International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056


International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
1Associate Professor, Dept. of Computer Science & Engineering, Sri Jayachamarajaendra College of Engineering, JSSS&TU, Mysuru, Karnataka, India 2,3,4,5 Dept. of Computer Science & Engineering, Sri Jayachamarajaendra College of Engineering, JSSS&TU, Mysuru, Karnataka, India ***
Abstract - Ship detection and classification is critical for national maritime security and national defense. As massive optical remote sensing images of high resolution are available, many digital image processing methods have been proposed to detect ships in optical remote sensing images, but most of them face difficulty in terms of accuracy, performance and complexity. In this paper we propose to use YOLOv5 for real time detection of ships.
Key Words: Ship detection, Machine learning, Deep learning,YOLOv5,Objectdetection.
Automatic detection of ships in a satellite image has gained increased importance in today’s military and political scenario. Detecting intrusion of enemy ships in restricted areas, effective enforcement of ceasefire, and protecting the waters of a country are the major military applications of ship detection. Politically, this area is of interest in enforcing agreement of countries with respect to shared water boundaries and monitoring of illegal fishing and maritime activities. Accurate mechanisms for detectingshipsinthesatellitefeedcanbegamechangerin thefield.Failingtodetectshipsanddetectingashipfalsely can both cause huge damage in terms of money, infrastructureandinternationalrelations.Hencedetection ofshipshastobecarriedoutwithasoftwarethatnotonly detects ships but also does not detect false ones. Many methodshavebeenproposedinthepastthatincludebasic histogramprocessingofimage,machinelearninganddeep learning. We propose to use YOLOv5, an object detection framework which has the capability of detecting ships in milliseconds.
In this section we review ship detecting methods for optical images obtained from satellites mainly related to objectdetectionandshipdetection.
Object detection is a common task in real life. Finding all objectsofinterestinanimageiscalledtargetdetection.It has two subtasks: determining the object’s categorization and location. Traditional approaches and methods based
on convolutional neural networks are the two types of target detection algorithms. Traditional object detection algorithm involves three steps in the traditional object detection algorithm: (1) Using sliding window frames of varioussizesandproportionstoslideontheinputpicture with a specific step length and as a candidate area; (2) extracting features from the local information of each candidateregionusingtraditionalmethodssuchascolourbased, texture-based, shapebased methods, and some middle-level or high-level semantic features. The algorithm’s ultimate output result is the final target that must be discovered. (3) For recognition, use classifiers such as SVM [1] models. Following the evaluation of the check box, a set of candidate boxes that could be the detectiontargetwill begenerated,withsomeoverlapping conditions. Traditional detection algorithms can produce good results in specific settings, but their performance is difficulttoguaranteeincomplicatedenvironmentssuchas cloudy conditions, unequal ship distribution in an image and different ship sizes. It has a limited ability to generalise. Furthermore, typical manual design elements necessitate a significant amount of prior knowledge. The three-part detection procedure is time-consuming and computationally costly, and it cannot keep up with realtimemonitoring.
Object detection based on deep learning can be divided into two types. There are two steps in category one. Candidateframesarecreatedfirst,andthenclassified.The first is centered on the creation of regions. R-CNN [2], Faster RCNN ([3], [4]), and SPP-net [5] are examples of common approaches. This approach offers a high level of detectingprecision,butittakesalongtime.Theothertype employs an end-to-end approach to anticipate the entire image while also detecting and classifying the target position.
SSD ([6], [7]) and YOLO ([8], [9], [10], [11]) are two examples of representative approaches. The end-to-end training is genuinely achieved with the one-stage target detection technique. The regression-based target identification system, represented by YOLO, determines the target category and positions the target all at once. Only convolutional layers and the input picture make up the full network structure. The target category and
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 1450
Dr. R Guru1, Shrinidhi T S2, Thryambak M V3, Shylesh N4, V Hemanth5International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
position are returned directly after the convolution procedure. As a result, the one-stage target detection method, particularly YOLOv5, which has advanced speed andaccuracy,isfasterthan thetwo-stagetargetdetection algorithm.
Detecting ships in satellite images has been approachedbymanymethodsincludingmachinelearning andimagesegmentation.YifanLi etal.[12]compared the performances of several machine learning methods on binaryclassificationtasksinvolvingimagesthatcontained shipsandthosethatdidnotcontainships,thentheresults were improved by HOG feature extraction in data preprocessing. Furthermore, they implemented a convolutionalneuralnetwork(CNN)andcompareditwith machinelearningmethods.

ShanlanNieetal.[13]utiliseaninstancesegmentation modelforinshoreshipdetection.MaskR-CNNisregarded asthebaselinemodelforitshighperformanceininstance segmentation. Meanwhile they introduced Soft-NMS into theMaskR-CNNtoimproveobjectdetectionperformance. Therefore,themethodisabletoobtainthemasksofships, which is useful for predicting the extra information of ships,likearea,circumference,direction,etc.
In a paper by Ying Liu et al. [14] ship candidates are coarsely extracted by image segmentation methods first, thenactualshipsaredetectedfromalltheshipcandidates andfinallyclassifiedinto10differentshipclassesbydeep learning.
Apaper by Sagar Karki etal.[15] investigatestraining methodswith differentmodelsusing theUnet model. The EfficientNet encoder trained Tversky loss on further finetuning on higher resolution can help in tackling false alarms. The smaller and close ships are better segmented by the Googlenet encoder model. Both these models clubbedwithagoodclassifierofwhetherthereisashipin the image or not further boosts their F2 score. The researchinthispaperprovidesasolutionthatcaneasethe work of analysing the satellite images and with further fine- tuning, the model can be deployed for maritime surveillancepurposes.
After analysing the above works, we decided to propose an object detection framework for ship detection usingYOLOv5sothatitisreliableandalsofastenoughfor realtimedetection.
We propose a real-time ship detection application that makes use of the YOLOv5 object detection model. Before applying the YOLOv5 model, we also analysed how our dataset performs when trained on image segmentation modelslikeMaskRCNNandUNet.
As shown in fig -1, the preprocessing step involves processing the imageso thatitcan be fedasinput forthe training process. The images in the dataset come along withRLEencodedstringsthatindicatepixelswhereships are present in an image. This can be used for training by converting RLE encoded string to binary masks for input for training on image segmentation models and by converting them to YOLO annotation format in a text file fortrainingonYOLOv5objectdetectionmodel.
YOLOv5 expectsannotationsfor eachimageintheform of a .txt file where each line of the text file describes a boundingbox.Eachlinerepresentsoneoftheobjectstobe detected. The specification for each line is as follows. (1) Onerowperobject.(2)Eachrowisclassxcenterycenter width height format. (3) Box coordinates must be normalized by the dimensions of the image (i.e., have values between 0 and 1). (4) Class numbers are zeroindexed.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
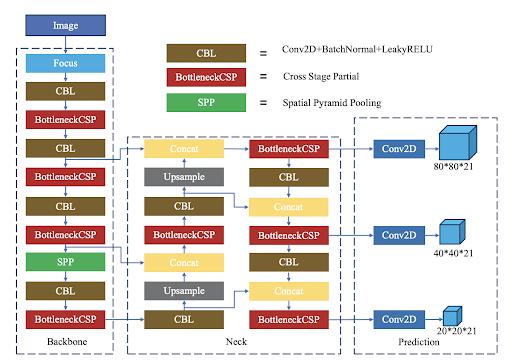
Fig-2:YOLOv5networkstructure[16]
The network structure of YOLOv5 is divided into three components, as depicted in fig -2, backbone, neck, and output. The input image with a resolution of 640*640*3 passes via the Focus structure in the backbone. It first becomes a 320*320*12 feature map via the slicing process, and then a 320*320*32 feature map after a convolution operation with 32 convolution kernels. A basic convolution module is the CBL module. Conv2D + BatchNormal + LeakyRELU is represented by a CBL module. The BottleneckCSP module extracts rich information from the image by performing feature extraction on the feature map. The BottleneckCSP structure can reduce gradient information duplication in convolutional neural networks’ optimization process when compared to other large-scale convolutional neural networks, in the optimization process of convolutional neural networks, the BottleneckCSP structure can reduce gradient information duplication. Its parameter amount accounts for the majority of the network’s parameter quantity. Four variants with varying parameters can be obtained by altering the width and depth of the BottleneckCSP module, namely YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. The SPP module primarily improves the network’s receptive field and acquires featuresofvariousscales.
Inaddition, basedonthe FPNstructure,YOLOv5addsa bottom-upfeaturepyramidstructure.TheFPNlayersends powerful semantic characteristics from top to bottom, whereas the feature pyramid conveys robust positional features from the bottom up, thanks to this combination operation.To boostthe network’sabilitytodetecttargets at different scales, use feature aggregation from several featurelayers.Outputthecategorizationresultsandobject coordinates at the bottom of the figure. We used the opensource version of YOLOv5 by ultralytics[17]. This contains different models that have been pre trained on
the MS COCO dataset for 300 epochs. The following is a shortdescriptionofeachofthese:
● YOLOv5n:Thisisthenewnanomodel,smallestin the family and meant for the edge, IoT devices, and with OpenCV DNN support as well. It takes less than 2.5MB in INT8 format. It is ideal for mobilesolutions.
● YOLOv5s: This is the small-sized model in the family.Ithasaround7.2millionparametersandis bestsuitedforCPUinference.
● YOLOv5m:Thisisthemedium-sizedmodel inthe family,ithas21.2millionparameters.Itisanideal model for many datasets and training since it provides a good tradeoff between speed and accuracy.
● YOLOv5l: It is the large model in the YOLOv5 family, it has 46.5 million parameters. It is ideal fordatasetswheretargetobjectsaresmallinsize.
● YOLOv5x:ItisthelargestandhasthehighestmAP among the five models. It is slower compared to theothersintermsofinferencetimeandhas86.7 millionparameters.
Fig-3:Sampleimagesfromdataset[18],i,ii&vcontain shipsandiii&ivdonot
The dataset is taken from Kaggle [18], which comprises 1,93,000 pictures, with just 40,000 images containing 80,000 ships [fig -3]. There may be one or more ships in the photos with ships. To generate masks for the image, thecorrespondingrun-lengthencodeddata isprovided in a separate CSV file. The data contains 15,000 photos for testing, and the ground truth values are available on





International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Kaggle. The models that perform well on the test data show their robustness and provide an approximate approximationofhowwelltheywillworkwhendeployed. All of the images are satellite images with a resolution of 768*768 pixels. Due to computational resource limits, all training is done using 10,000 images from the original datasetthatcontainvaryingnumberofshipsfrom0to16 and scaling down the size to 416*416 pixels. We considered 9000 images for training and 1000 images for validation and used 600 images from the original 15,000 test images for testing. The text annotations for all the 10,000 images along with the images make our dataset whichisfurthertrainedonYOLOv5network.
Themodelsprovidedby[17]arepretrainedontheCOCO dataset [19] for 300 epochs each. In [19] there are 80 objectcategories,andtheoutputtensor’sdimensionis3(5 + 80) = 255, where 3 represents each grid prediction’s three template boxes. The coordinates (x, y, w, h) and confidence of each prediction box are represented by the number 5. (confidence, c). Because there are two sorts of items in the ship detection scenario, one with ships and one without, the YOLOv5 classifier must be modified. 3(5+2) = 21 becomes the output dimension. Adapting to ship detection, we can reduce the amount of network parameters, lower computing overhead, and increase detection accuracy and speed by altering them. The number of classes is modified to 1 from 80 to reflect our trainingprocess[16].
1) Precision - It is a measure of how accurate the predictions are. It is the percentage of correct predictionsoutofallpredictions.
TP is the number of true positives and FP is the numberoffalsepositives.
2) Recall - Recall is the number of positives predicted divided by the total number of existing positivesinthedata.
mAP@0.5:ItistheaverageofAPofallpicturesin eachcategorywhenIoUissetto0.5.
mAP@ 0.5:0.95: This is the average of mAP considering different IoU thresholds (from 0.5 to 0.95instepsof0.05)
4) IoU (Intersection over Union) - It is a measure of theoverlapbetweentwoboundaries.Itisusedto measure how much the predicted boundary overlaps withthegroundtruth.For examplehow much of the picture the predicted bounding box covers.
5) AP (Average precision) - It is a metric used to measure the accuracy of object detection algorithms. It is the average precision value for recallvalueovertherangefrom0to1.
Inthissection, weintroducetheexperiment’s details,and thenweshowtheresultsoftrainingfromscratchandthat of using pretrained weights and compare the five models ofYOLOv5.Finally,weshowthe real time performanceof eachmodelandanalysetheresults.
TP is the number of true positives and FN is the numberoffalsenegatives.
3) mAP (mean Average Precision) compares the groundtruth bounding box to the detected box and returns a score. The higher the score, the moreaccuratethemodelisinitsdetections.
value:
In our experiment, all the training is done by scaling imageto416*416 pixelssize.Data enhancement methods such as random flip, geometric distortion, illumination distortion, image occlusion, random erase, cutout, mixup, etc.,. are performed on them. Due to unavailability of a powerfulmachinethatmeetstheneedsofourtraining,we performed all our analysis on a virtual machine with GPU providedbyGoogleColab[20]withabatchsizeof64.The specifications of the instance are shown in table -1. For training our dataset on YOLOv5 models, the hyperparametersasshownintable-2wereused.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Table -1: Experimentalenvironmentconfiguration.
Parameter Configuration
CPU 2Intel(R)Xeon(R)CPU@ 2.00GHz
GPU TeslaP100-PCIE-16GB
RAM 25GB Language Python3.6 Acceleration environment CUDA11.2
Table -2: Somehyperparametersusedfortraining
Parameter Value
Learningrate 0.01
Learningratedecay 0.999 Weightdecayrate 5e-4 Momentum 0.937 Batchsize 64
Initially,thedifferentYOLOv5modelsi.eyolov5n,yolov5s, yolov5m,yolov5l,yolov5xwhichvaryinnetworksizeand modelsize(inMB)withyolov5nhavingleastnetworksize and model size and yolov5x having the largest were trained on the dataset without using any pretrained weights. The results obtained after training from scratch for 100 epochs batch size of 64, image size of 416*416 pixels and hyperparameters as shown in table -2 are shown in fig -4 and table -3 shows the best mAP/0.5 obtainedontrainingeachmodel.
Table -3: BestmAP/0.5achievedbytrainingmodelsfrom scratchwithoutusingpretrainedweights.
Model Best mAP/0.5 after 100 epochs yolov5n 0.66436 yolov5s 0.73315 yolov5m 0.77113 yolov5l 0.79944 yolov5x 0.82100
Later, YOLOv5 models that were pretrained on the COCO dataset[19] were used for training. We used yolov5n, yolov5s, yolov5m, yolov5l, yolov5x along with their pretrained weights and trained them for our dataset by modify- ing the configuration file for 100 epochs with other configurations like batch size, hyperparameters, imageinputsizesameasthatoftrainingfromscratch.The resultsobtainedwereasexpectedi.e.theyperformedway betterthanthemodelsthatweretrainedfromscratchand yolov5x performed the best when compared to other modelsowingtoitslargenetworksize.table-4showsthe best mAP/0.5 achieved on each model. The highest mAP/0.5 achieved was 0.89 using yolov5x. fig -5 shows howeachmodelperformedoneachepoch.
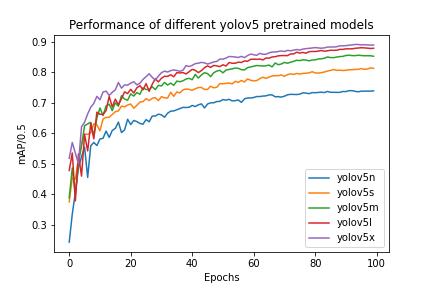
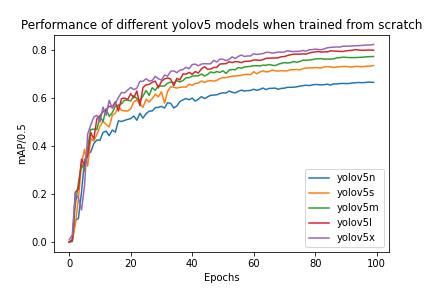
Fig-4:Thisfigureshowshowdifferentmodelsperform over100epochswhentrainedfromscratchwithoutusing pretrainedweights.
Fig-5:Thisfigureshowshowdifferentmodelsperform over100epochswhentrainedusingpretrainedweights
Table -4: BestmAP/0.5achievedduringtransferlearning usingeachpretrainedmodel.
Model Best mAP/0.5 after 100 epochs yolov5n 0.73989 yolov5s 0.81424 yolov5m 0.85593
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 1454
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
yolov5l 0.88049 yolov5x 0.89119
As the model size of yolov5x is very large and requires more computational resources to train for further epochs after100,wetrainedyolov5lformorethan100epochsby training the model for 100 epoch once a time and then using the saved weight of last epoch and training further for 100 more epoch. Even though after each 100 epochs the mAP reduces during training due to usage of saved weights of previous 100 epochs and different learning rate, eventually the model converges to one value of mAP/0.5 after around 400 epochs. The mAP/0.5 best achieved after 400 epochs was 0.894. As a balancing act, weconsiderbothyolov5s andyolov5l modelsforourreal time detection of ships in satellite images as yolov5l produced higher accuracy and yolov5s produced satisfactoryperformancewithhighspeeddetection.table5liststhetimetakenbyeachmodelforinference.
Table -5: Inferencetimeperimageinmillisecondsof differentmodelswhentrainedusingpretrainedweights.
Model Inference time per image in milliseconds
yolov5n 8.4 yolov5s 7.2 yolov5m 10.2 yolov5l 14.6 yolov5x 21.1
The experiment clearly shows that there is around 10% improvementintheperformanceafterpretrainedweights wereused.Wecaneasilyinferfromtable-5thatyolov5sis very fast and best suited for real time detection. It is also observable that yolov5l has a good trade off between speed and accuracy making it a good choice for scenarios where both accuracy and speed are important. Fig -6 shows some examples of detection of ships using our proposedmethod.Thismethoddetectsevensmallshipsin an image and also almost all ships in the image. As the datasetcontainsmoreimagesofshipsthatareorientedin some angle and less images in which ships are oriented horizontally or vertically, the results for these ships are notthatgoodastheboundingboxdoesnotcovertheship completely as in the case of ships that are oriented in an angle different than 90 degree or 180 degree. This is evidentfromfig-7.
Fig-6:Samplesofdetectionusingtheproposedmethod.
Fig-7:Resultsforimagesthatcontainshipsoriented horizontallyandvertically.



Owing to the need of detecting ships accurately and with high speed the proposed method seems a very fit candidate for large scale application for real time ship detection. We obtained a high detection mAP/0.5 of 0.89114withaninferencetimeof14.6millisecondswhich can be used in maritime regulatory authorities and defence sector usage. The future work includes adding moreimagesthatcontainshipsorientedinahorizontalor vertical fashion, improving the accuracy using higher batch size, training model from scratch without transfer learningandtryingdifferentsetsofhyperparametersfora large number of epochs. These things require more computational resources and time. Nevertheless it can improvetheaccuracyofdetectingships.





International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056 Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
[1] T.Malisiewicz,A.Gupta,andA.A.Efros,“Ensembleof exemplarSVMs for object detection and beyond,” in 2011 International Conference on Computer Vision, Barcelona, Spain, Nov. 2011, pp. 89–96. doi: 10.1109/ICCV.2011.6126229.
[2] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich FeatureHierarchiesforAccurateObjectDetectionand Semantic Segmentation,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2014, pp.580–587.doi:10.1109/CVPR.2014.81.
[3] C. Han, G. Gao, and Y. Zhang, “Real-time small traffic sign detection with revised faster-RCNN,” Multimed. Tools Appl., vol. 78, May 2019, doi: 10.1007/s11042018-6428-0.
[4] Z. Liu, Y. Lyu, L. Wang, and Z. Han, “Detection Approach Based on an Improved Faster RCNN for Brace Sleeve Screws in High-Speed Railways,” IEEE Trans. Instrum. Meas., vol. PP, p. 4395, Jan. 2020, doi: 10.1109/TIM.2019.2941292.
[5] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,” vol. 8691, 2014, pp. 346–361. doi: 10.1007/978-3-319-10578-9_23.
[6] Z. Chen, K. Wu, Y. Li, M. Wang, and W. Li, “SSD-MSN: An Improved Multi-Scale Object Detection Network Based on SSD,” IEEE Access, vol. 7, pp. 80622–80632, 2019,doi:10.1109/ACCESS.2019.2923016.
[7] X. Hu, H. Li, X. Li, and C. Wang, “MobileNet-SSD MicroScopeusingadaptiveerrorcorrectionalgorithm: real-time detection of license plates on mobile devices,” IET Intell. Transp. Syst., vol. 14, no. 2, pp. 110–118,2020,doi:10.1049/iet-its.2019.0380.
[8] Z. Huang, J. Wang, X. Fu, T. Yu, Y. Guo, and R. Wang, “DC-SPP-YOLO:Denseconnectionandspatialpyramid poolingbasedYOLOforobjectdetection,”Inf.Sci.,vol. 522, pp. 241–258, Jun. 2020, doi: 10.1016/j.ins.2020.02.067.
[9] D. T. Nguyen, T. N. Nguyen, H. Kim, and H.-J. Lee, “A High-Throughput and Power-Efficient FPGA Implementation of YOLO CNN for Object Detection,” IEEETrans.VeryLargeScaleIntegr.VLSISyst.,vol.27, no. 8, pp. 1861–1873, Aug. 2019, doi: 10.1109/TVLSI.2019.2905242.
[10] D.Sadykova,D.Mussina,M.Bagheri,andA.James,“INYOLO: Real-time Detection of Outdoor High Voltage Insulators using UAV Imaging,” IEEE Trans. Power Deliv., vol. PP, pp. 1–1, Sep. 2019, doi: 10.1109/TPWRD.2019.2944741.
[11] Y.Yin,H.Li,andW.Fu,“Faster-YOLO:Anaccurateand faster object detection method,” Digit. Signal Process., vol. 102, p. 102756, Jul. 2020, doi: 10.1016/j.dsp.2020.102756.
[12] Y. Li, H. Zhang, Q. Guo, and X. Li, “Machine Learning MethodsforShipDetectioninSatelliteImages,”p.6.
[13] S. Nie, Z. Jiang, H. Zhang, B. Cai, and Y. Yao, “Inshore Ship Detection Based on Mask R-CNN,” in IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium, Jul. 2018, pp. 693–696. doi:10.1109/IGARSS.2018.8519123.
[14] Y. Liu, H.-Y. Cui, Z. Kuang, and G. Li, “Ship Detection and Classification on Optical Remote Sensing Images Using Deep Learning,” ITM Web Conf., vol. 12, p. 05012, Jan. 2017, doi: 10.1051/itmconf/20171205012.
[15] S. Karki and S. Kulkarni, “Ship Detection and Segmentation using Unet,” in 2021 International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Feb. 2021, pp. 1-7. doi: 10.1109/ICAECT49130.2021.9392463.
[16] F. Zhou, H. Zhao, and Z. Nie, “Safety Helmet Detection Based on YOLOv5,” 2021 IEEE Int. Conf. Power Electron. Comput. Appl. ICPECA, 2021, doi: 10.1109/ICPECA51329.2021.9362711.
[17] ultralytics/yolov5.Ultralytics,2022.Accessed:Jun.13, 2022. [Online]. Available: https://github.com/ultralytics/yolov5
[18] “Airbus Ship Detection Challenge.” https://kaggle.com/competitions/airbus-shipdetection(accessedJun.13,2022).
[19] T.-Y. Lin et al., “Microsoft COCO: Common Objects in Context,” in Computer Vision – ECCV 2014, Cham, 2014, pp. 740–755. doi: 10.1007/978-3-319-106021_48.
[20] “Making the most of your colab subscriptionColaboratory.” https://colab.research.google.com/?utm_source=scsindex(accessedJun.13,2022).
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 1456
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Dr. R Guru Dr.RGuruisworking as Assistant Professor in the Department of Computer Science and Engineering. He graduated from Bangalore University. He obtainedhisMastersDegreefrom B M S College of Engineering, Bangalore, affiliated to Visvesvaraya Technological University. He obtained Doctoral Degree from Visvesvaraya Technological University, Belagavi.Hisareasofinterestare Computer Network, wireless sensor networks, Cloud Computing,IoT.

Shrinidhi T S, is studying B.E in computer science at JSS Science and Technology University. His current research interests include deep learning and computationalcomplexity.
Thryambak M V is studying B.E in computer science at JSS Science and Technology University. His current research interestisdeeplearning.
Shylesh N is studying B.E in computer science at JSS Science and Technology University His current research interest is machinelearning.


V Hemanth is studying B.E in computer science at JSS Science and Technology University His current research interest is machinelearning.

