2345
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072

2345
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
Abstract The novel 32x32 multiplier design using Booth architecture and Vedic architecture is presented in this project. The Booth multiplier, which is the foundation of the Booth architecture, cuts the number of partial products generated in half. Vedic architecture benefits from simultaneous partial product production and adding. The 16x16 Vedic architecture is used to divide the 32x32 multiplicand and multiplier in order to increase the performance of the multiplication. In addition to Vedic design, this new 32x32 signed multiplier also has more benefits than the individual Booth multiplier and Vedic multiplier technique. Compared to a standard 16x16 Booth multiplier, it has a straightforward architecture. This new multiplier makes use of the Carry Select Adder and the Ripple Carry Adder (RCA). CSA to add the product that was partially generated. The performance has increased thanks to the new 32x32 signed multiplier's shorter overall propagation delay. The modern 32x32 multiplier design is more optimized compared to individual ones. This is due to the concurrent usage of Vedic architecture for both the partial product addition and the partial product production by the Booth multiplier. The proposed multiplier is designed usingXilinxISEandXilinxVivado.
Key Words: BOOTH MULTIPLIER, VEDIC MULTIPLIER,POWER,
DELAY, XILINX ISE, XILINX VIVADO.Due to the rapid advancement of technology, demand for quick and effective processor units has surged as a result of digital signal processing (DSP). A processor's performance is primarily dependent on the multiplier's performance. High speed, small size, and low power consumption multipliers are increasingly priorities for highperformanceprocessors.Thedesignofthemultiplier for Very Large Scale Integration (VLSI) architecture faces a critical issue posed by these three key trade off parameters.
The new 32x32 combined Booth and Vedic multiplier is implemented using the Booth multiplier architecture and the Vedic multiplier architecture to enhance the performance of multiplication. The number of partial productsisalmostcutinhalfbythe Boothmultiplier,and
the signed input is divided for quick multiplication in the Vedicarchitecture.
Additionally, the partial product addition is crucial in enhancingamultiplier'sefficiency.
Very large scale integration (VLSI) circuits with low power consumption are essential for creating small deviceswithhighperformanceandenergyefficientdesign. The multiplier is crucial in the design of an energy efficient CPU since it determines the processor's power. Creatinga multiplier thatoperatesmorequicklyandwith lesspowerconsumptionthanearliermultipliermodels.
The 16x16 Booth multiplier and 16x16 Vedic multipliers are combined to create a new efficient 32x32 multiplier. CarryselectadderandRipplecarryaddersareusedinthis design.The energy efficientproposed multiplier isusedin Floating pointmultiplierwhichisanimportantapplication.
One such multiplier that scans the three bits at a time is the Booth multiplier, which lowers the number of partial products. Booth encoding conducts numerous multiplication steps simultaneously to speed up the multiplicationprocess.
The fact that an adder subtractor is almost as quick and compactasabasicadderisexploitedbyBooth'salgorithm. Addition and subtraction operations can be skipped if three consecutive bits are the same. As a result, in the majority of instances, Booth Multiplication's related delay islessthanthatofanArrayMultiplier.
By inspecting three bits at once, the Booth multiplier approach decreases the number of adders and, thus, the time needed to produce the partial sums. The booth multiplier's excellent performance has the drawback of beingpower hungry.Theneedforahighnumberofadder cells,whichusealotofpower,isthecause
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
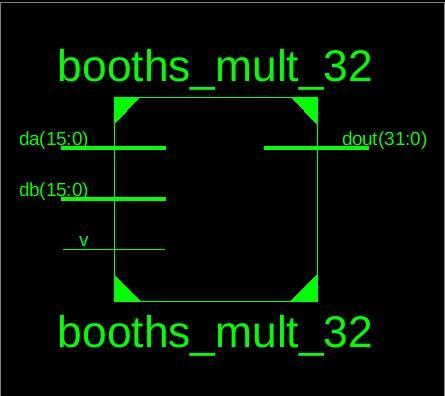
16x16 Booth multiplier is used in this design with 16x16 Vedicmultiplier.
Fig -3:16X16VEDICMULTIPLIER
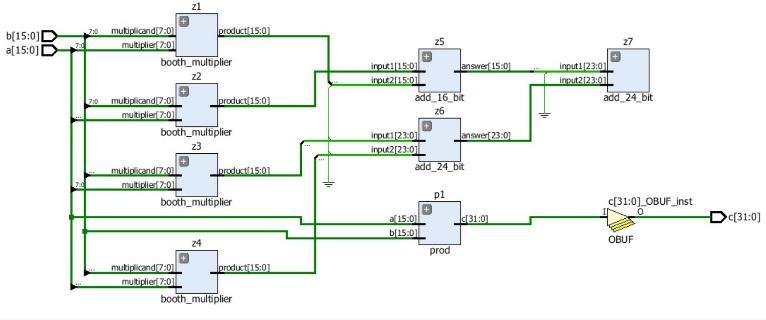
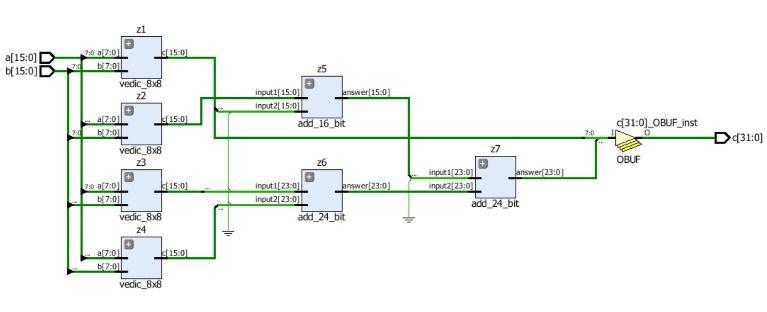
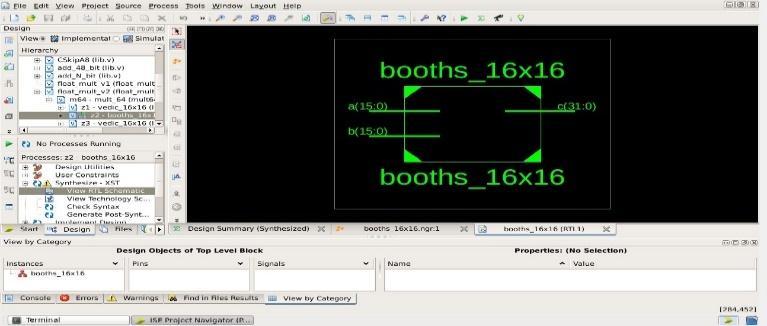
Fig 1:16X16BOOTHMULTIPLIER
Fig 2:16X16BOOTHMULTIPLIERSCHEMATIC
TotalDelay=10.288ns

Vedic mathematics is used because it simplifies complex computations that are typically seen in traditional mathematics. This is true because it is said that the Vedic equationsarefoundedonthesamebasiclawsthatgovern how the human mind functions. Based on the Vedic multiplication formulas(sutra), the Vedic multiplier is designed. The multiplication of two numbers has always been done using this sutra. We will use the same principles in the proposed work to make it compatible withthedigitalhardware.
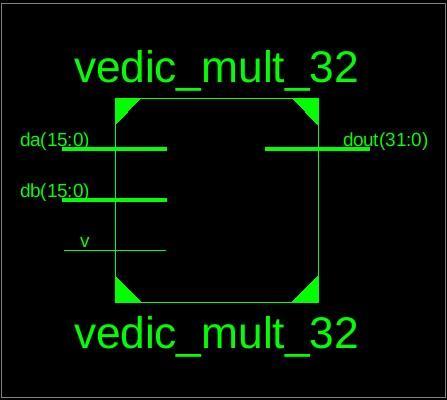
A universal multiplication formula that works in all situations is the Urdhva Tiryakbhyam Sutra. "Vertically and Crosswise" is what it signifies. The two ends of the line'sdigitsaremultiplied,andtheresultingsumisadded to the carry from before. All outcomes are added to the previous carry when there are more lines in a step. The resultant number's least significant digit serves as one of the result digits, with the remaining digits serving as the carry for the following step. The carry is first assumed to bezero.
Fig 4:16X16VEDICMULTIPLIERSCHEMATIC
The new design is designed by combining the Booth architecture and Vedic architecture. The new architecture partition each of the signed value into two block and multiplyusingVedicalgorithm.
The new design uses two 32 bit booth multiplier and two 32 bit Vedic multiplier. 16x16 Booth multiplier is used to multiply the signed value in each block. Figure shows the first design of 32x32 Combined Booth Vedic multiplier architecture.
This design uses the CSA to add up the generated partial products. The 32x32 Combined Booth Vedic multiplier is designedbyusingfour16x 16multipliersandtwo32bits CSAandone64bitCSA.herearefourdifferencecondition forthesignedmultiplicationusingVedicarchitecture.This istheimportantsectiontomakesurethemultiplicationis correct.
Fig 5:32X32COMBINEDMULTIPLIERBLOCKDIAGRAM
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
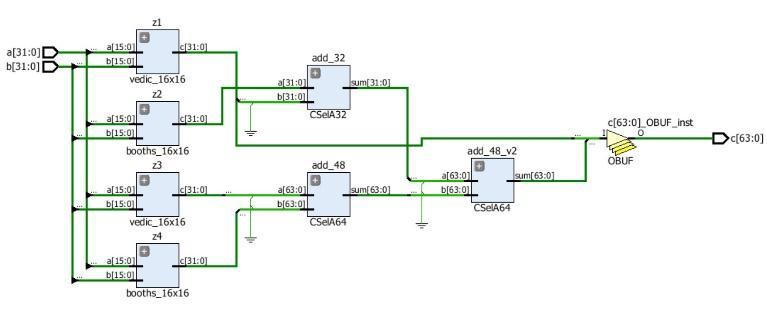
Fig -6:32X32COMBINEDMULTIPLIERDESIGN
Power usage: When computing large and small numbers, the multiplier's architecture requires lesspower.
Workflow speed: A multiplier that is meant to computelargeandsmallnumbersmorequickly.
Themultiplierhasalongerlifespan.
Cost of operation is reduced. This yields to more production.
A floating point technique is an additional or different methodofdescribingthenumber.Computerwords(actual numbers on computers) are displayed in real time using the IEEE 754 floating point format. These days, modern computersrepresentintegersinthismanner.Thismethod can be applied to every type of number, including huge, very large, tiny, and extremely small numbers. This technique offers representation for an infinitely large rangeofnumbers.Bothsignedandunsignednumbersare representedusingthisformat.Theaccuracyandprecision withwhichthenumbersareexpressedinthisexampleare veryhigh.Thisapproachrepresentsthenumberusingthe scientificmethod.
Inrecentyears,floatingpointconversionhasbeenusedby all contemporary computers, laptops, computer graphics, modellingsystems,DSPchips,andsoforth.
The proposed multiplier is used in the floating point multiplier.
FIRfilters
filters
Fixpointmultiplier
DCT,DFT,cosinetransformetc.
Inimageprocessingapplications
InfastFouriertransforms
InALUofmicroprocessor
TheXilinxsoftwareVivadoDesignSuitereplacesXilinxISE with new functionality for system on a chip development and high level synthesis. It is used for the synthesis and analysis of hardware description language (HDL) designs. The design flow has been completely rewritten and rethoughtusingVivado(comparedtoISE).
Similar to later iterations of ISE, Vivado has an integrated logicsimulator.High levelsynthesisisanotherinnovation made by Vivado. It uses a toolchain to transform C code intoprogrammablelogic.
Fig -8: XILINXVIVADOSOFTWAREWORKAREA
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
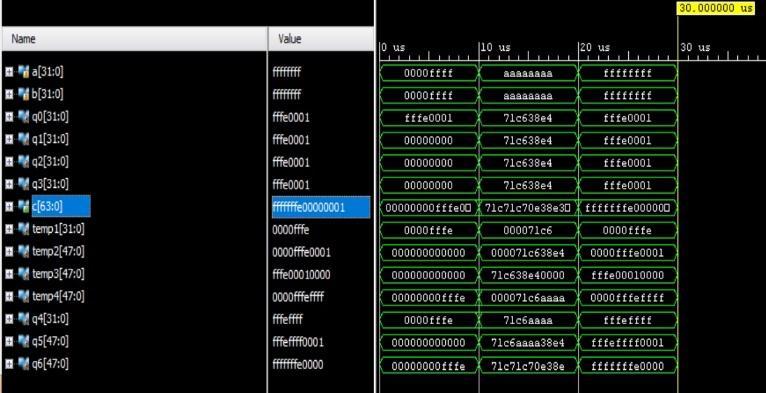
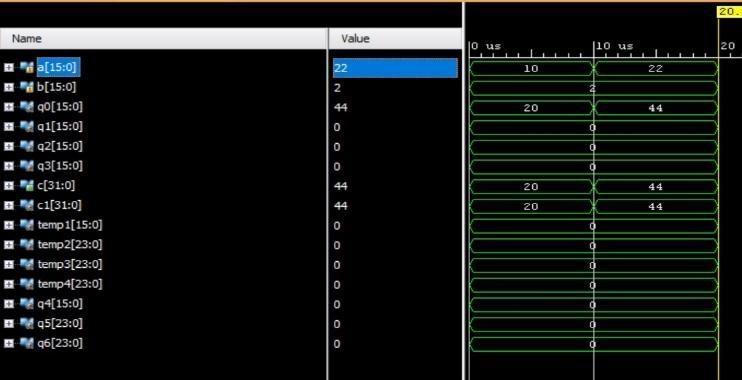
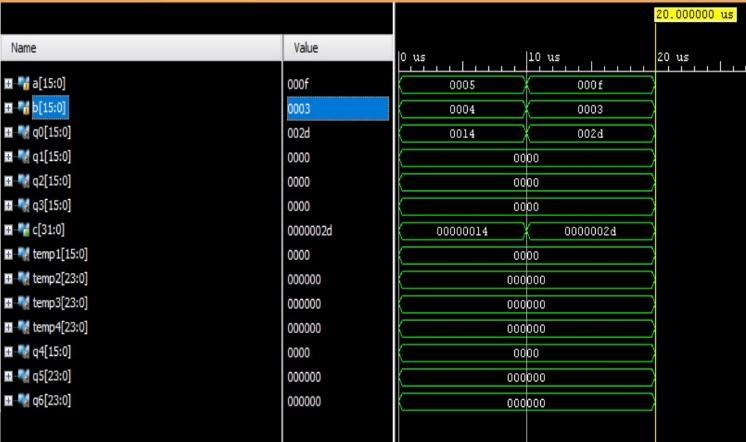
For the synthesis and analysis of HDL designs, Xilinx ISE (Integrated Synthesis Environment) is a discontinued software tool from the company. It was primarily used to generate embedded firmware for the FPGA and CPLD integrated circuit (IC) product lines from Xilinx. Xilinx Vivado succeeded it in the market. For in system programming of legacy hardware designs comprising older FPGAs and CPLDs that would otherwise be left orphaned by the replacement design tool, Vivado Design Suite,themostrecenteditionfromOctober2013isstillin use. ISE gives developers the ability to synthesize (or "compile") their designs, run timing analyses, go at RTL diagrams,simulateadesign'sresponsetovariousstimuli, and work with the programmer to set up the target device. The Software Development Kit (SDK), the Embedded Development Kit (EDK), and other items are alsoincludedwiththeXilinxISE(SDK).
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 07 | July 2022 www.irjet.net p ISSN: 2395 0072
To make things or programs easier to integrate into systems,everyonewantsthemtobelighterthesedays.As a result, new ways will be implemented in the future to makethedevelopeddesignconsiderablysmaller.Thiswill be useful for situations requiring less weight. In a key working condition, the lifespan of the multiplier is very significant,thusinthefuture,therequiredapproacheswill be incorporated into this project and the lifetime of the generatedmultiplierwillbefurtherimproved.
[1] A REVIEW PERFORMANCANALYSIS OF VARIOUS MULTIPLIERS FOR THE DESIGN OF DIGITAL PROCESSORS M. Prasannakumar, Dr. R. Thangavel, International Journal of Modern Electronics and Communication Engineering (IJMECE) ISSN: 2321 2152 VolumeNo. 6,IssueNo. 4,July,2018.
[2] DELAY-POWERPERFORMANCECOMPARISON OF MULTIPLIERS IN VLSI CIRCUIT DESIGN-Summit Vaidya and Deepak Dandekar, International Journal of Computer Networks & Communications (IJCNC), Vol.2, No.4, July 2018
[3] A NEW HIGH SPEED 16X16 VEDIC MULTIPLIER ShauvikPanda,Dr.Alpana Agarwal,International Journal of Scientific & Engineering Research Volume 9, Issue 5, May 2018ISSN2229 5518.
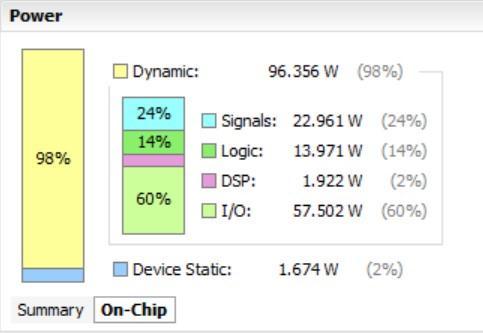
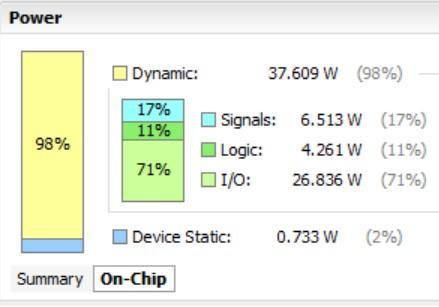
Using Xilinx Vivado and Xilinx ISE software, Booth Vedic multipliershavebeenconceived,designed,simulated,and testedforfunctionalityinthe32x32multiplier.Two16x16 multipliers were created, and their power usage and processing times were compared to those of a 32x32 combined multiplier. These were created in Xilinx Vivado utilizing carry select adders and ripple carry adders. The simulationsarecarriedout using Xilinx and Vivado Tools, andthe schematicsarecreatedusing Xilinx andVivado. It is taken the time summary (Speed) and power summary. The 32x32 combined multiplier uses less energy and operates more quickly. The latency and energy usage barelyincreaseasthenumberofbitsrises.
Energy efficient design is crucial in daily life, and as the number of bits increases, multiplication of numbers will become more and more efficient. With the addition of enhancedmethodologies,theproposedmultiplier'spower andspeedarefurtherdecreasedandraised,respectively.
[4] A COMPARATIVE STUDY ON ADDERS Bhavani Koyada,1N. Meghana,2Md. Omair Jaleel3and Praneet Raj Jeripotula, This full text paper was peer reviewed and accepted to be presented at the IEEE WiSPNET 2017 conference.
[5] FPGA Based Implementation of a Floating Point Multiplier and its Hardware Trojan Models S Nikhila; B Yamuna;KarthiBalasubramanian;DeepakMishra., 10.1109/INDICON47234.2019.9030341.
[6] A. Kumar and S. Kamya, “Design of a High Speed Multiplier by Using Ancient Vedic Mathematics Approach for Digital Arithmetic,” International Journal of Electrical andElectronicsEngineers,vol.8,no.2,pp.244 255,July Dec2016.