International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Shadab Ali1, Mr. Rahul Gupta2
1M.Tech, Computer Science and Engineering, SR Institute of Management & Technology, Lucknow, India
2Associate Professor, Computer Science and Engineering, SR Institute of Management & Technology, Lucknow ***
Abstract - In today's world, there is an ever-increasing number of apps that may be executed on a computer, as well as an ever-increasing number of network services. Inaddition, there is an ever-increasing number of network protocols. As a consequence of this, it is of the utmost importance to take into consideration certain practical security principles. Several various proposals on methods ofintrusiondetectionthat make use of data mining techniques have been offered in order to fulfill the goal of providing security for computer systems and networks. These approaches have been suggested in a variety of different ways. Different methods, such as outlier analysis, unsupervised data analysis, and supervised data analysis, all fit within these paradigms and may be used in diverse contexts. It is a well-known fact that certain data mining approaches cannot differentiate between various forms of cyber attacks. This is a truth that is well recognized. As a direct result of this, we have adopted the practice of using a Multi-Stage Intrusion Detection Method with the intention of removing this particular vulnerability. This technique integrates the unsupervised, supervised, and outlier identification approaches into an overarching framework. This strategy tries to improve performance and accuracy of detection by reducing the amount of false alarms generated throughout the process of detecting known and unknown attacks as well as increasing the number of known and unknown assaults that are detected. The amount of false alarms that are produced during the process shouldbe kept to a minimum in order to achieve this goal. During the course of this inquiry, we have used the NSL-KDD dataset, in addition to the KDD Corrected dataset, and the GureKDD dataset. All of these datasets are related to KDD.
Both the GBBK method and our proposed outlier strategy, which we refer to as GBBK+, provide the same results, as we found out when we compared the two approaches to one another. On the other hand, our method requires a far less amount of time and effort than the GBBK method does. Even when the comparison of the items in question is not essential, the unsupervised categorization approach known as k-point will continue to compare the things in question in an iterative way. In order to accomplish this goal, the amount of features that are used throughout each iteration will be cut down until they reach a point that will be designated as the k-point+. The proposedtechnique performedbetter thancurrent approaches in terms of the difficulty of the task, the amount of time that was necessary, and the accuracy of the detection. This conclusion is based on empirical evidence. According to the findings of the comparison, the newly proposed method was
discovered to be superior to the methods that were currently being used in the organization.
Key Words: GBBK+, k-point+, Multi-Stage Intrusion DetectionSystem,outlierdetection,SVM;
Becauseofthe exponential riseinthenumberofprogram thatareusedonacomputerandtheexcessivegrowthinthe number of network services, basic security rules are necessaryatthispoint in time. Thisisthecaseasa direct consequenceofbothofthesetrends.Thisisthecasesince therearenowmorenetworkservicesavailablethanthere ever have been in the past. The nature of the computergenerated virtual world makes the topic of computer securityaveryessentialone.Thisisowingtothefactthat the computer creates a virtual environment. Computer security is vulnerable to attacks and intrusions, which compromiseatleastoneof thethreeprimary purposesof computer security, which are to maintain the data's confidentiality, integrity, and availability [1]. Computer security is vulnerable to attacks and intrusions because it was not designed to prevent them. Because it was not intended to prevent assaults and incursions, computer security is very venerable to both types of threats. An intrusion detection system is a method that monitors the activitiesthataretakingplaceinsideacomputernetworkor system.Theseactivitiesmightincludehackingattemptsor other malicious behaviour. It is possible to do this monitoringeitherautomaticallyormanually(IDS).Within the context of this process, indications of breaches in conventional computer security processes or policies are investigatedandevaluated."intrusiondetectionsystem"is what the letters IDS stand for in the acronym "IDS." This abbreviationreferstosoftwarethatinitiatestheprocessof automaticallydetectingintrusions.AlsoknownasSIEM.The monitoringofthehostistheresponsibilityofahost-based intrusiondetectionsystem,moreoftenreferredtoasanIDS. Thesolepurposeoftheintrusiondetectionsystem(IDS)is touncoverhostilebehavioronthemonitoredhostbyusing localanalysis.Ananalysisiscarriedoutbyanetwork-based intrusion detection system on the data that was collected fromaparticularareaofthenetwork.Thisdatacomesfrom thenetworkitself.Itdoesthisbymonitoringthenetworkin order toidentifyany behaviors thatmay beseenasbeing suspicious.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
People are often oblivious to the fact that there is a difference between recognizing incidents of abuse and recognizinginstancesofintrusion,whichissomethingthat happens on a consistent basis. This kind of thing happens rather often. The identification of malicious behavior that arises only from inside an organization is referred to as misuse, while the identification of hostile behavior that arises from outside an organization is referred to as intrusiondetection.
Pattern-matching "Based Detection" refers to the act of analysingpreviouslysaved strings or patterns to evaluate whether or not they indicate the presence of a previously identifiedthreattothestringthatisnowbeingmonitored. Thisisdoneinordertoascertainifthereareanypotential flaws or not. Matching strings is the basis for this straightforward and efficient approach. The information about the current packet is compared to the pattern list, which is preserved, and then the list is used to determine whetherornotthecurrent packetshouldbeprocessed. It seldomtriggersfalsealarmssinceitconsistentlyoperatesin accordancewithasetofcriteriathathasbeenestablished beforehand.Inspiteofthis,itisunabletolocateeither the new assault pattern or the previous pattern with the modifications made to it. If the prior pattern is "connect proxy,"andifitisrecordedintheruleset,butifyoutweakit slightlysothatitreads"proxyconnect,"thenthedetection systemwon'tbeabletofindit.Similarly,ifthepreexisting patternis"connectproxy," andifitisrecordedintherule set. Another illustration of this would be if the preceding pattern was "connect proxy," and the rule set maintained that pattern. One example of a pattern-matching network intrusiondetectionsystemthatisabletoidentifyassaults thathavehappenedinthepastistheSnortsystem.
Clusteringisawaytoorganisedataitemsintogroupsbased onthesimilaritiesinthequalitiesofthoseobjects,andit'sa technique called "clustering." The data objects that are includedinsidetheclusterhaveahighdegreeofsimilarity withoneanother,whilethedataobjectsthatarecontained withindifferentclustersshareahighdegreeofdissimilarity with one another. A method known as clustering may be usedtodatathathasnotbeenlabelledinanyway.Afterthe clusters have been established, the objects that were a member of the same cluster will have a characteristic in commonwithoneanotherthatwillsetthemapartfromthe objectsthatwereapartofotherclusters.Itisnecessaryto beabletodifferentiatebetweendifferentthings,hencethe labelofanitemthatispartofaclusteroughttobethesame asthelabeloftheclusteritself.Thenumberofassumptions that are made, which happens a lot, is that the number of harmlessthingsisalotlowerthanthenumberofeveryday items. Therefore, if we are to accept this assumption, the
larger cluster needs to be categorized as belonging to the normal class, while the smaller cluster needs to be categorisedasbelongingtotheevilclass.Thisisbecausethe smaller cluster has a greater likelihood of causing harm. Havingsaidthat,therearetimeswhenthisisnotthecase. For example, in the case of a distributed denial of service (DDOS)attack,thelargerclusterbelongstoanattackclass that violates the assumption that motivates us to use a supervised technique to label the clusters that were generatedbyunsupervisedtechniques.Thismotivatesusto useasupervisedtechniquetolabeltheclusters.Thisserves asadrivingforceforourdecisiontolabeltheclustersusing supervisedmethods.
Inordertobuildamodel,thesubfieldofmachinelearning knownassupervisedanomalydetectionnecessitatestheuse of training data. In addition to receiving the information necessary for the training, you will also get a selection of examples that you are free to use while you are going throughthecourse.Everysingleoneoftheseoccurrencesis madeupoftwodifferentcomponents:aninputrecordand the value that is supposed to be created as the desired output for that record. These are the only two things that makeupthisoccurrence.Consequently,newdatathathave not yet been given a label may be categorised with the assistance of this training dataset. This is because of the aforementionedreason.Obtainingadatasetthatistypicalin allaspectsisnotastraightforwardprocesstocarryout,asa matteroffact.Ittakesalargeamountoftimetoaccomplish theprocessesofcollectingeachthing,manuallycategorising it,andthen,afterfinishingthosephases,assigningtheitema statusthatiseithernormalorhazardousbasedonitsprior condition.Dependingonthespecificsofthesituation,those whoaretakingpartintheactivitiesthatarehappeningright atthisverynowmayormaynotbeawareoftheattacksthat aretakingplace.Thestrategythatisbasedonanomalies,as opposed to the one that is based on signatures, is the one thattendstobethemosteffectivewhenitcomestoguarding against unknown threats. This is because anomalies are easiertoseethansignatures.Creatingatrainingdatasetthat is made up entirely of labels is one of the most difficult aspectsofcarryingoutsupervisedanomalydetection.Thisis one of the most demanding aspects of carrying out supervised anomaly detection. Consideration need to be giventothisasoneofthemostimportantissues.Ithasbeen demonstrated that both unsupervised anomaly-based detectionandtheidentificationofnewassaultswithoutany priorknowledgeoflabeledtrainingdatahavethepotential tobesuccessfulsolutionstothisproblem.Moreover,bothof theseapproachesdo not requirethepresenceofa human supervisor.Unsupervisedandsupervisedanomalydetection algorithmsareintegratedandputtouseinacertainmanner in order to identify the features of each kind of incursion. Thisisdonebycombiningthetwotypesofalgorithms.This is done with the main goal of obtaining a greater level of
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
performance in mind, thus that should be the driving motivationbehindit.
Matlab was used so that a number of simulations of the procedure could be carried out. Using this method, the managementofrecordsthatincludeduplicateinformation orvaluesthataremissingmaybeaccomplished.Inorderto locatetheabnormalityinthedatasetthatwasreferredtoas theoutlier,theprocedurethatwassuggestedwasputinto practise.Thedatasetispartitionedintoseveralsubsets,each ofwhichisestablishedonthebasisoftheclasslabelthatwas applied to the record. The final result of the method is createdbycompilingallofthefindingsthatwereacquired fromtheindividualcomputationsofanindexforanoutlier andcombiningthemtogether.
The strategy that is recommended makes use of three distinctmethods,andtheirnames,inorder,areFindNNk(), FindRNNk(),andFindRNOFk().FindNNk(),FindRNNk(),and FindRNOFk()arethenamesofsomeofthemethodsthatmay beutilisedinthissituation().Weareabletocalculatethe amountoftimethatwillberequiredtofinishtheFindNNk() functionbyfirsttakingintoaccountthedistancethatexists betweennitemsandthenlocatingthekobjectsthathavethe shortestdistancebetweenthem.Thisallowsustodetermine the amount of time that will be required to complete the FindNNk() function. Because of this, we are able to determine the amount of time that will be necessary to completethefunction.Thisfunction'sdegreeofdifficultyis represented by the notation O(n+n), which stands for the phrase"operationplusnumber."Thisisasadirectresultof thestrongconnectionthatexistsbetweenthesetwoaspects. TheamountoftimerequiredtocompletetheFindRNNK() method is inversely proportional to the total number of distinctitemsthatareexamined,whichisrepresentedbythe notation n*k. The complexity of each item beyond the nth oneisrepresentedbythenotationO(n*k*n),whichstands for "n times k times n." The documentation for the FindRNOFk() function states that it has been given a complexity grade of O, which indicates that it is quite straightforward to use (n). The procedure that was explained has a level of temporal complexity equal to O (n+n+(n*k*n)+n),whichisthesamethingasO.Becauseof this,thedifficultyoftheoperation,measuredintermsofthe amount of time it takes, is equivalent to O. (n2). When viewedfromanasymptoticperspective,ontheotherhand, the level of complexity shown by our approach as well as thatofthepriormethodissame.Ontheotherhand,ifour approachisusedtoaverylargenumberofn,itwillprovide resultsthataresuperiortothoseobtainedbyothermethods.
According to the research that has been conducted, the outlierdistributionisreportedtooccuranywherebetween 10and20percentofthedataset.ThenumberTservesasthe criterionfordetermininghowmanyofthedatapointsare regardedtobeanomalous.Thefindingsofthisexperiment haveledustotheconclusionthatTshouldhaveavalueof 0.99,andwegotatthisconclusionasaconsequenceofthe following:Theequationindicatesthatthereisaconnection betweenthethresholdvalueTandthenumberofoutliers, andthatthisconnectionhasarelationshipthatisinversely proportional to T. In other words, the relationship is inverselyproportionaltoT.
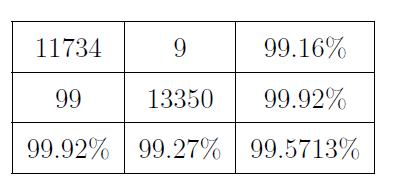
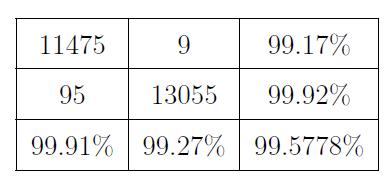
We constructed a predictionmodel that wasbased on the supportvectormachinesothatwecouldassesswhetheror notthemethodthatwassuggestedforspottingoutliersis effective(SVM).Thedatasetwasanalyzedusingthismodel both before and after the outlier was removed from the image.Thisallowedforacomparisonofthetwostatesofthe data.Theresultsonbothinstanceswereexactlywhatwas desiredandexpected.Boththeprocessoftrainingthemodel andtheprocessofvalidatingthemodel,which bothmake useofthetrainingandvalidationmethods,makeuseofthese twodistinctiterationsofthedatasetsthroughoutthewhole ofbothprocesses.Beforetheoutlierwastakenintoaccount, theconfusionmatrixofthemodelisshowninTable1,asit was originally. After taking into account the results of removingtheoutlier,theconfusionmatrixofthemodelcan beseeninTable2.Table1displaysthemodel'sconfusion matrixinitsuncorrectedform,whichmeansthatitdoesnot takeintoaccounttheoutlier.
Table-1: Confusionmatrixoftheoriginaldatasetpriorto SVM-basedoutlierelimination.
In all, there were 25192 cases in the NSLKDD Train20 dataset. The model correctly categorised 25084 of those examples.Thereisa98.3percentchancethatthisiscorrect. Asaresultoftheremovaloftheoutliers,thetotalnumberof occurrenceswasreducedto24634,andoutofthatnumber, only24530instanceswereabletobeidentifiedaccurately.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Table-2: ConfusionmatrixoftheinitialdatasetafterSVM removaloftheoutlier.
Tables1and2eachcontainagraphicalrepresentationofthe True Positive (1st cell), the False Negative (2nd cell), the Precision (3rd cell), the False Positive (4th cell), the True Negative(5thcell),theNegativePredictedValue(6thcell), the Sensitivity (7th cell), the Specificity (8th cell), and the Accuracy (9th cell). When compared to one another, the accuracyofthemodelthatdoesnotincludetheoutlierhasa much higher level of precision than the accuracy of the modelthatdoesincludetheoutlier.Toputitanotherway, the training error of the model that does not include the outlierismuchlowerthanthetrainingerrorofmodelsthat doincludetheoutlier. Becauseof this,theaccuracyofthe modelisimprovedwhenitisappliedtodatasetsthatdonot includeanyoutliersincomparisontodatasetsthatdohave outliers.Thedatasetoughtnottohaveanyextremevalues, often known as outliers, since doing so will make it less likelythatthemodelisbiassedorthatithasbeenoverfitto thedata
Inordertocreateadirectcomparisonoftheamountoftime requiredtocomputeGBBKandtheamountoftimerequired by the suggested technique GBBK+, we carried out 7500 instances at intervals of 500 seconds. A depiction of how well the performanceofthe total numberofinstancesdid maybeseenalongtheX-axisofFigure-1.TheY-axisprovides anapproximateestimateoftheamountoftime,measuredin seconds,thatwillberequiredtofinishtheexecutionofthe algorithms. This estimate is shown as a range. When comparedtothe method thatwassuggested,thegraph in Figure-1illustratesthattheamountoftimethatisrequired byGBBKconstantlyincreasesinproportiontothenumberof instances that are being processed. This is the case even though the proposed method was intended to reduce the amount of time that is required. When compared to the methodthatwasproposed,thisismuchdifferent.Evenwhen thereisagreaternumberofinstancestohandle,theGBBK+ approach completes the task in a shorter amount of time comparedtotheGBBKalgorithm.Thisisduetothefactthat theGBBK+approachhasareducednumberofrounds.
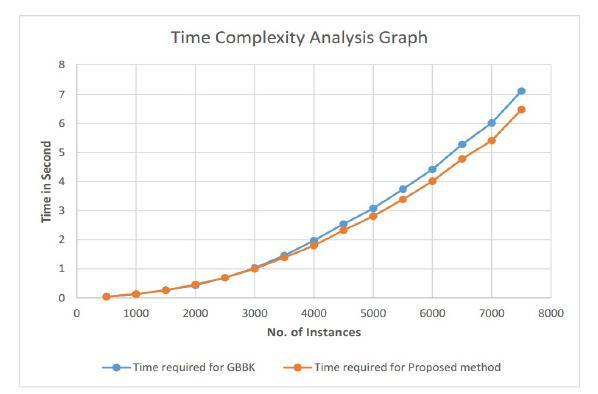
Figure-1: Comparisonoftheexecutiontimesforthe proposedtechniqueGBBK+andGBBK
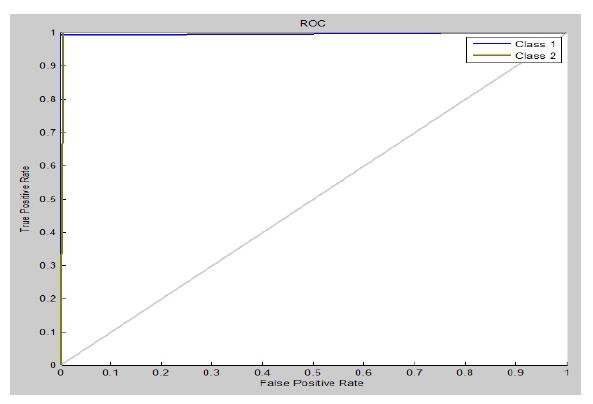
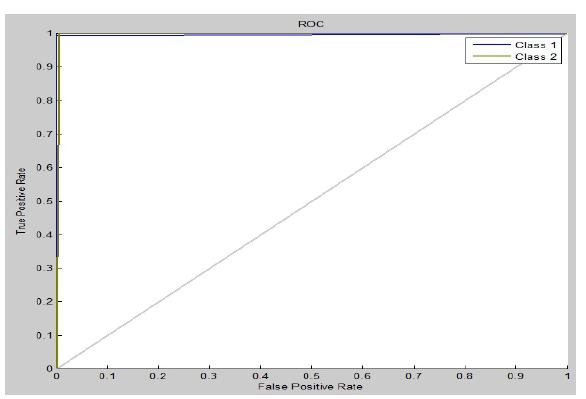
TheReceiverOperatingCharacteristicisoneofthemetrics thatisutilisedintheprocessofestablishinghoweffective thecategorizationsystemis.Thisstatisticisknownasthe ReceiverEfficiency(oftenabbreviatedasROC).Figure2isa depictionoftheROCthatwasobtainedbyapplyingSVMto theNSLKDDdataset.Youcanseethisrepresentationbelow. TheTruePositiveRate(TPR)isshownalongtheY-axis of thisgraph,whiletheFalsePositiveRate(FPR)isdisplayed alongtheX-axis.Thesetworatesarepresentedintheform ofapercentageeach.ForthepurposeofillustratingtheROC curve,a plotoftheTPRvstheFPRmaybeused.Afterthe eliminationoftheoutlier,whichmadeitpossibletoutilise the dataset for analysis, the ROC of the NSLKDD Train datasetcanbeseeninFigure3,whichshowstheresultsof thestudy.Theperformancethatwasperformedbythefigure thatcamebeforethisfigurewassomewhatmoreimpressive thantheperformancethatwasproducedbythisfigure.
Figure-2: Priortooutlierelimination,theROC
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Figure-3: ROCafterremovalofoutlier
The dataset of network connections that does not include anyoutliersandisshowninFigure-4istheonethatisused astheinputforthisstage.Atthisstageoftheprocedure,the objectiveistocomeupwithacollectionofclustersthatare based on the similarity measure. This phase will result in k+1clusters,withthek+1stclustercomprisingtheobjects thathavenotyetbeenassignedaclassificationandtheother k clusters having the identical qualities in every instance. Theunsupervisedclassificationmethodk-point,whichwas published in [3,] carried out the needless comparison of objectsinaniterativemannerbydecreasingtheamountof characteristicswitheachpassingiterationuntilitreached thethreshold.[Citationneeded][Citationneeded][Citation needed] [Citation needed] [Citation needed] [Citation needed][(minimumattribute).Anotherdisadvantageofthis methodisthatthetypicaldatalabelisassignedtothecluster thatcontainsthemostinformation,evenifthisisnotalways thecase.Forinstance,thelargerclusterthatisusedinaDOS assaultisseenasbelongingtothemalevolentclassrather thantheordinaryclass.ThisisbecauseaDOSassaultisan aggressivekindofattack.
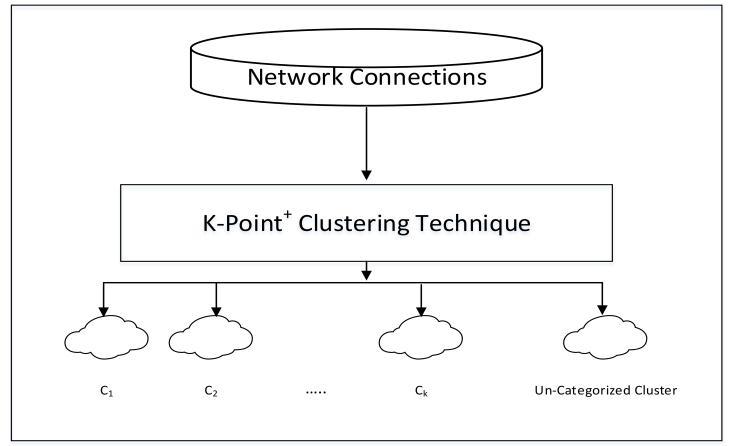
Therecommendedapproach,whichhasbeengiventheterm k-point+,hasthereforebeenchangedtohandlethesetwo limits as a consequence of this situation. The proposed methodbeginswithunlabeleddataanddevelopsaclustering listbasedontheunderlyingstatisticalfeaturesofthedata. This list is then used to cluster the data. These k random itemswerechosenfromthedataset,andtheotherobjects were clustered around them using the find sim similarity function().Thismethodwillultimatelyproducekplusone clustersfromthewholeunlabeleddatasetthatyouprovide.
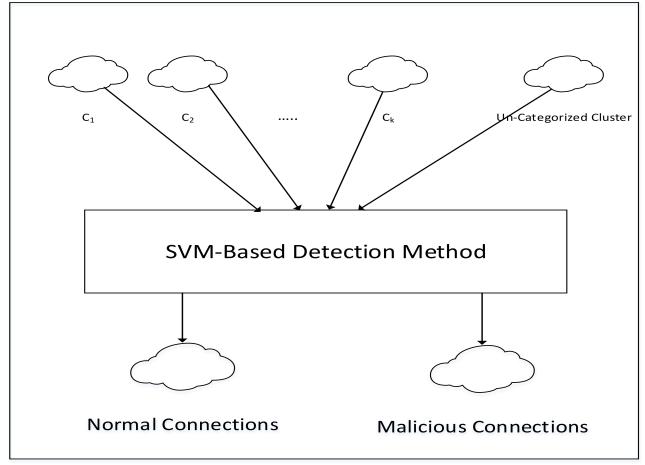
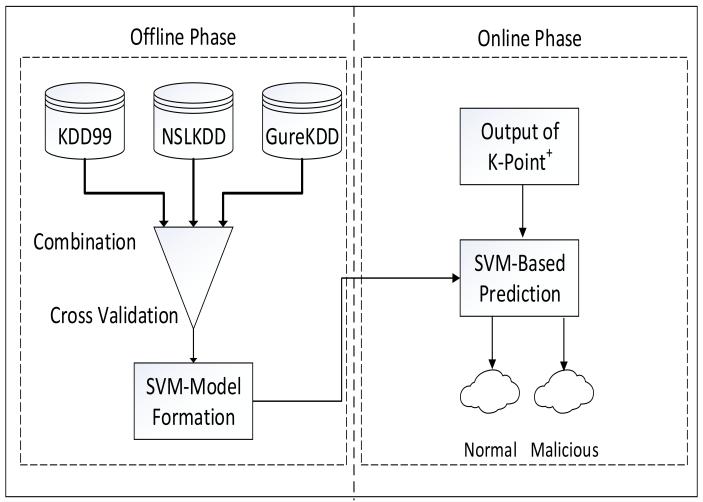
In the process of supervised classification, a classification model known as the Support Vector Machine (more often abbreviatedasSVM)isused.Supervisedclassification.This model is trained by using a training dataset that includes labelsinordertomakepredictions.Whenanunsupervised classifier is applied to a set of data, the result is a list consisting of k+1 clusters. Following that, the aforementioned list is fed into a supervised classifier in ordertobeutilisedasaninput.Toaccuratelytagthefirstk clustersonthislist,youneedtocorrectlyestimateonlyone randomobjectfromthroughoutthefullcluster.Ifitcanbe shown that this seemingly innocuous piece constitutes an attack,thenthewholeclusterwillbelabelledasanassault. If,ontheotherhand,itisnotfoundoutthatthisarbitrary itemispartofanassault,thentheclusterisrecognisedas being typical, as shown in Figure 5. However, the k+1th cluster comprises items that have not been categorised; hence,itisimportanttoevaluateeachobjectinthiscluster inordertoselectthelabelforeachindividualobjectonan individualbasis.Becauseofthis,thetotalnumberofobjects thatareincludedintothemodelisequivalenttokplusthe totalnumberofobjectsthatarecontainedinsidethecluster that is denoted by k plus one. Once the label of the first item'skpredictedlabelhasbeenassignedasthelabelofthe kcluster,thelabeloftheclusterthateachindividualobject wasinitiallyamemberofisthenassignedastheclasslabel ofeachindividualobject.Thisisdoneafterthelabelofthe firstitem'skpredictedlabelhasbeenassignedasthelabelof thekcluster.Followingtheapplicationoflabelstoeveryone oftheproducts,thenextstepistoclassifythemaseithersafe to use or potentially dangerous. The intrusion detection system will not interfere with the regular connections; nevertheless, it will either prevent malicious connections from being made or notify the administrator to their presenceiftheyarediscovered.Itispossibletodissectthe operation of a support vector machine into two distinct components,bothofwhichareshowninFigure6.Thefirst phase is referred to as the online phase, while the second phaseisreferredtoastheofflinephase.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Thephaseoftesting,whichoccursatthesametimeasthe periodinwhichthegameisbeingplayedonline.Duringthis stageoftheprocess,wewillproduceourforecastsbyusing themodelthatwebuiltduringthephasebefore,whichtook place outside of the computer. The k-point+ methodology produceacollectionofclustersthataremadeupentirelyof featuresetsasitsendproduct.Thisoutputisthensenttoa supportvectormachineinorderforittodoananalysisonit. After that, the data are run through a support vector machinesothatapredictionmaybemadeabouttheclass labelofthefeaturesets.Wemadeuseofabinaryclassifier SVMmodel,whichsplitsthewholeoutputintotwounique classes: the normal class, which is comprised of usual networkconnections,andtheauthorisedcategory.Weused this model to classify the data. This is the model that we basedourworkoffof.Thesecondcategoryisknownasthe "malevolent class," and it contains all potentially harmful network connections. This category is referred to as "bad actors." These connections are either prohibited or a notificationissenttoanadministratoraboutthem.
This model illustrates a multi-stage intrusion detection system that is dependent on outlier, unsupervised, and supervised detection methodologies to identify potential threats. These techniques of detection are included in the modelthathasbeensuppliedforyourperusal.TheGBBK+ algorithm produces results that are superior to those providedbytheGBBKtechniqueintermsofboththeamount oftimethatisrequiredandtheprecisionofthedetection. Thisisthecasewhetherwearetalkingabouttheaccuracyof thedetectionortheamountoftime.Whenyoulookatthe twoalgorithmssidebyside,youwillseethatthisisthecase. Aftertheoutliersinthedatasethavebeenlocatedwiththe assistance of the outlier detection method, the outliers themselvesareremovedfromthecompilationofthedata. Due to the fact that the previous technique was able to successfully eliminate all outliers from the dataset, the performanceofthesecondlevelwassignificantlyimproved as a direct consequence of this. Utilizing the method of findingdataoutliersisonewaytosuccessfullyhandlehighdimensional data in the shortest amount of time possible duringprocessing.Thismaybeaccomplishedbyusingthe techniqueofrecognisingdataoutliers.
Whenthek-pointmethodwasfirstdeveloped,therewerea number of restrictions and drawbacks that needed to be solvedbeforeitcouldbeconsideredaviableoption.Thekpoint+strategythatwedevelopedallowedustosuccessfully completethistask.Theempiricalinvestigationcametothe conclusionthattheperformanceofk-point+issuperiorthan thatofk-pointintermsofthedegreeofdifficultyofthetask, theamountoftimethatisrequired,andtheaccuracyofthe detection.Themodelthathasbeensuggestediscapableof detecting attacks with low frequency as well as high frequency,aswellasassaultsthatareknownandassaults that are unknown. Additionally, the model can identify assaultsthatareknownandassaultsthatareunknown.In additiontothat,themodelisabletodifferentiatebetween attacksthatareknownandthosethatareunknown.
1. Rebecca Bace and Peter Mell. Nist special publication on intrusion detection systems. Technicalreport,DTICDocument,2001.
2. BehrouzA.Forouzan.IntroductiontoCryptography and Network Security. McGraw-Hill Higher Education,2008.
3. Prasanta Gogoi, DK Bhattacharyya, Bhogeswar Borah, and Jugal K Kalita. Mlh-ids: a multi-level hybridintrusiondetectionmethod.TheComputer Journal,57(4):602{623,2014.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
4. Richard P Lippmann, David J Fried, Isaac Graf, Joshua W Haines, Kristopher R Kendall, David McClung, Dan Weber, Seth E Webster, Dan Wyschogrod, Robert K Cunningham, et al. Evaluatingintrusiondetectionsystems:The1998 darpalineintrusiondetectionevaluation.InDARPA Information Survivability Conference and Exposition,2000.DISCEX'00.Proceedings,volume 2,pages12{26.IEEE,2000.
5. EdwinMKnoxandRaymondTNg.Algorithmsfor miningdistancebasedoutliersinlargedatasets.In Proceedings of the International Conference on Very Large Data Bases, pages 392{403. Citeseer, 1998.
6. SridharRamaswamy,RajeevRastogi,andKyuseok Shim. E_cient algorithms for mining outliers from largedatasets.InACMSIGMODRecord,volume29, pages427{438.ACM,2000.
7. Wen Jin, Anthony KH Tung, Jiawei Han, and Wei Wang. Ranking outliers using symmetric neighborhood relationship. In Advances in Knowledge Discovery and Data Mining, pages 577{593.Springer,2006.
8. MarkusMBreunig,Hans-PeterKriegel,RaymondT Ng,andJ• orgSander.Lof:identifyingdensity-based local outliers. In ACM sigmod record, volume 29, pages93{104.ACM,2000.
9. PedroCasas,JohanMazel,andPhilippeOwezarski. Unada: Unsupervised network anomaly detection usingsub-spaceoutliersranking.InJordiDomingoPascual,PietroManzoni,SergioPalazzo,AnaPont, andCaterinaScoglio,editors,NETWORKING2011, volume6640ofLectureNotesinComputerScience, pages40{51.SpringerBerlinHeidelberg,2011.
10. CharuAggarwalandSYu.Ane_ectiveandefficient algorithm for high-dimensional outlier detection. TheVLDBJournalTheInternationalJournalonVery LargeDataBases,14(2):211{221,2005.
11. Graham Williams, Rohan Baxter, Hongxing He, SimonHawkins,andLifangGu.Acomparativestudy ofrnnforoutlierdetectionindatamining.In2013 IEEE13thInternationalConferenceonDataMining, pages709{709.IEEEComputerSociety,2002.
12. NeminathHubballi,BidyutKr.Patra,andSukumar Nandi. Ndot: Nearest neighbor distance based outlierdetectiontechnique.InPatternRecognition andMachineIntelligence,volume6744ofLecture NotesinComputerScience,pages36{42.Springer BerlinHeidelberg,2011.
13. Zuriana Abu Bakar, Rosmayati Mohemad, Akbar Ahmad,andMustafaMatDeris.Acomparativestudy foroutlierdetectiontechniquesindatamining.In Cybernetics and Intelligent Systems, 2006 IEEE Conferenceon,pages1{6.IEEE,2006.
14. Kingsly Leung and Christopher Leckie. Unsupervised anomaly detection in network intrusiondetectionusingclusters.InProceedingsof the Twenty-eighth Australasian conference on Computer Science-Volume 38, pages 333{342. AustralianComputerSociety,Inc.,2005.
15. TianZhang,RaghuRamakrishnan,andMironLivny. Birch: an e_cient data clustering method for very large databases. In ACM SIGMOD Record, volume 25,pages103{114.ACM,1996.
16. Kalle Burbeck and Simin Nadjm-Tehrani. Adwice anomaly detection with real-time incremental clustering.InInformationSecurityandCryptology ICISC 2004, volume 3506 of Lecture Notes in ComputerScience,pages407{424.SpringerBerlin Heidelberg,2005.
17. Daniel Barbar_a, Julia Couto, Sushil Jajodia, and NingningWu.Adam:atestbedforexploringtheuse ofdatamininginintrusiondetection.ACMSigmod Record,30(4):15{24,2001.
18. MAliAyd_n,AHalimZaim,andKG• okhanCeylan. A hybrid intrusion detection system design for computernetworksecurity.Computers&Electrical Engineering,35(3):517{526,2009.
19. JiongZhangandMohammadZulkernine.Ahybrid network intrusion detection technique using random forests. In Availability, Reliability and Security,2006.ARES2006.TheFirstInternational Conferenceon,pages8{pp.IEEE,2006.
20. KaiHwang,MinCai,YingChen,andMinQin.Hybrid intrusion detection with weighted signature generation over anomalous internet episodes Dependable and Secure Computing, IEEE Transactionson,4(1):41{55,2007.
21. OzgurDepren,MuratTopallar,EminAnarim,andM Kemal Ciliz. An intelligent intrusion detection system(ids) foranomalyandmisusedetectionin computer networks. Expert systems with Applications,29(4):713{722,2005.
22. Zhi-SongPan,Song-CanChen,Gen-BaoHu,andDaoQiangZhang.Hybridneuralnetworkandc4.5for misuse detection. In Machine Learning and Cybernetics, 2003 International Conference on, volume4,pages2463{2467.IEEE,2003.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page2039