International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
Dept. Of Electronics and Telecommunication Engineering, TPCT’s collage of engineering , Osmanabad, Maharashtra, India. ***
Abstract In this paper review work, we have tried to develop a novel way to improve the structure of a speech test during a speech, and to measure clear speech will be removedfromtheconfusingspeechlimit.Automaticspeech recognitionconsistsofasoundspeechspectrumusingFast FourierTransformaswellasathoughtfulreductioninthe volumeoftheaudiosoundfromtheaudiosound.Usingthe MATLAB software the audio reduction algorithm is developed to store audio speech data in half-time and calculate the spectrum of various sizes using Fourier Transform, reduce noise in audio speech, and recreate retrospectivespeechduringhighperformance.FastFourier (FFT).
Keywords –SpeechandvoiceEnhancement,Spectral noise Reduction, FFT, Sound Measurement, IFFT, Spectrograms.
Acleanandclearspeechsignalislinkedtotheamountof soundinspeechdevelopment.Therearemanywaystomake a speech signal without a clamor signal. In many places Phones and cell phones get noisy air Domains like cars, airports, roads, trains, stations. Therefore, we attempt to eliminate the clamor signal by using a spectral reduction method. The main purpose of this paper is for real-time devicetoreduceordecreasebackgroundsoundwithavisual speechsignal,thisiscalledspeechdevelopment.Varietyof languages of speech are present, in that background noise loweringspeech.Applicationslikemobilecommunicationcan be learned a lot in recent years, speech improvement is required. The purpose of this speech development has to reversethenoisewhichinputfromanoisyspeech,likeasthe speechphaseoraccessibility.Itisoftenhardtoremovethe background sound without interrupting the speech, therefore,theexitofthespeechenhancementsystemisnot allowedbetweenspeechcontradictionandnoisereduction.
There may be other techniques same as to Wiener filtering,wavelet-based,dynamicfilteringandopticaloutput remainausefulmethod.Inordertoreducethespectral,we mustmeasuretheclamorspectrumandreduceitfromthe clamorous acoustic spectrum. Completely this approach, there are the following three scenarios to consider: sound adds speech signal and sound is not related to a single channel in the market.During thispaper,weattemptedto reduce the audio spectrum in order to improve distorted speech by using spectral output. We have described the
methodtestedintheactualspeechdataframeintheMATLAB area.ThesignalswereceivefromRealspeechsignalsarea website used for various tests. Then we suggest how to remove noise between the average noise level and the spectrumnoise.
Ingeneral,onlyonemediumsystemissetupbasedona varietyofspeechdataandunwantedscreamingthat,itworks indifficultsituationswherenopreviousclamorintelligenceis available.Genresoftenassumethatsoundisstablewhenever thespeechisalert.Theyusuallyallowfordisturbedsound during speech operations but in actual manner, when the soundisnotmoving,theperformanceofthespeechsignalsis greatlyincreased
Manyadditionalvariationsofthevariousconclusionsare designedtoimprovespeech.Theoneweareusingisthought tobetheendofthephantomrelease.Thistypeworkswithin thescopeofthespreadandcreatesthehopethatthehelp cycle is said to be due to the phantom additon sound and clamor phantom. The action is specified within the image belowandcontainstwomaincomponents.
ConvolutionalDenoisingAutoencoder(CDAE)Promotes the same function of default encoders by adding convolutionalencodinganddecodinglayers.CDAEhasa2D layoutinthedialogandadjuststheinputtothe2Dalignment structure using the embedded space and the desktop as showninthepicture.Thus,inthestudyweproposed,Sofrom thismethodwecanproposethattheCDAEisbest suitedfor speechdevelopmentwhichis showninEq.
(3),onanyothermapincluded, hi=f(Wi*α+ai)(3) where, the process of conversion and the value of bias is Measuringthebackgroundofinthespectrum.
Reducetospectrumnoisefromthesoundspeechspectrum
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
Theproposedmethodofnoisereductionisprovidedfor visualremovalthatreliedonthereductionofthebackground sound level and the development of the speech signal. Evaluate the volume of sound enhanced by reduced visual acuityandthetypeofsoundreductionrecommended.
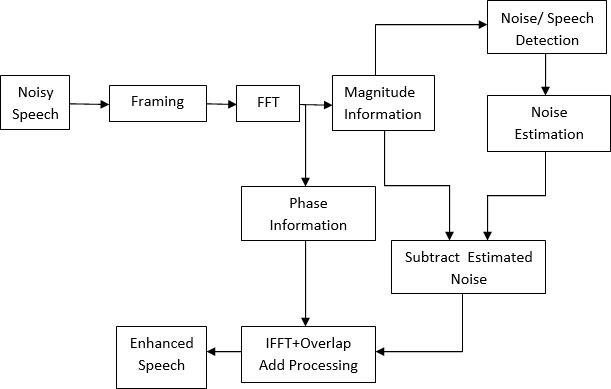
Assumingthatx(n)canbesoundandthemodifiedspeech signalisconsideredtobex(w)isasoundsignalspectrum willbe,N(w)thespectrumofratedintervalsandtherangeof speech processed by Y (w)and the pure speech signal the first is y (n). therefore, the processed spectrum as to the unpollutedspeechsignalwillbeprovidedasfollows:
Y(w)=X(w)-N(w)
Next Drawing Speech Block Impression By Spectral Removal.
Thespectrumsoundcannotbecalculatedinadvance,but it will be about the time for some instance speech is not present within the sound speech. When the people are speaking,oneshoulddefinitelypausetotakeadeepbreath. Wecanincludethesegapswithinspeechsignaltobalancethe background.
Wecancalculatetheaveragesizewhichiscalculatedfor anyframeinthelastfewseconds
After removing, all data of spectral signal which is appear unlikelyin positivevalues Somechancesareavailablefor removingunwantedparts.Fourierconversions,usingsection segments directly from the Fourier conversion unit, and additionaladditionsaremadetoreconstructthespeechrate withinthetimezone.
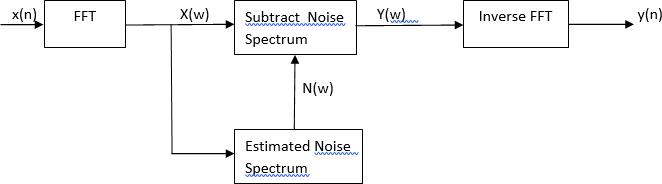
The basic idea will be to reduce the noise from the given signali.e-inputsignal:
Y(w)=X(w)-N(w)
Suggestworkflowandsimulationresults
Here,wecancreateacontinuousoutputsignal.Every frameis50%overwhelmed.FFT(FiniteFouriertransform) isusedineveryframe.
FFTsareoftenusefulindeterminingasignalhiddenin anoisytimezoneinpartsoffrequency.ThefunctionsY= FFT(x)andy=IFFT(X)suggestthealternatingrotation giventhevectorslengthNby
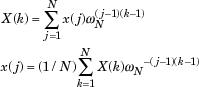
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
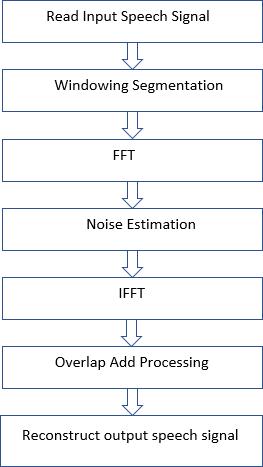
TheOverlapadd-onmethodisusedtointerruptandkeep thesignalsintosmallersegmentstomaketheprocesseasier. Thescatteringmethoddependson:(1)signaldecodeinbasic parts,(2)theprocedureofeverypart,(3)reassemblingthe cleared parts in an additional speech. In order to execute domain of frequency process to reduce visibility, it’s importanttodividetheconstantwisdom signalspeech into compact fragments which is called by frames. After completingprocedure,theframesarethenreassembled.
Theflowchartaboveshowstheproposedmethod,which involves collecting audio speech information and passing throughawindowtoextractexistingartobjectswithinthe ClamoroussignalandusetheFFTalgorithmthatdetectsthe phaseandmagnitudeoftheaudiosignal,duringwhichthe Technology focuses onthesize of the clamor to producea different refined speech signal. By using the type of visual reductionthenoiseismeasuredandreducedbythevalueof therequiredmagnitude.ThenusetheIFFTalgorithmandthe overlapaddstheprocesstowishforarefinedexpressionin thetimezone.
Thefollowingtestsareusedusingscreaming:Computer, trainsound,andcaraudiousingthisAWGNsoundproduced. Everyframeis50%spacedFFTisapplied.Inparticular,the quality of speech that is consistent with the test of comprehension test is held to judge the quality of sound speechthatisimprovedbystandardvisualremovalandthe proposednoiseremovalmethod.Audio-typeaudiobasedon visualdeletionandspeechmodificationcreatedbyactivated
waveforms and spectrogram. Different sound level with soundspeechsignalisgeneratedusing3typesofshouting.
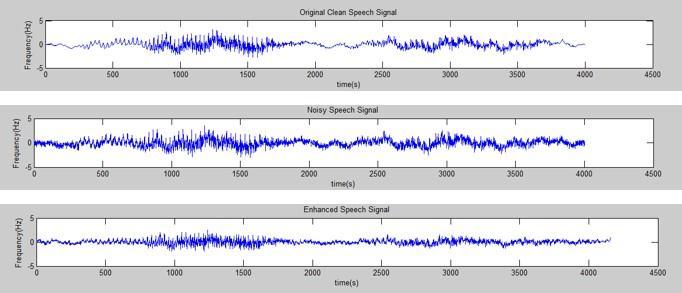
TheresultoftheaudiofilebuiltintoMATLAB
Fig 3: Results of speech enhancement: Noisefreespeech Noisyspeech EnhancedspeechusingSSmethod
3.1 Results of Spectrogram:
Fig(4)Cleanspeechsignalspectogram
Fig(5)Spectrogramofnoisyspeechsignal
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
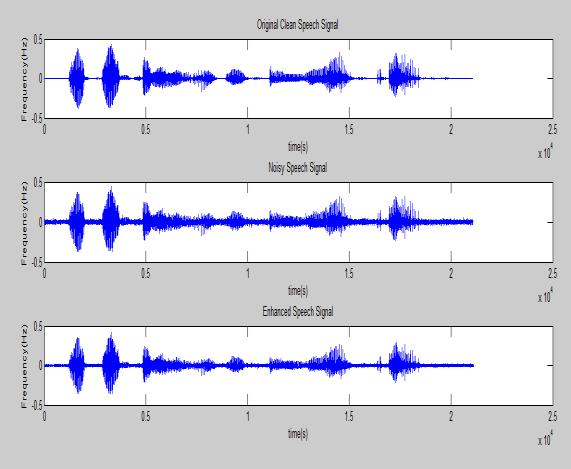
Fig(8)cleanspeechsignal
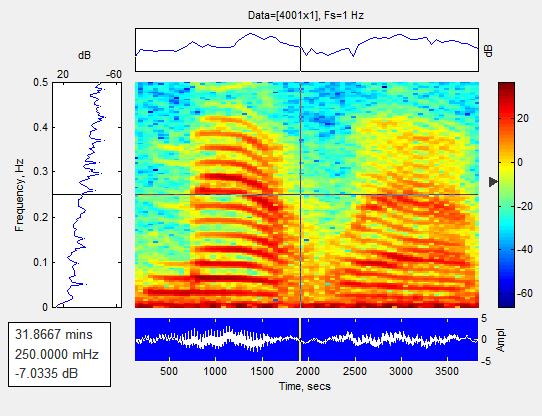
The above fig.6 shows the different colors of the spectrogram, while the red and yellow colors show two dissimilarenergylevel.Allofthesoundgiveninputsignals are full color of a very strong force due to the screaming patternassociatedwithbeinglargeyellow,redtomedium power,andblacktoasmallnumberwithalmostzeropower. Starting mainly from the effects at the exact time of the speechsignal,theeffectoftheshoutingcycle.Bycombining Fih.5withFig.6,theeffectastoclamorisreduced.
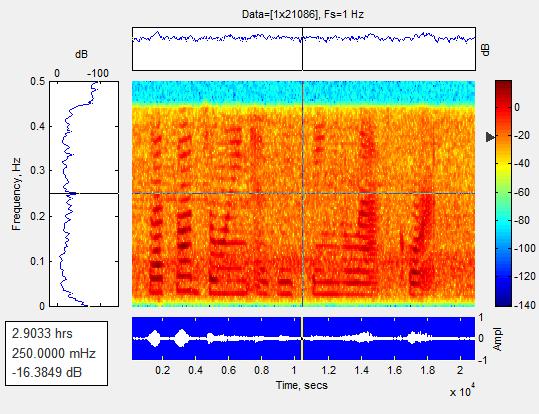
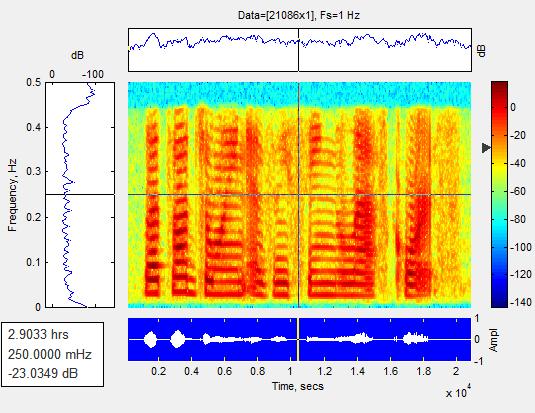
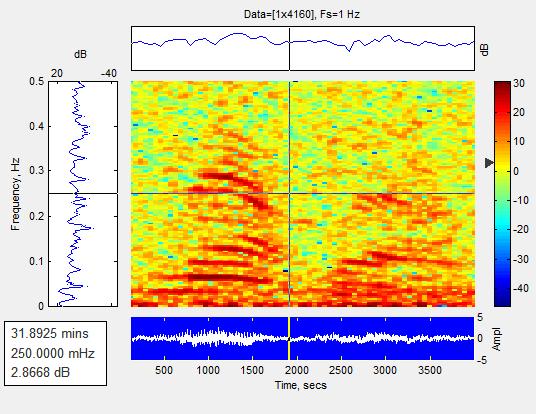
Fig 7: Results of speech enhancement: Cleanspeech Noisyspeech
EnhancedspeechbySSmethod
Fig(9)noisyspeechsignal
WhenmatchingFigure9withFigure10,thenoiseeffect decreased.Anotherinterestingtestoftheproposedalgorithm isseenincontrasttothespectrogramresultsfoundinFigure 9andhereanadditionalnumberofyellowlinesleftoutthe female speech signal suffering from high frequency. This provesthatawoman'svoicecanhaveaveryhighfrequency whenseparatedfromamaletone.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
Signalsoffemale speech background Level(dB) Noise Levelin (dB) Reducedlevelof noise
TrainNoise(at0dB) 3.6448 -4.852 8.4968
TrainNoise(at5dB) -15.1722 -17.0717 1.8995
TrainNoise(at10dB) -25.5382 -41.2185 15.6803
Malespeechsignal NoiseLevelin (dB) NoiseLevelin (dB) NoiseReduced level
TrainNoise(at0dB) -3.9138 -6.2895 2.3757
TrainNoise(at5dB) -22.4948 -19.3090 3.1858
TrainNoise(at10dB) -26.1571 -31.5079 5.3508
FromReducednoiselevelformale,Itwillbefound the amplitudestagesofmaleandfemalesoundgettinginputand outputdifferent.Thisindicatesthatithasasignificanteffect on sound speech. It promotes the clamor reduction phase. Thistypeofspectralreductioncreatesasignalofspeechbut also of shouting. Noise reduction was not properly guaranteedandcanbeguaranteedifseparatedbyinputand output.
TheClamorStageoftheinputandoutputspeechsignal andamplitudereductionupdatesaredifferentfromusingthe table.Table1showsthebackgroundstagedivisionforthe maleandfemalespeechsignalsite.
Inthispresentationpaperitishelpfultodevelopabetter spectralreductionalgorithm.Ithasrecentlybeenobservedin the fictional results that the suggested type significantly reduceslownoisecomparedtothealgorithmofmanyways toreducevisibility.Thistypeofspeechcausesthesignaltobe visible but is accompanied by a negative screaming. The soundisnotverylowanditisverylowcomparedtoinput andoutput.Theseforceswillalsobeadjustedandexpanded toaccommodatestaticnoise.Fromthistypeofdomaindesign wehavereached70%andthatwecanbuildthissystemfor embedded organizations that are subject to speech processing or communication purpose. For better comparisons, we showed as results and therefore
spectrogramsastoclear,soundandpreparedspeech.Delete thesite-preparedspeechsentence.
[1] S. Kamath, and P. Loizou, A multi-band spectral subtraction method for enhancing speech corrupted by colorednoise,ProceedingsofICASSP-2002,Orlando,FL,May 2002. R. Nicole, “Title of paper with only first word capitalized,”J.NameStand.Abbrev.,inpress.
[2]S.F.Boll,Suppressionofacousticnoiseinspeechusing spectralsubtraction,IEEETrans.onAcoust.Speech&Signal Processing,Vol.ASSP-27,April1979,113-120.
[3]M.Berouti,R.Schwartz,andJ.Makhoul,Enhancementof speech corrupted by acoustic noise, Proc. IEEE ICASSP , WashingtonDC,April1979,208-211.
[4]H.Sameti,H.Sheikhzadeh,LiDeng,R.L.Brennan,HMMBased Strategies for Improvement of Speech Signals Embedded in Non-stationary Noise, IEEE Transactions on SpeechandAudioProcessing,Vol.6,No.5,September1998. International Research Journal of Engineering and Technology(IRJET)e-ISSN:2395-0056
[5] Yasser Ghanbari, Mohammad Reza Karami-Mollaei, Behnam Ameritard “Improved Multi-Band Spectral Subtraction Method For Speech Enhancement” IEEE InternationalConferenceOnSignalAndImageProcessing, august2004.
[6]Pinki,SahilGupta“SpeechEnhancementusingSpectral Subtraction-typeAlgorithms”IEEEInternationalJournalof Engineering,Oct2015.
[7]S.Kamath,Amulti-bandspectralsubtractionmethodfor speech enhancement, MSc Thesis in Electrical Eng., UniversityofTexasatDallas,December2001.
[8] Ganga Prasad, Surendar “A Review of Different ApproachesofSpectralSubtractionAlgorithmsforSpeech Enhancement”CurrentResearchinEngineering,Scienceand Technology(CREST)Journals,Vol01|Issue02|April2013| 57-64.
[9]LalchhandamiandRajatGupta“DifferentApproachesof Spectral Subtraction Method for Speech Enhancement” InternationalJournalofMathematicalSciences,Technology andHumanities95(2013)1056–1062ISSN22495460.
[10]EkaterinaVerteletskaya,BorisSimak“Enhancedspectral subtractionmethodfornoisereductionwithminimalspeech distortion”IWSSIP2010-17th InternationalConferenceon Systems,SignalsandImageProcessing.
[11]D.Deepa,A.Shanmugam“SpectralSubtractionMethod ofSpeechEnhancementusingAdaptiveEstimationofNoise
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 09 | Sep 2022 www.irjet.net p-ISSN: 2395-0072
with PDE method as a preprocessing technique” ICTACT JournalOfCommunicationTechnology,March2010,Issue: 01.
[12]M.Berouti,R.Schwartz,&J.Makhoul,“Enhancementof SpeechCorruptedbyAcousticNoise,”Proc.ICASSP,pp.208211,1979.
[13] Prince Priya Malla, Amrit Mukherjee, Sidheswar Routary,GPalai“Designandanalysisofdirectionofarrival using hybrid expectation-maximization and MUSIC for wireless communication” IJLEO International Journal for LightandElectronOptics,Vol.170,October2018.
[14] Pavan Paikrao, Amit Mukherjee, Deepak kumar Jain “Smart emotion recognition framework: A secured IOVT perspective”, IEEE Consumer Electronics Society, March 2021.
[15] Amrit Mukhrerjee, Pratik Goswani, Lixia Yang “DAI basedwirelesssensornetworkformultimediaapplications” MultimediaTools&Applications, May2021,Vol.80Issue11, p16619-16633.15p.
[16] Sweta Alpana, Sagarika Choudhary, Amrit Mukhrjee, AmlanDatta“Analysisofdifferenterrorcorrectingmethods for high data rates cognitive radio applications based on energydetectiontechnique”,JournalofAdvancedResearch inDynamicandControlSystems,Volume:9|Issue:4.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page894