International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
1Assistant Professor, Department of Computer Engineering, Bharati Vidyapeeth (Deemed to be University) College of Engineering, Pune, Maharashtra, India 2, 3, 4Student, Department of Computer Engineering, Bharati Vidyapeeth (Deemed to be University) College of Engineering, Pune, Maharashtra, India ***
Abstract - Because of its widespread use in a variety of game genres and its ability to simulate human like behaviour, intelligent agent training has piqued the interest of the gaming industry. In this paper, two machine learning techniques, namely a reinforcement learning approach and an Artificial Neural Network (ANN), are used in a fighting game to allow the agent/fighter to simulate a human player. We propose a customised reward function capable of incorporating specific human like behaviours into the agent for the reinforcement learning technique. A human player's recorded bouts are used to educate the ANN. The proposed methods are compared to two previously published reinforcement learning methods. Furthermore, we provide a comprehensive overview of the empirical assessments, including the training procedure and the primary characteristics of each approach used. When compared to other current approaches, the testing results revealed that the proposed methods outperform human players and are more enjoyable toplay against.
The AI bot's logic is based on Reinforcement Learning Techniques. This method considers the game's previous stateandrewardsit(suchasthepixelsseenonthescreen in case of the Atari Games or the game score in case of cardgameslikeBlackjack).Itthendevisesaplanofaction against the environment. The goal is to make the next observation better (in our example, to increase the game score). An agent (Game Bot) selects and performs this activity with the goal of increasing the score. It is then exposedtotheenvironment.Theenvironmentrecordsthe outcome and reward based on whether the activity was beneficial(diditwinthegame?).
This project aims to develop a virtual assistant that can learn a variety of games, beginning with simple card games like Blackjack and progressing to more complex video games in the future. The AI bot uses Reinforcement Learningtotrainandimproveitslevelofexperienceinthe game. When compared to other machine learning technologies,RLisbestsuitedfordevelopingcomplexbot behaviour within a game. Like a human player, the learning bot interacts with its surroundings and receives feedbackbasedonitsactions.
As feedback, a reward for a successful action or a loss of life/points for a bad action can be used. The bot's behaviour is then improved based on the incentives and punishmentsitreceives.Thislearningmethodissimilarto howhumanslearnby trial anderror,and itworkswell in complex game situations. Players are drawn to online playerversusplayergamesbecausehumanplayersaddan element of surprise that traditional bots do not. This problemiseffectivelyhandledbyRL.Themaingoalofthe project was to find solutions to a variety of simulations that could one day be real life challenges rather than games.
This game playing bot's activities will never be limited to standardstepstakenbyplayers,butwillinsteadcreateits ownmethodsandnewvariations,makingitimpossiblefor aplayertosimplymemoriseitsmovesandbeatit.
(1) Agent: The person who solves problems can take certainactionsinagivensetting.
(2) Environment: The residence of an agent. An environmentprovides responsestoanagentbasedonthe actionsitperforms.
(3) Reward: When an agent performs an action in an environment, there is an associated reward; rewards can bepositive,negative(punishment)orzero.
(4) State: An agent’s action may cause it to enter a state whichyoucanassumetobeasnapshot(partialorwhole) of the environment. (Like checkmate(state)on a chess board(environment))
(5) Policy: Defines an agent’s behaviour, can answer questions like what action should be performed in this state?
(6) Value: Tracks the long term impact of the action. Provides a portion of reward to intermediate states that ledtoafinalpositivestat.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Blackjack is the American version of a popular global banking game known as Twenty One. It is a comparing card game between one or more players and a dealer, whereeachplayerinturncompetesagainstthedealer.
Players do not compete against each other. It is played withoneormoredecksof52cards,andisthemostwidely playedcasinobankinggameintheworld.
[1]Blackjackisacardgameinwhichtheobjectiveistoget as close to 21 as possible without going over. They're up againstapredetermineddealer.
[2] The value of the face cards (Jack, Queen, and King) is tenpoints.Acescanbecountedas11or1,andthenumber 11 is referred to as 'usable'. This game is set up with an unlimited deck of cards (or with replacement). The game begins with one face up and one face down card for each playeranddealer.
[3] The player can request more cards until he or she decides to stop or reaches the limit of 21. (bust). The dealer displays their facedown card and draws until their amount is 17 or larger after the player sticks. The player wins if the dealer goes bust. If neither the player nor the dealerbusts,thewinner(orloser)isdeterminedbywhose totalisclosestto21.
[4]Winninggivesyou+1,drawinggivesyou0,andlosing givesyou 1.
Following that, game developers attempted to simulate howhumansplayagamebydevelopingagamingbotthat mimicked human intelligence. As a result, machine learning (ML) trained bots were created, which were trainedusingavarietyofMLtechniques
This project will attempt to teach a computer (reinforcement learning agent) how to play blackjack and outperform the average casino player, with the goal of eventuallymovingontoothergamesandfeatures.
Most traditional ML based gaming models have the problem of being programmed to respond to hardcoded rulesorpatternsthat are usuallyfollowed byplayers, but because humans are unpredictable, these ML Models fail tokeepupandconstantlyimprovethemselves.
Toaddressthisissue,Q learning,areinforcementlearning technique, will be used. For each state action pair, a Q table is created, and the related entry in the Q table is changed based on the prize won after each round of the game. After the agent has thoroughly studied the environment, the learning process is complete. At this point, we'd have the optimised Q table, which is the blackjackstrategytheagenthaslearned.Itisareasonable choice as a performance measure because a prize is awarded at the end of each round of the game. To assess the efficacy of various approaches, a large number of rounds must be played in order to get close to their true rewards. As a result, the average reward after 1000 roundsofthegamewillbeusedtocomparethesimulated performance of the typical casino player to that of the trainedagent.
We mainly use Q learning, Monte Carlo Prediction and Actor Critic Learning to overcome the problems faced by traditional ML Models. Actor Critic Learning constantly evolves the machine learning model by using reward punishmentmechanismwithalearningagent.
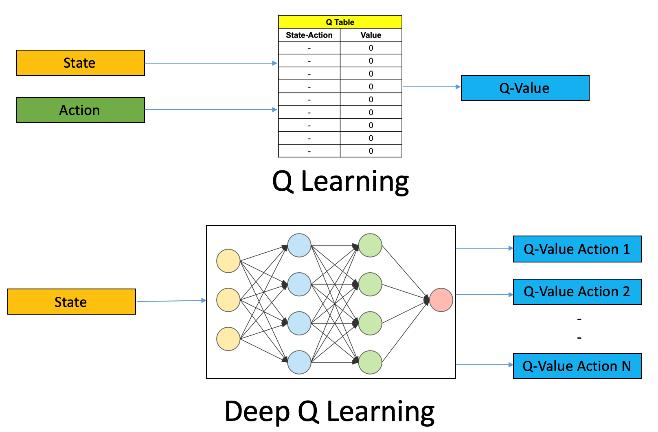
Qualityisrepresentedbytheletter'q'inq learning.Inthis situation, quality refers to how valuable a specific activity is in obtaining a future reward. Given a current state, Q Learning is a Reinforcement learning policy that will determine the next best action. It selects this action at randomwiththegoalofmaximisingthereward.
Giventhepresentstateoftheagent,Q learningisamodel free,off policyreinforcementlearningthatwill determine the best course of action. The agent will pick what action to take next based on where it is in the environment. The model'sgoalistodeterminetheoptimumcourseofaction given the current situation. To accomplish this, it may deviseitsownsetofrulesoractoutsideofthepolicythat hasbeen establishedforittoobey.Thismeansthereisn't arealneedforapolicy,whichiswhyit'scalledoff policy.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Model free indicates that the agent moves forward based on estimates of the environment's expected response. It does not learn through a reward system, but rather by trialanderror.
Monte Carlo simulation is a computer assisted mathematical technique for incorporating risk into quantitative analysis and decision making. Professionals in a variety of sectors, including finance, project management, energy, manufacturing, engineering, research and development, insurance, oil and gas, transportation, and the environment, employ the technique. For each given course of action, Monte Carlo simulation provides the decision maker with a range of probable outcomes as well as the probabilities that they willoccur.
It depicts the extreme outcomes the implications of going for broke and the most conservative decision as well as all possible outcomes for middle of the road selections. Scientists working on the atomic bomb were thefirsttoemploythetechnology,whichwasnamedafter Monte Carlo, the Monaco vacation town known for its casinos.MonteCarlosimulationhasbeenusedtomodel a range of physical and conceptual systems since its beginningsduringWorldWarII.
CODE:
Work withaparameterizedfamilyofpolicieswhileusing actor only techniques. The actor parameters are directly evaluated by simulation to determine the performance gradient, and the parameters are then updated in an upwardmanner.
Such approaches may have a disadvantage in that the gradient estimators may have a high variance. Additionally, a new gradient is estimated independently of earlier estimates as the policy changes. As a result, there is no "learning" in the sense of gathering and consolidatingpriorknowledge
Thegoalofcritic onlyapproaches,whichsolelyusevalue functionapproximation,istodiscoveraroughsolutionto the Bellman equation, which will hopefully subsequently suggestaclosetooptimalcourseofaction. Such approaches are indirect because they don't directly attempt to maximise over a policy space. This kind of approach might be successful in creating a "decent" approximation of the value function, but it lacks trustworthy assurances for the near optimality of the resultingpolicy.
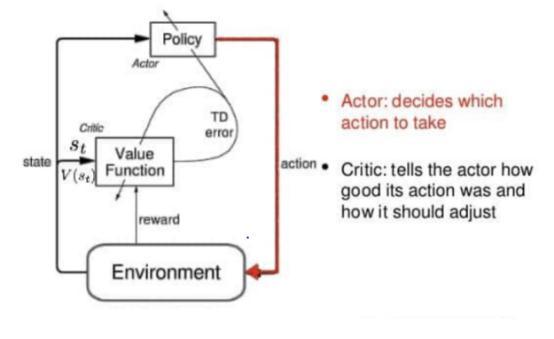
The advantages of actor only and critic only methodologies are intended to be combined in actor critic methodologies. The critic learns a value function through simulation and an approximation architecture, then uses that knowledge to modify the actor's policy parameters.
Actor Critical Algorithms 1009 are directed toward enhancing performance. As long as they are gradient based, such approaches may have desirable convergence features as opposed to critic only methods, where convergence is only possible in very specific circumstances.
When compared to actor only approaches, they have the potentialtoachievefasterconvergence(owingtovariance reduction). On the other hand, lookup table representations of policies have been the only focus of theoreticalunderstandingofactor criticapproaches.
The actor uses the state as input and produces the best action. It effectively regulates the agent's behaviour by teachingitthebestcourseofaction(policy based).Onthe otherside,thecriticcomputesthevaluefunctiontoassess theaction(valuebased).
These two models play a game where they both improve over time in their respective roles. As a result, the whole
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
architecture will develop better game skills than the two individualways.
One way we can improve is by using reward discounting tomoreintelligentlyallocaterewardsforactions.Itisbest tosupportthemostrecentactionorframeinthecaseofa positive reward and to discourage it in the case of a negative reward because it is the most pertinent. An exponential factor discounting factor, (gamma), with an initial valueof0.99,assigns lesscreditto anyactivities or timeframesthatoccurbeforetherewardwasearned.
seenthe inputimagebecausea largeportionof the pixels may be similar to an image that the NN has already seen and trained on. As a result, the NN is likely to output a prediction that is similar to the previously seen image. Again, we could perform this similarity comparison manually, but that would require much more work since theNNalreadyperformsitforus.
There are a few things we can do to speed up performance in general, reduce computation time, and run through more episodes in a given period of "wall clocktime.”
The effect of discounting rewards the 1 reward is receivedbytheagentbecauseitlostthegameisappliedto actionslaterintimetoagreaterextent
Discounting helps us come closer to our goals by more precisely assigning the reward to the behavior that is probablyasignificantcontributiontothebenefit.
In the case of Pong and other Atari games, the policy function,orpolicynetwork,usedtodeterminewhatto do next based on the input, is a fully connected Neural Networkwithhiddenlayers.
TheNNreceivesagameframeimageasinput,whereeach pixel represents a separate input neuron, and returns a decimal probability between 0 and 1, which translates to thelikelihoodthattheactionouragentpreviouslytookfor arelatedimagewasaUPmove.Itshouldbenotedthatthe probabilityoftheagentmakingaDOWNmotionincreases if the probability is below 0.5 and gets closer to 0. This policy is stochastic since it produces a probability. The numberofunitsinthehiddenlayerisahyperparameterof thesystemwhichisdecidedbyOptuna.
Since the chance that a certain action should be executed overtimeismorelikelytolietowardstheextremesof0or 1, the randomness factor becomes less important as the NN becomes more trained and the policy average reward increases.
Another advantage of the NN approach is that it doesn't matter if the previously described map hasn't actually
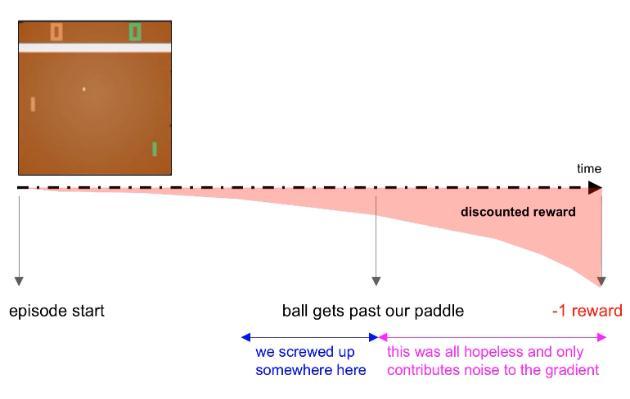
Image cropping as you can see from the Pong screenshots there are a lot of redundant areas which provide no value for our algorithm, for example the score section, and the white bar underneath the score. This has the added benefit of allowing us to ignore parts of the frame where the game result has already been decided, i.e.,aftertheballhaspastthepaddlealready
Diagram illustrating the case for ignoring / cropping the imagesectionaftertheballpassesthepaddle.
Gray scaling the color of the pixels is irrelevant so we can afford to remove them, for both the background and paddlecolors.Thepaddlesandballcanbethesamecolor, butshouldbeadifferentcolorfromthebackground.
Downsampling / reducing resolution lets us care about less of the image, and reduces the memory and computationrequirements.
Fig
Itwasnotedthatourbotfounditsimpletopickuponthe many games that were given to it. For each game, the output generally stayed relatively low until a certain
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
point,atwhichpointthebotbegantogenuinelylearnand developitsownstrategy.
Additionally, it was noted that our bot adopted several tactics throughout the training sessions. One of the most crucial aspects of reinforcement learning is that it preventsplayersfrompickingupourbot'stechniques.
As a result, they can play with the same bot repeatedly without feeling as though it is getting easier for them. Graphs havebeenusedtodepict theoutcomes ofthe bot playingthedifferentgames.
Thisissignificantimprovementfrombaselines.
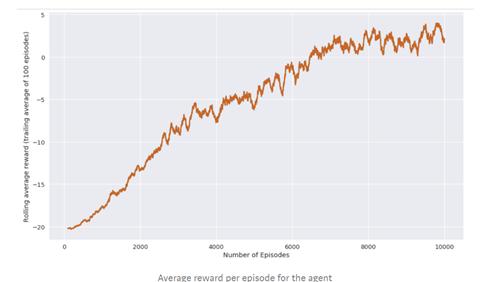
Thisistheperformancegraphobtainedononeparticular trainingofbotwhileplayingPONG.
Theresultsvarywitheverytrainingthatiscarriedout.
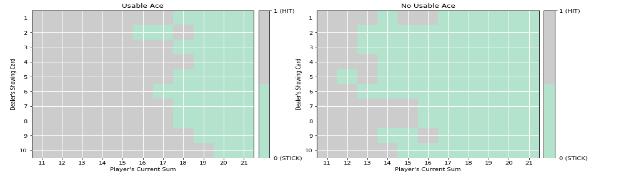
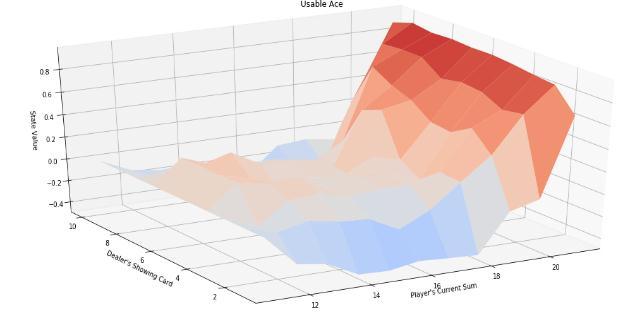
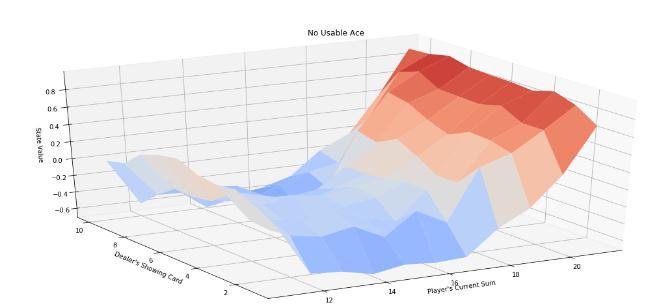
Basedontheabovegraphs,outbotdevisesastrategy for one training round thatcan be represented bythe below graph:
The reward (average of 100 episodes) is plotted along with the number of episodes and as we can see that the performance ofour bothas increasedsignificantly as the trainingprogressed.
Reinforcement learning is used by the AI bot to develop its skills and advance in the game. RL is most suited for creating complicated bot behavior within a game when compared to other machine learning techniques. The learningbotisengagingwithitssurroundingsandgetting feedback depending on its activities, just like a human playerwould.
For our first card game, blackjack, which has a smaller state space, we applied Q learning and Monte Carlo Control.
But as we shifted to playing Atari games, the state space and complexity of our games grew, thus we had to train ourbotwithmorecomplexalgorithmsliketheActorCritic Algorithm.
The above figure shows the strategy devised by our bot. Our policy based model performs better than the conventional80 20.aswellasarandompolicy.
In fact, ourbot does not require any training data at all and does not rely on any initial training data. As it advances in skill with each repetition, it learns by playing thegameitselfanddevelopsitsowntactics.
The project's outcome exceeded my expectations because mybotwasabletopickupallthegamesquicklyand,after a set number of training iterations, was ready to compete
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
againstplayersofaverageskill.Ifproperlytaughtover an extended period of time, this bot may even be able to defeatthegreatestplayers.
I intend to integrate Amazon Alexa into my work in the futureandaddthepossibilityforlearnerstoplaygamesas a feature. If this project is successful, Alexa's popularity will rise considerably. It will be directed at those residing in nursing homes and assist in addressing the long ignored issue of depression prevalent among older age groups.
We would like to thank Dr. S.B. Vanjale of Bharati Vidyapeeth Deemed to be University for his ongoing advice, support, and understanding. More than anything, he taught me to be patient in my work. My relationship with him extends beyond academia, and I am really fortunatetohavethechancetocollaborate witha thinker andMLandAIexpert.
We would like to convey our gratitude to all of the instructors for creating a productive environment and for serving as an inspiration throughout the duration of the course.
We convey imaginatively our sincere gratitude to our academicstaffandthepeoplewhoserveasthefoundation of our university for their non self centered excitement andtimelyencouragements,whichinspiredmetogainthe necessaryinformationtosuccessfullycompletemycourse study.Wewanttoexpressourgratitudetomyparentsfor theirhelp.
It is a joy to express our gratitude to our friends for their encouragement and persuasion to take on and complete this assignment. Finally, we would like to offer our appreciation and gratitude to everyone who has contributed, directly or indirectly, to the successful completionofthisproject.
[1] Robin, Baumgarten & Simon, Colton & Mark, Morris. (2018). Combining AI Methods for Learning Bots in a Real Time Strategy Game. International Journal of ComputerGamesTechnology.
[2] Azizul Haque Ananto .(2017). Self Learning Game Bot usingDeepReinforcementLearning
[3] Volodymyr Mnih Koray Kavukcuoglu David Silver (2018). Playing Atari with Deep Reinforcement Learning
[4] Vincent PierreBerges(2018).ReinforcementLearning forAtariBreakout,StanfordUniversity
[5] Leemon Baird. Residual algorithms: Reinforcement learning with function approximationrgan Kaufmann, 1995.
[6] Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of ArtificialIntelligenceResearch
[7] Marc G Bellemare, Joel Veness, and Michael Bowling. Investigatingcontingencyawarenessusingatari2600 games,2012.
[8] Marc G. Bellemare, Joel Veness, and Michael Bowling. Bayesian learning of recursively factored environments,2018.
[9] George E. Dahl, Dong Yu, Li Deng, and Alex Acero. Context dependent pre trained deep neural networks for large vocabulary speech recognition. January 2012.
[10] AlexGraves,Abdel rahmanMohamed,andGeoffreyE. Hinton. Speech recognition with deep recurrent neuralnetworks,2015.
[11] Matthew Hausknecht, Risto Miikkulainen, and Peter Stone. A neuro evolution approach to general atari gameplaying.2018.
[12] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neuralnetworks.2012.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |