International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
***
Abstract - The prediction of diseases benefits greatly from machine learningmethods. Basedonthe numerous symptoms that users enter as input to the system, the Ailment Prediction system uses predictive modeling to anticipate the user's disease. The algorithmanalyses the user's vividsymptomsand returns the likelihoodthat the disease willoccur as an output. Different Supervised Machine Learning methods are used for disease prediction. Accurate medical data analysis enhances patient care and early illness identification as big data usage grows in the biomedical and healthcare industries. This project's overarching goal is to help academics and professionals choose an appropriate machine learning algorithm for the healthcare industry. This study aims to give essential knowledge about the supervised machine learning algorithms utilized in the healthcare industry. As a result of compiling a data table on the efficacy of learning algorithms for various diseases, wewereabletocomparewhichalgorithm worked best for which specific type of condition. These publications will aid researchers and practitioners in understanding the role supervised machine learning algorithms haveinthehealthcareindustryandtheaccuracyof various supervised machine learning algorithms.
Keywords: Machine Learning, Diabetes, Supervised learning,UnsupervisedLearning,Semi-supervisedLearning, ReinforcementLearning
Computers may improve their performance utilizing minimaldatathankstothescienceofmachinelearning.This fieldconcentrateson learningandunderstandingthrough thestudyofcomputersystems.Machinelearningworkson two methods: training and testing. Machine learning technologyhasimprovedextraordinarilyinafewdecadesto predictthediseaseofpatientsbylookingattheirsymptoms. Machinelearningtechnologyservesasahugeblessingtothe healthcaresectorinidentifyinghealthissueseasily.Machine learning uses the various symptoms of the patients as an inputandgivesanoutputbasedonthat.Machinelearning helps doctors to detect a disease at an early stage. For example, Heart-related problems, Cancer, etc. Healthcare cases depend a lot on machine learning for diagnosis and analysis.Asaresult,itcanbesaidthathealthcareisoneof themostimportantusesofmachinelearninginthemedical field.
Despite the existence of advanced computer systems, medicos still need proficiency in X-rays and surgical operations,however,technologyopticallydiscernsitback after understanding. This process still depends on their knowledgeandexperienceinthemedicalfieldtounderstand thefactorsstartingfrompastmedicalhistory,atmosphere, sugar,bloodpressure,weather,andsomedifferentaspects. Asignificantnumberofvariablesareofferedasittakesalot to comprehend the full process, but no model is prosperouslyanalyzed.Wecanmanufacturemodelsbyusing machinelearningmedicalrecordstogiveoutputsefficiently byanalyzingthedata.Machinelearninghelpsdoctorstogive manyprecisedecisionsfortreatmentchoices,whichresults intheimprovementofpatient’shealth.
The proposed system allows us to detect the disease by analyzing the symptoms. This system utilizes many supervised learning methods for the assessment of the model.Diseasesareidentifiedbythissystembasedonthe said symptoms. This system is operated with the help of machine learning technology. Diseases like breast cancer, diabetes,kidneydiseases,liverdiseases,andheartdiseases canbepredictedusingthissystem.
Diabetesisa metabolicdiseasethatcausesa riseinblood sugar. People having diabetes suffer from dangerous diseasesrelatedtotheheart,kidneys,andsight;that’swhy it’sa lotmoredangerous forthem.Lack ofenergy, feeling thirsty, blurry eyesight, lightweight, urinating more often, etc. are some of the symptoms of diabetes. The health centresaccumulatetheobligatorydataforthediagnosisof the disease through tests and the treatments that are requiredbasedonthis.Thehealthcarefielddependsonthe informationtheygatherbyanalyzingthediseaseandlater operating based on that. This sector is predicated on an immense amplitude of data. Utilizing sizably voluminous data analytics that works with immense data sets and recovers rear data and the connections to process those receiveddatatogiveanaccurateoutput.Someoftheeffects andsymptomsofdiabetesaregivenbelow:
• Women suffering from any type of diabetes have high blood sugar during their pregnancy which risks the
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
birth of the baby. The health of the mother can also deterioratealotbecauseofthis.
• Diabetescausesahugeriseinbloodglucose.Ahuge amountofglucoseinthebloodcangiverisetovarioushealth problemsaftersometime.
• Diabeticpatientssuffermuchmorefromhighblood pressurethanthosewithoutit.Withoutanytreatments,this highbloodpressurecancauseheartdiseaseandstrokes.
• Skin sickness is one of the evident symptoms of diabetes. A high rise in blood glucose leads to inadequate bloodflowwhichcausessevereskindamage.Destructionof skincellsleadstohighsensitivitytowardstemperatureand pressure.
• Type 1 diabetes happens due to the lack of productionofinsulinbythecellsofthepancreas.Asaresult, glucose can’t provide energy in the body. Thus, type 1 diabetes can take lives if insulin is not injected for its lifetime.

• AdiabeticpatientneedstohaveaBodyMassIndex (BMI)of25orlessandmaintainahealthydiettopreventthe disease.
• Middle-aged persons have a higher prevalence of type 2 diabetes. However, today's youth are also growing greatly.
• Diabetes Pedigree Function is used to indicate whetherthediseasehasbeenpasseddowntothechildren throughtheirparentsornot.
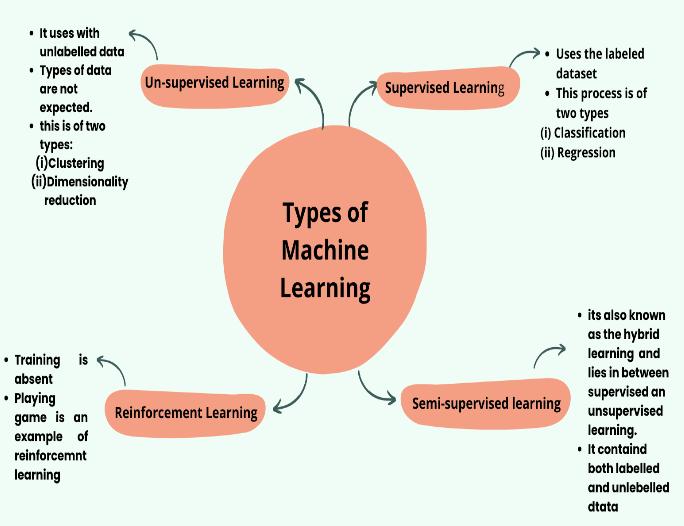
algorithmsintoclassifying data orpredicting the accurate result. The processes under the supervised learning algorithmare
Classification – It is a type of algorithm that classifies a dataset.
Regression –It is a particular kind of supervised learning techniqueusedtoforecastcontinuousoutcomes.
It is a method in which the machine works without supervision. Since the data, in this case, is unlabeled, the machine must explore the dataset and look for hidden patterns to anticipate the output without human involvement.Thetypesunderunsupervisedlearningare:
Clustering:Itisatypeofdataminingtechniqueforgrouping unlabelleddatapredicatedontheirhomogeneousattributes ordifferences.
Association:Itisanothertypeofunsupervisedlearningthat usesdifferentrulesanddiscoverspatternsindata.
Semi-supervisedlearningreferstolearningthatcombines supervisedandunsupervisedmethods.Insemi-supervised learning,thedataisfusedwithalittleamountoflabeleddata withamyriadamountofunlabelleddata.
Reinforcementlearningisatypeofmachinelearningwhere an agent learns to interact with its circumventing environmentbyinvokingactionsanddiscoveringerrorsor rewards. It’s all about taking appropriate action and maximizing as many rewards as possible in a particular situation.
Itisamethodwhereamachineistaughtusingwell-labeled data. This well-labeled data is targeted to train the
Fig
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
The procedures required in creating a machine learning algorithmareasfollows:
The first step in building a model is to gather data from numeroussourcesandsortoutfeaturesthathavethemost impactonthestudy.Thisisacrucialstepbecausethequality and quantity of the information we collect will directly determinehoweffectivethepredictivemodelcanbe.
It'stimetoassessthe data now that ithas beencollected. This aids in avoiding significant problems and ensuring betteroutcomes. Wemayalsopre-processatthislevel by doingthefollowingactions:
Dataformatting:Datamustberecordedinastandardformat that our machine learning can comprehend, such as XML, CSV,etc.,tousethegathereddatainmachinelearning.
Data Cleaning:Data cleaningismostlyutilizedin machine learning algorithms to remove noise, inaccurate data, and duplicatedatafromourdataset.
DataReduction:Minimizingthesampledataforobtaininga betterpredictivemodelinmachinelearning.
Afterdatacleaning,weconvertthecleandataintoanother format that will allow us to recover information. This is a crucial step since it improves the prediction model's precision.
Inmodeltraining,thecollectionofcleanandprocesseddata isdividedintotrainingdata andtestingdata.Thetraining datasetisusedtotrainthemodel,whilethetestingdatasetis usedtoassessthemodel'sperformanceonthedata.Dueto the usage of labeled data here, this characteristic is not presentinunsupervisedlearning.
Themodelthatwascreatedafterthealgorithmwastested mightnowbeutilizedtomakepredictionsinreal-time.
Thestatisticalmethodutilizedinmachinelearningislogistic regression. It is more frequently employed to address categorizationissues.Logisticregressionisusedtoforecasta dependent variable's categorical output. The result must thusbeadiscreteorcategoricalvalue.ItcanbeeitherTrue orFalse,YesorNo,0or1,etc.,butratherthanprovidingthe precisevaluesof0and1,itprovidestheprobabilityvalues thatfallbetween0and1.
RandomForestorrandomdecisionforestisconstructedby utilizing multiple decision trees and the final decision is obtainedbymajorityvotesofthedecisiontrees.Itmaybe utilizedtoaddressissueswithregressionorclassification.. Thekeybenefitsprovidedbyrandomforestwhenusedin regression or classification problems are Minimizing overfitting: Decision trees that are extremely massive run theriskofoverfittingwithintrainingdata,thuscausingthe classificationoutputtodrasticallydifferforasmallchangein the input value. They are hypersensitive to their training data, which may result in more errors in the test dataset (value).
Based on the Bayes theorem, the probabilistic supervised machinelearningtechniqueknownasNaiveBayesisutilized to resolve classification issues. The Bayes Theorem calculatestheprobabilitythataneventwilloccurgiventhe probability that an earlier event will occur. The following equation provides the mathematical version of Bayes' theorem:P(A|B)=P(B|A)P(A)/P(B)
Accordingtotheequationabove,wemaysaythat:
P(B|A)istheposteriorprobabilityofthegivenclasswhereB isthetargetandAistheattributes.P(B)denotestheclass priorprobability.
P(A|B)isthechanceofpredictorgivenclass.
Both classification and regression are performed using a supervised machine learning technique known as the SupportVectorMachine(SVM).Inthebeginning,eachdata point is mapped into an n-dimensional attribute space (n being the total number of attributes). The process then determinesthehyperplane thatsplitsthedata pointsinto two classes (divisions), maximizing the margin distance betweentheclasses(divisions)andminimizingclassification mistakes.Thevalueofeachattributeisthencalculatedtobe
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
equaltothevalueofthatspecificcoordinate,transforming eachdatapointintoapointinann-dimensionalspace.The nextstepistolookforthehyperplanethatseparatesthetwo classesbythegreatestmargin.
K-Nearest Neighbour is one of the most straightforward machinelearningalgorithmsthatcandobothclassification and regression tasks. Its foundation is the supervised learningapproach..K-NNmakesnoassumptionsaboutthe underlyingdatabecauseitisanon-parametricapproach.As aresultofsavingthetrainingdatasetratherthaninstantly learningfromit,themethodissometimesreferredtoasa lazylearner.Instead,itactswhilecategorizingdatabyusing thedataset.KNNcategorizesfreshdataintoacategorythat isrelativelyclosetothetrainingdatabymerelysavingthe informationduringthetrainingphase.
XGBoostwhichstandsforExtremeGradientBoostingisa distributed,scalablegradient-boosteddecisiontree(GBDT) machine learning framework. Artificial neural networks frequentlyoutperformallotheralgorithmsorframeworksin predictionissuesinvolvingnon-structureddata.However, decisiontree-basedalgorithmsarecurrentlythoughttobe best-in-classforsmall-tomedium-sizedstructured/tabular data
the medical field, doctors can now detect a disease at an earlystage.
InPaper2:Diabetesdiagnosisusingmachinelearning:Inthe year2021,thispaperwaspublishedbyBoshraFarajollahi, Maysam Mehmannavaz, Hafez Mehrjoo, Fateme Moghbeli, MohammadJavadSayadi.Intheirpaper,theyhavediscussed the chronic disease diabetes which is dangerous for our health.Theywantedtoevaluatetheperformancesoflogistic regression(LR),decisiontree(DT),randomforest(RF),and othermodelsfordiabetesclassification.Throughthis,they wanted to differentiate between various methods of detectingdisease.
Paper 3: Multiple Disease Prognostication Based on SymptomsUsingMachineLearningTechniques:Thispaper was published by Kajal Patil, Sakshee Pawar, Pramita Sandhyan,andJyotiKundaleintheyear2022.Inthispaper, theyhavediscussedtheimportanceofhealthcareforevery human being. They also made a model which can process output by using a vast source of information. Since the outputwillbebasedonthecollecteddata,andthat’swhyit willbedifferentforeveryperson.
InPaper 4:Using ThreeMachineLearning Techniquesfor Predicting Breast Cancer Recurrence: This paper was published by Ahmad LG, Eshlaghy AT, Poorebrahimi A, EbrahimiM,andRazaviARintheyear2019.Inthispaper, they have discussed the models they made to predict the presenceofbreastcancerbyanalyzingtheinformationthey collected.Toevaluatetheperformanceofthemodels,their accuracy,sensitivity,andotherfeatureswerecompared.The modelsareusedfortheearlydetectionofthedisease.
InPaper1:DiseasePredictionusingMachineLearning: In theyear2019,thispaperwaspublishedbyKedarPingale, SushantSurwase,VaibhavKulkarni,SaurabhStorage,Prof. AbhijeetKarve.Intheirpaper,theyusedthedataprovided bythepatientsasinputandgivestheprobabilityofdisease as output. They have used the Naive Bayes Classifier to predictthedisease.Withtheimprovementoftechnologyin
In this study, we investigated the use of ML-based techniques in healthcare. To do this, we first provided an overviewofmachinelearninganditsuseinhealthcare.We categorized machine learning (ML)-based approaches in medicine based on learning techniques (unsupervised learning,supervisedlearning,semi-supervisedlearning,and reinforcement learning), data pre-processing approaches (datacleaningapproaches,datareductionapproaches,and data formattingapproaches),andassessmentapproaches. Because medical data is developing at an increasing rate, currentdatamustbeprocessedtoforecastpreciseillnesses based on symptoms. To categorize patient data, several generic illness prediction systems based on machine learningalgorithms,includingLogisticRegression,Random Forest, Naive Bayes, Support Vector Machine, K-Nearest Neighbour,andXGBoosthavebeenpresented.
1)Pingale,K.,Surwase,S.,Kulkarni,V.,Sarage,S.,&Karve,A. (2019).DiseasePredictionusingMachineLearning.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN: 2395-0072
2)Balasubramanian,Satyabhama,andBalajiSubramanian. "Symptom-baseddiseasepredictioninthemedicalsystem by using Kmeans algorithm." International Journal of AdvancesinComputerScienceandTechnology3
3) Abu-Jamous, B., Fa, R., Nandi, A.K., 2015a. Feature Selection.IntegrativeClusterAnalysisinBioinformatics.John Wiley&Sons,Ltd.
4)A.K.JainandR.C.Dubes.Algorithmsforclusteringdata. Prentice-Hall,Inc.,1988
5) Tapak L, Mahjub H, Hamidi O, Poorolajal J. Real-data comparisonofdataminingmethodsinpredictionofdiabetes inIran.HealthcInformRes.2013;19(3):177–85.
6) Ahmad LG, Eshlaghy A, Poorebrahimi A, Ebrahimi M, Razavi A. Using three machine learning techniques for predicting breast cancer recurrence. J Health Med Inform. 2013;4(124)
7)ToshniwalD,GoelB,SharmaH.MultistageClassification forCardiovascularDiseaseRiskPrediction.In:International ConferenceonBigDataAnalytics;2015.p.258–66.Springer.
8) Mustaqeem A, Anwar SM, Majid M, Khan AR. Wrapper methodforfeatureselectiontoclassifycardiacarrhythmia. In: Engineering in Medicine and Biology Society (EMBC), 39thAnnualInternationalConferenceoftheIEEE;2017.p. 3656–9.IEEE.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal