International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
2
1M.Tech Final Year Student, Department of Computer Science and Engineering, Government College of Engineering, Aurangabad, Maharashtra, India.
2Assistant Professor, Department of Computer Science and Engineering, Government College of Engineering, Aurangabad, Maharashtra, India. ***
Abstract - Diabetes mellitus is an illness that arises whenever pancreas fails to generate enough insulin or if the body's glucose is inefficiently used. Hormone called insulin helps to stabilize blood sugar levels. Uncontrolled diabetes causes hyperglycaemia, or high blood sugar, which causes severe harm to various organ functions. Since the primary signs of the disease are difficult to recognise, a suitable technique of forecasting will aid individuals in self diagnosis. In this study, symptoms are used for classification instead of performing an insulin test. Machine learning implementation becomes much easier with the availability of data on which models can be trained. Multilayer perceptron, K Nearest Neighbour, Gaussian Naïve Bayes, and Linear Discriminant Analysis are among machine learning models implemented. A diabetes diagnostic forecast model for high risk or early stage diabetes is developed selecting the one with the best accuracy. The accuracy of the Multilayer Perceptron on the testing data is 99 percent, making it the ideal model for forecasting diabetes.
Key Words: Machine Learning, Diabetes Prediction, MultilayerPerceptron,Healthcare
Diabetes is a severe public health issue that affects 463 millionpeopleworldwide.By2045,itisexpectedtoimpact 700 million people globally. According to prevalence estimates,diabetesisspreadingquicklyinlow andmiddle incomenationsthanitisinhigh incomecountries.Diabetes affectsmorethan77millionpersonsinIndia.Accordingto researchers,thisnumberwillriseto134millionpeopleby theyear2045[1].
Whenpancreasdoesnotcreateanyinsulin,youaresuffering fromtype1diabetes.Whenpancreasdoesn'tcreateenough insulin or your body can't utilise it properly, you are sufferingfromtype2diabetes.Impairedglucosetoleranceas wellasimpairedfastingglycaemiaareintermediarystatesin the shift from normal blood glucose levels to diabetes (particularlytype2),althoughtheyarenotalwayspresent. Gestational diabetes is a disorder that develops during pregnancy and increases the chance of developing type 2 diabetes in the future. Whenever blood glucose levels are above normal though not high enough to be diagnosed as
diabetic, gestational diabetes is present. Cardiovascular disease,renalfailure,visualloss,nervedamage,infections, foot difficulties, and cognitive impairments are all major effectsofuntreateddiabetes[2].
Healthcare facilitiesare limited, and physicians can only identifyconsiderableamountofpatientsinagivenperiodof time. A quick and accurate diagnosis can aid patients in preventing diabetes and determining whether they have diabetes at a preliminary phase or they are risk of developing diabetes. Patients in our research were not requiredtoundergoanymedicaltests,makingourapproach moreintelligibleandrelevant.Theaimofourresearchisto finda machinelearningmodel whichcanpredictdiabetes riskordiabeteswithgoodaccuracy.
Author used six machine learning algorithms to develop diabetes prediction models: logistic regression, support vectormachine,decisiontree,randomforest,boosting,and neural network. Logistic Regression, Support Vector Machine,andDecisionTreearethefirstthreemodels,and they are basic and intuitive, with lower accuracy than the moresophisticatedremainingthreemodels.Hecompared their testing error results. Best model gave accuracy of 96.2%[3].
Authors created a diabetes prediction model usingneural network. They employed characteristics like PG Concentration, Skin Thickness, Diastolic BP, etc. Many characteristics in that research need a skilled medical examination;itisnotavailabletoeveryone[4].
AuthorsshowedaMatlabimplementationofSupportVector MachineandNaiveBayesalgorithmsinadatasetobtained fromdiabeticpatientsinKosovo.BodyMassIndex,Preand Post meal glucose, Diastolic and Systolic blood pressure, Familyhistoryofdiabetes,Regulardiet,Physicalactivities are the attributes used in their research. Joint implementation of SVM and Naïve Bayes is performed to predictdiabetes[5].
Theauthoroftheresearchsuggestedamodelthatdivides type2diabetestreatmentstrategiesintothreecategories:
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
insulin,food,andmedicine.Themodelwasbuiltusingdata fromtheJABER_ABN_ABU_ALIZclinic,whichhas318health records.ThemodelwascreatedwiththeWEKAtoolalong withJ48classifier,whichhas70.8percentaccuracy[6].
The authors created a model to predict whether or not a person will acquire diabetes based on everyday healthy behaviours.ThePIMAdiabeticdatasetwasutilizedtomake the prediction model, and the CART (Classification and RegressionTrees)machinelearningclassifierwasemployed. Theproposed model might have75percentaccuracyrate [7].
MultilayerPerceptronisusedtosolveproblemswhichare linearly inseparable with the help of backpropagation. Backpropagationisatechniqueforminimisingthedifference amongst the desired output and the actual output by adjusting the weighted values and threshold values continuously.Itconsists ofinput,outputandhiddenlayer [8].
K Nearest Neighbor is non parametric as it makes no assumptions about the distribution of data. It is a lazy learner.Itcalculatesthedistancebetweenkneighbours[9].
Gaussian Naïve Bayes follows Gaussian distribution. For dimensionality reduction challenges, Linear Discriminant Analysisisawidelyusedapproach[10,11].
Accuracy states the efficacy of a classifier as a whole. Precisiondenotesthedegreetowhichthedatalabelsagree withthepositivelabelsassignedbyclassifier.Theefficacyof a classifier in identifying positive labels is measured by recall. The F1 score reflects the relationship between the positivelabelsassignedtodataaswellasthoseassignedbya classifier[12].
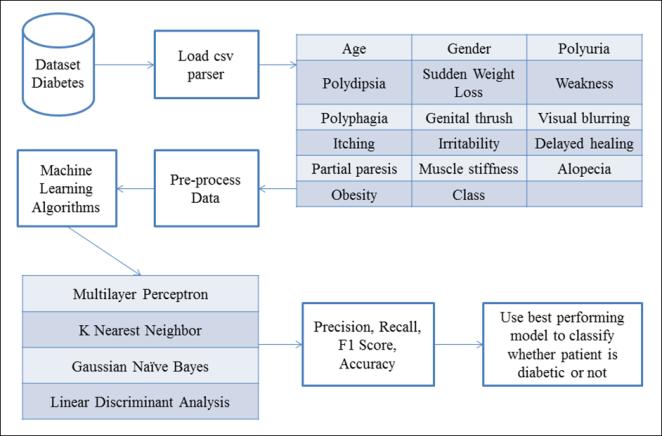
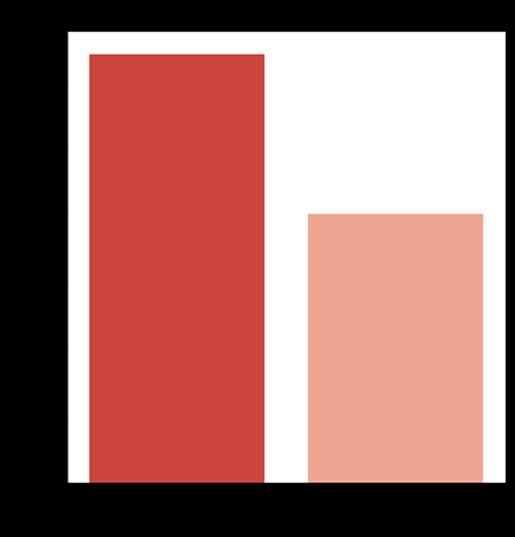
WeutilizeddataviatheUCImachinelearningrepository. Datais gathered via Sylhet Diabetes Hospital patients. Datasetconsistsof17variablesand520records.Thedataset doesnotincludeanynullvalues.Onlynumbervariableisage, whilerestarecategorical.Malesmakeup37%ofthedataset, whilefemalesmakeup63%.45%Malesand90%Females are insulin dependent in given dataset. Figure 2 indicates spreadofdiabetesinthedataset.320peoplearediabeticand 200peoplearenon diabeticinourdataseti.e.62%patients arediabeticand38%patientsarenon diabetic.
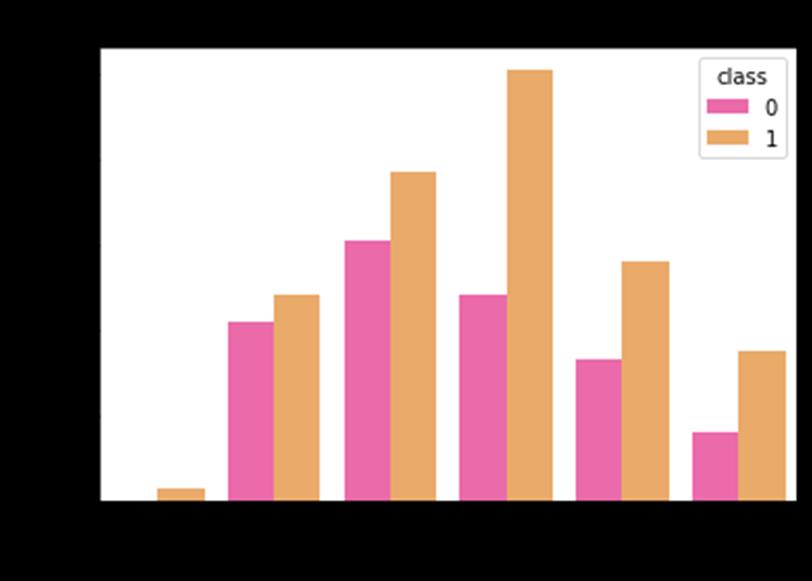
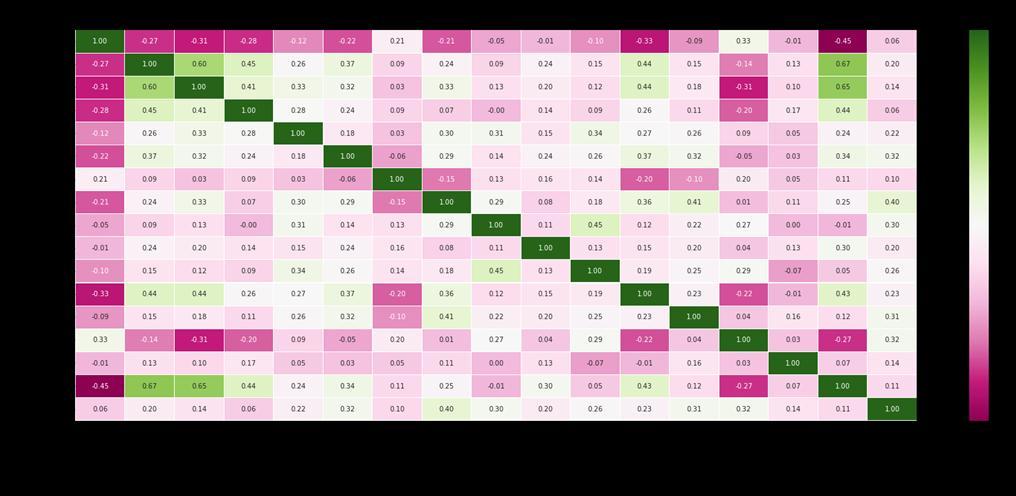
Data pre processing refers to the actions that must be takentoencodeoralterdatasoitwillbeeasilyinterpreted by a machine. First step is to get dataset. Then import necessarylibraries. Then import dataset. Then weneed to handlemissingvaluespresentindataset.Ourdatasetdoesn’t consistofanymissingvalue.Topreparethedataforanalysis, thedatasetwastranslatedfromcategoricallabelstonumeric labels.Aheatmapisvisualrepresentationofdatathatuses colours to display the matrix's value. Brighter colours are utilised to indicate more common values, whereas lighter colours are favoured to indicate less common values. According to Figure 3, a heatmap is plotted to find relationshipbetweendifferentattributes.Polyuriahas0.67 as correlation coefficient and Polydipsia has 0.65 as correlation coefficient with respect to diabetes, which indicatesithasstrongestlinktodiabetes.Diabetesandage revealed a minimal connection with 0.11 as correlation coefficient.Toseeifthereisalinkbetweenageanddiabetes, theagefieldindatasetisconvertedtocategoricaldatatype. As per Figure 4 diabetes is shared evenly across all age groups, there is no properassociation between age and diabetes.Nextstepistodistributeourdataintotrainingand
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
testingsetsrespectively.Thelaststageindatapre processing is feature scaling. It is a strategy for standardising the independentvariablesindatasetinaparticularrange.
Figure 3: HeatmaptoFindCorrelationamongAttributes
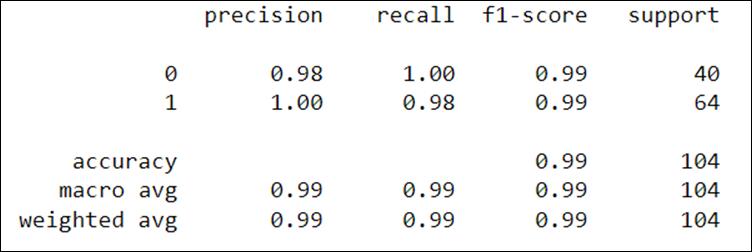
Figure5,asperconfusionmatrix,103patientsarecorrectly classifiedand1ismisclassified.FromFigure6,classification reportindicatesaccuracyandF1scoreof99%.
Thediabetesclassispredictedusingall16characteristics. 80%dataisusedfortrainingthemodeland20%dataisused for testing the model. Once the data is trained, test data predictionsaregenerated,andthealgorithm'sperformance ismeasured.
Afullylinkedmultilayerperceptroncomprisesofinput, output, and hidden layers. It's often used in healthcare to identifycomplicateddiseasestates.Thesizesofthehidden layersarechangedtothreelayerswithelevennodes.From

Itsortsdatapointsintogroupsdependingonwhichdata pointsareclosesttoit.Wehavesetneighborssizeto5.The distance metric issetto minkowski.FromFigure7, as per confusionmatrix,100patientsarecorrectlyclassifiedand4 are misclassified. From Figure 8, classification report indicatesaccuracyandF1scoreof96%.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page392
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
confusionmatrix,90patientsarecorrectlyclassifiedand14 are misclassified. From Figure 12, classification report indicatesaccuracyandF1scoreof87%.



Figure 7: KNearestNeighborConfusionMatrix
Figure 11: LinearDiscriminantAnalysisConfusionMatrix
Figure 8: KNearestNeighborClassificationReport
It is an example of Generative Model. A Gaussian distributionisfollowedbyeveryclass.Thecharacteristicsare assumed to be independent so covariance matrices are diagonalinnature.FromFigure9,asperconfusionmatrix,93 patients are correctly classified and 11 are misclassified. FromFigure10,classificationreportindicatesaccuracyand F1scoreof89%.
Figure 12: LinearDiscriminantAnalysisClassification Report
Best performing model is used for diabetes prediction or diabetesriskprediction.SoMultilayerPerceptronisusedfor modelbuilding.
For measuring performance of machine learning we have usedPrecision,Recall,F1ScoreandAccuracy.
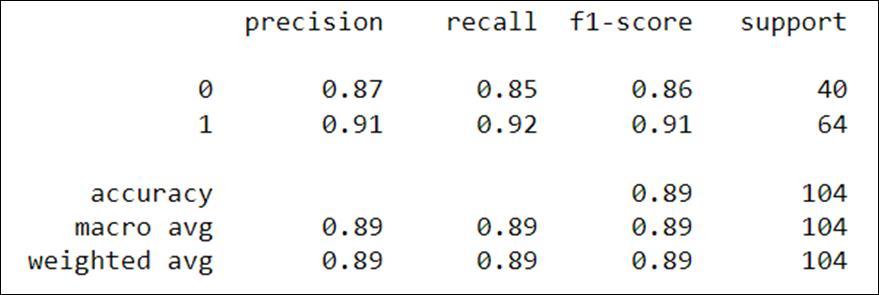
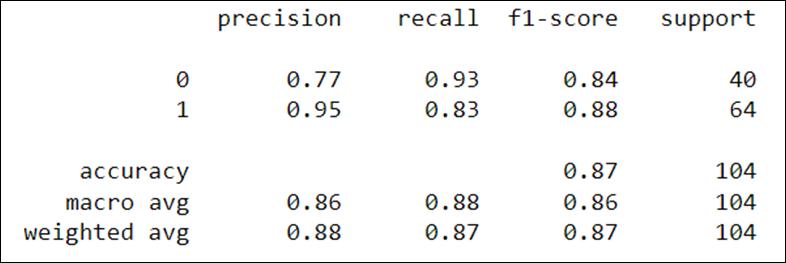
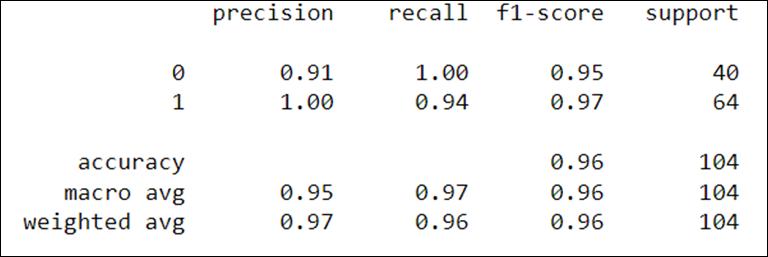
Figure 9: GaussianNaïveBayesConfusionMatrix
Precision=Tp/(Tp+Fp)
Recall=Tp/(Tp+Fn)
F1Score=2*Precision*Recall/(Precision+Recall)
Accuracy=(Tp+Tn)/(Tp+Tn+Fp+Fn)
Figure 10: GaussianNaïveBayesClassificationReport
It is used for dimensionality reduction to solve classificationissues.Acommoncovariancematrixisassumed by Linear Discriminant Analysis. From Figure 11, as per
Where Tp = True Positive, Fp = False Positive, Fn = False Negative,Tn=TrueNegative
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Table 1: PerformanceofMachineLearningModels
Precision Recall F1Score Accuracy 0 1 0 1 0 1
MultilayerPerceptron Classifier 0.98 1.0 1.0 0.98 0.99 0.99 0.99
KNeighborsClassifier 0.91 1.0 1.0 0.94 0.95 0.97 0.96
GaussianNaïveBayes 0.87 0.91 0.85 0.92 0.86 0.91 0.89
LinearDiscriminant Analysis 0.77 0.95 0.93 0.83 0.84 0.88 0.87
From Table 1, among given machine learning algorithms, MultilayerPerceptronhashighestaccuracyof99%whereas LinearDiscriminantAnalysishaslowestaccuracyof87%.So Multilayer Perceptron is used further in order to predict diabetesordiabetesrisk.
Agooddiabetesforecastingmodelwillaiddoctorsinmaking precisedecisionsandensuringthatpatientsreceiveprompt medicalattention.Weusedexploratorydataanalysisonour dataset to determine which characteristics are strongly linked to diabetes. We analysed the performance of four machine learning algorithms. Multilayer perceptron gave highest accuracy of 99% so it used further to predict diabetesordiabetesrisk.Wecantestalgorithmsonother unstructured diabetes datasets in the future to forecast diabetes.
[1] Luhar,Shammi,DimpleKondal,RebeccaJones,RanjitM. Anjana,ShivaniA.Patel,SanjayKinra, LyndaClarkeet al. "Lifetime risk of diabetes in metropolitan cities in India."Diabetologia64,no.3(2021):521 529.
[2] World Health Organization, 2016. World Health OrganizationGlobalReportonDiabetes.Geneva:World HealthOrganization.
[3] Ma,Juncheng."MachineLearninginPredictingDiabetes in the Early Stage." In 2020 2nd International ConferenceonMachineLearning,BigDataandBusiness Intelligence(MLBDBI),pp.167 172.IEEE,2020.
[4] El_Jerjawi, Nesreen Samer, and Samy S. Abu Naser. "Diabetes prediction using artificial neural network."InternationalJournalofAdvancedScienceand Technology121(2018).
[5] Tafa, Zhilbert, Nerxhivane Pervetica, and Bertran Karahoda. "An intelligent system for diabetes
prediction."In20154thMediterraneanConferenceon EmbeddedComputing(MECO),pp.378 382.IEEE,2015.
[6] Ahmed,TarigMohamed."Developingapredictedmodel for diabetes type 2 treatment plans by using data mining."JournalofTheoreticalandAppliedInformation Technology90,no.2(2016):181.
[7] Anand,A.,&Shakti,D.(2015,September).Predictionof diabetesbasedonpersonallifestyleindicators.In2015 1st International Conference on Next Generation ComputingTechnologies(NGCT)(pp.673 676).IEEE.
[8] Singh, Jaswinder, and Rajdeep Banerjee. "A study on single and multi layer perceptron neural network." In2019 3rd International Conference on Computing MethodologiesandCommunication(ICCMC),pp.35 40. IEEE,2019.
[9] Ray, Susmita. "A quick review of machine learning algorithms." In2019 International conference on machinelearning,bigdata,cloudandparallelcomputing (COMITCon),pp.35 39.IEEE,2019.
[10] Agarwal,S.,B.Jha,T.Kumar,M.Kumar,andP.Ranjan. "Hybrid of naive bayes and Gaussian naive bayes for classification: a map reduce approach."International Journal of Innovative Technology and Exploring Engineering8,no.6S3(2019):266 268.
[11] Tharwat,Alaa,TarekGaber,AbdelhameedIbrahim,and AboulEllaHassanien."Lineardiscriminantanalysis:A detailedtutorial."AIcommunications30,no.2(2017): 169 190.
[12] Sokolova, Marina, and Guy Lapalme. "A systematic analysis of performance measures for classification tasks."Informationprocessing&management45,no.4 (2009):427 437.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page394