International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
2
1,2,3,4 Student, Dept. of Information Technology, Dwarkadas J. Sanghvi College of Engineering, Maharashtra India 5Professor, Dept. of Information Technology, Dwarkadas J. Sanghvi College of Engineering, Maharashtra, India ***
Abstract The volume of textual data has expanded exponentially in recent years, making it a nuisance to store valuable information. Mining this enormous dataset containing dissimilar structured or unstructured data to identify hidden patterns for actionable and data driven insights can be troublesome. This information must be summarizedtoobtainmeaningfulknowledgeinanacceptable time.
This paper examines techniques for abstractive text summarization and validates these techniques on CNN/Daily MaildatasetusingROUGEscores.Inadditiontotheusecases, theirfeaturesandlimitationsintherealworldarepresented. The difficulties that arise during the summarization process and the solutions put forward in each approach are scrutinized, investigated, and explored. After evaluating the various approaches, it was found that the most common strategies for abstractive text summarization are recurrent neural networks with an attention mechanism and the transformer architecture. On experimenting, the results displayed that text summarization with Pegasus large model achievedthehighestvaluesforROUGE 1andROUGE L(44.17, 41.11 respectively). A detailed study was done to see how the best results were attained by the models applying a Transformer.
Key Words: Abstractive Text Summarization,Attention mechanism, BERT, Neural Networks, Pegasus, Transformer.
There is a need to provide a satisfactory system for extractinginformationmorequicklyandefficientlybecause of the rate at which the internet has grown and consequently,theenormousvolumeofonlineinformation anddocuments.Manualextractionofsummaryfromalarge written document is quite challenging for humans. Automatic text summarization is key for addressing the issuesoflocatingrelevantpapersamongthevastnumberof documentsavailableandextractingimportantinformation fromthem.Asummary,accordingtoRadevetal.[1].,is"a textthatisproducedfromoneormoretexts,thatconveys importantinformationintheoriginaltext(s),andthatisno longer than half of the original text(s) and usually, significantly less than that”. Text summarizing involves extracting and looking for the most meaningful and noteworthiest information in a document or collection of
value:
linkedtextsandcondensingitintoashorterversionwhile maintaining the overall meaning. The task of producing a succinctandfluentsummarywhilekeepingvitalinformation content and overall meaning is known as automatic text summarization. In recent years, several methods for automatictextsummarizinghavebeenfoundanddeveloped, and they are now widely utilized in a variety of fields. Automatictextsummarizingisdifficultandtime consuming for computers because they lack human knowledge and language competence. Humans, as opposed to computers, cansummarizeadocumentbyreadingitentirelytohavea bettercomprehensionofitandthenwritingasummarythat highlights the essential ideas. Text summarizing raises a number of difficulties, including, but not limited to; text identification,textinterpretation,summarygeneration,and examinationofthecreatedsummary.Thenumberofinput documents (single or several), the goal (generic, domain specific,orquery based),andtheoutputallinfluencehow textsummarizationisdone(extractiveorabstractive).The emergence and progress of automatic text summarization systems,whichhaveproducedconsiderableresultsinmany languages,necessitatesareviewofthesemethods.
Therearetwodifferentwaysoftextsummarization: Extractive Summarization: Extractive summarization attemptstosummarizearticlesbyfindingkeysentencesor phrasesfromtheoriginaltextandpiecingtogethersections ofthecontenttocreateareducedversion.Thesummaryis thencreatedusingtheretrievedsentences.
Unlikeextraction,AbstractiveSummarizationreliesonthe ability to paraphrase and condense parts of a document utilizingadvancednaturallanguageapproaches.Abstractive machinelearningalgorithmscanconstructnewphrasesand sentences to capture the meaning of the source content. When done effectively in deep learning issues, such abstractioncanhelpovercomegrammaticalmistakes.
Theearliestapproachesinabstractivesummarizationrelied on statistical methods heavily reliant on heuristics and dictionaries for substitution of words. The methods consideredforreviewinthispaperare
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
In2015,deeplearningtechniqueswereusedforthefirst time in abstractive text summarization by Nallapati et al., andtheproposedapproach[2]wasbasedontheencoder decoderarchitecture.
The encoder decoder models have been constructed to resolve Sequence to Sequence problems (Seq2Seq). The Seq2Seq models convert the neural network's input sequencerightintoasimilarsequenceofletters,words,or sentences. This model is utilized in numerous NLP applications, inclusive of system translation and textual content summarization. The input sequence in textual contentsummarizationisthereporttobesummarized,and theoutputsequenceisthesummary.
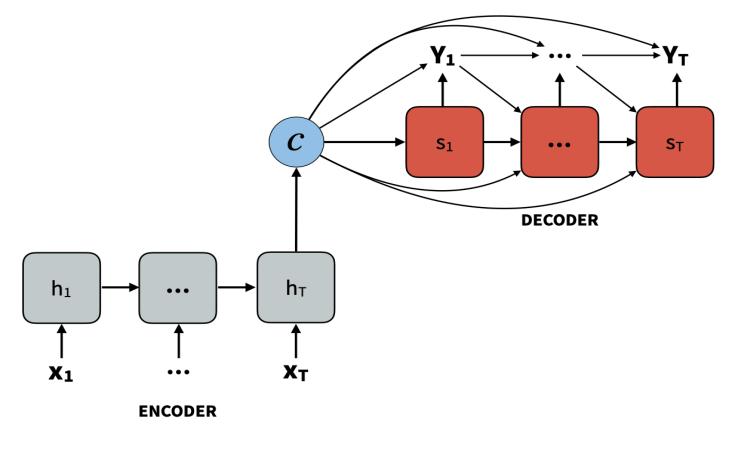
TwoRNNs,onefunctioningasanencoderandtheotheras adecoder,makeupthebasicencoder decoderarchitecture for language problems. The encoder receives the input sequenceandsummarizesthedataininternalstatevectors, also known as context vectors. The encoder's outputs are discarded, leaving just the internal states. To help the decodermakeaccuratepredictions,thiscontextvectorseeks toincludeinformationforallinputelements.TheRNNisa decoderinwhichthestartingstatesaresettothefinalstates, allowingthefinalstate'scontextvectortobeinputintothe decodernetwork'sfirstcell.TheSTARTtokenisalwaysthe initial input to the decoder. Each decoder's recurrent unit usesthistocreateanoutputaswellasitsownhiddenstate by taking a hidden state from the preceding unit. This procedureiscontinueduntiltheENDtokenisencountered. Finally, at each time step, the loss on projected outputs is computed,andthemistakesarebackpropagatedovertime toadjustthenetworkparameters.
before being utilized for NLP tasks such as text summarization.[4].
When given long phrases, a basic encoder decoder architecture may have problems because the size of the encodingis fixedfortheinputstringwhichimpliesthat it cannotexamineallthepartsofthelonginput.
Theattentionmechanismwascreatedtohelprecallthe informationthathasasubstantialinfluenceonthesummary. At each output word, the attention mechanism is used to calculate the weight between the output word and each inputword;theweightssumuptoone.Theusageofweights hastheadvantageofshowingwhichinputwordinrelation totheoutputwordmeritsextraattention.Afterpassingeach input word, the weighted average of the decoder's last hidden layers is calculated and given to the SoftMax layer alongwiththelasthiddenlevelsinthecurrentphase.Based onthecontextvectorslinkedwiththesourcelocationand previouslycreatedtargetwords,themodelpredictsatarget word. Bidirectional RNNs are used in the attention mechanism. The level of attention given to words is representedbythecontextvector.
Fig -2:Attentionmechanism[5]
Proposed by X. Wan et.al [6], the model follows these steps:1.Summarygenerationbythebackwarddecoderfrom righttoleft,similartotheSeq2Seq Attnmodel;2.Boththe encoderandthebackwarddecodershoulduseanattention mechanismsothattheforwarddecodermayconstructthe summary from left to right. The forward and reverse decodersbothsupportthepointerapproach.
ForthisarchitecturethechosenbaselinemodelisLEAD 3. Themaindrawbackwiththisapproachisthatitrequires anextensivedatasetwhichtakesalongtimetotrain.
TheattentionmechanismwasintroducedbyBahdanau, Cho, and Bengio [3] in the context of machine translation
The forward decoder is initialized with the backward encoder'slasthiddenstate,whereasthebackwarddecoder isinitializedwiththeforwardencoder'slasthiddenstate.As aresult,themodeliscapableofthinkingaboutthepastand future,resultinginbalancedoutputs.Theinput,aswell as the input in reverse, are encoded into hidden states. The hidden states from both the forward and backward directionsarethencombinedandsenttothedecoder.When encoding longer sequences, bidirectional encoders have demonstratedbetterperformance.

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Neural sequence to sequence models tend to repeat themselves and reproduce factual details incorrectly. To resolve this problem, See, Liu, and Manning proposed Pointer GeneratorNetworks[7],inwhichtheyuseahybrid pointer generator network that allows for both word copyingandwordgenerationfromapredefinedvocabulary. While maintaining the ability to generate fresh words through the generator, pointing facilitates the accurate reproduction of information. Coverage is a system for keepingtrackofwhathasbeensummarizedandpreventing duplication.
Drawback Insteadofintroducingnewterminology,the basic premise of this technique is to present a summary basedonthesourcetext.
XhixinLietal.[8]developedadoubleattentionpointer network based encoder decoder model (DAPT). In DAPT, importantinformationfromtheencoderiscollectedbythe self attentionmechanism.Thesoftattentionandthepointer networkprovidemoreconsistentcorecontentandcombine the two results in precise and reasonable summaries. Furthermore, the improved coverage mechanism is employedtoavoidduplicationandenhancetheoveralllevel ofthesummariesproduced.
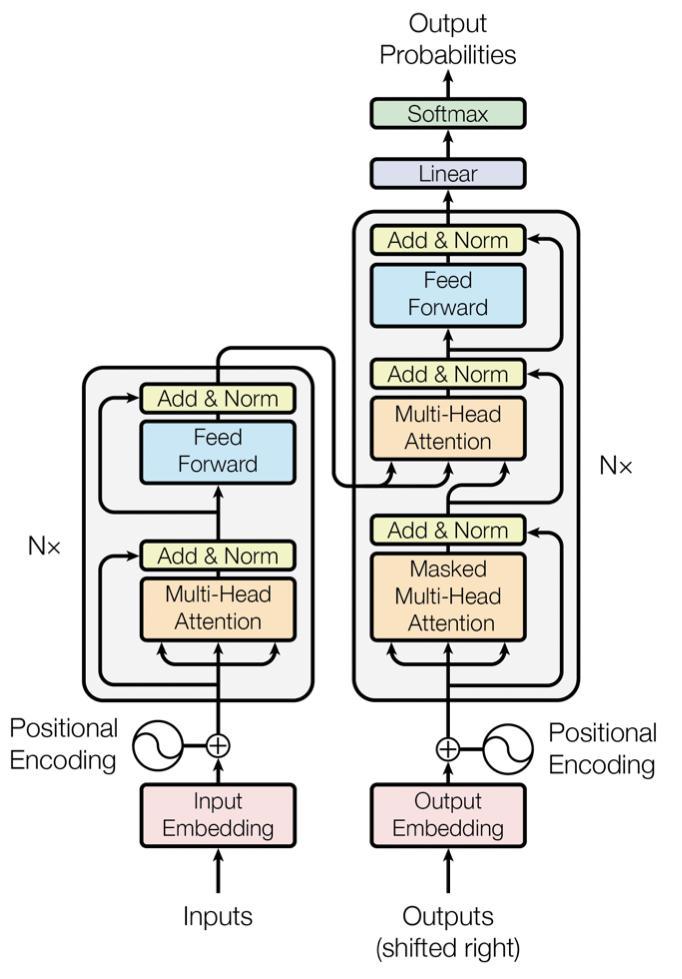
Vaswanietal.[9]proposedanewbasicnetworkdesign, theTransformer,basedentirelyonattentionmechanisms, with no recurrence and convolutions. The model uses positionalencodingtokeeptrackoftheorderofsequence. Only attention mechanism and feedforward networks are utilized for mapping dependencies between input and output.
The attention is calculated using Scaled Dot Product Attention dotproductbetweenaquery,akey,andavalue matrixQ,K,andV.
Attention(Q,K,V)=softmax((QK^T)/√(d_k))V
Equation(1)whereKreferstokeymatrix,Vreferstovalue matrix, Q refers to matrix of queries and dₖ is the dimensionalityofquery/keymatrix.
The scaled Dot Product mechanism runs in parallel on numerous linear projections of input, the output is concatenated,multipliedbyanextraweightmatrix,andthe multi headattentionlayeroutputisthenutilizedasinputto thefeedforwardlayer.
Fig 3:Transformerarchitecture[5]
ThemajoradvantageofTheTransformeristhatitlends itself well to parallelization. In comparison to encoder decodermodelswithattention,Transformerachievesstate of the artperformancewhilsttakinglesstrainingtime.The sequentialarchitecturelimitsefficiencyduringtraining,asit doesnotfullyutilizethecapabilityofGraphicsProcessing Units(GPU).
Thefollowingtransformervariationswereevaluatedfor theliteraturereview:
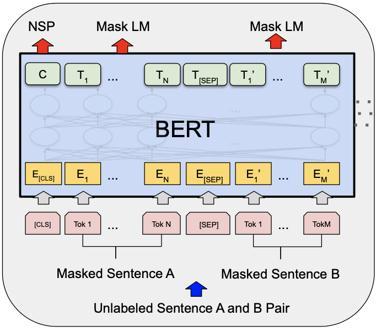
Proposed by Devlin et al. [10] and applied to text summarization[11],BERTisdesignedtoconditionbothleft and right context at the same time to pre train deep bidirectionalrepresentationsfromtheunlabelledtext.BERT isabidirectionallytrainedlanguagemodel,whichmeansit canreadtextfrombothsidessequentially.Asaresult,nowa greater comprehension of language context and flow is attainedthaninthecaseofsingle directionlanguagemodels. BERThastwoobjectives:
A.MaskedLanguageModellinginvolveshidingawordina phraseandthenhavingthemodelidentifywhichwordwas concealed(masked)basedonthehiddenword'scontext.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
B.Next Sentence Prediction assists the model in determining if two provided phrases have a logical, sequentialrelationshiporiftheirrelationshipisjustrandom.
MaskedLanguageModellingandNextSentencePrediction arebothusedtotrainthemodel.Thisisdonetolowerthe lossfunctionofthetwoapproacheswhencombined
2.6.3 BART (sequence to sequence Transformer)
Bart[13] employs a typical machine translation architecture that includes a left to right decoder and a bidirectionalencoder(similartoBERT).Thepretrainingtask entailschangingtheorderoftheoriginalphrasesatrandom and implementing a novel in filling strategy in which text spansarereplacedwithasinglemasktoken.
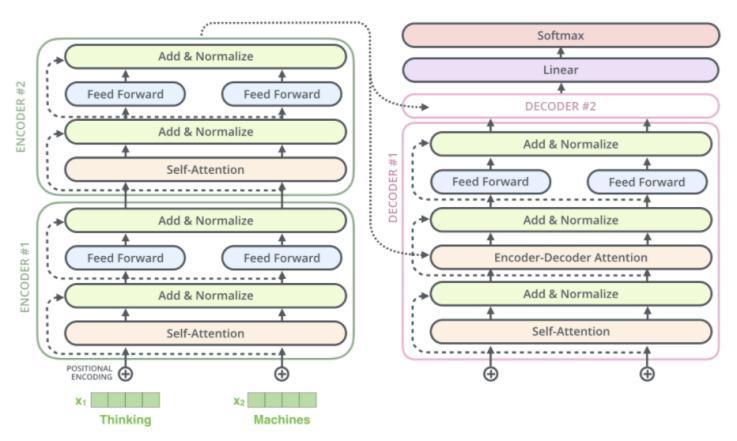
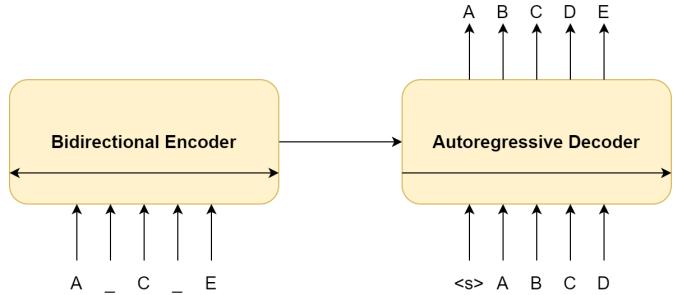
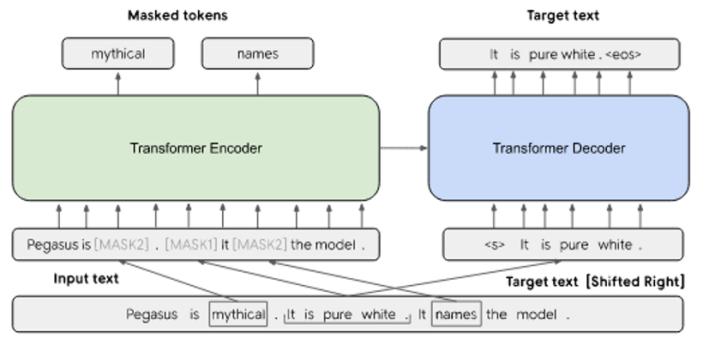
Fig 4:BERT[10]
2.6.2 PEGASUS Abstractive Summarization Pre training with Extracted Gap sentences (sequence to sequence Transformer) [12]
Uses2objectives:
a. Gap sentence generation (GSG): complete sentences fromthedocumentaremaskedoff,andthemodelistrained topredictthesesentencesusingtheremainingsentences.It hasbeenproventhathidingthemostimportantsentences fromapaperismoreeffective.
b.Encoderpre trainedasmaskedlanguagemodel(MLM): Words from sequences are randomly masked, and the sequence'sremainingwordsareusedtopredictthemasked words.
BothGSGandMLMareusedatthesametime.
Pegasusmayrequirepost processingtocorrecterrorsand improvesummarytextoutput.
Fig-6:BART
2.6.4 T5 Text To Text Transfer Transformer (Sequence to sequence Transformer) [14]
IncontrasttoBERT,whichfine tunesthemodelforeach task separately, the text to text framework employs the samehyperparameters,lossfunction,andmodelforalltasks. Inthistechnique,theinputsarerepresentedinsuchaway thatthemodelrecognizesatask,andtheoutputisjustthe "text" form of the projected outcome. Relative scalar embeddingsareusedinT5.
The three objectives that are concerned with T5 are as follows:
a. Language model: It is an autoregressive modelling approachforpredictingthenextword.
b.BERT styleobjective:Masking/replacingwordschosen randomly with a random different word and the model predictstheoriginaltext.
c.Deshuffling:Theinputsareshuffledrandomlyandthe modeltriestopredicttheoriginaltext.
Fig 5:PEGASUS,[MASK1] GSG,[MASK2] MLM[12]
Fig 7:T5[15]
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
CNN/Daily Mail is a text summary dataset [2]. Human produced abstractive summary bullets were constructed from CNN andDailyMail newsarticlesas questions(with oneoftheentitiesobscured)andstoriesastheappropriate sectionsfromwhichthesystemissupposedtoanswerthe fill in the blank inquiry. The programsthatcrawl, extract, and produce pairs of excerpts and questions from these websiteswerereleasedbytheauthors.
Accordingtotheirscripts,thecorpushas286,817training pairings,13,368validationpairs,and11,487testpairs.On average, the source texts in the training set comprise 766 wordsand29.74sentences,whereasthesummarieshave53 wordsand3.72sentences.
In 2015 and 2016, the Gigaword dataset from Stanford University'sLinguisticsDepartmentwasthemostpopular datasetfortrainingmodels.TheNewYorkTimes,Associated Press, and Washington Post are among the seven news organizationsrepresentedinGigaword,whichhasaround10 million papers. Gigaword is one of the largest and most diverse summarization datasets, despite the fact that it containsheadlinesratherthansummaries;asaresult,itis deemedtocontainsingle sentencesummaries.
CNN/DailyMaildatasethasbeenextensivelyusedinthe lateststudiesfortrainingandevaluation.
Forevaluation,ROUGE(Recall OrientedUnderstudyfor GistingEvaluation)scoresareused.Theyareasetofmetrics, eachhavingprecision,recall,andF 1score
ROUGE N measures the number of matching n grams betweenareferenceandmodel generatedtext.Ann gramis acollectionoftokensorwords.Aunigram(1gram)ismade upofasingleword,whereasabigram(2gram)ismadeupof twoconsecutivewords.TheNinROUGE Nstandsforthen grambeingused.
ROUGE L uses Longest Common Subsequence (LCS) to determine the longest matching sequence of words. The main benefit of using LCS is that it bases itself on in sequencematchesthatindicatesentencelevelwordorder instead of successive matches. A predetermined n gram lengthisnotneededsinceitnaturallyincludesthelengthiest in sequence common n grams. Longer shared sequences indicatemoresimilarity.
All ROUGE variations can be used to measure recall, precision,ortheF1score.TheF1scorewaschosenforthis paper because it is less impacted by summary length and provides a good balance between recall and precision. ROUGEdoesnotcatertodifferentwordsthathavethesame meaning.
Table 1: Summaryofapproaches
RNN RNN Encoder Decoder Uses2RNNcellstocomprehend inputandgenerateoutput sequence.
BiSum Generatessummaryinboth directionsusinganadditional backwarddecoder.
ABS Attentionmechanismaddedto Sequentialarchitecture.
Pointer Generator Networks+Covera ge
Allowsbothcopyingand generatingwords.
DAPT Usesself attentionmechanism, softattention,andpointer network.
Base Transformer Followsanencoder decoder structurebutwithoutrecurrence andconvolutions.
BERT UsesMLM(MaskedLM)andNSP (NextSentencePrediction).
PEGASUS UsesGSGandpre trainsthe encoderasaMLM.
T5 BERTmodelwithdecoderadded usessamelossfunctionand hyperparametersforallNLP tasks.
BART Denoisingautoencoder.
Table-2: ScoresonCNN/DailyMailDataset
Approach
R1 R2 RL
RNN Encoder Decoder LEAD 3 40.42 17.62 36.67
BiSum 37.01 15.95 33.66
ABS 41.16 15.75 39.08
Pointer Generator Networks + Coverage 39.53 17.28 36.38
DAPT + imp-coverage (RL+MLE(ss))
40.72 18.28 37.35
Base Transformer 39.5 16.06 36.63
BERT BERTSUMABS 41.72 19.39 38.76
PEGASUS Large 44.17 21.47 41.11
T5 43.52 21.55 40.69
BART 44.16 21.28 40.9
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Chart 1:ScoresonCNN/Dailymaildataset
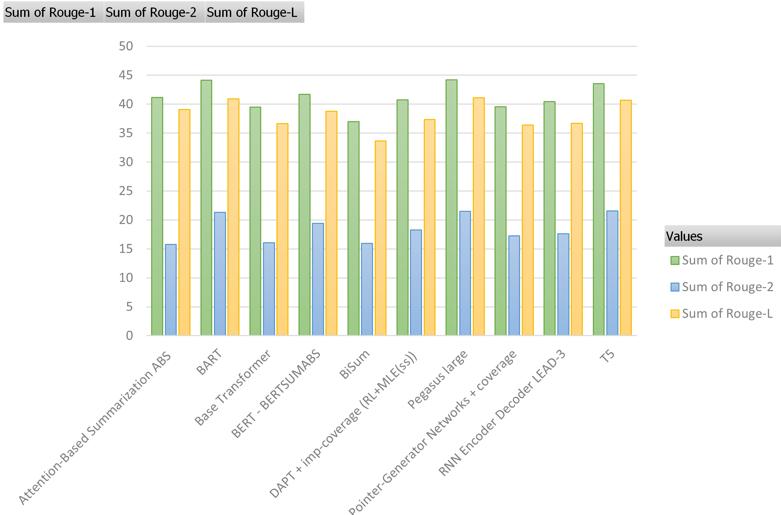
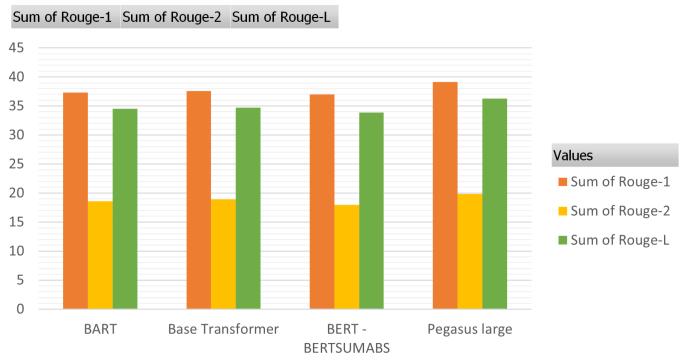
Table 3: ScoresonGigawordDataset
Approach R1 R2 RL ABS 30.88 Pointer Generator Networks + Coverage 39.53 17.28 36.38
DAPT + imp coverage (RL+MLE(ss)) 40.72 18.28 37.35
Base Transformer 37.57 18.9 34.69 BERT BERTSUMABS 36.97 17.96 33.87 PEGASUS Large 39.12 19.86 36.24 T5 BART 37.28 18.58 34.53
Theimportanceoftextsummarizationhasgrowninrecent yearsasaresultofalargeamountofdataavailableonthe internet. Natural language processing has a wide range of applications,withautomatictextsummarizationbeingone of the most common. There are two types of text summarization methods: extractive and abstractive. The area of automatic text summarizing has a long history of research, and the focus is shifting from extractive to abstractive summarization. Abstractive summary methodologygeneratesarelevant,precise,content rich,and lessrepetitivesummary.Theextractivetextsummarization approach,ontheotherhand,providesasummarybasedon linguistics and statistical factors that include words and phrasesfromtheoriginaltext.Abstractivesummarizationis adifficultfieldsinceitfocusesondevelopingsummariesthat areclosertohumanintellect.Asaresult,thisstudyputsthe methodologiesforabstractivesummarizationtothetest,as wellasthebenefitsanddrawbacksofvariousapproaches. TheROUGEscoresobtainedfromtheliteraturearereported, based on which, it can be concluded that the best results wererealizedbythemodelsthatapplyTransformer.
We would like to express our appreciation for Professor Abhijit Joshi, our research mentor, for his patient supervision,ardentsupport,andconstructivecriticismsof this research study. We thank Dr. Vinaya Sawant, for her advicethatgreatlyimprovedthemanuscriptandassistance inkeepingourprogressonschedule.
[1] D.R.Radev,E.Hovy, andK.McKeown, “Introduction tothespecialissueonsummarization.Computational linguistics”,vol.28,No.4,pp.399 408,Dec.2002.
[2] R.Nallapati, B.Zhou, C.D.Santos, Ç.Gulçehre, andB. Xiang, “Abstractive Text Summarization using Sequence to sequence RNNs and Beyond,” unpublished.
[3] D.Bahdanau, K.Cho, andY.Bengio, “NeuralMachine Translation by Jointly Learning to Align and Translate,” unpublished.
Chart-2:ScoresonGigaworddataset
ROUGEF1resultsonCNN/DailyMailandGigawordtestset (TheabbreviationsR1andR2standforunigramandbigram overlap, respectively; RL stands for the longest common subsequence.). The results for comparative systems are collectedfromtheauthors'publicationsorproducedusing opensourcesoftwareonthedataset.
[4] A. M. Rush, S. Chopra, and J. Weston, “A Neural Attention Model for Abstractive Sentence Summarization,” unpublished
[5] K.Loginova, “AttentioninNLP”, unpublished.
[6] X.Wan,C.Li,R.Wang,D.Xiao,andC.Shi, “Abstractive documentsummarizationviabidirectionaldecoder,” in Advanced Data Mining and Applications,G.Gan,B.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Li, X. Li, and S. Wang, Eds., Springer International Publishing,Cham,Switzerland,2018,pp.364 377.
[7] A.See, P.J.Liu, andC.D.Manning, “GetToThePoint: Summarization with Pointer Generator Networks,” unpublished
[8] Z. Li, Z. Peng, S. Tang, C. Zhang, and H. Ma, “Text Summarization Method Based on Double Attention Pointer Network,” IEEE Access, vol. 8, pp. 11279 11288,Jan.2020.
[9] A. Vaswani et al., “Attention Is All You Need,” unpublished.
[10] J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre training of Deep Bidirectional Transformers for Language Understanding,” unpublished
[11] Y.LiuandM.Lapata,“NeuralMachineTranslationby JointlyLearningtoAlignandTranslate,” unpublished.
[12] J. Zhang, Y. Zhao, M. Saleh, and P. J. Liu, “PEGASUS: Pre training with Extracted Gap sentences for AbstractiveSummarization,” unpublished.
[13] M. Lewis et al., “BART: Denoising Sequence to Sequence Pre training for Natural Language Generation, Translation, and Comprehension,” unpublished.
[14] C. Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text to Text Transformer,” unpublished.
[15] Q.Chen, “T5:adetailedexplanation”, unpublished.
[16] D.SuleimanandA.A.Awajan, “DeepLearningBased Abstractive Text Summarization: Approaches, Datasets, Evaluation Measures, and Challenges,” Mathematical Problems in Engineering, Hindawi, vol. 2020, pp.1 29,Aug.2020.



[17] F.Jonsson, “EvaluationoftheTransformerModelfor AbstractiveTextSummarization,” unpublished.
Aryan Ringshia is currently pursuing theB.Tech.degreewiththeDepartment ofInformationTechnologyatDwarkadas J. Sanghvi College of Engineering, Mumbai,India.HewasborninMumbai, India. From 2021 to 2022, he was a junior mentor in DJ init.ai student chapter of the Information Technology

Department at Dwarkakdas J Sanghvi College of Engineering where he worked on research and industry orientedprojectstoadvanceindomain ofAIMLwithguidancefromseniorsand taught AIML concepts to freshers. His research interests include machine learning, deep learning, and natural languageprocessing.
Neil Desai is a B.Tech. student in the DepartmentofInformationTechnology at Dwarkadas J. Sanghvi College of Engineering in Mumbai, India. Currentlyheis working as a Teaching Assistant in the Data Science Department at Dwarkadas J Sanghvi College of Engineering where he is helping the faculty design laboratory experiments for the department. Natural Language Processing, Deep Learning, and Image Processing Applications are among his research interests.
Umang Jhunjhunwala was born in Mumbai,Indiaandiscurrentlypursuing his B.Tech. degree in Information Technology at D.J. Sanghvi College of Engineering in Mumbai, India. He worked as a summer data science internatXelpmocDesignandTechLtd forfourmonthsinKolkata,Indiawhere worked as part of team to develop a systemcapableofperformingcomplex natural processing tasks. His research interests include analytics, natural language processing and machine learning.
Ved Mistry wasborninMumbai,India and is currently pursuing the B.Tech. degree with the Department of InformationTechnologyatDwarkadasJ. Sanghvi College of Engineering, Mumbai, India. He served as a junior mentorintheDJinit.aistudentchapter of the Information Technology Department at Dwarkakdas J Sanghvi College of Engineering from 2021 to 2022 where he worked on research projectswiththehelpofhisseniorsand taughtmachinelearningconceptstohis juniors. His research interests include ComputerVisionandImageProcessing, Deep Learning and Natural Language Processing.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page2771
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Prachi Tawde receivedtheM.E.degree in computer engineering from UniversityofMumbai,Mumbai,Indiain 2017andtheB.E.degreeininformation technologyfromUniversityofMumbai, 1stClass,Mumbai,Indiain2012.Sheis currently an Assistant Professor at DepartmentofInformationTechnology, Dwarkadas J. Sanghvi College of Engineering, Mumbai University. She has previously published in the International Conference on Big Data Analytics and Computational Intelligence(ICBDAC),IEEE,2017.Her researchinterestsincludeapplicationof natural language processing in educational domain, machine learning andanalytics.

2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |