International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Student Dept. of Computer Science and Engineering, IIT Bombay, Maharashtra, India ***
Abstract - Nowadays, in computer science, the student must have superb programming skill due to academic and professional life but these days, CS overall students having lack of this kind of quality. In this paper, they find an approach that they can track those students who are falling behind in computer courses and provide students with adaptive feedback that they can improve, and the teacher found those students who are not spending enough time and effort. They proposed a predictive model using several machine learning and deep learning techniques to train data. To train their predictive model, they use two kinds of data: student static and dynamic data. Before starting, of course, they collect student static data like ( previous academic records, previous high school data, and student characteristics) based on course enrollment of students, and during the semester, every week, they collect student dynamic data like ( activity log, amount spend of time in the assignment, online dynamic). These two types of data are first normalized and used for generating predictions based on their proposed model. From their prediction result, they send each student customized feedback via email. At the end of the semester, those students flow each week guidance they do well in the course.
Key Words: Learninganalytics;self-regulatedlearning;MOOCs;collaborativeprogramming;bigdataanalytics.
ComputerScience(CS)classeslackthecodingperformanceofsomestudentsandneedtoimprove(Luetal.,2017). However,whichstudentsarelaggingbehindinCSclasses,andfindingthembytheteacherisdifficultwhentheclasssizeis huge.Mostofthetime,theteacherwillbeabletofindthosestudentswhenthestudentfailsintheexam.Butifweareable tofindthosestudents beforefailinginthe examand wewill beabletoguide them, then it will bevery beneficial forthe student, and the failing chance will decrease. That is why we need automatic detection to predict those students. Nowadays, technology has evolved a lot because computer programming classes are conduct in blended ways; such as teachers teach the student in the classroom with face-to-face interaction and use several online tools like online assignment submission, self-assessment quizzes, Learning Management System (LMS). Nevertheless, all this helps students and teachers to learn and teach but using this online tool, we can collect data and leverage students digital footprint.
Dataiseverythinginthisresearchbecausethewholethingdependsondata.Trainthemodelorpredictingthestudent atriskusingadvanceddataminingtechniquesorprovidingadaptivefeedbackviaemailalldependsondata.Furthermore, these different types of data are collected in several ways. Only one-time static data is collected before the start of the course,wheredynamicdataarecollectedeachweek.Botharedifficulttocollect,butdynamiccollectiondataarerelatively morecomplex.
To identify those students who need assistance, we propose a prediction model using available data sources. For collecting, we student clickstream data, dynamic effort, and engagement. After collecting data, we leveraged the main componentfromthedataandtrainedourproposedmodelusingseveraladvanceddataminingtechniquesten-fold.After training,calculatetheresulttillthefirstweektosemestermid.
Some students might be opt-out after mid. That is why we start giving feedback to students those are still opt-in and predict the result. Based on the proposed predictive model result, provide custom massage feedback via email top to bottomorbottomtotop.However,eachstudentwillgettheiraddictivefeedback,andtheteacherwilldividetheresulting top student with the resulting bottom student in a group so that the lower result student will be able to learn from teamworkandimprovetheirperformance.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Student data are collected in several ways, also storing multiple times and in different locations. Like a student need to collect several locations and several ways. By collecting these data, we can leverage student engagement and involvementonthecampus.AllthewaycancollectStudentdatafrommultipleplaces,butwecanevaluateastudentbased on their current academic performance at the university. A student might have excellent results in previous, but the performance in the university can be poor due to several reasons. If a student spends a fair amount of time in computer programmingclasses,thatstudenthasgoodchancestodowellinassignmentsandexaminations.Duringanassignment,a student spends much time in the module to complete the programming assignment and solve the problem. After solving theprogrammingassignmentstudentandtastetheactualoutputormaysubmitagainforabetterresultbutallthesetime ispendingandsolvingproblemcreateahugeamountofdigitalfootprintprints.Allthesethingsarehandledbyanonline tool or platform, but these tools help students to submit and compiling their code. For teachers to evaluate the students submitted program or assignment, but there is no mandatory to use this only on the tool they can use several kinds of stoolsastheirrequirement.Soforthisproblem,theycollecteddata fromseveral online educational platformsof student interaction.Thereforeitistoughtocollectallground-truthdatatotrainapredictivemodel.Tosolvingthisproblem,they collect data from three different data sources for student engagement. Students’ efforts in computer programming assignmentortheirengagementandinteractionthroughouttheassignmentorprogramandthenbuildamodeltoachieve goodpredictiveperformance.
● Atfirst,theycalculatestudentcharacteristicsanddemographicsfromstudentregistration.
● Theybuildacustomlearningplatformforteachingcomputerprogrammingforstudentstosubmitprogramsand instructorstoreviewthem.
● Finally, from the Learning Management System (LMS) system University collects student click-stream data for findingeachstudent’sengagementwiththecoursematerial.
This study research is done by Dublin City University in 2016(Azcona et al., 2019) . To helping teachers and identifyingthoseisstudentsareatrisktoapplytheirproposedpredictivemodelintheirownUniversityacademiccourses, they builda custom virtual learning environmentforcomputer programming coursesacross computer science inDublin City University. They design their learning management system where students and drag and drop their files, and the systemwillprovidereal-timefeedbacktothestudent.Eventhesystemgradesthestudentsubmissionofassignments.The uses of student learning management system they collect student log data using artificial intelligence and machine learningtechniques.Thentheycombinethosedatawithtrainingtheirmodelandfindingthestudentisatriskincomputer programming classes based on the result, which means predictive model results. Then provide their own adaptive customizefeedback,butthefeedbackwillprovideafterthemid-termexambecausesomestudentwillopt-outbeforemid. Thecourse wasabouttwelveweeks,soaftersix weeks, theystart guidingstudentsabouttheir problemsandsometimes makinggroupteams.
Buildingthepredictivemodeltheprimarypurposeistoidentifyandclassifythosestudentshavechancestofailin computer programminglaboratory assignment. Using this predictivemodel, they trytofind betweenlowerperformance and higher-performing students. Like a not equal number of students, the primary imbalance between the two classes is passingandfailinginanexam.Theycollectstudentpreviousacademicdatabeforeandduringthecourse;theyalsocollect studentdigital footprintsto traintheirpredictivemodel.Fromthispredictivemodel, theusedmultiplemachinelearning techniqueusedtoextractinformationautomaticallyusingclassificationpatternsandidentifyingthestudentperformance incomputerprogramming-basedformal assignments. Theresultofthepredictive model isquite dynamicand gives near to the expected result. They used the predictive model to predict the result on a timely basis like they predict whether studentsaredivertingtotheirexpectedgoalornoteveryweek.
Dataprocessusinglearningfunctionforeveryweektoidentifyamongwithhigherandlowerperformingstudents best on their extracted data features for training the classifier. From the beginning to the end of the course, a set of dynamic and static data are used for each weekly learning function. Before the beginning of the course, all the static
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
features are collected. Static features are student characteristics and students' previous academic history, or we can say their period ofacademic performance. Andthen,the dynamicfeaturesarecollected every week during thecourse based onstudentengagementandprogression,andinteractionthroughoutthecourseandplatform.
Every week, build a new classifier to predict, and each weak classifier predicts some prediction based on the classifier or learning function and model. Then from the predicted results, collect the top features and the student characteristics.Then,thistopfeaturesandnewweekdynamicdataareusedfornextweek’sprediction,andtheprocesses arerunningthroughoutthewholecourse.
Static data collect before starting the courses, and this data is collected based on student characteristics and academicperformance.
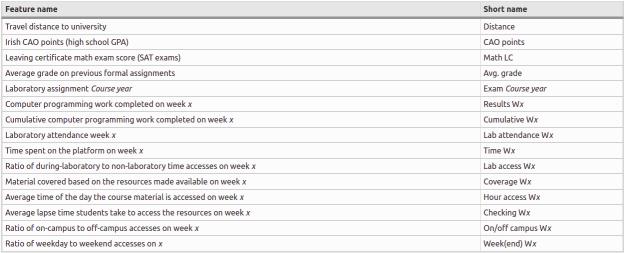
● Student characteristics: Their date of birth, distance from University to home, and how they come to UniversityliketheroutetoUniversity.
● Prior academic performance: In this part, collect the previous academic results like CAO points, High schoolCGPA,andacademichistoryinthepreviousuniversitycourse.
Duringthecourseis,dynamicdatacollectedbasedonstudents’interactionsthroughouttheweek.Amountspent ontimetoaccessthecoursematerialandcomputerprogrammingsubmission.
● Engagement: Get a system allowing them to submit their programming assignment in the system their submitted program and give real-time feedback, so it calculates the correctness of laboratory work and howmuchiscompleted.
● Prior academic performance: Try to find about how much time they spend on their laboratory work, during the course how they spend time on the platform how much time they used to access course material besides that they are accessing the course material based on IP address from home or campus anddoestheyaccessingthecoursematerialduringtheweekend.
Figure3.1:Featurenamesandshortnamesexperimentalsetupfromthepaper.
Fortheirpredictivemodel,theyuseaclassifiersettopredicteveryweekthechanceofastudent passingorfailing in a computer programming laboratory exam. The course is divided into two parts mid-term and end-sem. They predict thestudenthasthechancetofailinthemid-termexamonthetopofsixweeksand7to12weektheypredicttheoutcome of laboratory exam. Collected student static and dynamic data used to train every week learning function. The learning function builds by combining student dynamic and static data where student data is collected in previous but dynamic datafeaturesarefrompreviousweeks.Thisprocesscontinuedthroughoutthecoursestillthe12thweek.
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 1082
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
They use the empirical risks minimization principle to find out the misclassification error and find out which advancemachinelearningalgorithmlowestempiricalerrorin theirlearningfunction.Empiricalriskminimizationiseasy for a family of learning algorithms that are helping to give the model with minimal average error over the training sets. They use a Scikit-learn python library to find which supervised and unsupervised algorithm provides a better solution. Their learning function or bag classifier contain several machine learning algorithm, and they want to find out which classifier performs well all above them because they want to pick the best classifier to which can accurately find out passingandfailingintheirpredictionproblem.However,findingthisisquitedifficultbecausesomestudentsmightfailin the assignment but pass the exam. But their main objective is to find out those students are having issues during the courseandsolvingthe programmingassignment.So,Thatis,wecanguidethem by providing feedback forgroupingina team.
Figure3.2:Performanceofthelearningalgorithmsinthebagofclassifierswhentrainedandcross-validatedfromthe originalpaper.
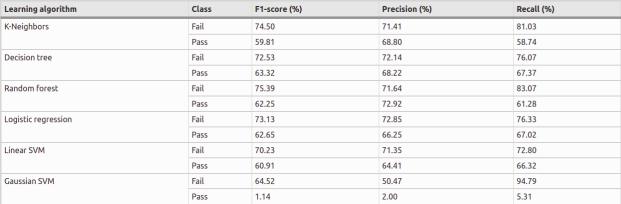
Their bag classified has a group of meta estimators that helps to find the subset of the original data set and aggregatewiththeirpredictionstofindthefinalorbestclassifier.Inthelearningfunction,youhaveseveraladvanceddata mining algorithms like linear support vector machine (SVM), Gaussian SVM, Decision tree, Random forest, Logistic regression,andK-Neighbors.K-Neighbors,SVM,Randomforest,Decisiontree,LinearSVMthisalgorithmareusedforboth classificationand regression,whichhelpstoanalyzeand understandtherelation between twoor more variables.Where Logistic regression helps to categorize values in binary response of variable based on a mathematical equation and GaussianSVMisitanglemethodusedinSVMmodel.
Figure 3.2 describes the learning algorithm performance in the back classifier after training the data and crossvalidation. The performance metrics of the learning algorithm show the average result of passing and failing in CS2 coursesduringthe12thweektimeperiod.UsedTenfoldcross-validationtoevaluatethepredictivemodelbypartitioning theoriginal sampleintoa trainingsettotrainthemodel foreveryweek’saverageresult(Kohavietal.,1995).Tofinding high-performance results in F1 matric day calculator precision and recall based on precision and recall value, they calculateF1matricvalue.Fromlearningalgorithms,theF1matricfoundthatK-Neighborshasthehighestchanceoffailing classonweek5and6.
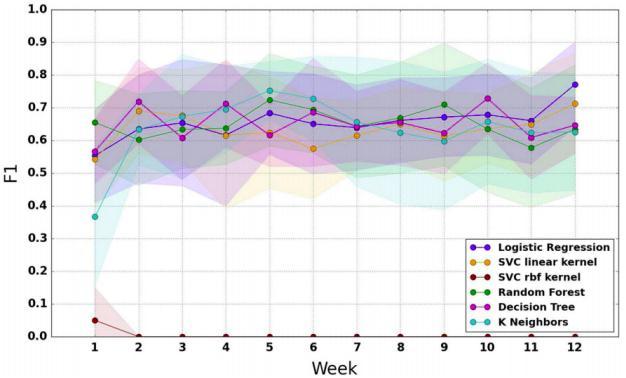
Figure3.3:PerformanceofthebagofclassifiersfortheF1metricfromtheoriginalpaper.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Infigure3.3showthattheresultisgoodeveristheresultofdifferentforceduringthesemester.Thefigureshows thatonlyonemachinelearningalgorithmlearningfunctionfailstodetect.
Moreover,figure3.4describesthatthelearningfunctionoftheF1matricvalueforthefailintheclass.
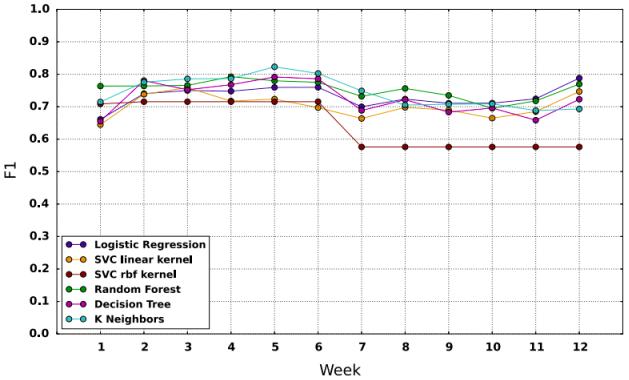
Figure3.4:PerformanceofthebagofclassifiersfortheF1metricandthefailclassfromtheoriginalpaper.
TheresultshowsthatSVMwithGaussiankernelfailstodetectstudentsarepassingmeanstheexpectedPvalueof Gaussian is less than 0.00001. Besides only this SVM Gaussian algorithm, other learning algorithm functions on bag classifierscanpredict,andtheyallhaveprettysimilarresults.Iftheyhadmoredataofastudent,thentheymightbeable togeneralizebetterresults.
Aftergeneratingpredictivemodelresults,theypickthemostappropriatelearningalgorithmsresultsandprovide weekly personalized notificationfeedback orguidelines via email afterthefirstliteraryexaminweek six.Then releasea feature in the module that a student can opt-in or opt-out for getting this notification or guidance notification via email. Once the student opt-in, they will not be able to change it during the course, but those students do not reply or opt-out, theywillremovefromthelearningmanagementsystemmodule. Hereisalistofpersonalizedfeedbackandhowtheyprovidepersonalizedfeedback.
● For providing personalized feedback, they guide every student based on student performance on that week. Supposeastudent’sperformanceisbetweenthetop10percent.Thesystemprovidesacustomizedmassagewith guidance.
● Samethosestudentsarebelow10percentgetacustomizedmessagelikepleasetrytomakemoreeffort.Insome otherscenario,theyalsosendeightcustommessagesbetweenthestudents.
● Those students do not spend enough time on their programming assignments or courses, and the system will generateamessageandsenditinboldletters.
● Supposea studentdoes not participateinlaboratory sessionsorlab work. Thesystemsendsthe message to the studenttojointhenextlabstation,andthetutorwillresolveissuesifthere.
● If a student submits an assignment and the submitted assignment failed with the test case, then in the system generated message to solve the previous problem and if that specific student failed to solve previous problems, then the teacher makes the team with top students that the weak student can able to to learn before next week submission.
● Also,thesystemprovidesresourcestolearnandprovidespredictionguidanceonhowthesystemwillpredictor observetheirweeklyengagementthroughoutthecourse.
● Also, the student can unsubscribe from the getting notification via email, but nobody did that throughout the course.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 08 | Aug 2022 www.irjet.net p-ISSN:2395-0072
Many students are currently studying in the computer science department worldwide, and they required super programming skills for doing well in the computer science field. Dublin City University found that computer science studentlacksprogrammingskillsandthelackremainsthroughoutthestudentUniversitylife.Furthermore,theclasssize is quite significant. That is why a teacher was not able to give proper guidelines and identify those students who are at risk.Sothatiswhytheyproposeapredictivemodeltoidentifythestudentareatriskincomputerprogrammingcourses. Toidentifyingthosestudentswhoareatrisk,theyusestudentstaticanddynamicdatatotraintheirproposedpredictive modelusingseveraladvancedmachinelearningalgorithmsontheirbagoftheclassifiertofindthosestudentswhoareat risk,fromtheirpredictivemodelusingstaticstudentdataandevery weekstudentdynamicdata.Theygenerateaweekly report based on that report and identify those students who are at risk. Those students are not concentrating or not focusing on the courses or even identifying those students are having some other problem. From the prediction model result, those students are at risk and give customized feedback via email. They also compare week reports and extract mainfeaturesandusethemtogeneratethefollowingweekreport.
Theproposedpredictivemodelhasjustone-yearstudentcohortsdata,andtheresultcamesignificantlywell,but inthefuture,theycanuseseveralyearsofstudentcohortsdata,whichwillhelptohaveabetterresult.Moreover,adding some more modalities to the system like video recording during the lab session. So that they can track student behavior and identify students at risk, and based on that, they can provide a better guide to the students. Then the system could have a more advanced method like tokenism. In the future and they can remove opt-out students. This means those students who drop the course or opt-out after mid and are also getting the same kind of customized feedback messages andemail.
[1] Azcona, D., Hsiao, I.-H., and Smeaton, A. F., 2019, “Detecting students-at-risk in computer programming classes with learninganalyticsfromstudents’digitalfootprints,”UserModelingandUser-AdaptedInteraction29,759–788.
[2] Kohavi, R., et al., 1995, “A study of cross-validation and bootstrap for accuracy estimation and model selection,” in Ijcai,Vol.14(Montreal,Canada).pp.1137–1145.
[3] Lu, O. H., Huang, J. C., Huang, A. Y., and Yang, S. J., 2017, “Applying learning analytics for improving students engagement and learning outcomes in an moocs enabled collaborative programming course,” Interactive Learning Environments25,220–234.
[4] Bravo, C., Duque, R., & Gallardo, J. (2013). A groupware system to support collaborative programming: Design and experiences.JournalofSystemsandSoftware,86(7),1759–1771.
Complected M.Tech CSE at IIT Bombay,Maharashtra
