
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
MODERN DATA PIPELINE
Sinchana Hegde1, Padmashree T2
1Student, Department of Information Science and Engineering, R V College of Engineering, India
2Assistant Professor, Department of Information Science and Engineering, R V College of Engineering, India ***
Abstract In the modern era , the prime commodity in the technology field is the ever growing data. Large companies continuously keep generating data in real time with related clients and employees. It is difficult to interpret data in raw form but after it is processed , it can be used for analytics. Taking into consideration the scale of data generated by the companies, it becomes necessary to dedicate a huge amount of time, people and resources to conquer the objective of data processing. Gathering data from various distributed sources requires much effort, time and resources. It also includes other difficulties in transporting data from its source to the destination. The main objective of Data pipelines is to increase the efficiency of data flow from the source to the destination. Since this process is completely automated, there is very less human involvement.
The main objective of the modern data pipeline is to solve the problems corporates bring in data pipelining technologies and directly receive processed data at the destination. With traditional data transfer processes like Extract, Transform and Load (ETL) having several shortcomings it becomes a new norm to choose the modern data pipeline stack which comprises extract, load and transform (ELT) to make better decisions. This paper tries to give an insight on the major differences between the two and how the modern data stack can be used to your company’s advantage.
Keywords Data Pipelines, Data Analytics, Cloud, Data Warehouse, Extract, Load, Transform
I. INTRODUCTION
Large companies generate a lot of data on a daily basis. This problem has been further amplified by the recent developmentofcloud basedapplicationsandservices.The appearanceofwebappsandserviceshascontributedtoan explosion of data.Most data is generated for making informed decisions, training the models using machine learningdeeplearning concepts. .Manycompaniesaround the world have now understood that big data is an
important contributor for success. However, quality data is necessary for excellent data products . Companies that are dependent on data should be able to gather, store, manageandprocessthishigh qualitydata.
This chain of various interrelated activities from data generationtodatareceptionconstitutesadatapipeline.In other words, data pipelines can also be defined as the connectedchainofprocesseswheretheoutcome ofsome processes becomes an input for another process. Data pipelines should be able to handle batch data and intermittent data as streaming data. Also, there are no hard constraints on the data destination. It can route data throughapplicationslikevisualizationormachinelearning / deep learning models and not only data storage like a datawarehousetobethe destinationofdata.
Inthispaper,westudymoderndatapipelines,explorethe best ways to gather data, process, store and manage data. We also explain why data pipelines are at the heart of modern software development and how the technology could be improved to navigate around barriers. Finally, this paper also mentions the potential security risks the technologyposes.
BACKGROUND
Previously the data pipeline services were based on Extract Transform Load(ETL).
In this method data was extracted from the source and loaded in to data warehouse according to requirements. Cost efficient remote data storage facilities were not presentwhichledtotheusageofthissystemforlongtime. So data was modified to store the data queried for analysis. Certain algorithms were used to transform the sourcedata.Sourcedatawasthenusedtogenerateasmall amountofdatathatmeetsqueryrequirements.
This method had several limitations such as, raw data cannot be directly queried since it is not available at the warehouse end, subject matter experts helped design algorithms and queries that can combine data and extract information enough for analytics from smaller extent of data.SomeoftheETLlimitationsare
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
1.Complexity.Data pipelinesrunoncustomcodedictated by the specific needs of specific transformations. This means the data engineering team develops highly specialized, sometimes non transferrable skills for managingitscodebase.
2. Brittleness. For the aforementioned reasons, a combination of brittleness and complexity makes quick adjustmentscostlyorimpossible.Ifthereissomeerror or warningfunctionalityofthecodewontworkproperly.Itis verydifficulttomakechangesinthecode.
3. Customization and sophistication Data pipeline not only extract data but make complex changes that meet specific analytical requirementsfor endusers.Thismeans alotofcustomcodes.
II. RELATED WORKS
Theconceptofdatapipesisarecentone.Recentadvances in cloud infrastructure have led to advancements in the field of data pipes. These are some new findings in the corresponding area of data pipelines. In 2009, research wasconductedonETLTechnology[1]anditwasbasedon thefollowingprinciple.The initial softwareprogramsthat support the initial stacking and occasional refreshing of the warehouse are usually known as Extraction Transformation Loading (ETL) forms. There were some limitations, however, information mining remains a difficult problem, largely due to resource constraints, streamlining and recovery issues, and non benchmarking hindering future research. Then in 2012 Real Time ETL Data Warehousing was investigated [2]. The goal was to achieve a real time data warehouse that is highly dependentonthechoiceofprocessinthedatawarehouse technologyknownasextract,transformandload(ETL).In 2013, a synchronous investigation[3] was underway in ELT, using the capabilities of the Information Distribution Center to directly import raw natural records, allowing change and cleaning the information until required by pendingreports.
Later in 2016, ETL was adopted for several applications, for example in the clinical field[3].Thisinformation must be properly removed, changed and stored while maintaining the integrity of this information. It approved theaccuracyoftheextract,laterin[4]theauthorsproved that despite the fact that many solutions have been presented in the literature to improve the speed of the extraction, transformation and loading phases of the data channel, the question of data integration still arises in the bigdataenvironment.Inaddition,developershavetodeal withalotofheterogeneitybecausethereareseveralways
in which data is formatted or different data structures[5]. During the work in [6], he tries to use context aware computing and merge the Data WareHouse (DWH) technology with the Data Lake technology in order to improve the computing mechanisms in the data pipeline [6]. In [7], the authors provide an overview of how to design conceptual models that can facilitate communicationbetweendifferentdatateamsandthatcan further improve system efficiency on heterogeneous data. Inaddition,itcanbeusedforautomaticmonitoring, error detection,mitigationandalarmingatvariousstagesofthe datapipeline.
III. METHODOLOGY
The introduction of ETL was for the process of compiling and uploading data for the sake of numeric calculations and analytical purposes, and eventually became a major data processing method for data storage projectswiththe spread of information in the 1970s..The basic steps provided by ETL is to analyze the data and to leverage machinelearning capabilities to the best of its ability. If it isgivenasetofbusinessrules,ETLisabletocleanand is able to organize your data in such ways that it is able to meetthe specificbusinessintelligencerequirements
LetusunderstandeachstepoftheETLprocessandwhyit isnotsuitableforcurrentdataworkflow
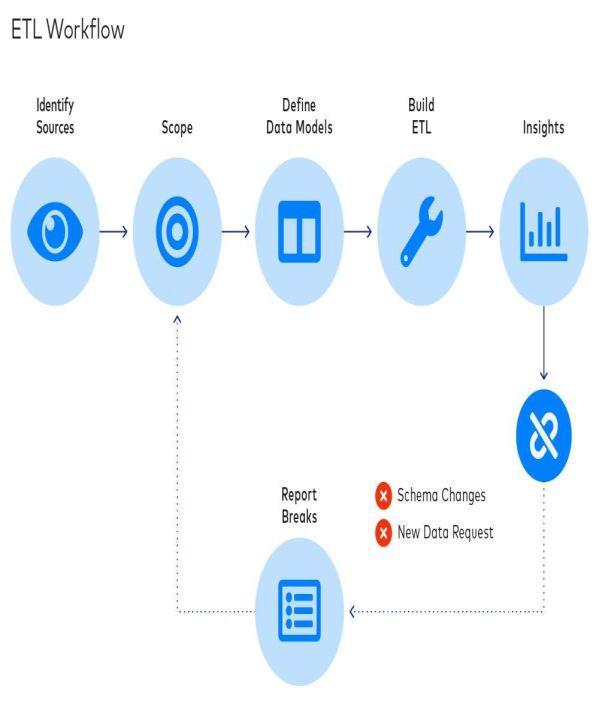
Fig 1 ETL Workflow
A.Extraction: The initial and most important step in the ETL process is known as the extraction phase. This is the step where you needto extractdata fromdifferentsource systems in different formats of JSON, XML, flat files etc.
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
move it to temporary storage. Because the extracted data isdiverseandpotentiallycorrupt,itisimportanttoextract the data from different source systems and store it in the stagefirst,ratherthandirectlyinthedatawarehouse.
B.Transformation: The transformation, or conversion phase, is the second step in the ETL process. This is the stepinwhichasetoftasksisappliedtotheextracteddata and converted into a single consensus standard format that can be used during the next or later stage of the ETL process. This involves various steps, some of which are: Filtering, cleaning, deduplication, validation and data validation. Cleanup wherever NULLs are found, some general value is added to them, for example, the NULL value can be replaced by a mean value. in numerical data. Splitting splittingoneattributeintomultipleattributes.
C.Loading:
The upload process or data pool is the final and final step of this process. This is the process by which data eventually becomes data converted or converted into a datarepositoryofourchoice.
As in the ETL process, both extraction and conversion are performed before any data is loaded locally, tightly integrated. In addition, because conversion is determined by the specific needs of analysts, each ETL pipeline is a complex, custom built solution. The set environment of these pipelines makes measuring very difficult, especially adding data sources and data models so modern data pipelines use ELT(Extract, Load and Transform)mechanism.
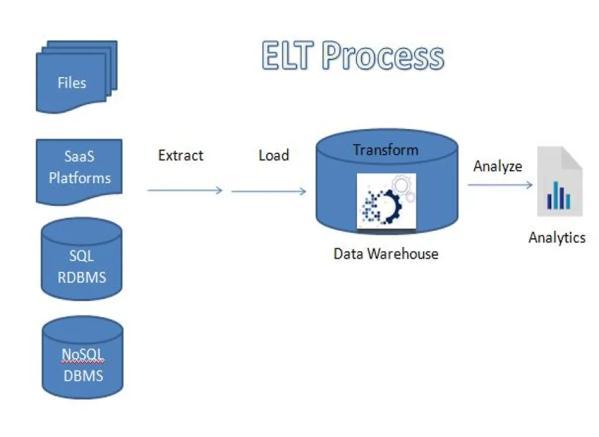
ELT
Extract/Load/Transform (ELT) is the method of fetching data from data sources and loading it into a destination warehouse followed by transformation of data.. ELT dependsonthetargettoperformthedatatransformation. Thisapproachrequireslessresourcesthanothermethods because it requires only raw and unprepared data. It is becoming more and more common to extract data from thesourcelocation,loaditintothetargetdatawarehouse, andtransformitintoactionablebusinessintelligence.
Fig 2 ELT Process
Thisprocessconsistsofthreesteps:
A.Extract This is the step where you need to extract data from different source systems in different formats of JSON,XML,flatfiles.ThisstepisthesameforbothETLand ELT methods. Raw data from different applications, softwarearegatheredinthisstepinELT.
B.Load This is where ELT evolves from its ETL.Data extracted are loaded directly to destination instead of loadingittoastagingserverfortransformation.Itreduces the cost needed to manage staging servers and also reducesthetimebetweenextractphaseandloadphase.
C.Transformation This phase in ELT happens at the destination warehouse instead of transforming data in staging servers. A database or data warehouse sorts and normalizes data and transforms it according to source data.CostoftheoperationwillbehighlyreducedinELTas transformationishappeningatthedestinationwarehouse withoutusinganystagingserverfortransformation.
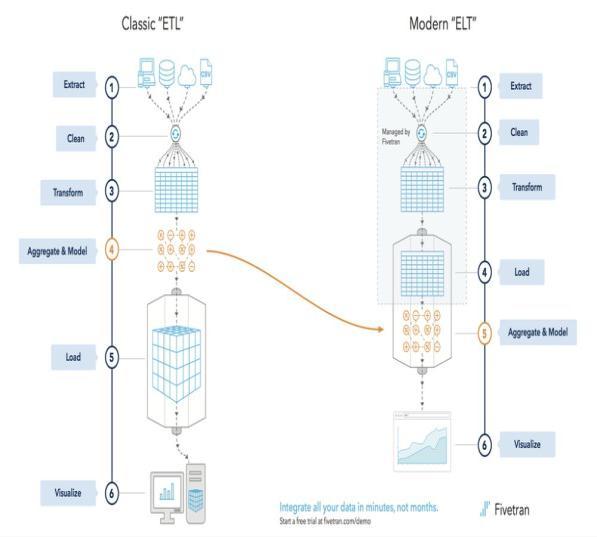
Fig 3: Difference between ETL and ELT
International Research Journal of Engineering and Technology (IRJET)
e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
The most obvious difference between ETL and ELT is the differenceintheorderofoperations.ELTcopiesorexports data from the source location, but instead of loading the data into the staging area for conversion, it loads the raw data directly into the target data store for conversion as needed.Bothprocessesutilizedifferentdatastoressuchas databases, data warehouses, and data lakes, but each process has its strengths and weaknesses. ELTs are especially useful for large unstructured datasets because theycanbeloadeddirectlyfromthesource.ETLissuitable for legacy on premises data warehouses and structured data.ELTisdesignedforcloudscalability.
IV. RESULTS AND ANALYSIS
Detailed review of ETL and ELT have been discussed above. ETL is traditional process for collecting and transforming data into data warehouse where as ELT is modern process for collecting and transforming both structured and unstructured data into cloud based data warehouse. ELT provides support for data lakes , data marts or data lake house which was not found in ETL method. Im recent times it is necessary to handle data of anysizeoranytypeELTiswellsuitedforthisascompared to ETL. Transformation and loading processes are more efficientinELTthaninETL. SinceELTiscloudbased itis cost efficient. whereas ETL is on premises and requires expensive hardware. ETL is more suited with GDPR and CCPA standards. ELT has more risk of exposing private data and not complying with GDPR and CCPA standards. ELTisamodernalternativetoETL.
V. CONCLUSION
The study focuses on challenges and opportunities in implementing and managing the data pipeline. Challenges fall into three categories: infrastructure, organization, and data quality challenges. The latest cloud based infrastructure technology provides huge amounts of data storage and computing power at low cost, storing petabytesofdatainlarge,scalabledatalakesforrapidon demandprocessing.willdoso.Thesurgeindatalakeshas enabled more companies to move from ETL to ELT. ELT seems to be the future of data integration and has many advantages over the old and slow process ETL. The amount of data in your business is growing exponentially, and ETL tools cannot integrate all this data into one repository for efficient processing. With increased agility and less maintenance, ELT is a cost effective way for businesses of all sizes to take advantage of cloud based data.
REFERENCES
[1] N.Schmidt,A.Lüder,R.Rosendahl,D.Ryashentseva,M. Foehr and J. Vollmar, "Surveying integration approachesforrelevanceinCyberPhysicalProduction Systems," 2015 IEEE 20th Conference on Emerging Technologies &FactoryAutomation(ETFA),2015,pp. 1 8,doi:10.1109/ETFA.2015.7301518.
[2] W. Zhang et al., "A Low Power Time to Digital Converter for the CMS Endcap Timing Layer (ETL) Upgrade," in IEEE Transactions on Nuclear Science, vol. 68, no. 8, pp. 1984 1992, Aug. 2021, doi: 10.1109/TNS.2021.3085564.
[3] J.HuangandC.Guo,"AnMAS basedandfault tolerant distributed ETL workflow engine," Proceedings of the 2012IEEE16thInternationalConferenceonComputer Supported Cooperative Work in Design (CSCWD), 2012,pp.54 58,doi:10.1109/CSCWD.2012.6221797.
[4] B.Z.Cadersaib,Y.Ahku,N.G.Sahib Kaudeer,M.H. M. Khan and B. Gobin, "A Review of Skills Relevant to Enterprise Resource Planning Implementation Projects," 2020 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), 2020, pp. 172 177, doi: 10.1109/ICIMCIS51567.2020.9354270.
[5] E.Begoli,T.F.ChilaandW.H.Inmon,"Scenario driven architecture assessment methodology for large data analysis systems," 2013 IEEE International Systems Conference (SysCon), 2013, pp. 51 55, doi: 10.1109/SysCon.2013.6549857.
[6] J.Sreemathy,S.Priyadharshini,K.Radha,K.Sangeerna and G. Nivetha, "Data Validation in ETL Using TALEND," 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), 2019, pp. 1183 1186, doi: 10.1109/ICACCS.2019.8728420.
[7] D.Tovarňák,M.RačekandP.Velan,"CloudNativeData Platform for Network Telemetry and Analytics," 2021 17thInternationalConferenceonNetworkandService Management (CNSM), 2021, pp. 394 396, doi: 10.23919/CNSM52442.2021.9615568.
[8] A.Tiwari,N.Sharma,I.KaushikandR.Tiwari,"Privacy Issues & Security Techniques in Big Data," 2019 International Conference on Computing, Communication,andIntelligentSystems(ICCIS),2019, pp.51 56,doi:10.1109/ICCCIS48478.2019.8974511.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
[9] A. Wibowo, "Problems and available solutions on the stage of Extract, Transform, and Loading in near real time data warehousing (a literature study)," 2015 International Seminar on Intelligent Technology and Its Applications (ISITIA), 2015, pp. 345 350, doi: 10.1109/ISITIA.2015.7220004.
[10] J.LuandM.Keech,"EmergingTechnologiesforHealth Data Analytics Research: A Conceptual Architecture," 2015 26th International Workshop on Database and Expert Systems Applications (DEXA), 2015, pp. 225 229,doi:10.1109/DEXA.2015.58.
[11] Panos Vassiliadis, ‘A Survey of Extract Transform Load Technology.,’ July 2009 International Journal of DataWarehousingandMining5:1 27
[12] Kamal Kakish, Theresa A Kraft, ‘ETL Evolution for RealTime Data Warehousing’, presented at Conference: 2012 Proceedings of the Conference on Information Systems Applied Research, At New OrleansLouisiana,USA
[13] Florian Waa, Tobias Freudenreich, Robert Wrembel, Maik Thiele, Christian Koncilia, Pedro Furtado, ‘OnDemand ELT Architecture for Right Time BI: Extending the Vision’, International Journal of Data WarehousingandMining9(2):21 38·April2013
[14] Michael J. Denney, MA,1 Dustin M. Long, PhD,2 Matthew G. Armistead, BS,1 Jamie L. Anderson, RHIT, CHTS IM,3andBaqiyyahN.Conway,PhD4,‘Validating theExtract,Transform,LoadProcessUsedtoPopulate a Large Clinical Research Database, ’Int. J. Med. Inform.,94(2016),pp.271 274
[15] Valerio Persico, Antonio Montieri, Antonio Pescapè, ‘On the Network Performance of Amazon S3 Cloud Storage Service’, 2016 5th IEEE International ConferenceonCloudNetworking(Cloudnet)
[16] Pwint Phyu Khine, Zhao Shun Wang, ‘Data Lake: A New Ideology in Big Data Era’, 2017 4th International Conference on Wireless Communication and Sensor Network[WCS2017],AtWuhan,China
[17] Benjamin S. Baumer, ‘A Grammar for Reproducible and Painless Extract Transform LoadOperations on Medium Data’, arXiv:1708.07073v3 [stat.CO] 23 May 2018
[18] IbrahimBurakOzyurtandJeffreySGrethe,‘Foundry:a message oriented, horizontally scalable ETL system
for scientific data integration and enhancement’, Database(Oxford).2018;2018:bay130.
[19] FabianPrasser, HelmutSpengler, RaffaelBild, JohannaEicher, Klaus A.Kuhn, ‘Privacy enhancing ETLprocesses for biomedical data’, International Journal of Medical Informatics, Volume 126, June 2019,Pages72 81
[20] Gustavo V. Machado, Ítalo Cunha, Adriano C. M. Pereira, Leonardo B. Oliveira , ‘DOD ETL: distributed on demand ETL for near real time business intelligence ’, Journal of Internet Services and Applicationsvolume10,Articlenumber:21(2019)
[21] Noussair Fikri, Mohamed Rida, Noureddine Abghour, Khalid Moussaid & Amina El Omri, ‘An adaptive and real time based architecture for financial data integration’,Journal