving intelligence department. A tool which can be used efficiently track threats for our country.
In2001ParliamentHouseofIndiawasunderattackofterroristswhichbelongedtoLashkar-e-ToibaandJaishe-Mohammad which are the two Pakistan raised terrorist organisations. All terrorists were killed and led to nine deaths(including6police,twoparliamentsecurityservicepersonnelandgardener).Theseattacksconductedwiththehelp of people who live in India. This attack may not have huge number of casualty but capital being attacked is huge hole in security. This attack was possible only due to some anti nationals provided information to terrorist organisation. So to identifysuchpeopleswehaveproposedoursystemwhichcouldidentifythesuchantinationalpeoples.Alsogetthreatful conversationsmadeandidentifythreatwellbeforeattacks.TheIntelligencedepartmentdoesatremendousjobtosecure the people from potential threats by identifying suspicious people. Identifying suspicious people is not an easy job in a countryof1.3Bnpeopleandkeepinganeyeoneachconversationofthesepeopleisalsoatremendousjob.Ourproposed model can simplify the above task and efficiently identify suspicious people. Hence with our idea we can help security departmentstoidentifypotentialthreatsandcounterthem.Ouraimistobuildamodelwhichwillhelpourcountryinthe abovementionedmanner.Presently,computershavealreadyreplacedatremendousnumberofhumansinmanycreative professions. Therefore, Artificial Intelligence areas are composed of Machine Learning, Natural Language Processing, ComputerVisionandRobotics.Similarly,speechrecognitioncanbepredictedbyusingcomputers. Previousresearchuses deeplearningtobeusedin speechrecognitionbyusing anaudiolibraryfromGooglewhichhas66.22%accuracy.Based ontheexperimentalresults,thisresearchcanbeappliedtospeechrecognition.Inotherways,thisresearchwillmakethe computer more intelligent and capable. Researchers used data from the Google audio Set, which is Google's voice data warehousetobeusedastrainingandtestdata.Naturallanguageprocessing(NLP)hasrecentlygainedmuchattentionfor representing and analysing human language computationally. It has spread its applications in various fields such as machine translation, email spam detection, information extraction, summarisation, medical, and question answering etc. ThepaperdistinguishesfourphasesbydiscussingdifferentlevelsofNLPandcomponentsofNaturalLanguageGeneration (NLG)followedbypresentingthehistoryandevolutionofNLP,stateoftheartpresentingthevariousapplicationsofNLP andcurrenttrendsandchallenges.Theproposedsystemisuniqueinitsconcept.Astherearemanytextsentimentanalysis modelsandspeechsentimentmodelsdevelopedbutarenotveryeffectiveandefficient.Ourproposedmodelwillidentify audio threat signals and only those can be put under observations and this will direct the security agency in the right directionandminimiseoverheadoftheintelligencedepartment.
Natural language processing applications are text processing ,classification and clustering applications. The simple text analytics application is tweet classification application. The tweets are classified as positive , negative and neutralbasedonthecontentofthattweet.
With help of Term frequency and Inverse document frequency we can determine most relevant from the dataset.The count of words in a text document is known as term frequency and how frequent the word present in the
International
e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
documentisknownasdocumentfrequency.TherelevanceofwordsfromtextdocumentiscalculatedusingTF-IDF.Words withhighTF-IDFnumbersimplyastrongrelationshipwiththedocumenttheyappearin,suggestingthatifthatwordwere to appear in a query, the document could be of interest to the user. This algorithm has been proposed to increase the relevance for a particular query. Machine Learning algorithms such as Naive Bayes classifier, Decision Trees, Random Forest,SupportVectorMachinesandboostingalgorithmsareproventobesuccessfulintextclassificationproblems.
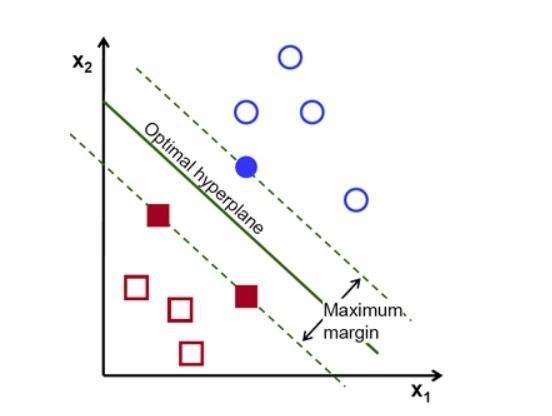
This paper is on ”Detecting potential threat signals from text documents and classifying them on severity of threat'' uses a Support Vector Machine (SVM) classifier to perform the text document classification. Support Vector Machineclassifier uses optimal hyperplane to perform the classification task. This paper aims at converting audio signal intotexttranscriptthenperformsentimentanalysisonitandthenclassifyitbasedonseverityofthreat.
Textdataisunstructureddata.Beforepassingtexttomachinelearningalgorithm,textshouldbeconvertedinto vectorformat.TextdataconvertedintovectorformatbyvarioustechniquesSometechniquesusewordoccurrencewhile someothertechniquesusewordfrequency.
MachineLearningalgorithmsarewonttoperformclassificationandregression.Thealgorithmsusedforclassificationare logistical Regression for binary classification, call Trees, Random Forest Classifier, Support Vector Machines, Naive mathematicianClassifier,andBoostingAlgorithms.
Logistic Regression may be a binary classification formula wont to predict output as o or one. The output of logistical regression continuously states the likelihood of being one. logistical regression works constantly because the sigmoid activationperformswherevertheoutputfallsduringavaryofzeroandone.
Naïve mathematician formula may be a supervised learning formula, that is predicated on mathematician theorem and used for determination classification issues. It is primarily utilized in text classification that has a high-dimensional coaching dataset. Naïve mathematician Classifier is one every of the straight forward and only Classification algorithms that help in building the quick machine learning models which will build fast predictions. It is a probabilistic classifier, which implies it predicts on the premise of the likelihood of the associate object. Some standard samples of the Naïve mathematician formula are spam filtration, Sentimental analysis, and classifying articles. Bayes' theorem is additionally referredtoasBayes'RuleorBayes'law,whichisemployedtoworkoutthelikelihoodofahypothesiswithpreviousdata. Itdependsonthechance.
Theformulafortheoremisgivenas:
Where,
P(A|B)isPosteriorprobability:thelikelihoodofhypothesisAonthedeterminedeventB.
P(B|A) is chance likelihood: likelihood of the proof provided that the probability of a hypothesis is true. P(A) is previous likelihood:Probabilityofhypothesisbeforeperceptivetheproof.
P(B)isMarginallikelihood:Probabilityofproof.
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
Support Vector Machineor SVM is one every of the foremost standard supervised Learning algorithms, that is employed forClassificationstillasRegressionissues.However,primarily,it'susedforClassificationissuesinMachineLearning.
ThegoaloftheSVMformulaistoformthesimplestlineorcallboundarywhichwillsegregaten-dimensionalarea into categories sothat we will simplyplacethe newinformation withinthecorrectclasswithinthe future. This best call boundary is termed a hyperplane. SVM chooses the intense points/vectors that facilitate making the hyperplane. These extremecasesarereferredtoassupportvectors,andthustheformulaistermedasSupportVectorMachine.
Oursystemcomprisesoftotalfourstepswhichwillbeexecutedsequentiallyinordertodetectthreatpatternsintheinput sample and then classifying them into flags based on the severity of threat. Below is the flowchart showing flow of the entiresystem.
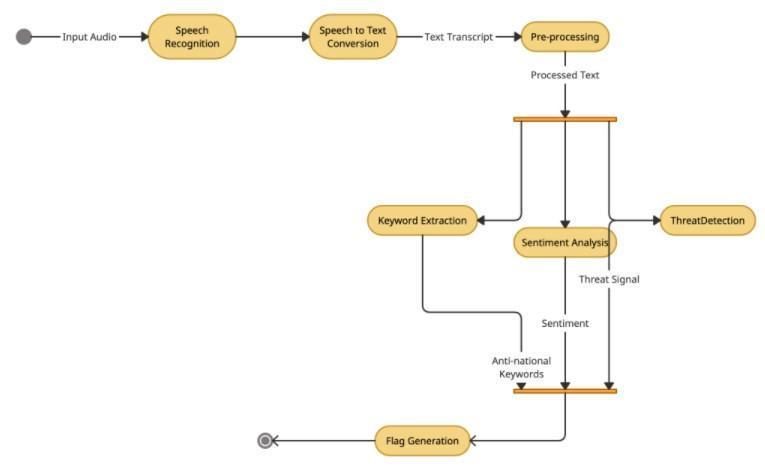
Inthefirststep,wetakeinputfromtheuserintheformofanaudio/textfile.Processingaudiodatacanbeamuch tedioustaskandprocessingtextdatawillbemuchefficient.Iftheinputfileisatextfilethentheprocesswillstartfromthe secondstepandiftheinputisanaudiofiletheninthefirststepitwillbeconvertedintoatextfileandthenitwillbegiven tothesecondstepasaninput.Forthisconversionofaudiototext,wehaveusedtheSpeechRecognitionpackageinpython. Thispackagehelpsinrecognisinginputaudio.Itconsistsofarecogniserclasswhoseinstancewillbeused.Eachinstance ofrecogniserclassconsistsofvariousmethodswhichcanreadvariousaudiosources.TheyusevariousAPI’sbasedonthe
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1144
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056


Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
user requirements. Here we are using Google speech recogniser API for converting input from speech to text as it is the bestaccuracyamongother API’s.Inthespeechalsowehavetwotypesofinputsoneasaudiofileanotherisdirectaudio from the microphone which is being recorded live. Your microphone input required pyaudio. pyaudio consist of listen methodwhichtakestheinputfromthemicrophone.Microphoneinputcanbetakenincaseofreal-timemonitoring.
ThesecondmoduleiskeywordextractionherewewillbeextractingfrequentlyoccurringAntiNationalkeywords from the input text and maintaining their account. this keyword extraction process consists of various types such as preprocessingwhereweremovepunctuationmarksandspecialcharactersfromthetextthenthereisstemmingwhereit removes suffixes and prefixes from the word roots and the last one is limited edition air it maths remaining root forms backtotheactual words.afterthisallpreprocessingwhereweremoveallthesestopwords,punctuationsandconvertto wordsbacktoitsrootformsandmapthemtoitsoriginalmeaningweallgetthewordwhichwillgivesomemeaningtothe sentence.thenwiththehelpofthedataset,wewillchoosealltheanti-nationalkeywordsandthecodewordswereusedby theterroristtocommunicatebetweenthem.Onlydetectingthosekeywordswillnothelpsowehavetodetectthatifthose keywordsarebeingusedinthecontextofnationalthreat,sowewilldetectthisbymaintainingalistofallthemajorcities andallthecountrieswiththeircapitalsandallthewordsreferringtocountryNationorcityandfindingthosewordsinthe sentenceinwhichtheanti-nationalwordsareidentified.Afteridentifyingthosewordswewillmaintaintheirrecordand willbeusingtheminthelastintheclassificationoftheinputrecordindifferentflags.
thethirdstepissentimentanalysis,thissteptakestheoutputofthefirststepasanInputandperformssentiment analysis on it. The basic task of sentiment analysis is to classify the text based on its polarity as positive negative or neutral. For sentiment analysis we have used NLTK which means natural language Toolkit it contains packages to make the machine understand human languages and also it has the most powerful Natural Language Processing libraries. so howthissentimentanalysisisperformedaswehavealreadysaidthatNLTKhasarichsetoflibrarieswhichincludesall therequireddatasetsandfunctionsointhatlibrariesonlyitmaintainssetofallthewordsthatdepictsomeemotionand linkthosewordstotheemotion.
This way while processing when we encounter the word which depicts any emotion it will be captured and the emotion with that word is representing will be added to the list of sentiments. now all of the sentiments/emotions are already labelled as positive or negative sentiments/emotions like the words such as enjoy happy good denote positive sentiment and the words such as hate or beat denotes negative sentiments. Now will use a polarity score checker it calculates the probability of positive sentiments negative sentiment and neutral sentiment into the text. after that for classificationoftextintopositivenegativeorneutral,itchecksiftheprobabilityofpositivesentimentsisgreaterthanthe probability of negative sentiments and if it is so then the entire text will be classified as positive. And vice versa, if the probability of negative sentiments is greater than the probability of positive then the entire text will be classified as negative.andiftheprobabilityoftextbeingpositiveisequaltotheprobabilityoftextbeingnegativethenthetextwill be classifiedasaneutraltext.
In the fourth step we are classifying the text into threatful or not threatful category. here we are using a machine-learning algorithm to classify it. as you can see in the experimental results we have tried Logistic regression, multinomial naive Bayes algorithm and support vector machine algorithm. out of these three algorithms, we got the highest accuracy with the support vector machine algorithm So we have decided to go with it. we have used the dataset that contains the text from Wikipedia talk page edits and divided the 80% of the dataset for training and 20% of the datasetfortesting.testingonthisdatasetourSVMmodelgotanaccuracyof97%.so wehavebuiltthemodelofthisand usingthismodeltoclassifiedourtext.supportvectormachineisasupervisedmachinelearningalgorithmthatcanbeused forbothclassificationorregressionchallenges.theobjectiveofthesupportvectormachineis tofindahyperplaneinanndimensionalspacethatdistinctlyclassifiesthedatapointswherenisthenumberoffeatures.Toseparatethetwoclasses ofdatapointstherearemanypossiblehyperplanesthatcouldbechosen.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
Our objective is to find a plane that has the maximum margin i.e the maximum distance between data points of bothclasses.
Fig-1:OptimalHyperplane

Maximummargindistanceprovidessomereinforcementsothatfuturedata points canbeclassifiedwithmore confidence. we have used SVM because its accuracy is more than other algorithms as well as it works really well with a clear margin of separation. also, it is more effective in 2-dimensional spaces and it is much memory efficient. so after successfultrainingandtestingofthemodelwhenwegiveourtextfilewhichisgeneratedasanoutputofthefirstmodule asaninputtothemodelforclassification,itaccuratelyclassifiesthetextasthreatfulornotthreatful.Afterthecompletion ofthesefoursteps,basedontheoutputofthesteps,weclassifytextintothreeflagsgreen,yellowandred.likeifthetext containsanti-nationalkeywords,itssentimentisnegativeanditisclassifiedasathreatfulltextitwillbelabelledasaRed flag,ifthetextdoesnotcontainasingleanti-nationalkeyword,itssentimentispositiveanditisclassifiedasnotthreatful thenitwillbelabelledasgreenflagotherwiseitwillbelabelledasyellowflag.
The machine learning models are tuned and evaluated on cross-validation data,It is part of training data.By performing Exploratory data analysis(EDA) the models are tuned with parameters.The models proposed with the current hyperparametersprovidebetterevaluationresultsthanthemachinelearningalgorithms.Foreachofthemodellingtechniques usedtheresultsarecaptured.
Table-1: Accuracy of different classification algorithms
Classification Algorithm Accuracy of model
LogisticRegression 92.33
NaiveBayes 87.55
SupportVectorMachine 95.33
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
The Support Vector Machine model tends to outperform the machine learning models. The below metric shows howtheaccuracyoftheSupportVectorMachinemodelischangingbychangingthehyper-parameters.
Table-2: Accuracy of the Support Vector Machine model with different hyper-parameters.
Kernel C Gamma Features Accuracy poly 1 1 5000 89 poly 0.1 1 5000 86 poly 0.1 10 5000 89.5 linear 0.1 10 5000 91.3 linear 1 1 5000 96.16 linear 1 1 10000 96 linear 1 1 20000 95.83 linear 1 1 89618 95.33
Whileresearchingforthisprojectwefoundverylessresearchdoneregardingthisprojectasawhole.Thisissueisnotyet addressed efficiently. So, We have proposed a model which can identify the severity of threat in the audio conversation. Forthis,wehaveincludedfourmodules.Thesemodulesincludeaudiototexttranscriptthenprocessingthesetextfilesto extract keywords then performing sentiment analysis and finally categorising into flags to show the severity of threat in conversation.
Alsoasafutureworkwewillbetryingtogeneralisethesystemfordifferentapplicationsjustbydoingsomesmall modificationsintheclassificationrulesandbyreplacingthedatasetaccordingtorequirements.
https://wordnet.princeton.edu/ https://research.google.com/audioset/ https://www.researchgate.net/post/How-do-you-extract-keywords-from-text-Which-good-NLP-tools-are-available BatoulAljaddohu,NishithKotak,DocumentTextClassificationUsingSVM(2020).
ShwetaMayor,BhaskerPant,DocumentClassificationUsingSVM(2012). SauravSahay,SupportVectorMachinesandDocumentClassification(2004).
ThedatasetcontainstextfromWikipedia'stalkpageedits.https://bit.ly/3uKYJQK