International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072


International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Nagareddy Deepthi1 , Tulasi N2 , Mrs Mona3
1Student Dept. of Information Science and Engineering, BNM Institute of Technology, Karnataka, India
2 Student Dept. of Information Science and Engineering, BNM Institute of Technology, Karnataka, India
3Assistant Professor, Dept. of Information Science and Engineering, BNM Institute of Technology, Karnataka. ***
Abstract Movies can be tagged with various details such as genre, plot structure, soundtracks, and visual and emotional experiences etc. This information can be used to build automatic systems to extract similar movies, enhance user experience and improve the recommendations. We describe a way that allowed us to create a fine-tuned set of various tags that expose the varied characteristics of movie plots. T h e correlation between tags is varying which we make a study on different types of movies. By means of this project we will be solving a Multi LabelClassification problem. This system was built to study the inferring tags from plot synopses. We hope it will be usefulinother tasks related to narrative analysis.
Key Words: Plot Synopsis, Machine Learning, Logistic Regression,OneVsRest,SGDClassifieretc
Various features of movies, such as genre, plot structure, soundtracks,andemotionalresponses,visualsandsoon can belabelledBecauseofthemassivevolume of multimedia datageneratedthesedays,it’sdifficultto imaginesystems thatcanautomaticallyanalyzethecontenttodeterminethe validityandclassify them.Manual processing isimportant for extracting needed information from the data and assigningsuitabletags.Asaresult,tagqualityisbasedona subjectivecriterionthatdiffersfrompersontoperson.This generated metadata makes it difficult to gain complete insights intomajorelementsofamovieanddue to lack of precision, there are irregularities and hence data is less accuratewhich could impact user experience. This data may be utilizedtocreateautomatedalgorithmsthatextract related movies, dealing with the growing problem of information overloadandimprovetheuserexperienceand suggestionsaswellasprovideuserswithapreviewofwhat toexpectfromamovie.Thistagpredictionmodelhasvarious applications like object detection, automatic subtitles generation and optimization of movie search engines and mainly in content censorship.
Only a machine learning based algorithm can efficiently completesuchtasks.Here,wewilladdressthisproblemby creatinganautomatedenginethatcanextracttagsfromthe plotofthemoviewhichisadetaileddescriptionofamovie (synopsis of movie story line) or summary of a movie. A movie can have one or more tags this is when multi label
categorization comes into play where each sample is givenasetoftargetlabels. e.g.,classifyinga dataset which may be adventure or action, comedy, horror, flashback. Machine learning’s remarkable breakthroughs have paved theroadfordiscoveringpatternsindatawithhighaccuracy, the completion of tasks with a machine learning based algorithmisthat’swhyefficient.Wedescribeawaythatwill allowustocreateafine tunedsetofvarioustagsthatexpose thevariedcharacteristicsofmovieplots.Afterthiswecheck astohowthesetagsrelatetodifferentsortsoffilms.Wewill use this model to assess if we could somehow infer tags from plot synopsis.
Wefeelthattherehasbeenalowattentiontowardsthetag predictionandcategorizationofmoviesintheliterature.The relevantworkinthissectorismainlyfocusedonsmall scale image,video,blogandothercontent basedtagging.S.Kar,et. al. [1], proposeda model which used plot analysis for tag prediction.Theyproposedanovelneuralnetworkmodelthat merges information from synopsis and emotion flows
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
throughout the plots to predicta set of tags for movies.In orderto create the tag set, they tackled the challenge of extracting tags related to movie plots from noisy and redundant tagspacescreatedbyusercommunitiesinMovie LensandIMDb.
Tagsetandmappingthetagstotheplotsynopsesandalso provided an analysis, to find out the correlations between tags.Thesecorrelationsseemtoportrayareasonablesetof movietypesbasedonwhatweexpectfromcertaintypesof movies in the real world. They also tried to analyze the structure of some plots by tracking the flow of emotions throughoutthesynopses,whereitisobservedthatmovies withsimilartaggroupsseemtohavesimilaritiesintheflow ofemotionsthroughouttheplots.Theycreatedasystemto predicttags from the synopses using a set of hand crafted linguisticfeatures.Foreachmovie,thealgorithmforecasta limitednumberoftags.
Ali Mert Ertugrul, et. al. [2], proposed ‘Movie Genre Classification from plot summaries' system where they performed movie genre classification using Bi directional LSTM. They used sentence level approach. Since plot summariescontainsmanysentences,theyfirstdivide each plot summary into sentences. Then using word representationsofsentences,theytrainedBi LSTMnetworks toestimategenresofeachsentenceseparately.Sincethere aremanysentencesandmanygenres,they used majority voting forthefinaldecisionbyconsideringtheprobabilities of genres assigned to sentences. The results reflect that, trainingBi LSTMnetworkafterdividingtheplotsummaries intotheirsentencesandfusingthepredictionsforindividual sentencesoutperformtrainingthenetworkwiththewhole plotsummarieswiththelimitedamountofdata.
Antonius Christiyanto Saputra, et. al. [3], proposed the ‘Classification of the Movie Genre based on Synopsis of the Indonesian Film’ system that aims to classify a document content into the correct label. Synopsis text data in Indonesian films is used as a features to determine the appropriate genre of film by utilizing machine learning algorithms. They used document level approach. The text classificationsystemaimstoclassifyadocumentcontentinto thecorrectlabel.Theyhaveusedseveralfeatureextraction methodsandmachinelearningmodelstoclassifythemovie genre. Their model gavethe best results with the Support Vector Machines classification algorithm with TF IDF extraction. There arestill shortcomings and errors in the resultsoftheclassificationofthefilmgenrewhenconducting summarysynopsisinputduetothelackofthedatasets.
JingchengWang.et.al[4],ProposedtheIdentificationofMovie genresthroughonlinemoviesynopses’systemthataimsto identify the genres of movie through movie synopses. The movies and corresponding synopses in database are downloadedfromtheKaggleandrottentomatoeswebsites. Inthissystemaccessingusefulinformationfromonlinemovie synopsis can be time consuming, misunderstanding and
misjudge the genre of the movie. In this system two supervised learning models KNN and SVM and two deep learningmodelsCNNandRNNareusedtoclassifythegenres ofmoviethroughmoviesynopses.SVMorKNNcanbeused whenthe number of samples intrainingsetislimited,but SVM is always better. Sample data of the training set increases, the training speed of SVM or KNN increases rapidly,andtheimprovementofaccuracyisless,soitisnot applicabletotheactualsituation.CNNandRNNwithLSTM layer in deep learning are used which are more suitable toact as a text analysts for hugedata. In this system RNN withLSTMlayeristhebestmodeloverall.
Darren Kuo,et,al.[5],proposed the ‘On word prediction methods’ This system represents a simple task of word prediction given a piece of text. This system includes clustering of documents, querying for related documents, similarityofdocuments,andcapturingthe topicsgiven aset ofdocuments.Thismodelusedaco occurrenceapproachto generate tags based on the words in the post and their relationship to tags. The model wascreated fornext word predictioninbigdatasetsandthenmodifiedbylimitingthe predicted next word to just tags. This co occurrence algorithm correctly predicts one tag per post with a classification accuracy of around 40 percent. The system emphasize on predicting words, which are mixtures of topics.
GiladMishne,et,al.[6],proposedthe‘Autotag:Acollaborative approachtoautomatedtagassignmentforweblogposts’The systemdescribesautotag,
A tool which suggests tags for weblog posts using collaborative filtering methods. autotag is used for simplifying the tagging process and in improving quality. autotagidentifiestagsforapostbyexaminingtagsassigned to similar posts. autotag was used to tag 6000 of the taggedposts. In addition tothecollaborativeapproachthe investigationoflocalapproachtotagsuggestionrequired.
Teh Chao Ying, Shyamala Doraisamy, Lili Nurliyana Abdullah,et,al.[7], proposed the ‘Classification of Lyrics based genre’. The system aim is to improve the performance of lyrics based musical genre classification. Music documents are often classified based on genre and mood. The features from lyrics text are used for classification of musical documents and the feasibility of lyrics features to classify musical documents. From the analysis of the lyrics text in the data collection, correlationoftermsbetweengenreandmoodwasobserved. In this system term frequency and inverse document frequencyvaluesareusedtomeasurerelevance of words to thedifferentmoodcategories.Thetf idfweightingscheme forlyricstextwasusedtodescribetherelativeimportanceof atermforaparticularmusicalmoodclass. In thissystem datasetsizeislimitedwhichwas145 songs with lyrics and in fact genre and mood provide complementary descriptionsofmusic.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
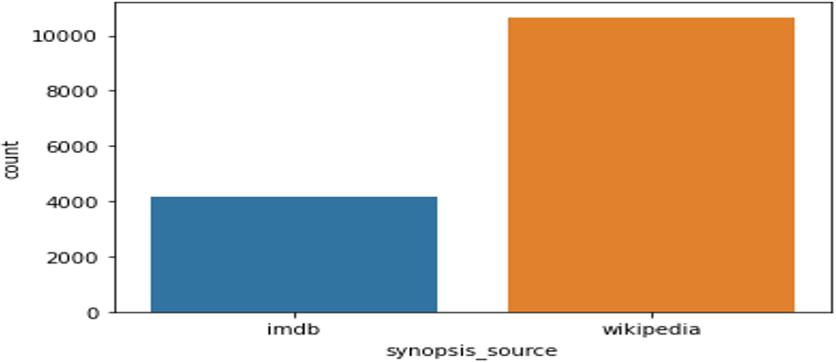
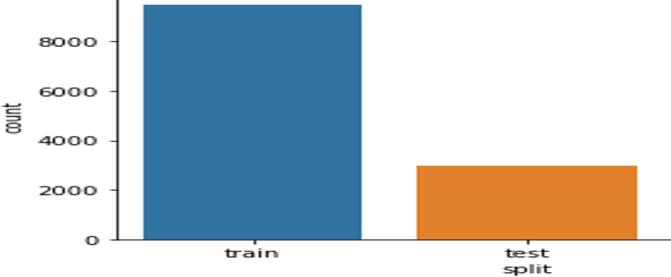
Therearevariousdatasetsavailablethatcontainmovies andtheirplots,butourmainconcernistoretrieveadataset with certain expected attributes, such as tags should be closely related to the plot and not some metadata that is completely irrelevant to the plot, and redundancy in tags should beavoidedbecauseweneedto assign unique tags, so havingtagsthatrepresentthesame meaning would be ineffective.So,wehavegathereddatafromvariousinternet sourcesthatcontainsnearly14,000movieswithuniquetag set of 72 tags. here, each data point has six attributes including IMDB idtogetthetag association information for respective moviesinthedataset,Titleofthemovie,Plot ofthemovie,Tagsassociatedwitheachmovie,Splitattribute indicatingwhetherthedatabelongstotest,ortrainsetand sourcewhichiseitherIMDB or Wikipedia.
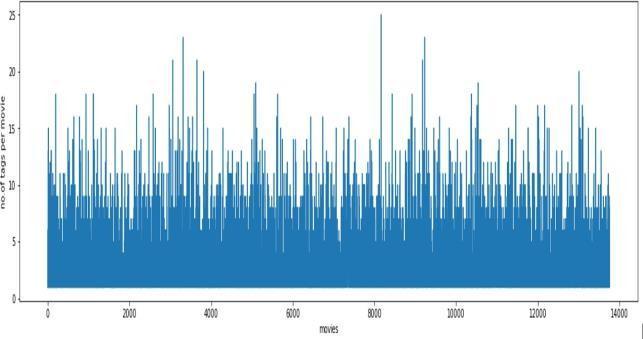
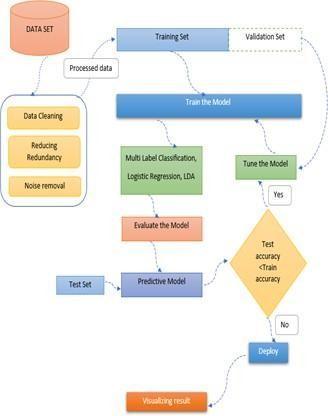
Fig 3: Flowdiagram1
TAGANALYSIS:
Fig 4:Movievsnumber.oftags permovie
Moreover, Plot synopses should not contain any noise suchasHTML tags or IMDB alerts and include sufficient information because understanding stories from extremely short texts would be challenging for any machinelearningsystem,eachoverviewshouldincludeat least10sentences.Althoughthetextisunstructureddata,
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
it is often created by individuals for the purpose of being understoodby others.So,howcanwehandleabigvolumeof textandconvertitintoarepresentationthatcanbeusedto predictandclassifyusingmachinelearningmodels?There areavarietyofmethodsforcleaningandpreparingtextual data, and weused a few ofthem here.
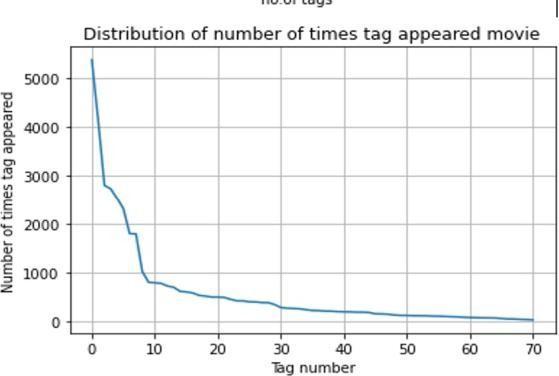
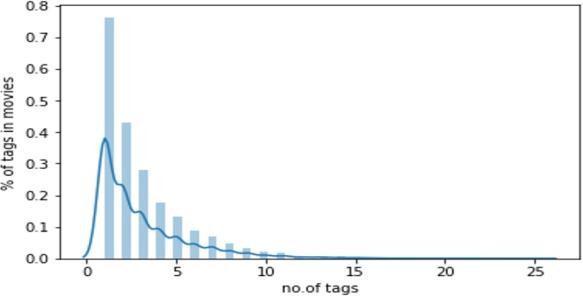
Fig 5:percentage oftagsinmoves vsno.oftags
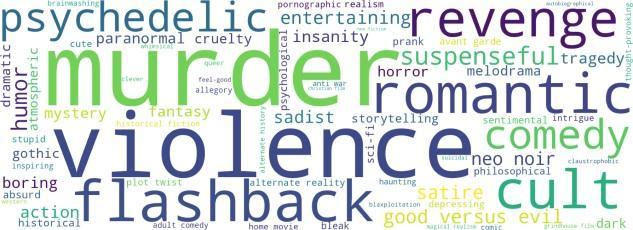
wecreatedaSQLdatabase file of the given source CSVfileanddeletetheduplicateentriesandmodifythesame by adding a new custom attribute (6+1) tag count which indicatesthenumberoftagsassociatedpermovieso,wecan findtheexactcount,howmanymoviesareassociatedwith how many tags. we also checked the number of unique tags present inthe dataset using the BOW (bag of words) technique whichisimplementedusingthecountvectorizer method.Wemusttransformitintovectorsofnumberssince machinelearning algorithmsdonotaccepttherawtextas inputdata.BagofwordsistheeasiestwaytorepresentText Documents. In other words, it will determine how many times a specific wordappears in a given document. This method yielded a tag cloud such as flashback, violence, murder, romantic and cult. This way we produced a more genericversionofthecommontagsrelevanttotheplotofthe movie. On the other hand, tags such as entertaining, and suspensefulareslightlylesscommongotfiltered out.
In this part, we’ll go through some basic tests we’ve done using thecorpus to predict movie tags. Using all tags:
• Convertingeverywordtolowercaseandremoving HTMLtags or other irrelevant elements present in thedataset.
• De Contraction of words like can’t to can not and remov inganystop wordsif presentsuchas“the”, “a”,“an”,“in”aswewouldnotwantthesetermsto take important processing time or space in our database.
• Lemmatization of words, which typically refers to per forming things correctly with the help of a vocabularyandreturningawordtoitsrootform,for instance,convertingwordsthatarein3rdpersonto 1st person and future and past tense verbs to present tense.
• Stemming refers to reducing words to their word stemthataffixestoprefixesandsuffixeslike“ ing”,“ es”,“ pre”, etc.
Exploratoryanalysisfordataoftags datadistribution andfeature engineering.
TFIDF Vectorizer Here, less frequent words are assigned comparatively more weight. TFIDF is the product of Term Frequency (the ratio of the number of times a word appearsin a document to the total number of terms in the document)andInverseDocumentFrequency(thelogofthe numberoftimesatermappearsinadocument)(thetotal numberofdocumentstodocumentswithtermpresentinit). We tested several approaches in the baseline model constructionportion,includingthemultinomialNaiveBayes classifier, which is good fordiscrete feature classification, such aswordcountsfortextcategorizationinadocument. Integerfeaturecountsaretypicallyrequiredformultinomial distributions, making them robust and simple to build, While Logistic Regression is used when the dependent variable (target)iscategorical,andthequestionarisesWhy Linear Regression is not used for classification? Two things explain this. The first one is that classification problems mandate discrete values whereas linear regression only dealswithcontinuousvalueswhichmakesitnotsuitablefor classification.Thesecondthingisthethresholdvalueforthis consideringasituationwhereweneedtodeterminewhether anemailisspamornot.Ifweuselinearregressionhere,we’ll need to select a threshold by whichwemayclassifythe data.Ifthe actual class is malignantwithapredictedvalue of0.45,and thethreshold is0.5,thenitwillbeclassifiedas non malignant,whichcanresultinseriousconsequencesin real time. So, it can be seen that linear regression is unbounded that’s why we need logistic regression for instance,inabinaryclassificationwhere we need topredict if a data point belongs to a particular classor notandthe class with the highest probability is wherethedata point belongs.So,tofitamathematicalequationof suchtypewe
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
cannotuseastraightlineasallthevaluesofoutputwillbe either 0 or 1. That’s when sigmoid function comes into picturethattransformsanyrealnumberinput,toanumber between 0and 1.
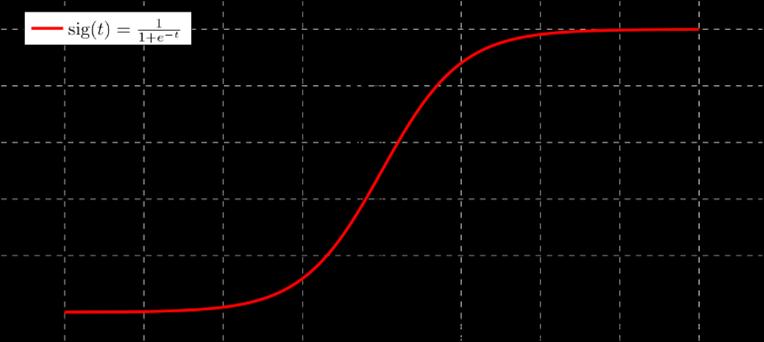
Sigmoid equation:
S(x)=1/1+e^ x
Fig-7:Sigmoidfunction
Hypothesis => Z = WX + Bh(x) = sigmoid(Z)
(2)
Here if Z becomes close to infinity, Y will become 1 andifZisclosetonegativeinfinity,Ywillbepredictedas 0.
Sigmoid equation formultiplefeatures:
Here,wearecomputingoutputprobabilitiesforall K 1classes.ForKthclass=1 Sumofallprobabilitiesofk 1 classes.
So,wecansaythatmultinomiallogistic regression usesK 1Logisticregressionmodelstoclassifydatapointsfor Kdistinct classes.
Anothermethod that we tried is SGD classifiers whichisanoptimizationmethod,whileLogisticRegressionis amachinelearningmodelthatdefinesalossfunction,andthe optimization method minimizes/maximizes it.
In all the cases our goal is to maximize the micro averagedF1score.Weusedmicro averagingashere,amovie might have more than two tags/labels associated with it. Microaveraged F1score is the harmonic mean of micro Recallandmicro Precision.Micro precisionisthesumofall true positives to the sum of all true positives and false positives.
TP 1+ TP 2+ TP 3+ Microprecision =
(TP 1+ TP 2+ TP 3+ . . . )+(FP 1+ FP 2+ FP 3+ . . . )
Micro recall is calculated by first finding the sum ofall truepositivesandfalsepositives,overalltheclasses.Then we compute the recall for the sums.
TP 1+ TP 2+ TP 3+ micro recall =(TP 1+ TP 2+ TP 3+ . . . )+(FN 1+ FN 2+ FN 3+ . . . )
Logistic Regression with Outliers was the model that provided us the highest micro averaged F1 score. One Vs Rest, sometimes known as one vs all, is a method that involvesfitting a single classifier to each class. The class is fittedagainstalltheotherclassesforeachclassifier.Despite thefactthatthistechniquecannothandlemultipledatasets,it trainsfewerclassifiers,makingitafasterandmorepopular option.
Bycapturingsemanticinformation,wordembeddings have been proved to be successful in text classification problems.Asa result, we average the word vectors of each word intheplottocapturethesemanticrepresentationof the plots. Thus, we get a 1D vector of features correspondingto eachdocument.Byusingthismodelalso logistic regression gave thehighest micro averaged F1 score.
According to the exploratory data analysis, a movie is typically associated with three tags. As a result, we attemptedtocreateamodelthatcouldpredictthetopthree tags.Weutilisedthesamesetoffeaturesthistime,butthe numberoftagswassettothree.ByusingTFIDFVectorizer thehighestF1scorewasachievedbyusingSGDClassifier withloglossaswellasaccuracyscoreisalsoimprovingand byusingAVGW2V(averageword2vec)LogisticRegression model gave the highest F1 score. Similarly, for the next trainingofourmodel,wehavesetthetagstothetop5and observedthe
F1 score for each model. We read the dataset and vectorizethetagsusingtheBoWalgorithminthe following trainingsteptoseewhichwordappearshowmanytimes. Then,toconstructanewdataframe,wesortedthesetagsin decreasing order depending on how many times they appearedinthedocument.Outofthe71distincttags,we manuallychosethetop30tagsbasedontheirfrequency. Then, except for the 30 tags present per movie, we eliminated all other tags alongwiththeirrespectiverows andrepeatedtheproceduretotrainthemodelfurther.For thenextstage,weemployedPython’sTopicModellingand LatentDirichletAllocation(LDA).
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
WeusedLatentDirichlet Allocation (LDA) to classify text in a document toa specific topic. Topic Modelling is a statistical model for discovering the abstract ”topics” presentinacollectionofdocuments,andit is acommonly utilized forthediscoveryof hidden semantic meaningful structures in the body of text.It generates a topic per documentandwordpertopicmodelbasedontheDirichlet distribution.(LDA)isacommontopicmodellingapproach withgreatPythonimplementationsintheGensimpackage. The LDA model above is made up of ten separate topics, eachofwhichismadeupofseveralkeywordsandgivena specificamountofweighttothesubjectthatrepresentthe importance of a keyword to the particular topic. It determinesthedominantsubjectofaparticulartextandis one of the practical applications of topic modelling.
To accomplish so,wesearch forthetopicwith thehighest percentagecontribution.Thenwesaved these dominating topicstoaCSVfileandconcatenateditwithouroriginaldata andusedthesamemethodtotrainthemodelevenfurtherto improve accuracy
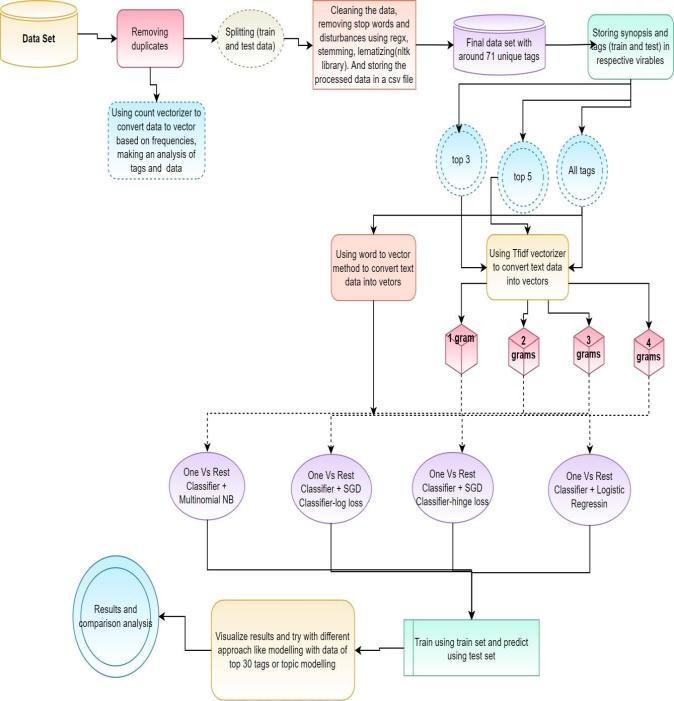
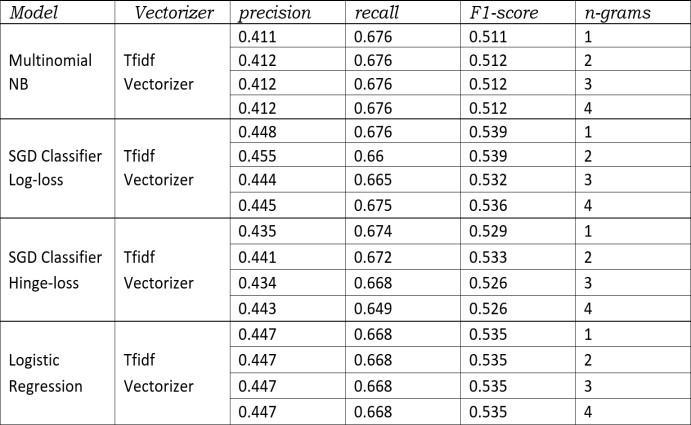
TosolvethisMultiLabelclassificationproblemweusedOne VSRestClassifiercombiningwithdifferenttypes ofbinary classificationalgorithms.Firsttimewetookdatacontaining all tags (complete pre processed data set). To make the model understand the plot synopsis we trained the model withdifferentwordcountslike1grams,2grams,3gramsetc. HerefirstlyTfidfVectorizerisusedtoconvertthesynopsis data into numeric data. After that we tried to train the model with OneVS Rest classifier Multinomial NB, SGD Classifier log loss, SGD Classifier hinge loss and logistic regressionwith1grams(initially)andthesameprocessis repeatedwith2,3,4grams.Ouraimhereistomaximizethe f1score.
Fig-8: DataFlowdiagram2
IncaseofMultinomialNBthescoredecreasedfrom1to 2gramsandstayedsamethrough2,3,4grams.Andwhenit comestoSGD Classifier log loss itdecreased from 1 to 2 to3andincreasedin4grams(andthisisthemax).SGD Classifier hingelossincreasedgraduallyandhighestisat4 grams. And now comes the logistic regression it’s score increased from 1 to 2 grams and remained unchanged later and logistic regression showed highest scores in individual models of 1, 2, 3, 4 grams and also in the overall case (andit is 0.26). And on a overview 4 grams model gave the better results when compared with the rest.Figure ”fig 9”.
Fig 9:Top3 Tag Prediction
Now to improve the model even further we try to implementthis procedure with top3 and 5 tags as we saw in analysisofdata,wetakemaximumfeaturesas3and
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
5intheserespectivetrainings.Andfollowtheabovethatwe havedonewith data with all tags.
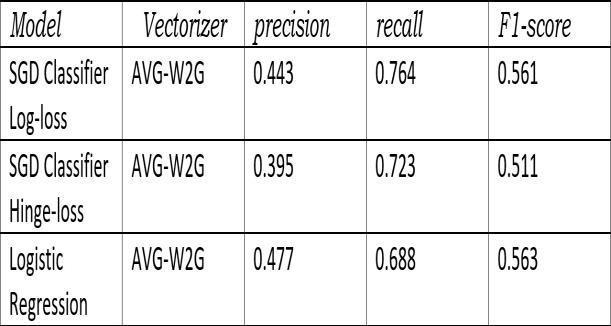
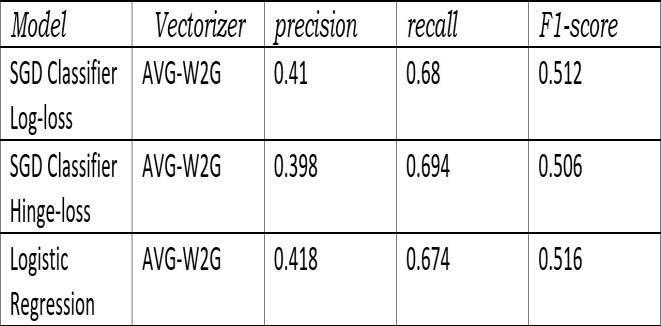
Wealsotriedtousewordtovectorasitconvertsthedata intomoremeaningfulsensecomparedtoTfidf.”fig12”,”fig 13”,”fig 14”
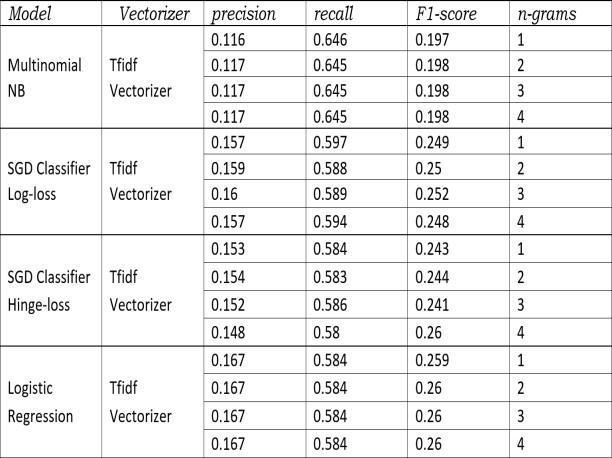
MultinomialNBstaysthesamein all variants. The f1of SGD Classifier log loss increases from 1 to 2 grams and decreases from 3 to 4 grams (but still ¿ 1gram). SGD Classifier hingelossdoesn’tshowmuchvariationandlogistic regressionalsostaysthesameinallcases.ButthistimeSGD Classifier loglossshowshighestscore(ofallvariants)incase of2grams,thatis0.568.Here2gramsperformanceisbetter compared to the rest.”fig 10”
Let’s go a step further and try to predict top 5 tags ”Fig
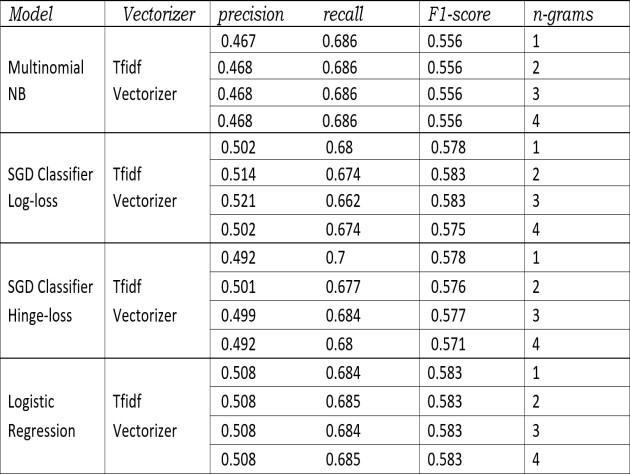
11. The f1 score of Multinomial NB it increases from 1to2gramsandremainsunaltered.SDGClassifier logloss f1 decreasesin3and4gramswhereasequalin1and2grams. SDGClassifier hingelossincreasesthescoregraduallyinall grams.Logistic Regressionshows samescores withall 12 34 grams. But here also logistic regression is the highest f1score achiever and the score is 0.535.”fig 11” Now let’s compareamongthesemodelswhichtrytopredict all,top5 and 3 tags. We can clearly see the significant increase in scoresoff1intopthreeandfivetagprediction compared to alltags.Andtop3modelisshowingthebestresultsamong these.
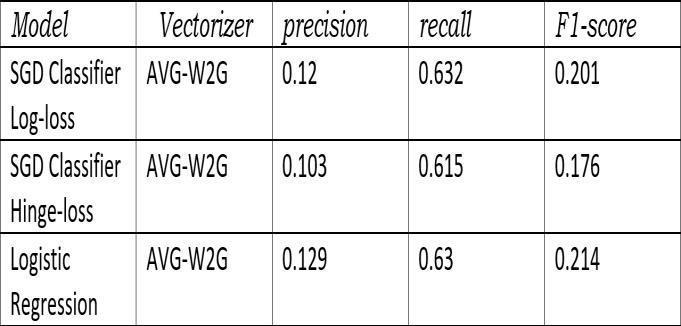
Fig 12:All Tag Prediction w2v
Fig 13:Top3 Tag Prediction w2v
Andperformedtheoperationsjustasaboveforall,5and threetagpredictions,wealsoappliedthisforthedataset containningtop30tagsandgotthefollowingf1scoresas follows.
All tagprediction Logisticregression(gavehighestscore thatis 0.214)
Top 3 Logistic Regression (gave highest score that is 0.563)Top5 LogisticRegression(gavehighestscorethat is0.516)Top 30 data tags Logistic Regression (gave highest scorethat is 0.32)
Asyoucanseethisfollowedthe same trend like whenwe used Tfidf. And Logistic Regression gave the best model outcomesincaseofbothvectorizers.Alsotop3 prediction gave some what satisfying results in both. We also used Topic modelling (which finds the topics with in our synopsis) and LDA (latent dirichlet allocation) model to Implement this. Here also Logistic regression gave the highest result (0.366).
HeretheapproachthatwehavestatedutilisesOne Vs Rest classifier to solve the problem as a multi label (classification).A set of people [22] Khalid Haseeb, Najm us Sama, MiguelA ´ Mart ´ Inez Del Amor, Adnan Ahmed, Umair Ali Khan,
Fig 14:Top5 Tag Prediction w2v
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
SalehM.Altowaijri,NaveedIslamandAtiqUrRehmanwho belongstovariousfieldsandbranchesofComputerScience workedonthesameproblem(movie tagprediction)witha differentapproach.Thesimilarthingbetweenusiswe both feltthatthisfield(predictingtagsformovies)received less attentionoveryears.Theytriedtopredictthetagsusingseg mentation of movies (movie frames) and CNN (Convolutional Neural Network).Wepreparedatagsetof 71 tags( based on mostly used or occurring tags) and this team on the otherhand prepared a tag set of 50 tags (dataset with combined information of each tag with 700 imagesandpreparedadatasetwith semantic information).
We tried combinations (two algorithms) of different classifyingalgorithmslikeLogisticregression,Multinomial NB,GCDwithOneVsrestclassifiertotrainourmodelusing N grams(to geta semantic sense) andVectorizers (Count, TFIDF,Word
to Vec),theyusedInceptionV3 pretrainedmodel(CNN) and modified the final layers of classification in the sense with Soft max classification for pridictions (transfer learning)
Inourcasewetriedtopredictbasedontheplotsynopsis and tried to gather the feel of plot and predicted tags accordingly.Butthisteamusedsegmentationtoachievethis. Inthisprocesstheyusevideosofthemovieanddivideit into differentframesandgatherasingleslidefromtheframeand trytopredict3tagsforthisslideandtheycombineallthe frames information and select top thre tags having higher weights or probabilities (dominant). They also designed a algorithm for boundary and key frame detection and extraction.Inourcasewetriedtoclassifyourproblemasa multilabelmodelandtrieddifferentcombinationofOne vs rest classifier(which classifiesthe model considering one feature to rest all the features)and other multiclass classificationalgorithmsandtriedwithn gramapproachand used different type of vectorizers to get meaningful numerical data.
Ourhighestf1 scoreisadecent0.583andtheyhaveareally efficientscoreof0.88astheirhighest.Boththeseareintop threetagpredictions.Sothereisstillaimprovementscope when compared with other variant models.
Wedescribedawaythatallowedustocreateafine tuned set ofvarioustagsthatexposethevariedcharacteristicsofmovie plots.Wetookonthetaskofextractingtagsrelatingtomovie plotsfromnoisyandrepetitivetagspaceswhichneededtobe pre processed. We present an analysis where we tried to predict movie tags from plot synopsis. The highest micro averagedF1scorethatweobtainedfromtheentireproject is 0.583. As, we observed in the EDA section that on an averageamoviecontains3tags.So,wtriedtotrainourmodel
value:
multipletimes and each time we set the tags to different values liketop3andtop5andwealsoselectedthetop30 tagsmanuallytoanalyzeourmodeltoagreaterextentandwe alsousedvarioussemanticsvectorizationssuchasLDA(Latent Dirichlet Allocation) and word2vec to improve our model. Although we had a small dataset, we still got a decent F1 score.BymeansofthisprojectwearesolvingaMulti Label Classificationproblem.Wehopeitwillbeusefulinothertasks relatedtonarrativeanalysis.
[1] SudipaKar,SurajMaharjan,A.PastorLopez Monroyand YhamarSolorio,23Feb2018,”Predictingtagsformoviesfrom plotsynopsisusingemotionflowencodedneuralnetwork”In 2018internationalconferenceonsemanticcomputing.IEEE.
[2] Ali Mert Ertugrul, Pinar Karagoz,2018,”Movie genre classification from plot summaries using Bidirectional LSTM”.In 2018 12th international conference on semantic computing.IEEE.
[3]Antonius Christiyanto Saputra,Anjelina Br Sitepu,Stanley,Yohanes Sigit Purnomo W.P,2019,” The Classification oftheMovie Genre based on Synopsisof the Indonesian Film”. In 2019 international conference on semanticcomputing.IEEE.
[4] Jingcheng Wang ,2020,” Using machine learning to identify movie genres through online movie synopsis”. In 20202ndinternationalconferenceoninformationtechnology andcomputerapplication.IEEE.
[5] Darren Kuo,December 16,2011,” On Word Prediction Methods”. In 2011 international conference on semantic computing.IEEE.
[6] Weblog Posts,Gilad Mishne,May 23,2006,” AutoTag: A Collaborative Approach to Automated Tag Assignment for Weblog Posts”. In 2006 World wide web conference committee.IEEE.
[7]Teh Chao Ying, Shyamala Doraisamy, Lili Nurliyana Abdullah,2015,” Lyrics Based Genre Classification Using Variant tf idf Weighting Schemes”. Journal of Applied Sciences,15:289 294.IEEE.