International Research Journal of Engineering and Technology
(IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072

(IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
Pooja K C1 , Pooja K P2 , Pooja N G3 , Dr.A B Rajendra4
1 3 Students, Information Science and Engineering
2Head of Department, Dept. of Information Science and EngineeringVidyavardhaka College of Engineering, Mysuru, Karnataka, India
India is a country where the primary economic sectors are agriculture and industries that are closely related to it. It has become one of the nations that have had significant natural catastrophes like drought or flooding that have destroyed crops. Predicting acceptable crops to produce and suggesting proper fertilizers to improve crop output long before the harvest helps farmers and the government in making appropriate plans such as storing, selling, determining minimum price, importing/exporting, and so on. A thorough analysis of enormousvolumes ofdataobtainedfromnumerous variables, including soil quality, pH, EC, N, P, and K, is necessary for an advanced crop prediction. As it involves an enormous number of databases, this prediction method is an absolute option for data science applications. We take out insights from huge amounts of data using data science. This system provides a study on the various machine learning methods for predicting the best crops and recommending fertilizer. The performance of any crop prediction system depends critically on how accurately features are extracted and how well classifiers are employed. We have used two algorithms that are Naïve Bayes and KNN for predicting the crop and fertilizers respectively.
Key Words: Crop Prediction, Data Science, Machine Learning, Naïve Bayes, KNNIndia's main source of income is agriculture, which is an example of a sector that contributes only approximately 14% of GDP yet has a huge impact on the economy of the country. To raise the crop output and the farmers' living conditions, better methods are needed. Agriculture has evolved as a result of globalization, adopting the latest technologies andpracticesfora higherlevel ofliving.One of the more recent technologies and methods in agriculture is precision agriculture. Crop and fertilizer recommendations are one of the most important aspects of precision agriculture. Crop suggestion is based on several factors,[6] and precision agriculturetechnologies aid in detecting these factors, allowing forimproved crop selection. Farmers may benefit fromknowingtherelative contributions of climate factors on agricultural output in ordertoplantand managecropsin theface of climate
Based on input andtraining data, machine learning can forecastsuitabilitylevels using a variety of techniques. In the suggested task, we forecast crops and provide the required fertilizers to increase agricultural output. For crop productionestimationandfertilizerrecommendations, we employ a variety of agricultural characteristics. The currentagriculturalfieldisbesetbyissues,oneofwhichis inadequate for farmers. Farmers plant cropsbut do not receive adequate yields, resulting in lowerprofits. Crop recommendations and appropriate fertilizer recommendations are critical in the agriculture department, and appropriate crops and fertilizers are determined by a variety of factors like soil, rainfall, and temperature characteristics. It is critical to make early predictions based on these limits. ML can be utilized effectively to assist farmers in achieving the highest potentialoutput.Thelistofpartsthatmakeupthispaper's organization is given below. Section 2 comprises the literature survey, which also contains a table that compares the paper of different authors. Section 3 comprisesthemethodology,whichhas8stepsinit,andalso contains a brief description ofthe algorithm used in the project. Section 4 contains the overview of the proposed system. Section 5 contains the conclusion and References arefoundintheSection8part.
1. Sally Jo Cunningham and Geoffrey Holmes,[10] proposed the Developing innovative applications in agriculture using datamining.ThemethodsinvolvedinthisareWekaclassifiers: ZeroR, OneR, Naïve Byes, Decision Table, Ibk, J48, SMO, Linear Regression, M5Prime,LWR, Decision Stump and associationruleincludeapriorialgorithmandalsoitincludes theEMclusteringalgorithmforthepurposeofclustering.This producesaclassifier,which isfrequentlyinthedecisiontree formoracollectionofguidelinesthatcanbeusedinpredicting the categorization of newer data instances. This approach recognizes that machine learning technology is still expandingandimproving,withlearningalgorithmsthatmust bedeliveredtothepeoplewhodealwiththedataandarealso familiar with the application domain from which it originates. Weka is a huge step forwardin bringing machine learningintotheworkplace.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
2. D Ramesh, and B Vishnu Vardhan detailed Data Mining Techniques and Applications to Agricultural Yield Data [11]. The KNN and K Means Algorithms areused in this. Thesystemcananticipatetheaverage yieldproductionby examining the cluster to which the forecasted rainfall belongs in this procedure, given therainfall in a specific year.ItalsomentionsthattheK Meansalgorithmcansplit samples into clusters, but noconsideration is given to the substances that cause this partition. This type of informationcanbeobtainedusingbi clustering.
3. Monali Paul, at el.[12] Described the Analysis of soil Behavior and Prediction of Crop Yield using the Data MiningApproachintheyear2015.Foritssystemto work, it employs the KNN and the Naïve Bayes Algorithm. This demonstrates that the category with the highest confidence value is projected to be the category of that specific soil.It also suggests that this research can assist soil analysts and farmers in determining which land to seedoninordertomaximizeagriculturalyield.
4. Ami Mistry and Vinita Shah[13] described the Brief Survey of data mining Techniques Applied to applications of Agriculture in the year 2016. This system employs a variety of approaches, including Linear Regression, KNN, Regression Tree, and SVM for classification. K means clustering, Self organized maps, Density based clustering, and Weight based clustering are examples of clustering techniques. The results indicate that rice production variability is influenced by sunshine hours and daily temperature variation in the current research area. According to this, farmers might plant different crops in differentregionsbasedonbasicforecasts produced by this research, and if that happens, every farmer would have a chancetoboostthecountry'soverallproductivity.
5. Yogesh Gandge, and Sandhya[14] described A Studyon Various Data MiningTechniquesfor Crop Yield Prediction in the year 2017. This system uses a Classification Algorithm. The agricultural yield prediction per acre is the outcome, along with some recommendations. It is noted that the method used by most experts does not employaunifiedapproachinwhichallelementsimpacting cropproductioncanbeusedsimultaneouslyforcropyield prediction.
6. Md. Tahmid Shakoor, et al.[15] described Agricultural Production Output Prediction Using Supervised Machine Learning Techniques in the year 2017. This system uses the KNN algorithm, Decision Tree algorithm, and ID3 (Iterative Dichotomis) algorithm. Without eliminating the dataset's outliers, the Decision Tree Learning ID3 approachproducesalowerpercentageerrorvaluethanthe KNN technique. Though the study is confined to a single set of data, more data will be added in the future, which willbeanalyzedusingmoremachinelearningalgorithms
7. Umid Kumar Dey et al.[16] described the Rice Yield PredictionModelUsingDataMiningintheyear2017.This system uses the k means algorithm, Linear Regression, SVMRegression, andModifiedNon linearRegression. This system has been found to be quite good at predicting yields, with SVM regression providing the best performance. The modified Non linear regression equation is found to perform better than the other three predefined models. It also establishes that the MNR equationisthemostappropriate.
8.KuljitKaurandKanwalpreetSinghAttwal[17]proposed “EffectofTemperatureandrainfallonPaddyyieldusingData Miningintheyear2017.TheyusedtheAprioriAlgorithmfor theirstudy,whichgavetheresultthatpredictsthegrowthof thepaddyyield.Thisdependedonvariousparameterslike Rainfall and Temperature. Inthe end,theyconcludedthat with the increase in rainfall the paddy yields also increased. During the reproductive phase, the rainfall and temperature did not influence, and also during the maturationphase,theyieldwasbetterexpectedatthelower temperatureandworseatahighertemperature.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1459
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
S.No. Title Author Methodused Results
1. Developing innovative applications in agriculture usingdatamining
2 DataMiningTechniquesand Applications toAgricultural YieldData.
Sally Jo Cunninghamand GeoffreyHolmes
DRamesh,BVishnu Vardhan
Weka classifier: ZeroR,OneR, Naive Bayes, Decision Table, Ibk, J48, SMO, Linear Regression.AssociationRules: AprioriAlgorithm Clustering: EM ClusteringAlgorithm.
Theendresultisaclassifier,whichis typically in the shape of a decision treeorguidelinesthatcanbeusedto anticipate how fresh data examples willbeclassified.
KNN,KMeansalgorithm. Byexaminingtheclusterinwhichthe projected rainfalls, the system can predicttheaverageyield production basedontherainfallina certainyear.
3 Analysis of Soil Behavior andPredictionofCropYield usingDataMiningApproach.
4 Brief Surveyofdata mining Techniques Applied to applications of Agriculture
5 A Study on Various Data MiningTechniques for CropYieldPrediction
6 Agricultural Production Output Prediction Using Supervised Machine LearningTechniques
7 Rice Yield Prediction ModelUsingDataMining
Monali Paul, Santosh K. Vishwakar ma, Ashok Verma.
KNNandNaiveBayes. Wecanseefromtheresultsthatthe categorywiththehighestconfidence valueisexpectedtobe the soil category for that specific soil.
Ami Mistry, Vinita Shah Classification technique: LinearRegression,K nearest neighbor Clustering Technique: K means clustering, Selforganized maps, Densitybased clustering.
Yogesh Gande and Sandhya.
The results indicate that in the currentstudyarea,sunlighthoursand the range of daily temperaturehave important roles in rice yield variations.
ClassificationAlgorithm. The output is a projection of agricultural yield peracre along withsomesuggestions.
Md.TahmidShakoorand others. KNN,DecisionTreealgorithm, ID3(Iterative Dichotomis) algorithm
UmidKumarDeyand others. KMeans, Multiple Linear Regression, Modified Nonlinearregression.
The result reveals that without eliminatingthedataset'soutliers,the Decision Tree Learning ID3 approach delivers a lower percentage error value than the KNNtechnique.
It can be observed that it predicts yieldswell,withSVMasbestresult.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
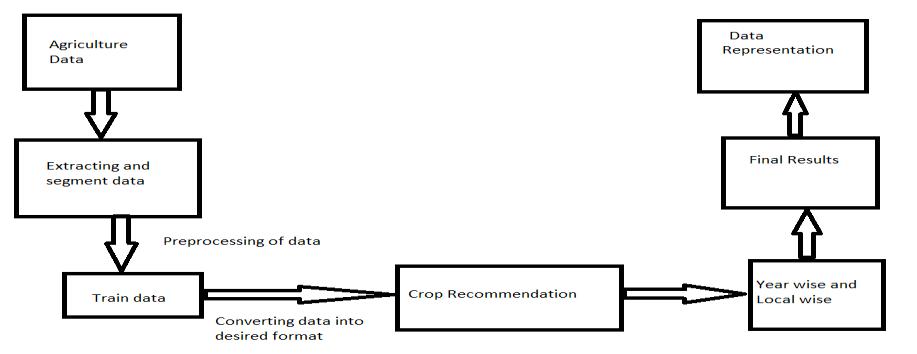
Step 1: Raw data and Weather Statistics
This is the first step in the crop recommendation process wherewecollectagriculturedata.Agriculturedata,including agriculturecharacteristics,cropdetails,farmerdetails,and yield details, was obtained from the region "Mysore." Rainfall,temperature,andsoil[6]characteristicssuchasPH, nitrogen, potassium, iron, and so on are all considered agricultureparameters.
Agriculture data is analyzed here, and only relevant information is taken. The information needed for processing is extracted and split into various regions. Because the completeagriculturedataisnotnecessaryforprocessing,and becauseifweinputalldata,processingwouldtaketoolong, dataprocessingisperformed
Aftertherelevantdatahasbeenextracted and segmented, the data must be trained, which involves translating the data into the required format, such as numerical values, binary, string, and so on. The type of algorithmdeterminestheconversion.
Designing and analyzing data learning systems is a major focusinthefieldofmachinelearning.
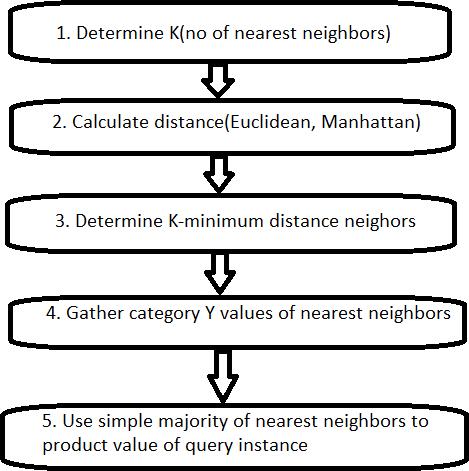
It is one of the effective algorithms that just operate on numbers. For numerical data, it functions and moves throughdatamorequicklythanotheralgorithms.Itoperates basedondistancecalculation.
Fig 2: FlowofKNNalgorithm
Supervised learning isatypeofmachinelearningthat employstrainingdatathatincludespredictedresponses.
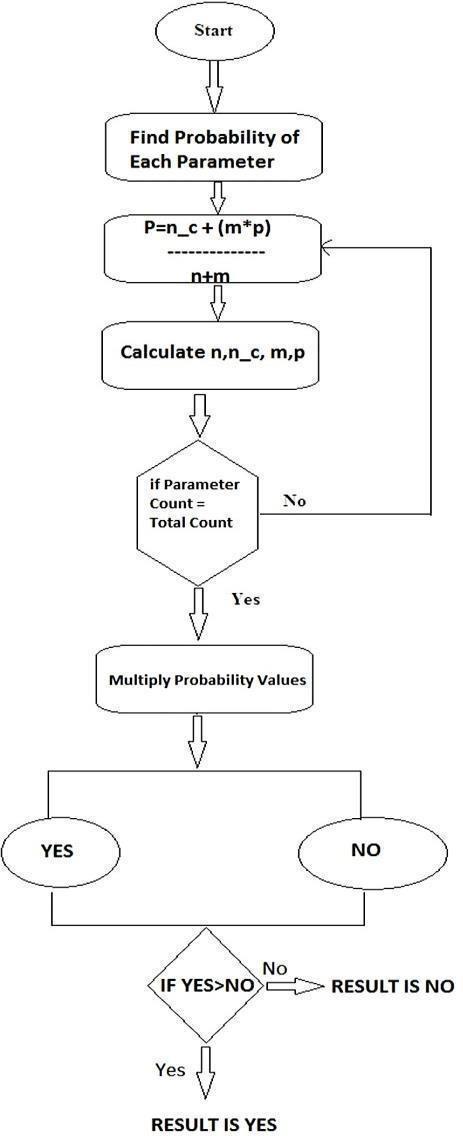
Naive Bayes Algorithmisusedforcroprecommendation becauseofthefollowingreasons:
Efficientclassifier
Worksfineforasmallernumberofparametersas wellasagreaternumberofparameters.
Worksfineforsmallandbigdata set.
Moreaccurateresults
Fig 3:FlowofNaïveBayesalgorithm
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
Heresuitablecropsarerecommendedforthefarmerswhich mayyieldhighprofits.ThenaïveBayesalgorithmgenerates outputs(croprecommendations)basedonprioritywise.
Thecroprecommendationisbasedonregion wiseand year wise.
Advisingsuitableandhigh profitcropstofarmersisdonein priorityorder.Herehighprobabilitycropsareextractedand sortedandthetop3cropsarerecommendedforthefarmers.
CropsarerecommendedforthefarmersonGUI.Whenusers get to log in, the application system recommends suitable andhigh profitcropsforthefarmersonaGUI.
TheTheproposedsystemcontains2majorobjectives,one recommendingsuitablefertilizerbasedonthesoiltypeand features, and secondly suggesting the suitable crop dependentonenvironmentalconditions.Machinelearning algorithmsareapplied toanalyzedata andtorecommend suitable fertilizers and suitable crops. Data sets were collected from agriculture departments. Rainfall, temperature, PH value, nitrogen, potassium, zinc, phosphorous, iron, etc. all these parameters are used for recommendation. The system developed as a real-time application that is useful for agriculture departments and farmers.
We use suitable technology to work with real time applications,inthefront endweusevisualstudio,andinthe back end SQL server is used. These technologies are preferredbecauseitsupportsmoresuitablelibraries,tools, and concepts required to work with real time application comparedtoothertechnologies.Therecommendedsystem helps farmers to grow the suitable type of crops at the correct time and also by suggesting suitable fertilizer for increasedcropyield.Thisapplicationwillbehelpfultothe majority of Indians. The Bayesian classifier, K nearest neighbor, or Random Forest algorithms are examples of supervised learning algorithms that are utilized for the recommendations. These algorithms are chosen because they produce quicker results, operate effectively, and supportalldataformats.Afewsurveypublicationshavealso suggestedthatthesealgorithmsareeffectiveandsuitablefor datasetsrelatedtoagriculture.
Nowadays farmers face ample issues and they don’t recognize the correct info concerning crops to grow and cultivate.Thisplannedsystemhelpsfarmerstounderstand thecorrectcroptogrow.Theplannedsystempredictsthe crop’s victimization information science techniques supportedthesoil testedresults. This methodis additionally helpful to agriculture departments to predict the correct croprighttime.Ifwe'vegotsuchreasonableautomation,is going to be helpful to farmers and agricultural fields. The createdsystemachievestheobjectivesbystreamliningand reducing manual labor, preserving enormous amounts of knowledge,andfacilitatinganefficientworkflow.We'veseen how techniques like data mining and machine learning algorithmscanenableustoanalyzedataandrecommendthe most appropriate fertilizer and crops for a given piece of land. The recommendations are made using a supervised learning algorithm, like a Bayesian classifier, K nearest neighbor, or Random Forest algorithm. These algorithms havebeenchosenbecausetheyworkreliably,providequick results, and are compatible with every data format. The system makes use of data gathered by the agriculture department.However,theproposedsystemisareal world application aimed at agriculture departments, assisting farmersincultivatingsuitablecropsandhighprofit.
[1] Maria Rossana C.de Leon,Eugene Rex L.Jalao, “A predictionmodelframeworkforcropyieldprediction,”Asia PacificIndustrialEngineeringandManagementSystem.
[2]RameshA.Medar,VijayS.Rajpurohit,“AsurveyonData MiningTechniquesforcropyieldprediction”,International Journal of Advance Research in Computer Science and ManagementStudies.Volume2,Issue9,Sept2014.
[3]DRamesh,BVishnuVardhan,“Regionspecificcropyield Analysis: A data Mining approach “, UACEE International Journal of Advancees in computer Science and its Applications IJCSIAvolume3:issue2.
[4] George RuB, “Data Mining of Agricultural Yield Data:A comparisonofRegressionmodels.
[5]SudhanshuSekharPanda,DanielP.Ames,andSuranjan Panigrahi,“ApplicationofVegetationIndicesforAgricultural Crop Yield Prediction Using Neural Network Techniques”, RemoteSensing2010,2,673 696;doi:10.3390/rs2030673
[6] S.Veenadhari,Dr. Bharat Misra ,Dr. CD Singh,” Machine Learning Approach for forecasting crop yield based on climatic parameters”, 978 1 4799 2352 6/14/$31.00 ©2014IEEE
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 07 | July 2022 www.irjet.net p-ISSN: 2395-0072
[7]https://www.ifad.org/en/web/latest/event/asset/41949 435June,2020
[8] DigitalGreen(2019).FarmStack.ADigitalGreenWeb Publication.Availableonlineat:https://farmstack.co/
[9] Das, A., Basu, D., and Goswami, R. (2016). Accessing agricultural informationthroughmobilephone:lessons of IKSLservicesinWestBengal.IndianRes.J.ExtensionEduc. 12, 102 107. https://api.semanticscholar.org/CorpusI D:168547286
[10] https://www.researchgate.net/publicat ion/2606155_Developing_Innovative_Applications_in_Agricu lture_Using_Data_Mining
[11] Data Mining Techniques and Applications to Agricultural Yield Data D Ramesh, B Vishnu Vardhan Associate Professor of CSE, JNTUH College of Engineering, KarimnagarDist.,AndhraPradesh,India1ProfessorofCSE, JNTUH College of Engineering, Karimnagar Dist., Andhra Pradesh,India2
[12] Monali Paul, at el. Described the Analysis of soil Behaviour and Prediction of Crop Yield using the Data Mining Approach in the year2015 https://www.researchgate.net/publication/ 306302068_Analysis_of_Soil_Behaviour_and_Prediction_of_C rop_Yield_Using_Data_Mining_Approach
[13] Umid Kumar Dey et al. described the Rice Yield Prediction Model Using Data Mining in theyear 2017. https://www.researchgate.net/publication/ 316906792_Rice_yield_prediction_model_using_data_mining
[14]AmiMistryandVinitaShahdescribedtheBriefSurvey of data mining Techniques Applied to applications of Agriculture in the year 2016 https://www.researchgate.net/publication/ 301214822_IJARCCE_Brief_Survey_of_data_mining_Techniqu es_Applied_to_applications_of_Agriculture
[15] Kuljit Kaur and Kanwalpreet Singh Attwal proposed “Effect of Temperature and rainfall on Paddy yield using DataMining in the year 2017. https://www.researchgate.net/publication/ 317424300_Effect_of_temperature_and_rainfall_on_paddy_yi eld_using_data_mining.