International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Shesha Sai Balaji K P1 , Sourav N R2 , Dr. Shashikala3
1,2 VIII Semester, B.E., Dept. of ISE, BNMIT, Bangalore, Karnataka, India
3Professor and Head, Dept. of ISE, BNMIT, Bangalore, Karnataka, India ***
Abstract Security has become a priority in everyone’s life.
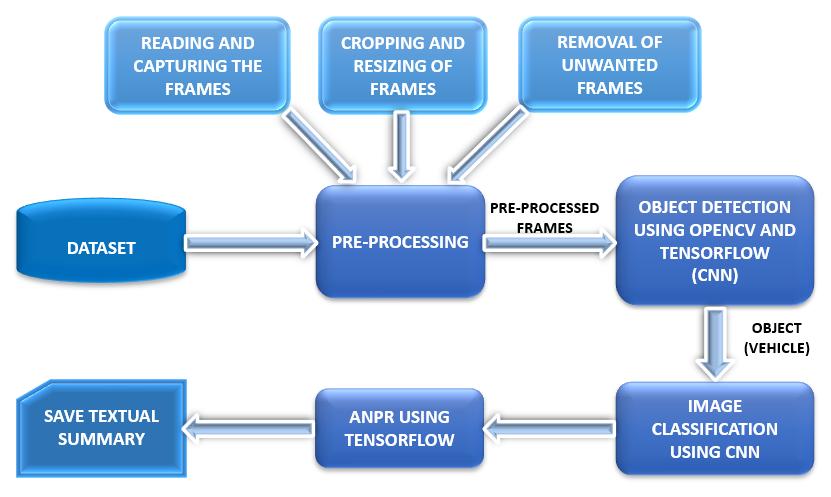
As a result, the number of security cameras has increased exponentially, necessitating massive storage capabilities to archive the footage. Due to many inactive parts, reviewing the entire footage is time consuming and monotonous. This work aims to provide users with a textual summary of the vehicles in the footage making reviewing easier. Firstly, unnecessary frames are removed to obtain a shorter video. The resultant video is then processed frame by frame using CNN for object classification and number plate recognition to obtain the textual summary
KeyWords: CNN,OpenCV,Security,Summary,TensorFlow
Surveillance is the monitoring of behavior, a range of activities, or data with the goal to acquire information, influence, manage, or direct. Security cameras, usually referredtoassurveillancecameras,areemployedtokeepan area under observation. These are used in a variety of circumstances by a range of businesses, institutions, or organizations.Typicallyattachedtoarecordingdeviceoran IPnetwork,theycanbewatchedbyasecurityguardorlaw enforcement officer to see if any criminal conduct is occurring. One such kind of surveillance is “Parking Surveillance”. It deals with monitoring and recording the activitiesoccurringintheparkinglot.Itispossibletodetect ifanimproperactivityhasoccurredbyviewingtheselected footageattheappropriatetimes.
Deep learning is an important domain in AI, and a lot of researchisbeingdoneonapplyingdeeplearningalgorithms to image datasets to obtain valuable insights and forecast possible future outcomes. Convolution Neural Network (CNN)excelsinseveraltasksconnectedtocomputervision, such as detection, classification, and recognition of both imagesandvideos.
Advancementintechnologyandprocessingcapabilitieshas equipped us with the ability to develop, deploy, and test complicatedneuralnetworks.
Yubo An et al, [1] put forth a method for Video Summarization that uses Temporal Interest Detection and KeyFramePredictionforsupervisedvideosummarization.A flexible universal network frame is constructed to predict
frame level importance scores and temporal interest segments simultaneously for the purpose of video summarization, which is presented as a problem of integrating sequence labelling and temporal interest detection.Thefollowingaretheprimarycontributionsand innovations:(i)Thevideosummarizationisfirstdescribedas a problem combining sequence labelling and temporal interestdetection.(ii)Basedontheproblemspecification,a universalnetworkframeispresentedthatforecastsframe levelrelevancescoresandtemporalinterestsegmentsatthe same time. The two components are then merged with different weights to produce a more thorough video summary.(iii)Theuniversalframeworksuccessfullyemploys the convolutional sequence network, long short term memory (LSTM), and self attention mechanism. A general framework can also be easily adapted to other effectivemodels.
V. Choudhary et al, [2] remove spatial redundancy by displayingtwoactivitiesthattookplaceindistinctframesat different spatial locations in a single frame, spatial redundancy is eliminated. Temporal redundancy is eliminated by identifying frames with low activity and discardingthem.Thenastroboscopicvideoisgeneratedthat tracesthepathoftheretrievedobject.Thefollowingstepsare used to create a video summary from the input video: (i) Objectsareextractedfromtheinputvideo.(ii) Acollectionof non overlapping segments is chosen from the original objects.(iii)Eachsegmentisgivenatemporalshift,resulting in a shorter video summary with no occlusions between objects.
K. Muhammadetal,[3]presentedaproductiveCNN based summarising technique for resource constrained devices' surveillance videos. Shot segmentation, which is the foundationofvideosummarisingsystems,affectstheoverall qualityofthefinalsummary.Withineachshot,theframewith thehighestmemorabilityandentropyscoreisconsidereda keyframe. When compared to state of the art video summarising approaches, the suggested method performs encouraginglyon two benchmark video datasets. This frameworkaimstoproposeanenergy efficientCNN based VStechniqueforsurveillancevideoscapturedbyresource constraineddevices.ItismotivatedbythepowerofCNNsfor diverse applications. Shot segmentation based on deep features, computing picture memorability and entropy for eachframeoftheshots,andkeyframeselectionfromeach shotforsummarygenerationareallpartoftheframework.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Finally,acolorhistogramdifferencebasedpost processing stepisusedtoremovetheduplicateframes.
M. Rochan et al, [4] addresses the problem of video summarization.Theobjectiveistochooseaportionofframes from theinput video to generate a summary video that accurately captures the input video's key points. Video summaryisausefultoolforvideosearch,retrieval,browsing, andotherusesbecausetherearesomanyvideosavailable online.Thedifficultyofsummarisingvideosmightbeviewed as a problem with sequence labelling. This workofferscompletely convolutional sequence models to addressvideosummarization,incontrasttopriorapproaches thatutilizerecurrentmodels.Priortoadaptingawell known semantic segmentation network for video summary, the authors firstcreatea novel relationshipbetween semantic segmentation and video summarization. The usefulness of thesemodelshasbeendemonstratedbyin depthtestsand analysisontwobenchmarkdatasets.Thechallengeofvideo summary is referred to as a keyframe selection problem. Fullyconvolutionalnetworks(FCNs)havebeensuggestedfor video summarization. FCNs are frequently employed in semanticsegmentation.
M.Prakashetal,[5]comparesandcontraststhe2categories of Video to video summarization: (i) Static Video Summarizationand(ii)DynamicVideoSummarization.Inthe former,relevantkey framesareextractedwhileinthelatter, relevant video shots are extracted. Video Summarization techniques may be based on the classification of the clustering basedapproaches.Toextractrelevantpartsofthe videoseveralfeaturesoftheframeslikeColourDistribution, Contrast, sharpness, edges can be considered. RNNs (RecurrentNeuralNetworks)likeLSTM(LongShort Term Memory)havebeenusedtoannotatetheimagesbygiving thedescriptionoftheimageinthetextualformat.Thesame conceptcanbeextendedtoannotatetheextractedrelevant partsofthesummarizedvideo.
S.Sahetal,[6]proposestechniquesthatleveragemethods thatmakeuseofcurrentdevelopmentsintextsummarising, videoannotationandsummarizationtosummarizehour long videos to text. The important contributions of this work: (i)Thecapabilityofdividingavideointosuperframeparts and ranking each segment according to the visual quality, cinematography standards, and consumer preference. (ii) integrating new deep learning findings in image categorization, recurrent neural networks, and transfer learningtoadvancethefieldofvideoannotation.Inorderto create textual summaries of videos that are legible by humans,(iii)textualsummarisingtechniquesareused,and (iv)knobsareprovidedsothatboththelengthofthevideo and the written summary can be adjusted. The proposed approach has 4 main components: (i) Finding intriguing sectionsintheentirevideo.(ii)selectionofthekeyframes fromtheseintriguingportions.(iii)Adeepvideo captioning networkisusedtocreateannotationsforthesekeyframes.
(iv) To provide a paragraph summary of the events in the video,theannotationsarecondensed.
G. Dhiraj Yeshwant et al, [7] suggest a technique for AutomaticNumberPlateRecognition(ANPR).Today,ANPR systems are employed in a variety of settings, including automatedtollcollection,parkingsystems,bordercrossings, trafficmanagement,lawenforcement,etc.Ahistogram based strategywasutilisedinthiswork,whichhastheadvantageof beingstraightforwardandquickerthananyotherapproach. To obtain the necessary information, this method goes through four basic processes. Image capture, plate localization, character segmentation, and character recognitionarethesefourphases.Theexecutionconsistsof: (i)Changeacolourimagetoagrayscaleimage(ii)Dilation:a methodthatenhancesagivenimagebyfillinginimagegaps, sharpeningobjectedges,reunitingbrokenlines,andboosting brightness.(iii)HorizontalandVerticalEdgeProcessing(iv) Passing histograms through a low pass digital filter to prevent loss of important information in further steps (v) Filtering out unwanted regions in an image (vi) Segmentation:Inthisstage,theregionsaredetectedwhere the license plate is probable to be present. (vii) Character recognition:Theentirealphanumericdatabaseiscompared to each individual character using Optical Character Recognition(OCR).
U.Shahidetal,[8]proposeanalgorithmthatisspecifically modelledtoidentifyautomobilelicenceplates.Thesystemis firsttaughtusingthedatasetofcollectednumberplates,and thisprocessisrepeateduntilthemachinelearns.Successful machinelearningwillresultinmoreprocessing.Animageof a car taken by a camera at a distance of two to three feet servesastheinput.ThisimageisprocessedusingNumber PlateExtractor(NPE),whichseparatesthecharactersofthe image and outputs it for segmentation. The data for each character is then stored in a row matrix. Finally, the recognition component uses a trained neural network to identifythecharactersandgeneratethelicencenumber.
G. KeerthiDevipriya etal, [9] deals with Classificationand Recognitionofimages.Theyuseaclassifieralgorithmandan API that includes a collection of pictures to compare the uploadedimagewiththesetofimagespresentinthedataset under consideration, exposing the performance of the trainingmodels.Theimageisaddedtotheappropriateclass after being determinedfor it. Imagesare classified usinga machinelearningmodelthatcomparesthemandplacesthem inthecorrespondingclasses.Theimplementationincludes: (i) Machine Learning Process that implements the classificationofimagesbyutilizingthestrategyofsupervised learning.(ii)ImageclassificationusingBagoffeatures:The concept of ‘Bag of Features’ has been inspired by “Bag of words”.Everyfeatureoftheimagehasbeenconsideredasa word in this model, analogous to the Bag of Words, and comparisonhasbeendonesimilartothewordcomparisonin documents.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page136
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
M. Azlan Abu et al, [10] propose an image classification architectureusingDeepNeuralNetwork(DNN),alsoknown asDeepLearningbyusingtheTensorFlowframework.The inputdatalargelyfocusesontheflowercategory,whichhas five (5)distinct flower variations. Due to its highaccuracy rate,adeepneuralnetwork(DNN)hasbeenselectedasthe bestalternativeforthetrainingprocedure.Inthefindings, the categorization accuracy of the images is shown as a percentage.Theaverageoutcomeforrosesis90.585percent, andthetypicaloutcomeforothertypesofflowersisupto90 percentorhigher.Thisprocedureisdividedintofourstages. Theprocedurecontinueswiththecollectionofsomeofthe images (inputs), followed by the application of DNN, and finally,theclassificationofallimagesintotheirgroups.
The proposed approach summarizes the input footage to containingonlythoseframeswithvehiclesinthem.Objects are detected from these frames using the OpenCV and TensorFlowmodules.CNNalgorithmisusedfortheobject classificationintotwo/four wheelers.Theclassifiedobjects arefurtherprocessedtoobtainthelicensenumber.
Imageenhancementnecessitates imageprocessing.Apre processingphaseisperformedbeforetheimagesarefedinto theproposedstructure.Imagesareextractedfromvideosvia OpenCV. The first step is to lower the original image's dimensionalitybydownscalingitfrom512x512x1pixels to 128 x 128 x 1 pixels. This will let the network operate morequicklyandwithlesscomplicatedcalculations.These photos are processed to detect vehicles, resulting in a collectionofimagesthatexclusivelycontainvehicles.These photosaremergedtocreateanewvideothatsolelycontains vehicles.Toenablethealgorithmtotrainonunsorteddata andpreventitfromconcentratingona certainarea ofthe entire dataset, the data isseparated and then shuffled. Training,validation,andtestsetsofdataareeachassigneda unique set of target labels (68%for training and 32%for systemtestandvalidation).Finally,weimprovethemodel's robustnessandreduceoverfittingbyenhancingthephotos to the point where the system recognizes them as brand new. In addition to the geometric augmentation, the photographs are subjected to a grayscale distortion (salt noise).
Algorithm: PROCESS VIDEO (video.mp4): Description: pre processes the actual footage to generate the summarized footage and further processes the frame to generate a textual summary Input: video.mp4 Output: Summarised video
1 If task = “pre_process”, then 1.1 Capture the input video vidcap = cv2.VideoCapture(video) 1.2 Extract the frames from the captured video vidcap.read()
1.3 If a frame is extracted, then 1.3.1 Write the frame to an intermediate directory 1.3.2 Crop the frame to remove the unwanted space using img.crop() 1.3.3 Resize the frame to a specific size using img.resize() so that all frames are uniform 1.3.4 If a vehicle is present in that frame, then I.3.4.1 Copy the frame to the result directory
1.4 Detect the vehicles from the extracted and resized images
1.4.1 if car is detected, then 1.4.1.1 Save the images with the cars in car_images folder
2 Otherwise, if task = “extract”, then
2.1 For each frame with a vehicle in it, do: 2.1.1 Detect and recognize the number plate characters
2.1.2 If length(number_plate) == 10, then
2.1.2.1 Detect the vehicle class (two wheeler/four wheeler)
2.1.2.2 Write the result into a text file
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
3 Generate a video by combining the extracted frames with vehicles in the result directory
The Feature Extraction stage is required because certain featuresmustbeextractedinorderforthemtobeunique. After determining if a vehicle is present, the last frame is examined.Therepresentationsetofhugedataisreducedby using a feature vector. It contains information about the imagefeaturethatisextracted.Featureextractionisnothing buttransformingsuchinputdataintoasetoffeatures.The mainelementsneededforimageclassificationareextracted at this stage. The segmented vehicle image is used, and texturecharacteristicsareextractedfromittoillustratethe image's texture property. We use a pre trained vehicle number plate model in conjunction with the images containingvehicles.
Algorithm: VEHICLE DETECT (image.png):
Description: detects if there is any vehicle in the considered frame, image.png
Input: image.png
Output: image.png gets saved to the output folder “/Result” if a
vehicle is detected
1 Read the image using cv2.imread()
2 Feed the image as input to OpenCV DNN
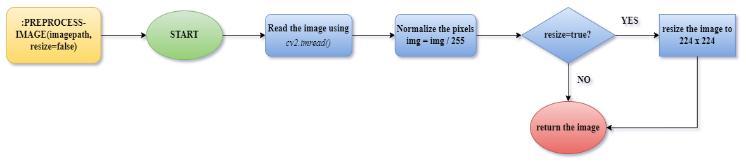
3 Repeat for all the objects detected
3.1 obtain the confidence_score of detection
3.2 if confidence_score > 40%, then
3.2.1 Obtain the id of the detection
3.2.2 Draw a box around the detection
3.2.3 Obtain the label of the detection
3.2.4 if label = ‘car’, then
3.2.4.1 Write the image to the output folder
4 Return the result
Vehicle classification and number plate detection are accomplished using priorly generated features. Deep learning techniques are used to classify vehicles as either four wheelers or two wheelers. The main goal of deep learningalgorithmsistolearnandmakeinformedchoices automatically.Intheproposedmethod,theCNNalgorithmis usedforclassification.
Algorithm: VEHICLE CLASS DETECTION (image.png):
Description: classifies the detected vehicle into a 2 wheeler or a 4 wheeler
Input: image.png.
Output: Classification as a two wheeler or four wheeler
1 Read the image using cv2.imread()
2 Convert the image into a pixel array:
[height x width x channels] image.img_to_array(img)
3 Add a dimension to the pixel array because the model expects the shape: (batch_size, height, width, channels)
4 Import the pre trained Keras CNN model
5 Compute the prediction score using the predict method in keras
6 Classify the object in the image based on the prediction scores for the labels
7 Return the classification label
Algorithm: NUMBER PLATE DETECT (image)
Description: detects the number plate and recognizes the characters on the number plate of the vehicle in image.png
Input: path to image.png
Output: detected number plate of the vehicle in image.png
1 Method: PROCESS IMAGE (image)

1.1 Get the location of the number plate using the method ‘GET PLATE (image)’
1.2 If there exists at least 1 number plate image, then 1.2.1 Convert it to a grayscale image 1.2.2 Apply inverse threshold binary to obtain clear number plate characters using OTSU threshold approach
1.3 Obtain all the boundary points (x,y) of the characters in the number plate
1.4 for each boundary point (x,y), do 1.4.1 obtain x, y, width, height of character 1.4.2 crop the characters based on the ratio (height/width)
1.5 Load the CNN model trained on mobilenet dataset: LOAD MODEL(path)
1.6 Load the class labels for character recognition 1.7 for each character detected, do 1.7.1 char = PREDICT FROM MODEL (character, model, labels)
1.8 Print the detected number plate final_string
Fig-2:GET_PLATEmethod
Fig 3:PREPROCESS_IMAGEmethod
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Chart 1providesagraphicalanalysisofANPRmodule:

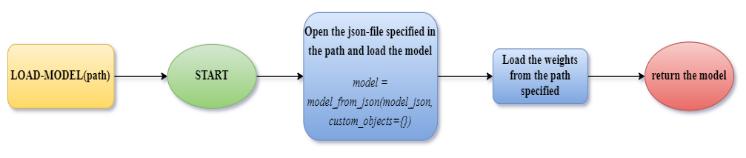
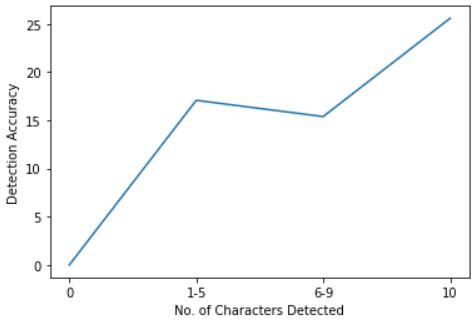
Fig 4:LOAD_MODELmethod
Theaccuracyscorewhen1 5charactersaredetectedis better compared to when 6 9 characters are detected i.e.,theaccuracyhasreduced.Thisisdependentonthe imagequalityandangleofvehicle(numberplate)inthe image.Intheseframes,thenumberplateofthevehicleis notclearlyvisibleduetoitsdistancefromthecamera.
Fig 5:PREDICT_FROM_MODELmethod
Theanalysisofthenumberplatedetectionresultsobtained istabulatedinTable1.Theresultsdependonthefollowing:
Image/framequality Bettertheimagequality,better theresults.Lowerqualityimagesmakeitdifficultto detectthenumberplateregionandalsothecropping ofcharactersisinaccurate.
Whenall10charactersaredetected,theaccuracyscore rises.All10charactersaredetectedwhenentirenumber plateisvisiblei.e.,whenthevehicle(numberplate)is straightandclearlyvisibleintheimage
Obstructions to the number plate region in the image/frame If some object is obstructing the numberplateregion,thentheobstructedpartofthe platewillnotbedetectedaccurately.
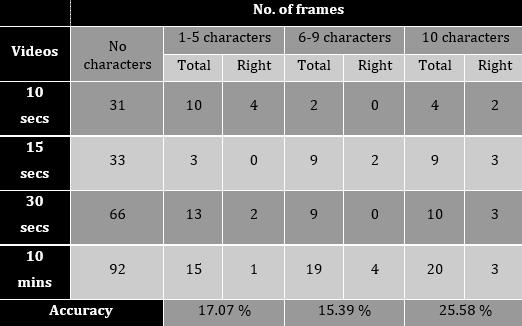
The angle of the vehicle in the image (straight/inclinedangle) Iftheimageisataninclined angleintheframe,thenthedetectionisnotaccurate. A straight view of the image number plate region yieldsbetterresults.
The distance of the vehicle from the camera The closer the detected number plate region to the camera,thebettertheaccuracyofcharacterdetection.
Table 1: TabularanalysisoftheANPRresults
Chart-1:LineGraphanalysisofANPR
Textualdescriptionofvisualcontentlikeimages,particularly videos,isadifficulttask,butanecessarystepforwardinto machine intelligence and many applications in day to day activitiessuchasgeneratingvideosubtitles,downsizingthe contentofalongervideointosmalltexts,etc. Videolabeling is more challenging than image labelingdue to a large numberofobjects,activities,backgrounds,varyingpicture qualities,andotherunwantedinformation.Oneofthemost significantroadblockstotextuallabelingofvideoistheuser perspectives.
The proposed work aims to provide users with a textual summaryofthevehiclesinthesurveillancefootagemaking its review easier. The summary consists of registration number,classificationasatwo wheeler/four wheelerofthe vehiclesdetectedinthefootage
Thisworkcanbefurtherextendedtomultipleviewsofthe area using footages from different CCTV cameras and integratingithumanactivityrecognitiontherebydetecting anyabnormaleventshappening.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
We would like to thank BNM Institute of Technology, Bangalore, Karnataka, India, for the constant support and encouragementforthesuccessfulcompletionofthisproject. We extend our gratitude to the Dept. of ISE, BNMIT, for providing the computing facilities in the “GPGPU Computing for Computationally Complex Problems Laboratory”,whichissupportedby VGST underKFIST L1..
[1] Yubo An, Shenghui Zhao “A Video Summarization Method Using Temporal Interest Detection and Key Frame Prediction”, September 2021, eprint arXiv:2109.12581(arXiv.org)
[2] Choudhary, Vikas, and Anil K. Tiwari. “Surveillance Video Synopsis.” 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, 2008. doi:10.1109/ICVGIP.2008.84
[3] T.Hussain,K.Muhammad,A.Ullah,Z.Cao,S.W.Baikand V. H. C. de Albuquerque, “Cloud Assisted Multiview Video Summarization Using CNN and Bidirectional LSTM,”inIEEETransactionsonIndustrialInformatics, vol. 16, no. 1, pp. 77 86, Jan. 2020, doi: 10.1109/TII.2019.2929228.
[4] Rochan, M., Ye, L., Wang, Y. (2018). Video Summarization Using Fully Convolutional Sequence Networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision ECCV 2018. ECCV 2018.LectureNotesinComputerScience(),vol11216. Springer, Cham. https://doi.org/10.1007/978 3 030 01258 8_22
[5] MadhuraPrakash.,KrishnamurthyG.N.,“DeepLearning Approach for Video to Text Summarization,” in InternationalJournalofInnovativeResearchinScience, EngineeringandTechnology(IJIRSET),vol.10,issue1, Jan.2021.doi:10.15680/IJIRSET.2021.1001032
[6] S. Sah, S. Kulhare, A. Gray, S. Venugopalan, E. Prud'Hommeaux and R. Ptucha, "Semantic Text Summarization of Long Videos," 2017 IEEE Winter ConferenceonApplicationsofComputerVision(WACV), 2017,pp.989 997,doi:10.1109/WACV.2017.115
[7] GaikwadDhirajYeshwant,Samhita Maiti,P.B.Borole, 2014, Automatic Number Plate Recognition System (ANPR System), International Journal Of Engineering Research & Technology (IJERT) Volume 03, Issue 07 (July2014)
[8] Shahid, Umar. (2017). Number Plate Recognition System.10.13140/RG.2.2.23058.71361
[9] G.K. Devipriya, E. Chandana, B. Prathyusha, T. S. Chakravarthy., “Image Classification using CNN and MachineLearning,”inInternationalJournalofScientific Research in Computer Science, Engineering and Information Technology (IJSRCSEIT), vol. 5, issue. 2, 2019.doi:https://doi.org/10.32628/CSEIT195298
[10] Abu,MohdAzlan&Indra,NurulHazirah&AbdRahman, Abdul &Sapiee,Nor&Ahmad,Izanoordina.(2019).A studyonImageClassificationbasedonDeepLearning andTensorflow.12.563 569.
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page140