International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Shwethashree GC1, Vishwas S Jois2, Sudeep K3 ,Tippesh Naik C4 , Suraj S5
1Assistant Professor, Dept of Computer Science and Engineering, JSS science & Technology University, Karnataka, India
2,3,4,5UG Student, Dept of Computer Science and Engineering, JSS science and Technology University, Karnataka , India ***
Abstract This paper presents a transfer learning approach to summarize sports match videos by leveraging the single stage detection principle of YOLO coupled with simple speech analysis. The main motive here is, to extract frames of importance in a sports video. The definition of importance of frame can vary according to the sport under consideration. Scope of these definitions are up to the individuals' needs, out of a sports match, Cricket and Football are the two sports under the consideration of this Paper. Crowd cheer is the event which can give an inkling to the important events that is taking place in the game. Thus, crowd cheer is considered as a common look out event for both the games. Additionally, for football Red Card or Yellow Card shown by referee and a significant change in the score of the team within a short time, for cricket is considered as primary events in this Paper. Same are looked for, from video and corresponding sub clips are concatenated to produce a summarized video, In layman's terms highlights of the match.
Key Words: Summarization, OCR ,YOLO ,Object DetectionSports highlight generation is the task of creating a summaryofasporteventthatgivestheviewerasummary ofthegamethroughitskeymoments.Ingeneral, theyare created according to user description. There are many videoretrievaltechniquesavailablemostofwhichdepend on user description, tags and thumb nails which are not very descriptive. It also depends on the content creator who can add click baits and irrelevant description which are not accurate. In this case, an automated tool that can generatethehighlightscanbecomehandy.
Existing efforts in this regard consider only single features like background audio analysis or important frame detection which is being generic to all category of videosisusedtogeneratehighlightswhichcanoftenmiss out other important events due to obvious discrepancies in audio or definition of importance might change accordingtothesport.Thiswouldratherlead todecrease inefficiencyoftheoutcome.Thus,here,throughthispaper weareaimingatgathering alltheimportanteventsbased onthepre definedcriteriabytheadditionofnewefficient
value:
features to the model. The aim here is to come up with a simplewebapplicationwhereusercanuploadthevideoof the sport and get the video rendered on the same platform.
[1] Sanchit Agarwal, Nikhil Kumar Singh, Prashant Giridhar Shambharkar proposed a novel method for automatic annotation of events and highlights generation forcricketmatchvideos.Thevideosaresplitintointervals denoting one ball clip using a Convolutional Neural Network and Optical Character Recognition. CNN detects the start frame of a ball. OCR is used to detect the end of the ball and to annotate it by recognizing the change in runs or wickets. This proposed framework is able to annotate events and generate sufficiently good highlights for four full length cricket matches. But this method requires more of processing techniques in order to annotate
[2]Pushkar Shukla, Hemant Sadana,Apaar Bansal, Deepak Verma, Carlos Elmadjian, Balasubramanian Raman, Matthew Turk proposed a model that considers both event based features and excitement based features to recognize and clip important events in a cricket match. Replays,audiointensity,playercelebration,andplayfield scenarios are examples of cues used to capture such events.Basically,alltheeventsweregroupedtoformsub highlights event driven highlights and excitement driven highlights. Events coming under event driven highlights areboundaries,sixes,wickets,milestonesandthoseunder excitement driven highlights are Audio cues and player celebrations.
[3] Ritwik Baranwal suggested on detecting exciting events in video using complementary information from theaudioandvideodomains.First,amethodofaudioand video elements separation is proposed. Thereafter, the “level of excitement” is measured using features such as amplitude, and spectral center of gravity extracted from the commentator speech’s amplitude to decide the threshold. Finally, audio/video information is fused accordingtotime orderscenes whichhas“excitability” in order to generate highlights of cricket. The techniques
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
described in this paper are generic and applicable to a varietyoftopicandvideo/acousticdomains
[4]Mayu Otani, Yuta Nakashima, Esa Rahtu, Janne Heikkil and Naokazu Yokoya presented a video summarization technique for an internet video to provide a quick way to yoverview its content. They propose to use deep video features that can encode various levels of content semantics, including objects, actions, and scenes. A deep neuralnetworkthatmapsvideosaswellasdescriptionsto a common semantic space and jointly trained it with associated pairs of videos and descriptions was designed. To generate a video summary, the deep features were extracted from each segment of the original video and apply a clustering based summarization technique to them.
[5]AjeetSinghRamPathaka,ManjushaPandeya,Siddharth Rautaraya worked on Application of Deep Learning for Object Detection. Deep learning frameworks and services available for object detection are also discussed in the paper. Benchmarked datasets for object localization and detection released inhas been discussed. State of the art deep learning based object detection techniques have been assessed and compared. Deep learning frameworks and services available for object detection are also enunciated
[6] P.K. Sandhya Balakrishnan, L. Pavithira in their paper aimed to optimize Convolution Neural Networks (CNN) using Simulated Annealing (SA), for optical character recognition.TheresultsofaDBNareoftenhighlybasedon settings in particular the combination of runtime parameter values for Deep Learning. Simulated Annealing is proposed to increase the results of Convolution Neural Network. The classification accuracy from the proposed method is lower than the original of CNN for variation of fonts. The proposed method could potentially be employedandtriedforbenchmarkdataset.
[7] Washington L.S. Ramos, Michel M. Silva, Mario F. M. Campos, Erickson R. Nascimento proposed a novel methodology to compose the new fast forward video by selectingframes based onsemanticinformation extracted from images. Proposed method analyzes the semantic scoreofeachframeandsegmentsthevideointosemantic and non semantic parts. Based on the length of each segment and the desired speed up for the final video, an optimization function is solved to select different speed ups for each type of segment. The frame selection is performedbyashortestpathalgorithm.
The entire system is composed of four different modules. All of these modules are independent of each other. The Deep learning models for Object Detection and OCR are specific to each sport. Speech Analysis and User Interface modulearecommontoboththesports.Datasetiscustom built [13] containing images related to that particular sport. Images are annotated accordingly. The entire video is made to pass through the modules in the same manner listeddownunder.
A.ObjectDetectionModule.
B.OCRmodule.
C.SpeechAnalysismodule.
D.VideoProcessing.
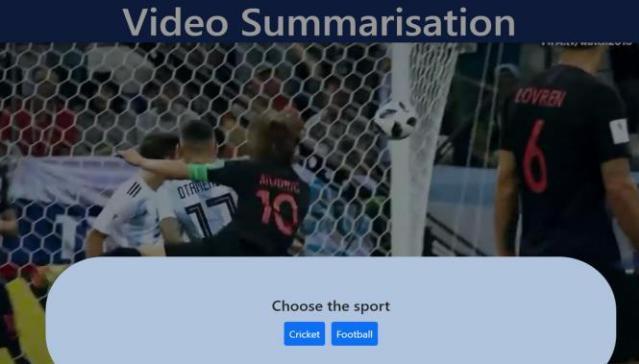
A User Interface will be provided where the user is given choices of sports category, the video of which has to be summarized.Usercanthenuploadthevideo.
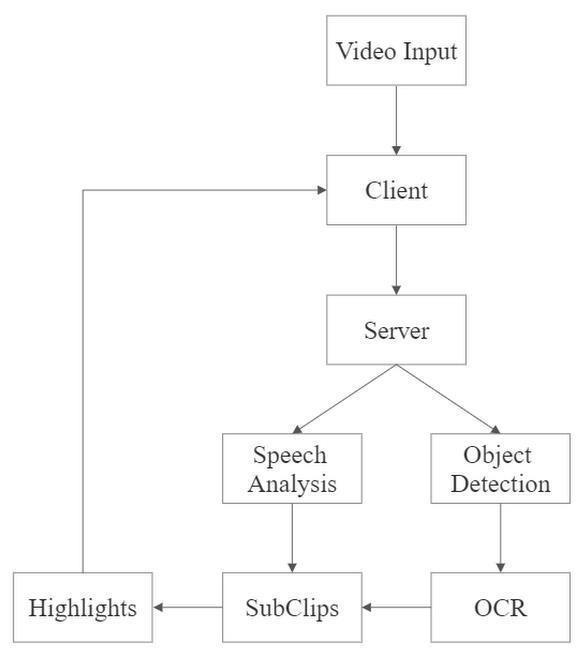
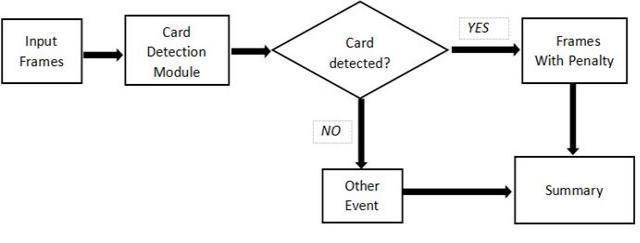
At first, the video enters Object Detection Module For football, all the annotated images are trained on yolo model using transfer learning method[9]. Video under consideration for summarization is split into frames [18] and each of these frames are passed through Object Detectionmodeltocheckifcardispresentintheframe.If
Factor value:
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
so,isthecase,thenasub clipwith15secondsintervalon eitherendsfromthattimestampareextractedandmarked asimportantevent.SimilarlyforCricket,alltheannotated scoreboard images are trained on yolo model using transferlearningmethod[12].TheframesoftheVideoare then passed through Object Detection model in order to detect for scoreboard in that particular frame[14]. If so then the frame is considered for processing in OCR module.
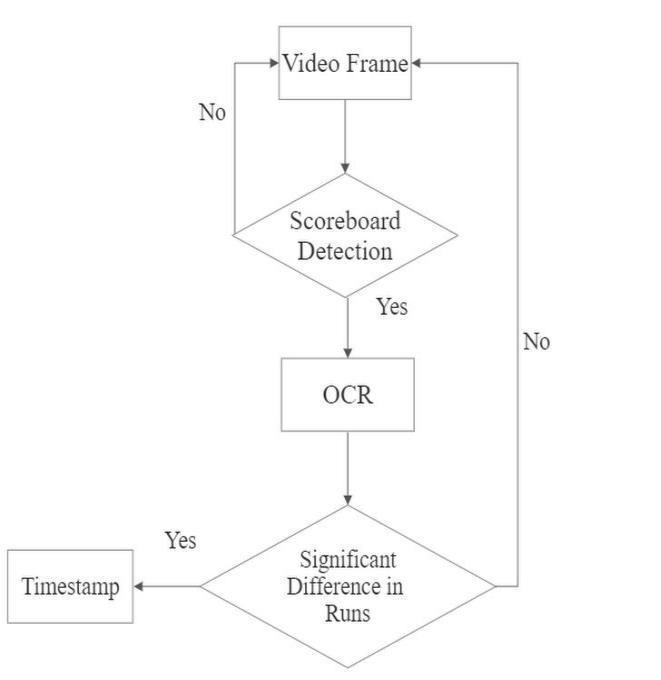
In case of cricket, the images qualified by Object Detectionmodelareprocessedtodeterminethescoreon scoreboard. The contents in the scoreboard are kept underscannerforeveryframethatcomesintheinterval of 10 seconds. After contents are determined, runs area and wickets area are bifurcated. Then, the runs and wickets are compared separately. If a significant change in runs is found i.e. if diff = 3,4,5,6 or if there is an increment in the wickets area, the sub clips of duration 30 seconds with 15 seconds on either side of the timestamp of that particular frame is extracted and considered as important event. In case of Football, if there is a change in goal counts area, the sub clips of duration 30 seconds with 15 seconds on either side of the timestamp of that particular frame is extracted and consideredasimportantevent.[10]
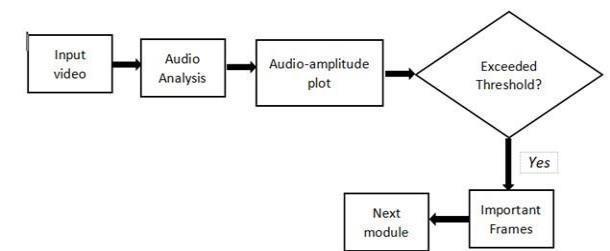
The entire sports video is fed into the librosa audio processor[8].Athresholdenergyforchunkisdefined.The duration of the video from which the amplitude of the crowd cheer ascends till it descends is noted down if the energy chunk crosses the defined threshold. Sub clips are extracted from the second the amplitude rises till the secondamplitudefallsdownthethreshold.[16]
All the timestamps from above modules are made to undergo union operation and sorted in ascending order. These timestamps are then used to extract sub clips from the Original Video. All the sub clips are concatenated to produce the highlights or summarized Video. The summarizedvideoisthenrenderedinthesameplatform.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
5.1
1) FootballCardsDataset:600annotatedimages containingcardsshownbyreferee.
2) ScoreCardsDataset:250annotatedimages consistingofscoreboards.
5.2
mAP 0.65 Threshold 0.5
Table 1: CardDetectionModel
mAP 0.96 Threshold 0.5
Table 2: ScoreboardDetectionModel
TheObjectDetectionmodelforcarddetectionwastrained on pre trained yolo v3 model, with batch size 4 and num_iterations 10 on 500 images and that for scoreboard detectionwastrainedfor180imageswithaforementioned parameters used for training. Card Detection Model [20] achievedanmAPof0.65andScoreboardDetectionModel achieved and mAP 0.96 with IOU 0.5, nms threshold 0.5 and object threshold 0.3. On OCR end, images were initially resized to size 40*40 [19].Images were then resized to 4 D array for keras processing. A sequential model was chosen. The model has 1 CNN layer [11] with kernel size(3,3) with adam optimizer sparse categorical cross entropy as loss function. A hidden layer is present with 128 layers and ReLu activation unit. Final Output layerhas14layerswithSoftMaxactivationunit.
Librosasamplingrateforprocessingtheaudiowassetto 16000.The threshold energy chunk was at 12000.A plot wasgeneratedforenergychunksaswellasdistributionof amplitudeoverthedurationofvideo[17].Thresholdvalue canbechangedasrequired.
moviepylibrarywasusedtoextractandconcatenatesub clips. OpenCv was used to process each frame from the video. All the above functionalities were taking place on the top of flask server and highlighted video was being renderedonreactapplicationinthefrontend.
ClientUserInterfacewasdesignedusingReactJSwhich communicateswithbackendflaskserver Fig 5 : UserInterface
Inthiswork,wepresentedatechniquewhereausercan summarize sports video through a simple application. By examiningeachframetogetanideaifitcould'vebeenthe part of important event, we were able to come up with pool of sub clips denoting important events in the match. The highlights detection was done by passing video through Object Detection, OCR and Audio modules. Subsequently, the detected highlights of the match were rendered to the user on the same platform. Although this model is specific to cricket and football, similar kind of modelscanbetrainedfordifferentsportsbyhavingadata setaccordingly.
The possible extension to this approach, which we have plannedareasfollows:
1.Fromfootball'sperspective,additionalimportantevents canbedefinedlikepenalty,corner kick,off side,free kick. Incaseofcricket,no ball,byes,players'celebrationcanbe thoughtofasimportantevents.
2.Efficiency can be improved if models have relationship between them. An event marked as important by one module can be tested for the same in other modules to validate the outcome of that module. By doing this, false positivescanbereduced.
3.Itusuallytakesmoretimetoprocessvideos,wecan comeupwithfasteralgorithmstopaceupprocessing.
4.Broadcasters can think of implementing real time highlights detection of a sports match. By doing which highlightscanbegeneratedinstantaneously.
5.Insteadofhavingtocreateseparatemodelsforevery game,wecancomeupwithagenericmodelaltogether.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page467
[1]“Automatic Annotation of Events and Highlights Generation of Cricket Match Videos” by Sanchit Agarwal, NikhilKumarSingh,PrashantGiridharShambharkar,2019
[2]“Automatic Cricket Highlight generation using Event Driven and Excitement Based features” by Pushkar Shukla, Hemant Sadana, Apaar Bansal, Deepak Verma, Carlos Elmadjian, Balasubramanian Raman, Matthew Turk,2020.
[3]“AutomaticSummarizationofCricketHighlights usingAudioProcessing”byRitwikBaranwa,2020.
[4]“Video Summarization using Deep Semantic Features” byMayuOtani,YutaNakashima,EsaRahtu,JanneHeikkil¨a andNaokazuYokoya,2016.
[5]“Application of Deep Learning for Object Detection” by Ajeet Ram Pathaka, *, Manjusha Pandeya,, Siddharth Rautaraya,2018.
[6]“Multi fontOpticalCharacterRecognitionUsingDeep Learning”byP.K.SandhyaBalakrishnan,L. Pavithira,2019.
[7]“FastForwardVideoBasedOnSemanticExtraction”by Washington L.S. Ramos*, Michel M. Silva*, Mario F. M. Campos,EricksonR.Nascimento,2016.
[8]”Librosa:AudioandMusicSignalAnalysisinPython”by Brian McFee,Colin Raffel, Dawen Liang, Daniel P.W. Ellis, Matt McVicar, Eric Battenbergk, Oriol Nieto,Research Gate,2015
[9]"One Shot Learning for Custom Identification Tasks; A Review" N. O’ Mahonya, Sean Campbella, Anderson Carvalhoa, L. Krpalkovaa , Gustavo Velasco Hernandeza, SumanHarapanahallia,D.RiordanaandJ.Walsha
[10]"Optical character recognition using deep learning techniques for printed and handwritten documents.", SSRN, 2020. Sanika Bagwe,Vruddhi Shah,Jugal Chauhan, Purvi Singh Harniya,Amanshu Shah Tiwari,Vartika Gupta,Durva Raikar,Vrushabh Gada, Urvi Bheda,Vishant Mehta,MaheshWarang,NinadMehendale
[11]"Research Paper on Basics of Artificial Neural Network",IJRTC,2014,Ms. Sonali. B. Maind ,Ms. Priyanka Wankar
[12]"ObjectDetectionandRecognitionUsingYOLO:Detect and Recognize URL(s) in an Image Scene" by John TemiloluwaAjala
[13]"EffectofDatasetSizeandTrain/TestSplitRatiosin QSAR/QSPRMulticlassClassification"AnitaRácz,Dávid BajuszandKárolyHéberger,MDPI,2021
[14]“Yolov3: An incremental improvement,”J. Redmon , arXiv,2018
[15]"ImageAI:Comparison Study on Different Custom Image Recognition Algorithms", Manuel Martins,David Batista Mota ,Francisco dey Morgado,Cristina Wanzeller,Researchgate,2021
[16]"Audio to Sign Language Conversion" Shivangi Saharia, Priyanka Kulkarni, Amardeep Bhagat, Himalaya Prakash,AmberKesharwani,IJARCCE,2020
[17]"Data visualization: an exploratory study into the software tools usedby businesses", Michael Diamond,Angela Mattia,Journal Of Intstructional Pedagogies,2017
[18]"OpenCV for Computer Vision Applications",Naveen kumarMahamkali,VadivelAyyasamy,ResearchGate,2015
[19]"The NumPy Array: A Structure for Efficient Numerical Computation", Stéfan Johann van der rosie Walt,S. James Chris Colbert,Gael Varoquaux, ResearchGate,2011
[20]"ATour of TensorFlow",Peter Goldsborough,Research Gate,2016
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page468