International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
Atharvraj Patil1, Jayesh Ingale2
1Department of Electrical Engineering, College of Engineering, Pune, India
2Department of Electrical Engineering, College of Engineering, Pune, India ***
Abstract - With the aid of a picture produced by security cameras, automatic license plate detection systems (ALPDS) have the potential to automatically track and identify the vehicle by capturing and recognizing the number plate of any vehicle. It can be used for a variety of practical purposes, like recording vehicle numbers at toll gates, tracking down stolen vehicles using CCTVs, and more. Detecting the license plate from the input image is the primary stage in automatic license plate recognition systems, which are frequently employed for purposes like effective parking management, updating law enforcement, systematic toll way management on roads, etc. There are numerous methods for detecting license plates. This study focuses on various techniques for reading license plates from input images of vehicles. Here, three key methods edge detection, object detection with YOLOv4 (You Only Look Once) and WPOD-NET (Warped Planar Object Detection Network) are covered. This paper also provides adescriptionofeachmethod'sbenefitsanddownsides.
Key Words: Edge detection, License plate detection, WPOD-NET, YOLOv4.
Massive growth of the vehicular sector has raised the issues of parking management, traffic control, tracking stolen vehicles, etc. Also, tracking individual vehicles has become a tedious task for all organizations. To avoid issues and for effective parking management, the Automatic Number Plate Recognition Systems (ANPRS) are designed. License plate recognition is the base of ANPRS. It has a wide range of applications which uses extracted license plate details to create automated solutions for various problems like access control, tolling, bordercontrol,trafficcontrol,findingstolencars,efficient parking management and so on. The primary step in ANPRSislicenseplatedetectionandextraction.
This paper discusses different methods of license plate extraction where the vehicle’s static image is fed to the system which further processes the image to extract the license plate. Each of the techniques discussed in this paper has various advantages and drawbacks. Like, a methodmayrequirelowprocessingpower,butitfailsfor
different unconstrained scenarios. Another method may be efficient for real time applications but then it requires highprocessingpowerleadingtolimitationsofhardware. Thus, further sections describe in detail about various methodsoflicenseplatedetection.
In [1], the Automatic Number Plate Recognition System (ANPRS)isdividedinto3mainstepsnamely,
● VehicleDetection
● LicensePlateDetection
● OpticalCharacterRecognition(OCR).
Therewerevariousalgorithmsavailablefortheprocessof object detection like Fast Region Based Convolutional Neural Network (RCNN), Single shot multibox detector (SSD), You Only Look Once (YOLO), etc. After comparing various algorithms for the process of vehicle detection theyfoundtheYOLOalgorithmasthemostsuitedforthis work due to its advantage of quick real-time object detectionanduseditforvehicledetection,WarpedPlanar Object Detection Network (WPOD-NET), and Optical Character Recognition (OCR) for License Plate (LP) detection. They have employed various datasets for training this network. These datasetsconsider various factors, such asthe LP angle (frontal and tilted), the distance from vehicles to the camera (near, intermediate, andfar),andtheareawherethephotographsweretaken. Finally, after training the model on all four datasets average accuracy obtained was 89.33%. The earlier YOLOv2 vehicle detection and OCR-NET were developed and put into use using the DarkNet framework, but the proposed WPOD-NET is implemented using the TensorFlowframework.In[4],thisprojectreportpresents development on new approaches for the extraction of license plates. Their proposed algorithm was based on video acquisition, licenseplate region extraction, plate character segmentation, and character recognition. This project presents a simplestraightforward license plate extraction technique. The method's four main stages converting RGB images to grayscale, applying Gaussian blur, performing morphological operations, and determining the license plate's precise location are
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
basedontheEdgeDetectionalgorithm.Itusesacharacter segmentation algorithm to detect the characters on the number plate. Templates are created for each of the alphanumeric characters (from A-Z and 0-9). The mean squared error method is used for image similarity. Each segmentedcharacterofthelicenseplateiscomparedwith all the standard template characters and the error is recordedandthefinaloutputisdisplayedonthemonitor. Theproposedsystemhasthefollowinglimitationslikethe camera should be of good quality to extract correct characters from license plates. It should have proper lighting. It doesn’t work in different illumination conditions and although accuracy is high, mean squared errorleadstolowcomputationalresults.
The implementation of the proposed system can be extended for the recognition of number platesof multiple vehicles in a single image frame. User-friendly android applications can be developed for traffic surveillance management systems. Also, character recognition can be doneusingvariousdeeplearningalgorithmsastheyyield more accuracy. (Graphical Processing Units) GPUs can be used to achieve more performance in terms of computationaltime.
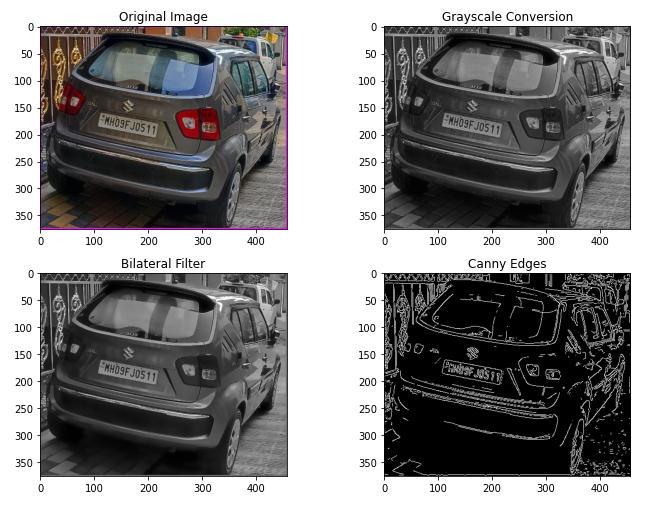
Digitalimageshaveedges,whicharenotablelocalchanges in intensity. An edge is a collection of linked pixels that identifies the boundary between two distinct sections. Edge detection is the method of image pre-processing used to recognize points from the input image and in simplewords,itidentifiessharpchangesinthebrightness oftheimage.Itisafundamentalstageinimageprocessing, computer vision, and picture pattern recognition. Edge DetectionOperatorsareoftwotypes:
● Gradient–based operator: First-order derivations are computed using gradient-based operators in digital images,suchastheSobel,Prewitt,andRobertoperators.
● Gaussian–based operator: Second-order derivations are computed using Gaussian–based operator in a digital image like Canny edge detector and Laplacian ofGaussian.
TheinputimageisfirstlyconvertedfromRGBtograyscale to simply reduce complexity: from a 3D pixel value (R, G, B) to a 1D value. Many tasks do not fare better with 3D pixels (e.g., edge detection). To reduce the noise, we need toblurtheinputimagewithGaussianBlurthenconvertit
to grayscale. Image noise is a distortion in the image that results from a camera malfunction or from reduced visibility brought on by shifting weather conditions. Noises are another term for the random change in pixel intensity levels. There are many varieties of noise, including salt & pepper noise and Gaussian noise. For noiseremoval,weimplementedaniterativebilateralfilter. A bilateral filter is used for smoothening images and reducing noise, while preserving edges. More effectively than the median filter, it offers the mechanism for noise reduction while preserving edges. The process of binarizing a picture results in an output image that only has two-pixel values, white and black pixels. The work of detecting license plates will be simpler if the binarization step is carried out first since edges will be visible more clearlyinthebinaryimage.
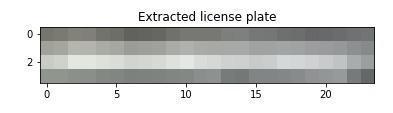
Our image is ready to discover contours after preprocessing shown in figure 1. The remaining contours are sent for additional processing once any contours having an area of less than 30 are eliminated. Every contourisroughlyapproximatedtoformapolygon,andif a contour is quadrilateral in shape (has four sides), it is expected to be the licenseplate. The contours are thencreated,andtheresultingimageisasfollows:
Fig -2:Extractedlicenseplate

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
Resultsforleveledimageandtiltedimage: As the image shown in figure 3 is leveled, therefore the detection and extraction are done properly as depicted in 4.



Thisalgorithmfailswhentheimageismoretilted.Also,it works only if the input image is of good quality. As this algorithm is not efficient enough in real time, we have triedotheralgorithmsforlicenseplatelocalization.
You only look once (YOLO) is a family of one-stage object detectors that are fast and accurate. All the YOLO models are object detection models. Object detection models are trained to look at an image and search for a subset of object classes. When found, these object classes are enclosed in a bounding box and their class is identified. Object detection models are typically trained and evaluated on the COCO (Common Objects in Context) dataset,whichcontainsabroadrangeof80objectclasses. Real-time is particularly important for object detection models that operate on video feeds, such as self driving cars,etc.Theotheradvantageofrealtimeobjectdetection models is that they are small and easy to wield by all developers.
ForTiltedImage: Asshowninfigure5and6,theregionofinterestdetected isnotaccurate. Fig -5:
YOLOv4makesrealtimedetectionapriorityandconducts trainingonasingleGPU.
Theoriginal YOLO(You OnlyLookOnce)waswrittenina custom framework called Darknet. Darknet is a very flexible research framework written in low-level languages and has produced a series of the best real-time objectdetectorsincomputervision.
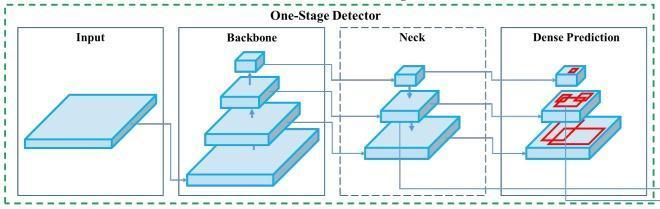
The general architecture of YOLOv4 includes the following:
Backbone is the deep learning architecture that basically acts as a feature extractor. The neck has additional layers between the head and the backbone. The head, often referred to as the object detector, essentially locates the area where the object may be present. Methods such as "bag of freebies" (BoF) can improve object detecting accuracy without raising inference costs. Bag of Specials (BoS) are those plugin modules and post-processing techniques that only slightly raise the inference cost but
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
greatly increase object detection accuracy. The general architectureofYOLOv4isdepictedinfigure7.
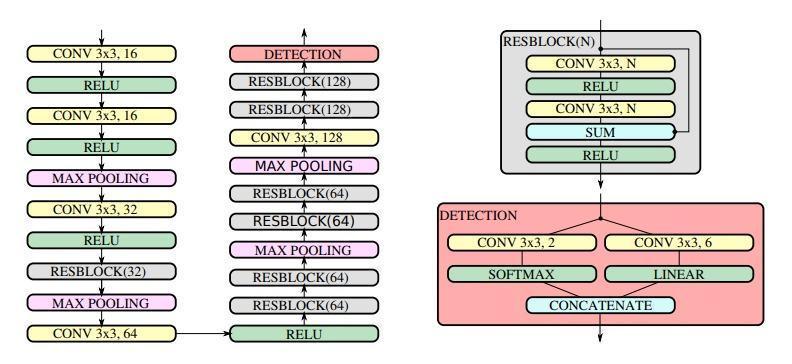
Selection of architecture for the entire network is a very tedious task as there can be a lot of possibilities. Thus, depending upon some factors like number of convolutionallayers,numberofparametersandadditional characteristicswhichincludebag ofspecials,freebies, etc, thefinalarchitectureofYOLOv4canbepresentedas:
CSPDarkNet53(Head)-SSP+PANet(Neck)YOLOv3(head)
ThemainideabehindtheYOLOv4objectdetectoristhatit divides the image into evenly sized grids, and then predicts the boundary boxes and corresponding probability of each grid. Owing to this, YOLOv4 uses CIoU as loss function as it considers distance between center points and overlapping area, and it uses Mish activation function.
As discussed, the YOLOv4 network has the ability of detecting 80 classes, but for our real time application detection of unnecessary classes leads to reduction of efficiency and increases time of operation. Thus, in order to deal with this problem, we decided to train a custom YOLOv4 detector for a single class i.e., license plate. Further in order to create a custom detector the primary requirementisagooddatasetofimagesandlabelssothat the detector can be efficiently trained to detect objects. WeusedtheimagesfromGoogleOpenImagesandcreated a dataset of 5000 images and are split into training and validation dataset in 80:20 ratio. All the images in the training dataset were labeled with the bounding box coordinates and further these labels are converted in YOLOv4 format. The parameters for the training process were set to optimal values found by fine tuning it: batch=64, subdivisions=16, learning_rate=0.001, max_batches = 6000, policy = steps, steps=4800, 5400. Finally, we received an accuracy of 91%. The results of YOLOv4customdetectorareshowninfigure8.

Even though the YOLOv4 custom object detector has an advantage of high-speed processing making it apt for real time applications, it sometimes fails in unrestricted situations when the LP may be significantly altered as a resultofobliqueperspectives.

Warped Planar Object Detection Network (WPOD-NET) is a novel Convolutional Neural Network (CNN) capable of detecting and rectifying multiple distorted license plates in a single image. The methodology of this network is complex and is described further. The network is initially fed by the vehicle detection's output that has been downsized. An 8-channel feature map with object/nonobjectprobabilityandaffinetransformationparametersis the result of the feed forwarding. Let's first consider an imaginarysquarewithaconstantsizesurroundingacell's centerinordertoextractthewarpedLP(m,n).Aportion oftheregressed parameters are thenutilized tocreate an affinematrixthatconvertsthehypotheticalsquareintoan LP region if the object probability for this cell is greater thanaspecific detectionthreshold.Thereareatotalof 21 convolutional layers in the proposeddesign. All convolutionalfiltershaveaconstantsizeof3x3.Exceptfor the detection block, the entire network employs ReLU activations. There are four max pooling layers with a size
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
of 2x2 and a stride of 2, which lowers the input dimensionality by a factor of 16. Two parallel convolutional layers make up the detection block's last layer.ThearchitectureofWPOD-NETcanbeseeninfigure 10.
power. Hence considering the requirement of application, onecanoptforanyofthesealgorithms.
[1] S´ergio Montazzolli Silva, Cl´audio Rosito Jung, “LicensePlateDetectionandRecognitioninUnconstrained Scenarios”, Institute of Informatics - Federal University of RioGrandedoSulPortoAlegre,Brazil,ECCV2018.
[2] Cheng-Hun Lin, Yong-Sin Lin, Wei-Chen Lui, “An Efficient License Plate Recognition System Using ConvolutionalNeuralNetworks”,IEEEICASI2018
Adatasetof196photosisutilizedtotraintheWPOD-NET, comprising 105 images from the Cars Dataset, 40 images from the SSIG Dataset (training subset), and 51 images from the AOLP (Application-oriented License Plate)dataset(LEsubset).FourofthecornersoftheLPin eachimagearemanuallyannotated.MostoftheLPsinthe Cars Dataset's chosen photos are European, but there are alsoalotofAmericanandothertypesofLPs.Brazilianand Taiwanese LPs are depicted in images from SSIG and AOLP, respectively. Data augmentation is done on the datasetbecauseitisminimalinsize.
Various augmentations are done on images such as rectification, centering, scaling, rotation, mirroring and translation. Due to hardware limitations, we studied WPOD-NET architecture and decided to use pre-trained weights trained on the dataset mentioned above. The average accuracy obtained on all the dataset is 91%. According to the WPOD_NET results, the suggested strategy performs significantly better than previous methods in complex datasets with LPs collected at severely oblique viewpoints while maintaining good resultsinmorecontrolleddatasets.
The above discussed methods work well in different scenarios. As per discussed, edge detection algorithm requires low computation power, but may not work well in unconstrained scenarios. While YOLOv4 is known for real time applications but struggles to detect small sized objects on the other hand WPOD-NET works well with small, oblique and distorted license plate images and in unconstrained scenarios but requires high computation
[3] Zhenbo Xu, Wei Yang, Ajin Meng, Nanxue Lu, Huan Huang, Changchun Ying, and Liusheng Huang, “Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline”, School of Computer Science and Technology, University of Science and Technology of China,Hefei,China(2018).
[4] Arpitha D, Archana T, Rajashree Y G, Priya G, “Automatic License Plate Recognition for Real-Time Videos”, Visvesvaraya Technological University Belagavi, Karnataka.
[5] V Gnanaprakash, N Kanthimathi, N Saranya, “Automatic number plate recognition using deep learning”, Bannari Amman Institute of Technology, Department of Electronics and Communication Engineering, Sathyamangalam, Erode, Tamilnadu, India, ICCSSS2020.
[6] Muhammad Tahir Qadri, Muhammad Asif, “Automatic Number Plate Recognition System for Vehicle Identification Using Optical Character Recognition”, 2009 International Conference on Education Technology and Computer.
[7] Joseph Redmon, Ali Farhadi, “YOLO9000: Better, Faster,Stronger”,CVPR2017.
[8] Prof.Amit Kukreja, Swati Bhandari, Sayali Bhatkar, Jyoti Chavda, Smita Lad, “Indian Vehicle Number Plate DetectionUsingImageProcessing”,Apr-2017.
[9] Ibtissam Slimani, Abdelmoghit Zaarane, Wahban Al Okaishi, Issam Atouf, Abdellatif Hamdoun, An automated license plate detection and recognition system based on waveletdecompositionandCNN,Array,Volume8,2020.
[10] M. Jogin, Mohana, M. S. Madhulika, G. D. Divya, R. K. Meghana and S. Apoorva, "Feature Extraction using Convolution Neural Networks (CNN) and Deep Learning,"
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056 Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN:2395-0072
20183rdIEEEInternationalConferenceonRecentTrends in Electronics, Information and Communication Technology(RTEICT),2018.
[11] Lubna,N.Mufti,andS.A.A.Shah,“AutomaticNumber Plate Recognition:A Detailed Survey of Relevant Algorithms,”Sensors,vol.21,no.9,p.3028,Apr.2021.
[12] J.-S. Chou and C.-H. Liu, “Automated Sensing System for Real-Time Recognition of Trucks in River Dredging Areas Using Computer Vision and Convolutional Deep Learning,”Sensors,vol.21,no.2,p.555,Jan.2021.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page929