International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056


International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Saathvik Krishnan1, Shrijeeth S2
1Saathvik Krishnan, Dept. of computer science and engineering, Rajalakshmi Engineering College, Tamil Nadu, India
2Shrijeeth S, Dept. of computer science and engineering, Rajalakshmi Engineering College, Tamil Nadu, India ***
Abstract - A human posture and tracking system in which we utilize a deep learning model to fit in data from humans and then train the model to recognize a certain personality utilizing media pipelines. It may be usedas a security system in homes and businesses to prevent unwanted entrance. Pose Detection is a framework for creating multimodal audio, video, or any type of time series data. The Pose detection framework may be used to create an outstanding ML pipeline for inference models like TensorFlow and TFLite, as well as media processing routines Pose estimation from the video is critical for augmented reality applications such as overlaying digital content and data on top of the physical world, signing recognition, full-body gesture management, and even quantifying physical exercises, which will form the basis for yoga, dance, and fitness applications. A large number of possible positions, variable degrees of mobility, occlusions and a range of looks or clothes make creating an assessment for fitness applications, particularly tough. Incontrast to the Face Mesh and Pose detection Hand following pipelines, where we calculate the ROI from predicted key points, we expressly forecast two extra virtual key points for the human cause following that clearly depict the actual body rotation and measurement as the circle. So this application can be used for Home security applications and if built on a larger scale, it can be used in companies for high-profile security with extra facial recognition making it a more secure system.
Key Words: Media Pipelines, TensorFlow, Mobility, Occlusions, Pose detection, ROI, TFLite
People detection has long been a focal point of debate for many purposes in classical object detection. Using stance detectionandposetracking,computerscannowreadhuman bodylanguagethankstorecentadvancementsinmachine learning algorithms. These detections' accuracy and hardwareneedshavenowimprovedtothepointwherethey areeconomicallypractical.High-performingreal-timepose identification and tracking will deliver some of the most significantdevelopmentsincomputervision,hasaprofound impactonthetechnology'sprogress.Computervisiontasks likehumanpositionestimateandtrackingincludefinding, connecting, and following semantic key points. "Right shoulders,""leftknees,"or"vehicle'sleftbrakelights"area fewexamplesofsemantickeypoints.Theaccuracyofposture estimatehasbeenlimitedbythelargeprocessingresources
neededtoexecutesemantickeypointtrackinginlivevideo data.
HumanPostureTrackingandEstimatesisoneofthemajor research areas of computer vision and deep learning. The reasonforitsimportanceistheabundanceofapplicationsof this type of technology in our daily lives. Human pose skeletons usually represent the orientation of a person graphically.Thatis,itcanbeusedtoidentifythepersonality ofMannerism.Inessence,asetofpointscoordinatedcanbe usedtoshowapersonbylinkingthosepoints.Hereevery partinthephysicalstructureiscalledahinge,orvalidpoint. Avalidconnectionbetweentwopartsiscalledapair,butnot allcombinationsofpartsarevalidpairs.Variousapproaches to tracking and estimating human posture have been introduced over the years. These methods usually first identifyeachpartandthenformaconnectionbetweenthem tocreatethatparticularpose.
L. Sigal et al, They have displayed data that was gathered usingahardwaresetupthatcanrecordsynchronisedvideo and3Dmotionthatisaccurate.TheresultingHUMANEVA databaseshaveseveralparticipantscarryingoutaseriesof predetermined behaviours repeatedly. Approximately 40,000frames ofsynchronisedmotioncaptureandmultiviewvideo(producingoveraquartermilliontotalpicture frames) and an additional 37,000 time instants of pure motion capture data were gathered at 60 Hz. In order to evaluatealgorithmsfor2Dand3Dpostureestimationand tracking, a common set of error metrics is provided. Additionally,theyhavediscussedabaselineapproachfor3D articulated tracking that employs a comparatively conventional Bayesian framework with optimization through sequential importance resampling and annealed particle filtering.They investigatedvarious likelihood functions, previous models of human motion, and the implications of algorithm settings in the context of this fundamentalalgorithm.Theirresearchindicatesthatimage observationmodelsandmotionpriorsplaysignificantroles inperformance,andthatBayesianfilteringoftenperforms wellinamulti-viewlaboratorysettingwhereinitializationis possible.Thescientificcommunityhasaccesstothedatasets andthesoftware.Thisinfrastructurewillaidinthecreation offresharticulatedmotionandposeestimationalgorithms, serve as a benchmark for assessing and contrasting novel
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1937
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
approaches,andcontributetotheadvancementofthestateof-the-artinhumanposeestimationandtracking[1].
D.Mehtaetal,TheyhaveputforthaCNN-basedmethodfor estimating a 3D human body's posture from a single RGB photograph that overcomes the problem of models' poor generalizability when trained just on the incredibly little amountofpublicallyaccessible3Dposedata.Throughthe transferoflearntfeaturesandgeneralisationtoin-the-wild scenarios, they have demonstrated cutting-edge performanceonknownbenchmarksusingjustthecurrent 3Dposedataand2Dposedata.Additionally,anoveltraining set for estimating human body posture from monocular photosofactualpeoplewasprovided,withthegroundtruth being obtained via a multi-camera marker-less motion capturesystem.It enhances thediversityofposes,human look,clothes,occlusion,andviewsinthecurrentcorporaand allowsforawiderrangeofaugmentation.
Their 3D posture dataset exhibits superior in-the-wild performance than current annotated data, and is further enhancedinconjunctionwithtransferlearningfrom2Dpose data.Theyalsosuppliedanewbenchmarkthatincludesboth indoor and outdoor situations. In essence, they proposed that transfer learning of representations is essential for universal 3D body position estimation, together with algorithmicanddatacontributions[2].
L. Bourdev et al, Poselets, a novel kind of component presentedbythem,aredesignedtoformdenseclustersboth in the configuration space of keypoints and in the appearance space of picture patches. In this research, theycreateda novel poselet-based method for people detection.Theysimplyemployed2Dannotations,whichare significantly simpler for novice human annotators, as opposed to that work, which used 3D annotations of keypoints. A two-layer feed-forward network that has its weights set using the maximum margin method has been trained. Then, based on experimentally obtained spatial keypoint distributions, the revised poselet activations are groupedintomutuallycoherenthypotheses.Inordertooffer asegmentation,shapemasksarematchedtopictureedges and bounding boxes are predicted for each human hypothesis.With an average precision of 47.8 percent and 40.5 percent, respectively, on PASCAL VOC 2009, the resultant system is now the best performer on the job of persons detection and segmentation, to the best of theirknowledge[4].
L. Pishchulin et al. they have compared human activity recognitionmethodsthatareholisticandpose-basedona large scale using the "MPII Human Pose" dataset. Additionally,theyhaveexaminedthevariablesthataffectthe successandfailureofholisticandpose-basedapproaches.
The data in thisdataset was systematicallygathered from YouTube videos using a taxonomy of common human activities that includes 410 activities. Around 25K photos,
40Kannotatedpostures,andrichannotationsonthetestset are included. Over 1 million frames, 3D torso and head position,bodycomponentocclusions,andavideosamplefor eachpicture[5].
Z. Cao et al, They have provided a method for accurately identifyingthe2Dposesofseveralpersonsinaphotograph. The method learns to link body parts with people in the imageusingnonparametricrepresentationsknownasPart AffinityFields(PAFs).Nomatterhowmanyindividualsare intheimage,thearchitecturestoresglobalcontexttoenable a greedy bottom-upparsing phase thatachievesreal-time speedwhilemaintainingexcellentaccuracy.Twobranchesof the same sequential prediction method are used in the architecture to jointly learn the locations of the parts and theirassociations.OurapproachwonthefirstCOCO2016 keypoints challenge and, in terms of performance and efficiency,outperformsthepreviousstate-of-the-artresult ontheMPIIMulti-Personbenchmark[6].
Mykhaylo Andriluka et al. they has collected a comprehensivedatasetwithestablishedclassificationsfor morethan800humanactivities.Theimagescollectedcover a wider range of human activities than previous datasets, includingvariousleisure,professional,andhomeactivities, andcapturepeoplefromawiderrangeofangles.Foreach frame, weprovided adjacentvideoframestofacilitate the useofmotioninformation[7].
LeonidPishchulinetal.theyhavediscussedaboutthetaskof clearlyestimatingthehumanpostureofmultiplepeopleina real image. They proposed the division and labeling formulationofasetofbodyparthypothesesgeneratedbya CNN-based parts detector. Its formulation, which is an instanceofintegerlinearprogramming,implicitlyperforms non-maximum suppression of a set of sub-candidates and groupsthemtoformabodypartcompositionthatrespects geometricandappearanceconstraintsincrease[8].
N.Dalaletal,Theyinvestigatetheissueoffeaturesetsfor reliablevisualobjectrecognitionusingatestcaseoflinear SVM-basedpersondetection.Theyexaminedcurrentedgeand gradient-based descriptors and demonstrated experimentallythatgridsofHOGdescriptorsgreatlyexceed existing feature sets for human detection. They looked at howeachstageofthecomputationaffectedperformanceand came to the conclusion that fine-scale gradients, fine orientationbinning,somewhatcoarsespatialbinning,and excellent local contrast normalisation in overlapping descriptorblocksareallcrucialforsuccessfuloutcomes.The original MIT pedestrian database can now be separated almostperfectlyusingthenewmethod,thuswepresenta more difficult dataset with over 1800 annotated human photoswithawidevarietyofposesandbackdrops[9].
Alexander Toshev et al.they have suggested a method for estimating human poses based on Deep Neural Networks (DNN). Pose estimation is formulated as a DNN-based
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
regressionproblemforbodyjoints.Theyhavepresenteda cascadeofsuchDNNregressors,resultinginhighlyaccurate poseestimates[15].
J.Tompsonetal,theyhaveproposedauniquearchitecture that consists of a productive "position refinement" model that is trained to guess the joint offset location within a circumscribedarea ofthepicture. Toincreaseaccuracy in human joint position prediction, this refinement model is concurrentlytrainedincascadewithacutting-edgeConvNet model. We demonstrate that our detector beats all other methods on the MPII-human-pose dataset and that its varianceapproachesthevarianceofhumanannotationson theFLICdataset[18].
MatthiasDantoneetal.theyusedatwo-tieredrandomforest asacommonregressor.Thefirstlayeractsasanidentifiable andindependentclassifierforbodyparts.Thesecondlayer canpredictthelocationofjointsbytakingintoaccountthe estimatedclassdistributionofthefirstlayerandmodeling theinterdependenceandgeneraloccurrenceofparts.This leadstoa frameofposeestimationthatalreadyconsiders the dependencies between body parts for general localization[24].
YiYang etal.the orientation isrecorded bycombiningthe templatesofeachpart.Theydescribeageneralandflexible mixed model for capturing context-related co-occurrence relationshipsbetweenpartsandcomplementthestandard springmodelforencodingspatialrelationships.Inthispaper theyshowthatsucharelationshipcancapturetheidea of local rigidity. So they present experimental results on a standardposeestimationbenchmarkthatsuggeststhattheir approachisthelatestsystemforposeestimation[25].
Fangting Xia et al.they first train two fully convolutional neuralnetworks(FCNs),theposeFCNandthepartFCN,to provideinitialestimatesoftheposejointpotentialandthe semantic partial potential. Then, the two types are fused with a fully connected conditional random field (FCRF) to usethenewsmoothnesstermforsegmentjointstocreate semanticandspatialconsistencybetweenpartsandjoints. Torefinethepartsegment,therefinedposeandtheoriginal partpotentialareintegratedbythepartFCN,andthepose skeletonfeatureservesasanadditionalregularizationhint for the part segment. Finally, to reduce the complexity of FCRF,theyguidehumandetectionboxes,derivegraphsfor eachbox,andspeedinferenceby40times[26].
Cheol-hwan Yoo et al. It has been demonstrated that convertinganoriginalpictureintoahigh-dimensional(HD) feature is efficient for cacategorizingmages. In order to increase the face recognition system's capacity for discrimination, this research introduces a unique feature extractiontechniquethatmakesuseoftheHDfeaturespace. The local binary pattern may be broken down into bitplanes, each of which contains scale-specific directional informationofthefacialpicture,theyhavefound.Eachbit-
planehasanillumination-robustpropertyinadditiontothe intrinsiclocalstructureofthefacepicture.Theycreatedan HD feature vector with enhanced discrimination by concatenatingallofthedeconstructedbit-planes.
The HD feature vector is subjected to orthogonal linear discriminant analysis, a supervised dimension reduction technique, in order to miniminimize computational complexitywhilemaintainingtheintegratedlocalstructural information.Numerousexperimentalfindingsdemonstrate thatunderdifferentlighting,stance,andexpressionchanges, current classifiers with the suggested feature outperform thosewithothertraditionalfeatures[30].
Today, there are several models for performing pose estimation. Here are some methods used to estimate the pose: 1. Openpose 2. Posenet 3. Blazepose 4. DeepPose 5. Densepose 6. Deepcut
Model-basedapproachesaretypicallyusedtodescribeand deriveposesforthehumanbodyandrender2Dor3Dposes. Mostmethodsusetherigidkinematicjointsmodel.Inthis model,thehumanbodyisrepresentedasaunitwithjoints andlimbsthatcontainsinformationaboutthestructureand shapeofthekinematicbody.Therearethreetypesofmodels formodelingthehumanbody:
Both2Dand3D posture estimatesareperformed usingakinematicmodel,oftenknownasaskeleton model. This flexible and intuitive human body model includes various joint positions and limb orientationstorepresenttheanatomyofthehuman body. Therefore, skeletal posture assessment models are used to capture the relationships between different parts of the body. However, kinematic models have limitations in expressing texture or shape information.This can be seen in Fig.3.1.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Aplanarorcontour-basedmodelusedtoestimatea two-dimensional pose. A flat model is used to representtheshapeandshapeofthehumanbody. In general, body parts are represented by many rectanglesclosetothecontoursofthehumanbody. Atypicalexampleistheactiveshapemodel(ASM), which is used to obtain complete graphs of the human body and silhouette deformation using principalcomponentanalysis.
Fig
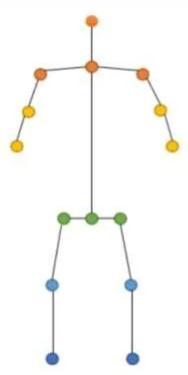
The body's look joins alter dynamically owing to various types of clothing, arbitrary occlusion, occlusions due to viewing angle, and backdrop contexts, making human position estimation a difficult operation. Pose estimation must be resistant to difficult real-world variables like illumination and weather. As a result, image processing algorithms have a hard time identifying fine-grained joint coordinates.It'sparticularlytoughtokeeptrackofminor, scarcelyvisiblejoints.

Afterthetextedithasbeencompleted,thepaperisready forthetemplate.DuplicatethetemplatefilebyusingtheSave Ascommand,andusethenamingconventionprescribedby yourconference for the name of your paper. In this newly created file, highlight all of the contents and import your preparedtextfile.Youarenowreadytostyleyourpaper;use the scroll down window on the left of the MS Word Formattingtoolbar.
A volumetric model is utilised to estimate 3D posture.Thereareavarietyofcommon3Dhuman body models that may be used to estimate 3D humanpositionusingdeeplearning.Forexample, GHUM&GHUML(ite)arefullytrainableend-to-end deeplearningpipelinesthatsimulatestatisticaland articulated3Dhumanbodyformandpositionusing ahigh-resolutiondatasetoffull-bodyscansofover 60'000humanconfigurations.
Position estimation uses a person's or object's pose and orientation to estimate and monitor their location. Pose estimation,ontheotherhand,allowsprogramstoestimate thespatiallocations("poses")ofabodyinanimageorvideo. Mostpostureestimatorsaretwo-stepframeworksthatfirst identifyhumanboundingboxesbeforeestimatingthepose within each box. 17 distinct key points may be detected usinghumanposeestimation(classes).Eachkeypointhas three integers (x, y, v), with x and y indicating the coordinatesandindicatingwhetherornotthekeypointis visible.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
In posture estimation tasks, deep learning approaches (imagesegmentationorobjectidentification)haveresulted inconsiderableadvancementsandperformancebenefits.
The detector we utilized is based on our own lightweight BlazeFacemodel,whichisusedasasurrogateforahuman detectorinFaceDetection.Itpredictstwomorevirtualkey pointsthataccuratelycharacterizethehumanbody'scenter, rotation, and size as a circle. The radius of a circle circumscribing the entire body, as well as the inclination angleofthelinejoiningtheshoulderandhipmidpoints,are allpredicted.
In Posture detection, we employed a landmark model to forecasttheplacementof33poselandmarks.
Adeeplearningmethodisdevelopedinthisresearchto recognise a person based on his or her walking style or mannerism. To begin, the BlazePose Model is utilised to extract 33 skeletal key points from a video stream of 5 seconds. The essential elements are then entered into the model algorithm, which predicts the likelihood of the individualwalking.Foratestingpurpose,dataof3peopleare collectedandtrainedbyDeepLearningModel.
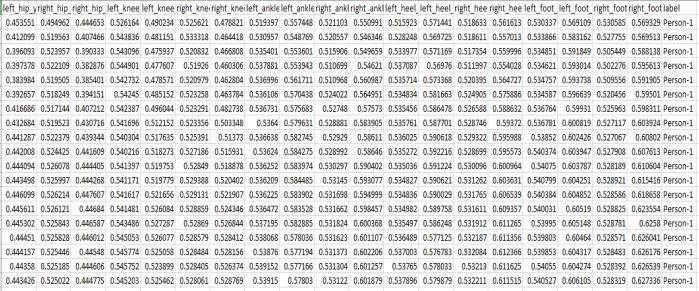
Datasetsforvariouspeopleareacquiredbytaking305-6 secondsrecordingsofeachindividual,whicharethenput throughtheBlazePoseDetectortoobtainthe44skeleton essential points. The facial region's key points are eliminated,andtheremainingkeypointsareputtoaCSV file with the class label Person's unique identification. This information is then loaded into a Deep Learning Model,whichclassifieseachindividual.
Following data collection, 90 frames (90 rows) of the same class label are chosen and concatenated. During inference, the same technique is followed. Then the dataset is split into classes and labels during training period. Now this data is ready to be fed into the Deep Learning Model. The data is stored in CSV file as mentionedinFigure.5.1.
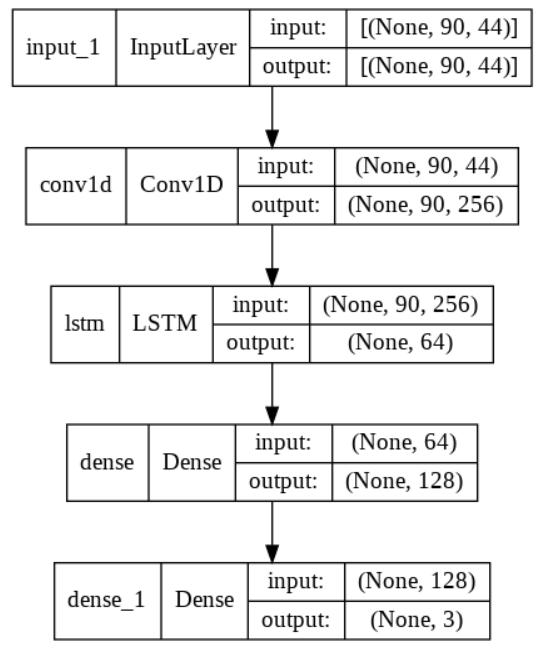
After Data Preprocessing, thedata is fedinto the Deep Learning Model for training. This model was trained using the given data for 100 epochs using Tensorflow KerasAPI.CategoricalCrossEntropy(SoftmaxLoss)loss functionisusedwithanAdamOptimizerwithalearning rate of 0.0001. This model produced an accuracy of 96.88% in the Training Set and 94.12% in Test Set. A DeepLearningModeliscreatedasshowninFigure.5.2.
Firstthekeypointsfor90framesfromvideostreamsof3 persons walking is taken by BlazePose Model. Using thesekeypoints,aDeepLearningModelistrained.After training,modelisdeployedasanapplication.Thevideo stream is read from the camera continuously and the application 90 frames from this video stream and extractsthekeypointsfromthose90frames.Thesekey points are the preprocessed and are concatenated togetherasasinglearray.Thisarrayisthenfedintothe DeepLearningModel.TheDeepLearningModelpredicts theprobabilityofPersonwalking.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Therearelotsofmethodstoidentifyahumanoraperson. Some of them are fingerprint, face recognition, voice recognition, etc. These methods are called as biometrics. Biometrics refers to the identification of humans by their characteristicsortraits.“Footstep”anewbiometrichasbeen proposed by a group of researchers in 1997. In their research, they stated that the footstep of a person has a uniquepropertyanditisdifferentforadifferentperson.So itcouldbeanidentitytodetectaperson.Themainbenefitof footsteps over the known biometrics is that this is a behavioralfactofhumansanditisdifficulttoreplicateby others.
So using this footstep biometrics we can differentiate the walkingpatternformfrompersontoperson.Moreover,we willbeabletofindoridentifyahumanorapersonbytheir walkingpattern. Therearevariousmethodologiesproposed and implemented to recognize persons based on their footsteps.Oneofthemethodologiesusessensors.Thereare differentkindsofsensorstogetinformationaboutfootsteps likepressuresensors. That couldbe placedinthefloor or couldbeintheperson’sfootware.Butimplementingthisis costlyandrequiresalotofpreprocessing,powerandenergy. Anotherpatterncanalsobethewalkingsoundofaperson.A studyshowsthatitispossibletoidentifyapersonaccurately justbyhearingtheirwalkingsound.Andtheaccuracyrateis about 66%. This technique requires high-quality noise canceling microphones to be deployed in the Detection System.Inthispaper,weproposeamostefficientandcost effectivewaytodetectpersonbasedontheirwalkingstyle. Wehavecollectedvideosamplesforeachperson(30videos each5seconds).BodyKeypointsofeachperson'sisbeing extracted from each frame of the video using pretrained BlazePose Model. First, the key points for 90 frames from video streamsof3 persons walkingis taken by BlazePose Model. Using these key points, a Deep Learning Model is trained. After training, the model is deployed as an application. The video stream is read from the camera continuouslyandtheapplication90framesfromthisvideo stream and extracts the key points from those 90 frames. These key points are preprocessed and are concatenated together as a single array. This array is then fed into the DeepLearningModel.TheDeepLearningModelpredictsthe probabilityofaPersonwalking.Thismethodologyproduces accuracy on test set upto 94%. This model uses LSTM to learnwalkingmanneracross90framesandConv1Disused toidentifyfeaturesineachframe.
Thedatasetwascollectedandisdividedinto3partsorsplits (Training, Validation, and Test Set). Softmax Loss and Categorical Accuracy are used as metrics to check the performanceofthemodel.TheTrainingsplithadaSoftmax Lossof0.1873withanaccuracyof96.88%.ValidationSplit hadaSoftmaxLossof0.2521withanaccuracyof99.98%. TestSplithadaSoftmaxLossof0.2368withanaccuracyof
94.12%.DeepLearningModelSoftmaxlossandaccuracyfor differentDataSplitsisgiveninTable1.
Training 0.1873 96.88%
Validation 0.2521 99.98%
Test 0.2368 94.12%
Table. 6.1 Loss and Accuracy for various splits
Tosummarize,wehavedevelopedaDeepLearningModel fordetectingapersonfromhis/herwalkmannerism.This modelpredictstheprobabilityofthepersonwalkingfrom3 persons the model was trained on. By experimenting, on various Hyper Parameters, we got Training Accuracy of 96.88% and Test Accuracy of 94.12% for 3 persons. Therefore,inthispaperwehaveproposedanewmethodfor detectingpeoplebasedontheirwalkingstyle.Therecanbe more research done on this paper, for example, a more advanced and complicated Deep Learning Model can be trainedtoobtainaevenmorehigheraccuracy.Researchcan alsobedonetoimprovethismethodologysothatitcanbe appliedtomorepersonswhichcanthenbeusedinvarious sectorsasasecuritymeasure.
[1]L.Sigal,A.O.Balan,M.J.Black,Humaneva:Synchronized videoandmotioncapturedatasetandbaselinealgorithmfor evaluation of ar-ticulated human motion, International JournalofComputerVision87(2010)4.
[2]D.Mehta,H.Rhodin,D.Casas,P.Fua,O.Sotnychenko,W. Xu,C.Theobalt,Monocular3dhumanposeestimationinthe wild usingimproved CNN supervision, in: International Conferenceon3DVision,2017,pp.506–516.
[3] H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, T. Serre, HMDB:alargevideodatabaseforhumanmotionrecognition, in:IEEEInternationalConferenceonComputerVision,2011.
[4] L. D. Bourdev, J. Malik, Poselets: Body part detectors trained using 3dhuman pose annotations, in: IEEE International Conference on Com-puter Vision, 2009, pp. 1365–1372.
[5] L. Pishchulin, E. Insafutdinov, S. Tang, B. Andres, M. Andriluka, P. V.Gehler, B. Schiele, Deepcut: Joint subset partitionandlabelingformultipersonposeestimation, in: IEEE Conference on Computer Vision andPattern Recognition,2016,pp.4929–4937.
[6]Z.Cao,T.Simon,S.Wei,Y.Sheikh,Realtimemulti-person 2d poseestimation using part affinity fields, in: IEEE
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
Conference on ComputerVision and Pattern Recognition, 2017,pp.1302–1310.
[7]M.Andriluka,U.Iqbal,E.Insafutdinov,L.Pishchulin,A. Milan,J.Gall,B.Schiele,Posetrack:Abenchmarkforhuman pose estimation andtracking, in: IEEE Conference on ComputerVisionandPatternRecog-nition,2018,pp.5167–5176.
[8] L. Pishchulin, M. Andriluka, B. Schiele, Fine-grained activityrecogni-tionwithholisticandposebasedfeatures, in: German Conference onPattern Recognition, Springer, 2014,pp.678–689.
[9]N.Dalal,B.Triggs,Histogramsoforientedgradientsfor humandetec-tion,in:IEEEConferenceonComputerVision andPatternRecognition,volume1,IEEE,2005,pp.886–893.
[10]L.Bourdev,S.Maji,T.Brox,J.Malik,Detectingpeople usingmutuallyconsistentposeletactivations,in:European ConferenceonComputerVision,Springer,2010,pp.168–181.
[11] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, J. Sun, Cascaded pyra-mid network for multi-person pose estimation, in: IEEE Conference onComputer Vision and PatternRecognition,2018,pp.7103–7112.
[12]B.Xiao,H.Wu,Y.Wei,Simplebaselinesforhumanpose estimationand tracking, in: European Conference on ComputerVision,2018,pp.472–487.
[13] K. Sun, B. Xiao, D. Liu, J. Wang, Deep high-resolution representationlearningforhumanposeestimation,in:IEEE Conference on ComputerVision and Pattern Recognition, 2019,pp.5693–5703.
[14] A. Jain, J. Tompson, M. Andriluka, G. W. Taylor, C. Bregler, Learninghuman pose estimation features with convolutional networks, in: Inter-national Conference on LearningRepresentations,2014.
[15] A. Toshev, C. Szegedy, Deeppose: Human pose estimationviadeepneuralnetworks,in:IEEEConferenceon ComputerVisionandPatternRecognition,2014, pp.1653–1660.
[16]J.Tompson,A.Jain,Y.LeCun,C.Bregler,Jointtrainingof aconvo-lutionalnetworkandagraphicalmodelforhuman pose estimation, in:Advances in Neural Information ProcessingSystems,2014,pp.1799–1807.
[17]A.Jain,J.Tompson,Y.LeCun,C.Bregler,Modeep:Adeep learningframeworkusingmotionfeaturesforhumanpose estimation,in:AsianConferenceonComputerVision,2014, pp.302–315.
[18] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, C. Bregler, Efficientob-jectlocalizationusingconvolutionalnetworks,
in: IEEE Conference onComputer Vision and Pattern Recognition,2015,pp.648–656.
[19] S. Wei, V. Ramakrishna, T. Kanade, Y. Sheikh, Convolutional pose ma-chines, in: IEEE Conference on ComputerVisionandPatternRecogni-tion,2016,pp.4724–4732.
[20]J.Katona,“Areviewofhuman–computerinteractionand virtual reality research fields in cognitive InfoCommunications,” Applied Sciences, vol. 11, no. 6, p. 2646,(2021)
[21]M.Andriluka,L.Pishchulin,P.GehlerandB.Schiele,"2D HumanPoseEstimation:NewBenchmarkandStateofthe ArtAnalysis,"2014IEEEConferenceonComputerVisionand Pattern Recognition, 2014, pp. 3686-3693, doi: 10.1109/CVPR.2014.471.(2014)
[22]D.L.Quam,“GesturerecognitionwithaDataGlove,”IEEE Conference on Aerospace and Electronics, vol. 2, pp. 755–760,(1990)
[23]https://arxiv.org/abs/1911.07424
[24]M.Dantone,J.Gall,C.LeistnerandL.VanGool,"Human Pose Estimation Using Body Parts Dependent Joint Regressors,"2013IEEEConferenceonComputerVisionand Pattern Recognition, 2013, pp. 3041-3048, doi: 10.1109/CVPR.2013.391.(2013)
[25]Y.YangandD.Ramanan,"Articulatedposeestimation withflexiblemixtures-of-parts,"CVPR2011,2011,pp.13851392,doi:10.1109/CVPR.2011.5995741.(2011)
[26]https://arxiv.org/abs/1708.03383
[27]K.Khan,M.Mauro,P.MiglioratiandR.Leonardi,"Head pose estimation through multi-class face segmentation," 2017IEEEInternationalConferenceonMultimediaandExpo (ICME), 2017, pp. 175-180, doi: 10.1109/ICME.2017.8019521.(2017)
[28]Y.IbukiandT.Tasaki,"ImprovementofSegmentation AccuracyforPoseEstimationbySelectinganInstance,"2021 IEEE/SICEInternationalSymposiumonSystemIntegration (SII), 2021, pp. 823-824, doi: 10.1109/IEEECONF49454.2021.9382764.(2021)
[29]Dr.BapuraoBandgar,2021,ImplementationofImage Processing Tools for Real-Time Applications, INTERNATIONALJOURNALOFENGINEERINGRESEARCH& TECHNOLOGY(IJERT)Volume10,Issue07(July2021),
[30] Cheol-Hwan Yoo, Seung-Wook Kim, June-Young Jung, Sung-JeaKo,High-dimensionalfeatureextractionusingbitplanedecompositionoflocalbinarypatternsforrobustface recognition,Journal of Visual Communication and Image Representation,Volume45,2017,
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1943