International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Abstract - Code clones in software development are types of fragments of code that must be identified by using a clone detection tool. This paper discusses reviews on different code-clone detection techniques, code reuse or cold cloning issues, and ROP (Return Oriented Programming). Review of “clone detection precision using machine learning techniques” which thereby seeks to eliminate false-positive clone classes outlinedby a clone recognition tool. Pyclone: “A Python code clone test bank generator” which testifies a new tool that will take akernel of ‘source code’(python) & give rise to Type1, Type2, and Type3 code clones in python. After reviewing these papers, we have found some research gaps that are briefly mentioned in this review paper. Code clones or code reuse could create a serious issue when it comes to software maintenance,testing, and debugging also makes the system vulnerable so, it may be easily exploited by unauthorized people. Also, it culminates that there exist numerous types of research to identify type1, type2, type3, and type4 clones.However, there is a necessity to remodel new methodologies using proper tool support in order to discover all types of emulations cooperatively and mitigate code cloning and code reuse attacks. Moreover, it is also essential to propose more methodologies andtechniques to streamline the expansion of Program Dependency Graph (PDG) while dealing with the recognition of type4 clones. Also, cloning issues like exploitation of code, and code reuse attacks are discussed along with approaches to mitigate code reuse attacks.
Keywords - ML, Clone Detection, Decision Tree, AST, Code Reuse, ROP (Return Oriented Programming), Malware
Inthesoftwaredevelopmentindustry, therecenttrendis to reuse existing code [17], libraries, components, etc. by replication,andfixingfragmentsofsourcecodeisageneric pursuit. The outcome of theseactivities is replicated code i.e., codeclones.Codeclonesintroduceissuesinthe form of bugs, and complexity in software maintenance. The developer’s habit of replicating code, rather than refactoringcode,leadstocodeclonesinprograms.Cloning and reusing of code are similar terms in software
development.Thedeveloper performing the codereuse task is not awareof furthercomplexity,which is much moredifficulttohandle.
Inthisbusyworldeverybodywantstocompletetheirtask ontimeandbecauseofpeerpressuredeveloperalsotakes the easy route to accomplish the development of the software by using code cloning and code reusing. Also, nowadays most of the shared libraries and components are alreadyavailable by the framework and compiler. If similar software is already developed in thiscase, we try toreuseexistingcodeandintroducenewsoftware.
Above all the scenario is hands down to develop the software but it may introduce a large number of issues and vulnerabilities to the software where e hacker or another unauthorized person who is used to those libraries and know to flow of code can easilyexploit the software. And that is not good practice for software development.
Recently, the log4j library, one of the most popular libraries of java, was exploited by a malicious code injection by a hacker. This negatively impacts development, and other java packages were also at high riskofdisclosure.
Code reuse attacks and code cloning are one of the major concerns in software development practices nowadays. It is important to mitigate code reuse attacks and code cloning by using randomization techniques and early recognition of codereplicas during the development of code.
This is a well-known research topic in software development intending to detect such replicated fragmentsofcodeinthesoftware.
Also, if two code fragments are similar with minor modifications they are called code clones. These code clonescancausetroubleinthesoftwaremaintenanceand debuggingprocess.
e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
BeginningwithPyclone,whichwascomposedtogenerate codeclonesbasedon akernelofpythonfilesconcededto it. Withthe vision of mutation of AST (AbstractSyntax Tree)iscreatednexttothekernelfiles.
Types of clones:
Type-1: includes clones that are identical code snippets,neglectingwhitespacesandcomments.
Type-2: include clones with only disparities in using parameters & formatting style. (i.e., literals, type, literals,variable,function)
Type-3: include clones with variations including modifiedstatements.
Type-4: include clones that don’t comprehend the identical structure (syntactical more precisely) and stillinstigatesimilarfunctionalities.
Original code Type 1 code Type 2 code Type 3 code Type 4 Code
Ina machinelearning-based technique,the author picked “19cloneclassmetrics”thatdepictdiversedescriptionsof cloned andnon-cloned classes and a decision treebinary classifier to facilitate filtering out clone classes from the originalcloneresultgiven byaclonedetectiontool.Here, Asupervisedlearningalgorithm“DecisionTreeAlgorithm” is used that produces decision nodes via the information gain attained from the value of each feature. The classification is made by accepting the data through the treefromthetoptoaleafnode.
a) “Pyclone”: This can create a documentedno. of codeclonescenteredattheobjective oftransformationof Abstract Syntax Tree (AST) created from the kernel records.Inthispaper,theveryfirststepistoexaminethe kernel files & create ASTs for the same. “An AST is basically a tree representation of abstract code structure. If the code is dissimilar amid the two projects,the ASTs willalsocontrast.”
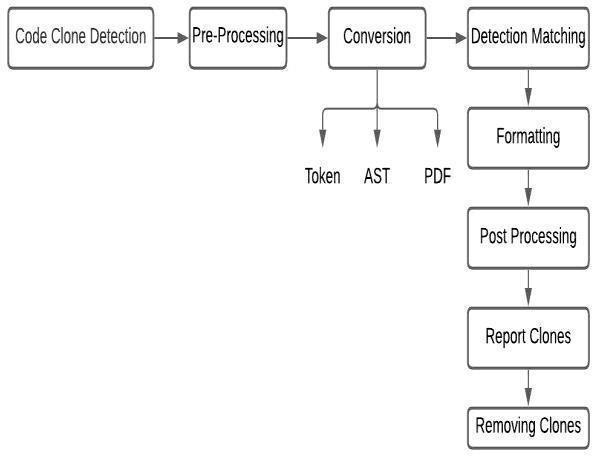
Inordertocompilethepythoncodeinto bytecode,python uses a compiler associated with AST. A Python package called Astor is also used by Pyclone. Astor permits Pyclone to develop ASTs based on justifiable Python files andalterthesame.
intx=9; intx=9; inty =0; while( y<=x) {y++; }
double inty=0; //Com 9; intb=0; a = (18/2); doubleb= 0;
ment while( y<=x)
inta= doublea= 9; doubleb= 0; while(b <=a){ b+1= 1.0; }
while(b <=a){ {y++; } } b +1= 1.0; }
while(a <=b){ b++;
In this paper, we will review two techniquesof clone detection and mitigation of code reuse attacks and brieflydiscusstheirflaws.
class P: def_init_(self, x): self_x = x def get_x(self): return self_x def set_x(self, x): self_x = s
class P: def_init_(self, x): self_x = x def get_x(self): returnself_x
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Here,thegenerationofType3,Type2,andType1,has been accomplished by using the Abstract Syntax Tree method.
Nevertheless, they did not compare their methodology with a prevailing clone detection technique using any renownedclonebenchmark.
b
)”Clone detection using Machine Learning”,19clone metrics are chosen that accumulate diverse emulated andnon-emulatedclasses.
The methodology of this research consists of an “Experimental framework, Dataset and clone validation, error measures, Model Training, Tuning, and evaluation of the clone filter on clones in another language.”
There are two Research Questions in this paper. The first is the effectiveness of a Machine Learning clone filtertoadvanceclonedetectionprecision &thesecond is the effectiveness of applying a Machine Learning clonefilterdirectedfromonetoanotherlanguage.
The ML clone filter is efficient in refining clone recognition precision. When integrated decision tree filter into i-clones displays that itcan improve i-clones accuracyfrom0.94to0.98.
A large training data set is required in the directionto generate a more comprehensiveclone filter. Also, the developed metrics may not efficiently capture the featuresofclonesinadifferentlanguage.
Originalprecision=0.94,Filter’sprecision =0.98.
c)”Search-based software engineering (SBSE) in clone- detection optimization”,
Tofindasetofparametervalues,twoapproachesused SBSEthatmaximizesthe contract amongst a collective of clone detection tools.[7][8] Also, Eva-Clone, is an approach using a genetic algorithm to discover the alignmentspaceofclonedetectiontoolsandtoachieve the best parameter backgrounds. However, Eva- Clone gives undesirable results in terms of clonequality.
d) “Tree-based clone detection”, creates an abstract syntax tree (AST) for each code fragment and then leverages tree matching algorithms to detect similarsubtrees.[9]
e) “Deep-learning-based-research” in software engineering, researchers have recently used deep learning to solve problems in software engineering.[12],[13],[14],[15]
In a study of Pyclone, the whole system works on the injection-based framework and due to the class of this framework, it could be probable that by injecting novel codeornewlinesofcodeorremovingthem,anaccidental clone could be established with an unintended code fragment.
As,“Type1andType2clones” areforthright,astheyare nearly indistinguishable replicas of the novel code. Nevertheless, the detection of “Type 3 or Type 4 clones” mighthingeontheperformanceofthetoolsforretrieving clones, and the specified tool may not define “Type 3 or Type4”assimilarasthewaythetoolhasgeneratedthem, withthisclonemaybemisidentifiedor notcaught atallin caseofType3,Type4incaseofusingPyclone.
In our study of the Machine Learning Technique, the author only focuses on replicas of Type 1 to Type 3 becauseoftheirsyntacticsimilarity.Butthemainproblem is with Type 4 which is spotless in this paper. Moreover, the finding of this very research is centered only on Python “open-source project” (Django) & Java “opensource project” (J Free Chart). Also, the efficiency of the filter is associated witha Decision Tree Model. Dataset or Datapointsshouldbeincreasedtoinstruct andassess the model by using more balanced & larger ground reality data,moreprecisemodelsarenormallyanticipated.
Instead of using a Decision Tree, more sophisticated techniques like Random Forest should be taken into consideration. It might present an improved implementationthanthepresentmodel.
a) Vulnerability of Code: Vulnerability isconsidered as themajorconcerninsoftwaredevelopment which is introduced in the code because of badcoding habits, practice, not following coding standards, and also using the code block without knowing the functionalityofthatblockofcode.
b) Code Reuse Attacks: Anothermajorissuein software development is caused by the copying of malicious code or the libraries in the software. ROP (Return oriented programming) is a technique where an attacker introduces a set of instructions called
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
gadgets to exploit the code. It is depending on the flowofmemorydesignwherecodeisexecuted.
c) Exploitation of Code: Malicious code leads to exploit the software by using exploitation techniques hacker hacks or theft the important information from the user’s system. This is also another major issue that is causedbycodecloning.
d) Complex to Manage Code: Code cloningis not only introducing the major issue or vulnerability in the system/software but also makes complex to manage thesoftwareinthefuture.Hardtodebugandtrackthe buginthesystem.Causethecodeisnotwrittenbythe concerneddeveloper.
1. Code Randomization: CodeRandomization consist of two phases the first phase also consists of two-part one isused to extract the information from function blocksandflowcontrol,andthesecondpartisusedto separate the code segment. The second phase makes shufflestheblockofcodeandfunction.
2. Optimization of Code: It is a technique tomodify the code to reduce the size code, and consume less memory during execution. By detecting the code cloning level,wecanabletooptimizeandrefactorthe codeso,complexityandvulnerabilitycanberesolved.
3. Other techniques which are used to reducethe code reuse attacks are: ILR[18],MARLIN [17], STIR [19], XIFER[21],DROP[20], CFL [24], CCFIR, ROPDEFENDER[23]
Type 3 - Type 4 clones are much more complex to weight and resolve as well. As, in Pyclone, the filter was fairly suitable for “Type 1 and Type 2” replicas in contrast to “Type 3 and Type 4”. Also, using an injection-based framework isunsuitableif wewanttoavoidaccidental or unintended clones. In, the ML technique, Pyclones illustrates that the filter was not efficient in the other programming languages & future work is required proceedingthisproblem.
Also, by using the Randomization technique and optimization technique which are mentioned above we can able to reduce the code reuse attacks and early detection ofcode cloning which helps to refactor thecode andreducethecomplexity.
By increasing the data points, we can get more accurate results,andalsobyusingamoresophisticatedtechnology we can increase the performance and accuracy of our model. In the software industry, there aretools out there thatcancatchType3cloneseffectivelybutstillType4isa bigissueinthesoftwareworld.
[1] Qurat Ul Ain1,Wasi Haider Butt1, Muhamad Waseem Anwar1,Farooque Azam1,AndBilalMaqbool1RecentAdvancem ents inCode CloneDetectionTechniquesandTools
[2] Schaeffer Duncan1, Andrew Walker1, Caleb DeHaan1, Stephanie Alvord1,Tomas Cerny1, and Pavel Tisnovsky2 Pyclone: A Python Code Clone Test Bank Generator
[3] Liuqing Li, He Feng, Wenjie Zhuang, Na Meng and Barbara Ryder CCLearner: A Deep LearningBased CloneDetectionApproach
[4] Vara Arammongkolvichai, Rainer Koschke, Chaiyong Ragkhitwetsagul, Morakot Choetkiertikul, Thanwadee Sunetnanta Improving Clone Detection PrecisionusingMachineLearningTechniques
[5] Hannes Thaller, Lukas Linsbauer, Alexander Egyed Towards Semantic CloneDetectionviaProbabilistic SoftwareModeling
[6] HAIBO ZHANG 1 AND KOUICHI SAKURAI 2 “ A Survey of Software Clone Detection From Security Perspective”
[7] T. Wang, M. Harman, Y. Jia, and J. Krinke, “Searchingfor betterconfigurations: Arigorous approach to clone evaluation,” in Proceedings of the 2013 9th Joint MeetingonFoundationsofSoftwareEngineering
[8] C. Ragkhitwetsagul, M. Paixao, M. Adham, S. Busari, J. Krinke, and J. H. Drake, Searching for Configurations in CloneEvaluation – A Replication Study. Cham:SpringerInternationalPublishing,2016
[9] I. D. Baxter, A. Yahin, L. Moura, M. Sant’Anna, and L. Bier, “Clone detection using abstract syntax trees,” in Proceedings of the International Conference on SoftwareMaintenance,1998.
[10] [10] L. Jiang, G. Misherghi, Z. Su, and S. Glondu, DECKARD: scalable and accurate tree-based detectionofcodeclones,2007.
[11] H.Sajnani,V.Saini,J.Svajlenko,C.K. Roy, and C.V.Lopes,“SourcererCC: Scalingcodeclonedetection tobigcode,”
[12] A. N. Lam, A. T. Nguyen, H. A. Nguyen,andT. N. Nguyen, Combining deeplearning with information retrievaltolocalizebuggyfilesforbugreports,2015
[13] S. Wang, T. Liu, and L. Tan, Automatically learning semantic features for defect prediction, in Proceedings of the International Conference on SoftwareEngineering,2016.
[14] X. Gu, H. Zhang, D. Zhang, and S. Kim, Deep API learning, in Proceedings of the ACM International Symposium on Foundations of Software Engineering, 2016
[15] M. White, M. Tufano, C. Vendome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection,” in Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering,2016
[16] G.E.Hinton,S.Osindero,andY.W.Teh,“Afast learning algorithm for deepbelief networks,” Neural Computing,2006.
[17] A. Gupta, J. Habibi, M. S. Kirkpatrick, and E. Bertino, "Marlin: Mitigating Code Reuse Attacks Using Code Randomization," in IEEE Transactions on Dependable and Secure Computing, vol. 12,no. 3, pp. 326-337, 1 May-June 2015, DOI: 10.1109/TDSC.2014.2345384.
[18] J.Hiser,A.Nguyen-Tuong,M.Co,M.Hall,andJ. W. Davidson, “ILR: Where’d my gadgets go?” in Proc. IEEESymp.SecurityPrivacy,2012,pp.571–585.
[19] R. Wartell, V. Mohan, K. W. Hamlen, and Z. Lin, “Binary stirring: Self- randomizing instruction addresses of legacy x86 binary code,” in Proc. ACM Conf.Comput.Commun.Security,2012,pp.157–168.
[20] P. Chen, H. Xiao, X. Shen, X. Yin B. Mao, and L. Xie, “DROP: Detecting return-oriented programming malicious code,” in Proc. 5th Int. Conf. Inf. Syst. Security,2009,pp.163–177
[21] L. V. Davi, A. Dmitrienko, S. Nurnberger, and A.R. Sadeghi, “Gadge meif you can: Secure and efficient adhoc instruction-level randomization for x86 and arm,”in Proc. 8th ACM SIGSAC Symp. Inf. Comput. Commun. Security,2013,pp.299–310.
[22] V.Pappas,M.Polychronakis,andA.D.Keromytis, “Smashing the gadgets: Hindering return-oriented programmingusingin-placecoderandomization,”inProc. IEEESympSecurityPrivacy,2012,pp.601–615.
[23] L. Davi, A.-R. Sadeghi, and M. Winandy, “ROPdefender: A detection tool to defend against returnorientedprogramming attacks,” in Proc. 6th ACM Symp. Inf.Comput.Commun.Security,2011,pp.40–51.
[24] T. Bletsch, X. Jiang, and V. Freeh, “Mitigating code-reuse attacks with control-flow locking,” in Proc. 27th Annu. Comput Security Appl. Conf., New York, NY, USA.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page576