International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Tanush Shetty1 , Dharmik Timbadia2
1Undergraduate Student, Rajiv Gandhi Institute of Technology, Andheri, Mumbai
2Graduate Student, Boston University, Boston, Massachusetts, USA ***
Abstract - Chronic kidney disease is a major obstacle for health care infrastructure all over the world consuming a large amount of health care budgets, mainly affecting poor countries. Machine learning plays a vital role in analyzing vast amount of medical data and to solve difficult problem of early prediction of diseases. This study is aimed to develop a chronic kidney disease prediction using machine learning techniques to predict the presence of the disease. The prediction of kidney disease is done in three phases: feature selection process to select those features which aid most in prediction. The second phase is applying the machine learning algorithms, AdaBoost, KNN & Random Forest in which the data will be trained and tested. The final phase is the user interface in which the user will enter his health related information and the machine learning models will predict whether the user will have kidney disease or not.
Key Words: Chronic Kidney Disease, Machine Learning, RandomForest,FeatureSelection.
Non Communicable Diseases (NCDs), especially chronic kidney diseases (CKD), cardiovascular, hypertension, and diabetesmellitushavenowtakenaplaceofcommunicable diseases that become a serious public health issue and economic cost issue worldwide, consuming a high percentage of health care budgets. CKD is a chronic disease that has significantly contributed to increased morbidity, mortality, and an admission rate of patients throughouttheworld.
Chronic kidney disease is a condition in which the kidney structure is uneven or function reduces for 3 months and more with a reduced glomerular filtration rate. According to the reports, CKD has now become a fast spreading and fatal disease all over the globe. According to reports, the yearlylifelossofCKDincreasedby90%anditisknownas the 13th leading death cause in the world. Currently, 850 million people throughout the globe are likely to have kidneydiseasesfromdifferentfactors,fromwhichatleast 2.4 million die per year and now it is the 6th fastest growingcauseofdeathglobally.[1]
The associated extent of the increased danger of clinical occurrences, which makes it a severe public health condition globally, is affiliated with chronic kidney disease. Even though it is widely accepted that CKD has
significant interactions with magnified hazards of end stageexcretoryorgandisease,vesseloccurrencesandall causemortality,thereisstillalackofaccurateinformation onindividualpatients.Excretoryorgandamagereferstoa condition that allows the capacity of the kidney to be reducedbyaconsiderabledecreaseinthevesselfiltration rate (GFR). The kidneys operate as filters to remove the waste products from the blood in different tiny blood vessels. In certain cases it decomposes and kidneys lose their capacity to distinguish nutrients, which ends in nephropathy. CKD has no underlying cause, but it generally becomes irreversible and can cause severe healthproblems.
A concerning 195 million girls are laid low with CKD within the world and it's presently the eighth leading reason behind death among women with around 600,000 individuals' dying of this illness annually. Between 2011 and 2012. There have been 9 million adults with CKD in England as registered within the Quality Outcomes Framework(QOF).
ChronicKidneyDiseaseisaprogressivekidneydiseasethat kills millions of people silently all over the world regardlesstheageandsex.CKDdiseaseisaconditionwhen thekidneydamagedandunabletofilterwastesasmuchas the normal kidneys because wastes are built up in the kidneys for several time. This can also cause other complications such as cardiovascular disease (CVD), anemia,andbonedisease.Itisa decreasedfunctionofthe kidney over several years; it often goes undetected and undiagnosed until the disease is a well advanced stage. Fromdifferentreportestimations,itindicatedthattheCKD prevalence is around 8 16 % globally, which shows it is becomingoneoftheseriouspublichealthproblems.
In most developed countries, CKD is mostly related to old age, diabetes, hypertension, obesity, cardiovascular disease,anddiabetic glomerulosclerosis,andhypertensive nephroscerosis, whereas, in developing countries, the common causes of CKD are glomerular and tubulointerstitialdiseaseswhichresultfrominfectionsand exposure to drugs and toxins. Moreover, in most developing countries low level quality of life like lack of clean water, lack of appropriate diet is the main cause of CKD.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Our daily diet, what we eat and drink can damage our kidneys.Therefore,sincegettingabalanceddietisdifficult in developing countries like Ethiopia, people suffer from kidney disease and other risk factors of this disease. Chronickidneydiseaseleadstokidneyfailuresilentlyifdo not detected early and accurately by practitioners. At the early stage of CKD, the patients may not have any symptoms. The only way to detect and identify the presence or absence of the CKD disease is urine analysis and blood test needed to know the kidney function and kidneydamage.Thetreatmentoptionisnotaffordable,on time and people have less knowledge about CKD in developing countries. CKD will grow to end stage kidney failure slowly that is a very serious problem for which artificial filtering (dialysis) or a kidney transplant is needed.
In [3], authors conducted their research on the common riskfactorinchronickidneydisease.Theyhavestatedthat amongtheriskfactor,agingwasasignificantpredictorfor renal failure in both males and females, but more prominent in males and stated that hypertension and diabetes mellitus, main causes among diseases for causing renalfailure.
In [2], authors conducted their research to measure the prevalence and risk factors for chronic kidney disease (CKD)anddiabetickidneydisease(DKD)inaChineserural population. According to their finding, they came up with age, gender, education, personal income, alcohol consumption, overweight, obesity, diabetes, hypertension, anddyslipidemiaasprevalentriskfactors.
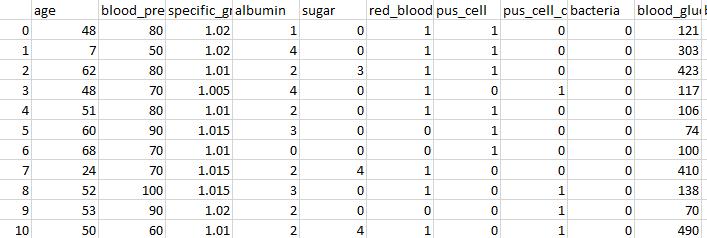
Dataset was derived from UCI. The data set contains 400 samples. In this CKD data set, each sample has 25 predictive variables (12 numerical variables and 13 categorical variables). Each class has two values, namely, CKDandnotCKD.Inthe400samples,250samplesbelong tothecategoryofCKD,whereas150samplesbelongtothe category of notCKD.Normal and abnormal were codedas 1and0.[4]Presentandnotpresentwerecodedas1and0. There is a large number of missing values in the data set, and the number of complete instances is 158.A sample dataset of 10 instances that has been used in this project hasbeenshown:
The proposed system majorly focusing on the accuracy andthesystembettermentandovercomingthedrawbacks of previous systems by developing a frontend based CKD detectionsolution.Theproposedsystemalsoemploysthe feature selection method in order to select the most relevantandpredictivefeatures.
Theclassifierswerefirstestablishedbydifferent machine learning algorithms to diagnose the data samples. Among these models, those with better performance were selected as potential components. By analyzing their misjudgments, the component models were determined. [4] An integrated model was then established to achieve higher performance. As shown in above figure 2 first we have a preprocessing phase to convert dataset into appropriateformat.Then wehavefeatureselectionphase toselectfeatureswhicharemostusefulinhelpingpredict CKD. Then we use classification algorithms to develop a CKD prediction model. Then we have training and testing phasetoevaluateperformanceofthemodel.
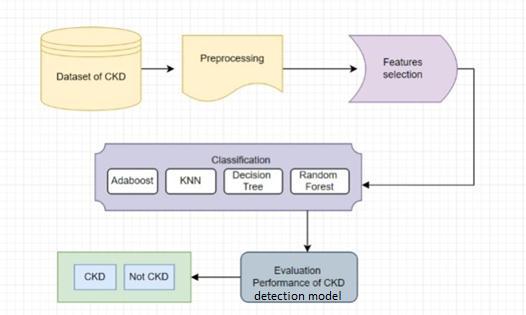
The system was designed used machine learning methods for chronic kidney disease detection. Various ensembles likeboostingwereusedinthepredictionofkidneydisease. A frontend based CKD detection solution has been developed. Users can enter their test data such as blood pressure,creatininelevelsandexpectanoutputpredicting if they have CKD or not. Supervised classification algorithms, AdaBoost, KNN and Random forest were used to develop a model to predict if someone has CKD or not. Pythonlanguagewasusedtodevelopthissystem.
Pre processing was done to make the data clean and appropriateforthemachinelearningmodels.Inthisstudy, the missing values have been handled using the mean replacement method and categorical values have been convertedtobinary.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
AdaBoost combines multiple classifiers to extend the accuracyofclassifiers.AdaBoostisanensemble methodology. AdaBoost classifier builds a powerful classifier by combining multiple poorly playing classifiers so you'll get high accuracy strong classifier. The essential idea behind AdaBoost is to line the weights of classifiers and coaching the information sample in every iteration specified it ensures the correct predictions of surprising observations.Anymachinelearningformulaareoftenused as base classifier if it accepts weights on the coaching set. AdaBoostmustmeet2conditions:
Here 1representsthenegativeclasswhereas1represents the positive one. Initialize the weight for every data point as: ( )
Foriterationm=1…,M:
1. Fit weak classifiers to the data set and select the one withthelowestweightedclassificationerror.
2.Computetheweightfortheweakclassifier.
3.Updatetheweightforeachdatapoint.
After M iteration, we can get the final prediction by summinguptheweightedpredictionofeachclassifier.[5]
K Nearest Neighbour is a non parametric algorithm, meaningitdoesnotmakeanyassumptiononthedata.
It is called a lazy learner algorithm since it does not learn from the training set at once instead it stores the dataset and during classification, it performs operations on the dataset.
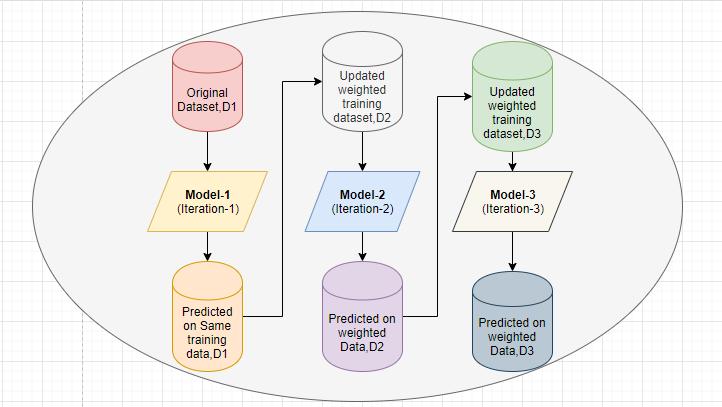
Intheabovefigure3itisshownthat:
1. The classifier should be trained iteratively on various weightedtrainingexamples.
2. In each iteration, it tries to provide an excellent fit for theseexamplesbyminimizingtrainingerrors.
The final equation of the AdaBoost algorithm can be representedasfollows: ( ) (∑ ( ))
where f_m denotes for the m_th weak classifier and theta_m is the corresponding weight. It is exactly the weightedunionofMweakclassifiers.Thewholeprocedure of the AdaBoost algorithm can be briefly explained as follows
Givenadatasetcontainingnpoints,where * +
Example: Suppose, we have a picture of an animal that lookssimilartocatanddog,butwewanttoknowwhether itisacatordog.Soforthisidentification,wecanusetheK Nearest Neighbour algorithm, as it works on a similarity measure. Our KNN model will find the corresponding features of the new data set to the cats and dogs pictures andbasedonthemostcorrespondingfeaturesitwillputit incatordogcategory.
• Random Forest Classifier:
Randomforestisamachinelearningalgorithmformulated on ensemble learning. Ensemble learning is a category of learning where you join various types of algorithms or same algorithm many times to form a better prediction model. The random forest algorithm integrates many algorithm of the same category i.e. many decision trees, which leads to a forest of trees, hence the name "Random Forest". The random forest algorithm can be used for regressionaswellasclassificationtasks.
The following are the fundamental steps involved in performingtherandomforestalgorithm:
1. PickNrandomfeaturesfromthedataset.
2. FormadecisiontreebasedontheseNrecords.
3. Choose the number of trees you want in your algorithmandrepeatstep1and2.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
4. In case of a regression problem, for a new record, everytreeintheforestpredictsavalueforY(output). Thefinalvaluecanbecomputedbytakingthemeanof allthevaluespredictedbyallthetreesinforest.Or,in caseofaclassificationproblem,everytreeintheforest predicts the type to which the new record belongs. Finally,thenewrecordisassignedtothecategorythat winsthemajorityvote[6].
There are many advantages of using Random Forest Classifier as the base algorithm for machine learning modelsinthisprojectwhichareasfollows:
• Therandomforestalgorithmisnotbiased,since,there aremanytreesandeverytreeistrainedonasubsetof data. Basically, the random forest algorithm relies on the power of "the crowd"; therefore, the overall biasednessofthealgorithmisscaledown.
• This algorithmic program is extremely stable. Even though brand new information is introduced within theknowledgesetthegeneralalgorithmprogramisn't affected. Since new data could impact one tree, however it's highly impossible for it to impact all the trees.
Therandomforestalgorithmworksbetterwhenyouhave both kind of data which is categorical and numerical features.
The random forest algorithm also works well when data hasnullvalues,orhasnotbeenscaledwell.
Given below are the results of system. Confusion matrices of algorithms used that were generated while testing the modelareincluded.
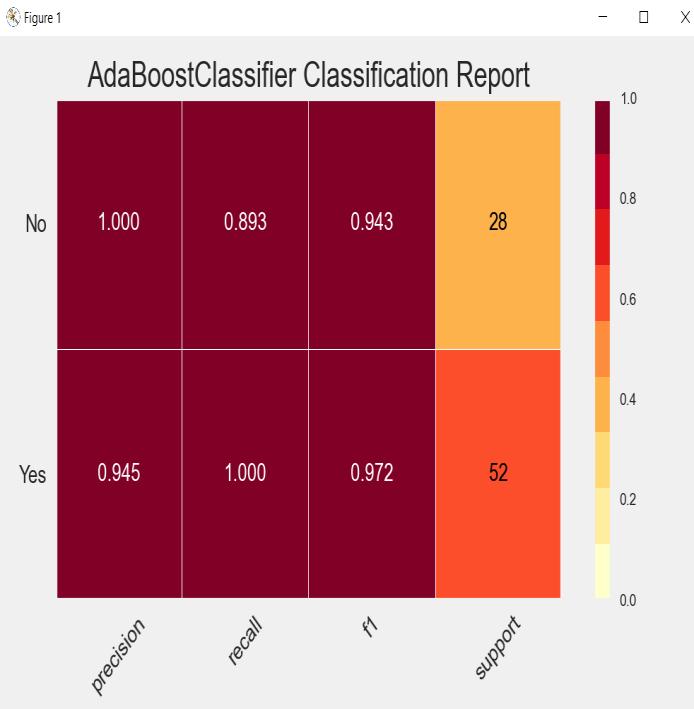
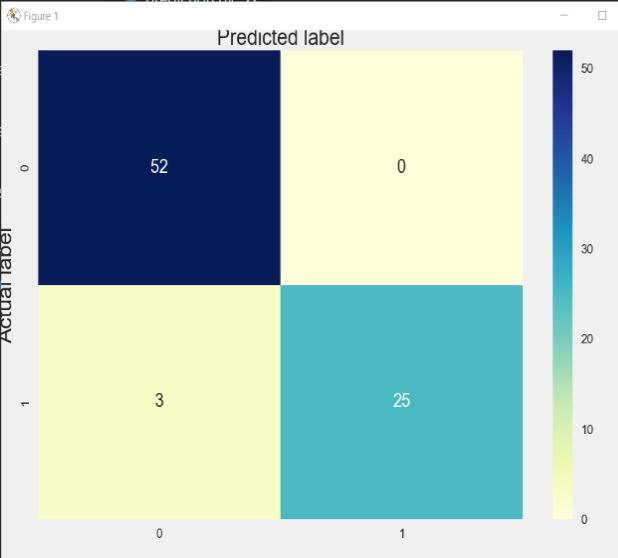
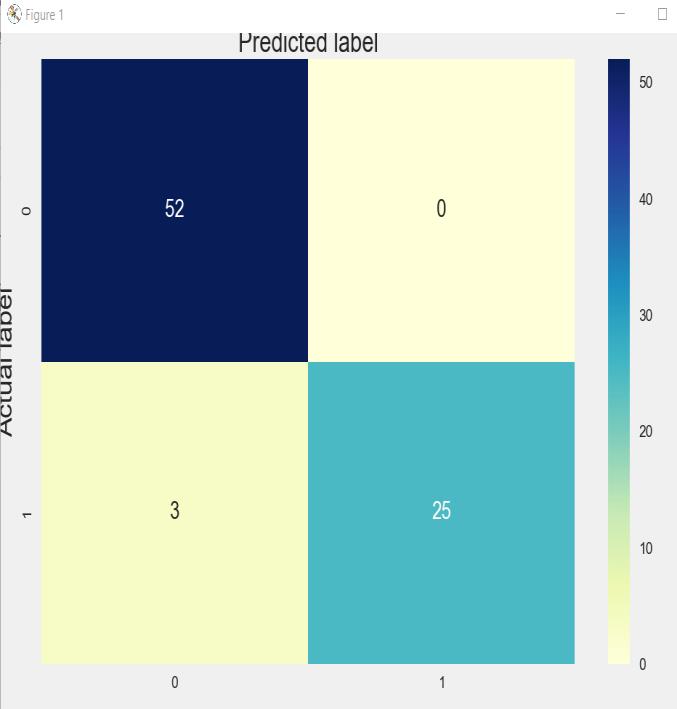
Below are the confusion matrix as well as classification reportforAdaBoostalgorithm.
Intheabovediagram(AdaBoostconfusionmatrix) wecan see that it is predicted that 52 people do not have CKD which is correct but for 3 subjects, it has predicted wrongly, on the other hand, it has predicted correctly for 25subjectsandincorrectlyfornone.
The above diagram tells us about the classification of the AdaBoost algorithm As we can see that we are getting a good precision of 94.5 % for Yes and 100 % for No. Also, for recall the accuracyisgood whichis 100% forYes and 89.3%forNo.
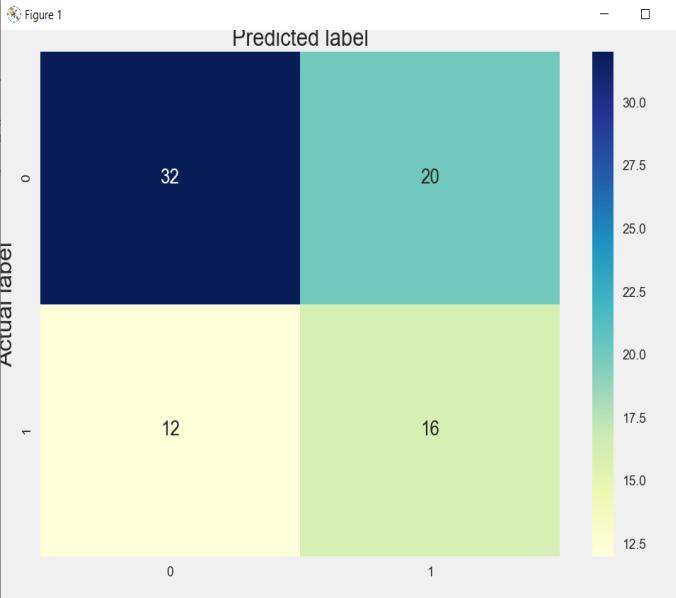
Below are the confusion matrix as well as classification reportforKNNalgorithm.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
In the above diagram (KNN confusion matrix) we can see thatitispredictedthat32peopledonothaveCKDwhichis correctbutfor12subjects,ithaspredictedwrongly,onthe other hand, it has predicted correctly for 16 subjects and incorrectlyfor20subjects.
In the above diagram (Random Forest confusion matrix) we can see that it is predicted that 52 people do not have CKD which is correct but for 3 subjects, it has predicted wrongly, on the other hand, it has predicted correctly for 25subjectsandincorrectlyfornone.
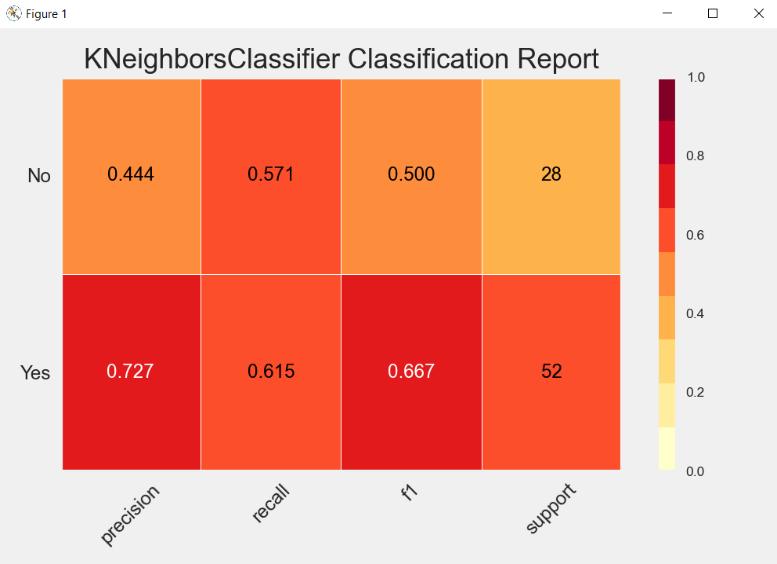
The above diagram tells us about the classification of the KNN algorithm. As we can see that we are getting a good precision of 72.7% for Yes and 44.4% for No. Also, for recall the accuracy is good which is 61.5% for Yes and 57.1%forNo
Below are the confusion matrix as well as classification reportforRandomForestalgorithm
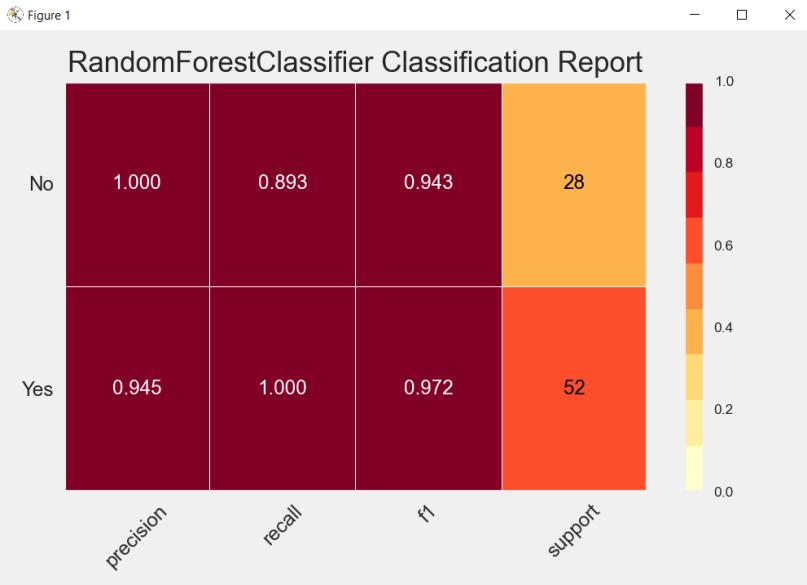
The above diagram tells us about the classification of the Random Forest algorithm. As we can see that we are gettingagoodprecisionof94.5%forYesand100%forNo. Also,forrecalltheaccuracyisgoodwhichis 100%forYes and89.3%forNo
AsshowninthebelowimagewecanseetheuserInterface whichwedesignedfortestingtheuserinput.Wehavebuilt this UI using Flask micro framework. In the UI part, the user enters the values which are required to diagnose kidneydiseasebythedevelopedtrainedmodel.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Preprocessing was done to make the data clean and appropriate for the machine learning models using relevant libraries. In this study, the missing values have been handled using the mean replacement method and categoricalvalueshavebeenconvertedtobinary.
[1] Prof. Sachin Wakurdekar, Munish Goswami, Anupama Sharma and Harshit Gupta, “Chronic Kidney Disease Detection Using RFA”, IJIRT, vol 8, Issue 3, pp. 714 718, Aug.2021.
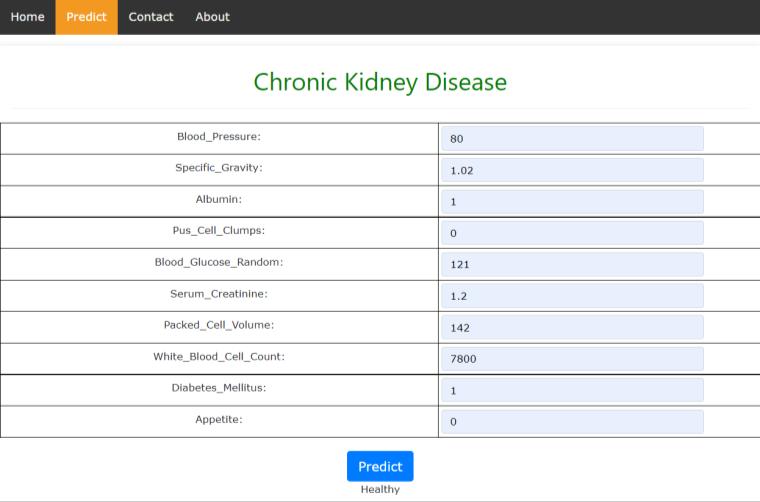
Fig10:Healthyprediction (Predictionpageofwebsite)
[2]JiayuDuan,ChongjianWangetal.,“Prevalenceandrisk factors of chronic kidney disease and diabetic kidney disease in Chinese rural residents: a cross sectional survey”, Nature, 2019, https://doi.org/10.1038/s41598 019 46857 7
[3]RoshniPR*,MahithaMathew,“RiskFactorsAssociated WithChronicKidneyDisease:AnOverview”,Int.J.Pharm. Sci. Rev. Res., 40(2),; Article No. 47, pp. 255 257, September October2016
[4] Jiongming Qin, Lin Chen, et al., “A Machine Learning Methodology for Diagnosing Chronic Kidney Disease”, IEEEAccess,vol8,pp.20991 20993,2020
[5]T. K.An,M. H.Kim,AnewdiverseAdaBoostclassifier, 2010InternationalConferenceonArtificial Intelligence and Computational Intelligence, IEEE, 2010, pp.359 363.
[6] M.J.I.J.o.R.S. Pal, Random forest classifier for remote sensingclassification,26(2005)217 222.
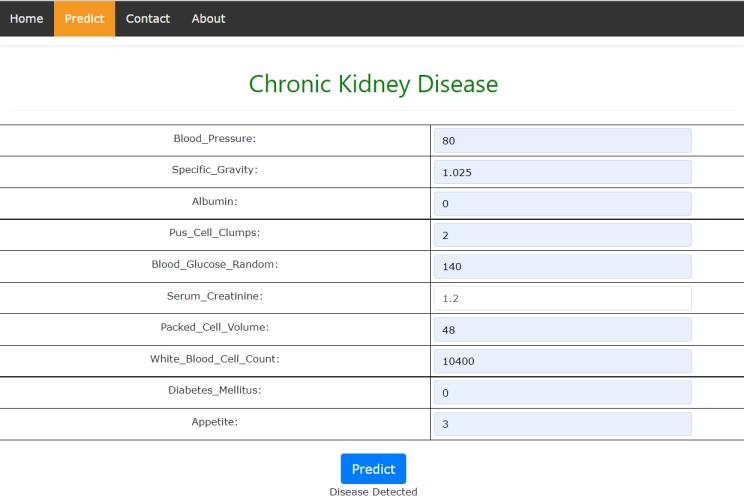
Fig11Kidneydiseasedetected (Predictionpageofwebsite)
Early prediction is very crucial for both the experts and the patients to prevent and slow down the progress of chronickidneydiseasetokidney failure.Inthisstudy, the chronic kidney disease prediction, using the machine learningtechniqueisproposedwiththedeploymentofthe modelinordertohelptheexpertstodiagnosethedisease quickly.
Specific machine learning methods were evaluated by literature. We have used ensembles like boosting in the predictionofkidneydiseaseusingnumericdatatoachieve better accuracy results. Testing data sets setting together strategieswereextremelyefficient.
The proposed study also employs the feature selection methodinordertoselectthemostrelevantandpredictive features.
[7] V. Jha , G. Garcia Garcia , K. Iseki , Z. Li , S. Naicker, B. Plattner, R. Saran, A. Y. Wang, C.W. Yang (2013),”Chronic kidney disease: global dimension and perspectives”, The Lancet.
[8] Kunwar, V., Chandel, K., Sabitha, A. S., & Bansal, A. (2016).ChronicKidneyDiseaseanalysisusingdatamining classification techniques. In 2016 6th International Conference Cloud System and Big Data Engineering (Confluence)(pp.300 305)
[9] L. Xun, Wu Xiaoming, Li Ningshan and Lou Tanqi, "Application of radial basis function neural network to estimate glomerular filtration rate in Chinese patients with chronic kidney disease," 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, 2010, pp. V15 332 V15 335.
[10] A. Salekin and J. Stankovic, (2016) “Detection of chronickidney diseaseand selecting important predictive attributes,” IEEE International Conference on Healthcare Informatics.