International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Abstract In the present situation, Riding motorcycle without wearing helmet is a traffic violation which has increased in the number of accidents and deaths in India. The existing system monitors the traffic violations primarily through CCTV recordings, where the traffic police have to look into the frame where the traffic violation is happening, zoom into the license plate in case the rider is not wearing a helmet. But this requires a lot of manpower and time. What if a system automatically looks for a traffic violation of not wearing a helmet while riding a motorcycle? If so, would automatically extract the vehicles' license plate number. Recent research has successfully done this work based on CNN, R CNN, LBP, HoG, HaaR features, etc. But these works are limited concerning efficiency, accuracy, or the speed with which object detection and classification is done. In this research work, a Non Helmet Rider detection system is built which attempts to satisfy the automation of detecting the traffic violation of not wearing a helmet and extracting the vehicles' license plate number. The main principle involved is Object Detection using Deep Learning at three levels. The objects detected are person, motorcycle at first level using YOLOv2, helmet at a secondlevel using YOLOv3, License plate at the last level using YOLOv2. Then the car place license number is extracted using OCR (Optical Character Recognition). All these techniques are subjected to predefined conditions and constraints, especially the car place number extraction part. Since this work takes video as its input, the speed of execution is crucial. A holistic system is built for both helmet detection and license plate number extraction.
developersfortheconstructionsites.JingHuetal.2019used theYOLOv3modeltoprocessreal timevideofeedanddetect apersonwearingahelmetornotatconstructionsites.The worker is recognized using YOLOv3 and the samples are made. These samples go through the YOLOv3 model to detectiftheyarewearinghelmetsornot.Themodelgives 93.5 mAP and 35fps. Further, Fan Wu et al. proposed an improvementtotheYOLOv3algorithmbyusingthefeature extractionmethod.Theyusedthefeatureextractionmethod as the backbone of the YOLOv3 model. This improvement gavetheincreaseddetectionrateof2.44%.
Words: YOLOv3, OCR, OpenCV, Deep learning, Helmet detection
Withtheadvancementoftechnology,therapidconstruction ofhigh qualityroadsisnoweasier.Theavailabilityofbetter roadconnectionsleadstoanincreaseinthenumberofroad vehiclesrequiredtoensurethesafetyofroadusers.Safety rulesandregulationsmustbecarefullymonitoredtoreduce road accidents. Road accidents involving two wheels are severelydamagedandthechancesofsurvivalforthepeople involvedintheseaccidentsareverylow.Thereareseveral methodsusedtomonitortherulesandsafetyofroadusers; someofwhicharetheimproveduseofComputerVision.
Toavoidaccidentsoftwo wheelersontheroad,theremust be real timedetectiontocheck thattherideris wearinga helmet or not. Such a type of problem was addressed by
Nowadays,usuallymanyaccidentsoccur.Manyofthemare duetonotfollowingsomebasictrafficrules.Peoplemayride good but the other person may not. So, we must be safe during traveling from place to place. Mainly Motorcycle riders must wear a helmet. As we know there is a huge impact on image tuning and image detection. There are manywaystodetectmanythings.StartingfromOpenCVto YOLO V5, we have several techniques to perform object detection.So,wecameupwiththeideaofdetectingNumber Plateswhodon'twearhelmetsusingYolo v4.1.3.Objective oftheProjectThisprojectproposesamethodtoautomate thedetectionoftrafficviolatorsandtorecognizetheriders notwearinghelmetsusingtheCNN basedalgorithmYOLOv3 whichisafastsingle stageobjectdetectionalgorithm.Itis basedondarknetarchitectureandtrainedontheMSCOCO dataset capable of detecting 80 classes of objects which includepersons,motorcycles,bicycles,cars,trafficlights,etc. This algorithm is used to find the two wheeler riders in a frame.Peoplearedetectedandcheckediftheyareonatwo wheeler.Thecroppedboundingboxofthedetectionisthen passedontothenextphase.Thisisanimageclassifierbased on the LeNet architecture trained to classify an image to have a helmet or not. If a rider is not wearing the helmet, then the instance is returned and displayed in a different colorthanthehelmet wearingriders.
Efficient and accurate object detection has been an important topic in the advancement of computer vision systems. Withtheadventof deeplearningtechniques,the accuracyofobjectdetectionhasincreaseddrastically.The projectaimstoincorporatestate of the arttechniquesfor object detection to achieve high accuracy with real time performance.ThemainaimofHelmetDetectionistoextract
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
thenumberplateswhodon’twearhelmetsandchargethem afine.
TheImageisdividedintoSxSgridcells.Eachgridcellhasn anchorboxeswithitscenterinthegridcell.ThevalueofS canbeanyintegerbutthemostcommongridcellvaluesare 13x13asshowninFig.1and19x19forlargerimageswith manyobjectstobedetected
probability that the detected object belongs to a specific class.Tomakethefinalpredictionweuseathresholdvalue. Iftheclassconfidenceoftheboundingboxisgreaterthan thethresholdthenthat box isselected.Classconfidence = confidencescorexconditionalclassprobabilityInfewcases, Iftheobjectislargeandmultiplegridcellspredictthatthe object’s center is present in them, we get multiple over lappingboundingboxes.Tosolvethisproblem,weuseNon MaxSuppressionalgorithm.Weselecttheboundingboxwith thehighestclassconfidenceandwechecktheIoUofthatbox withtheoverlappingboxes.Weuseathresholdandifthe IoUisgreaterthanthethresholdweremovetheNon Max boundingboxintheimage.

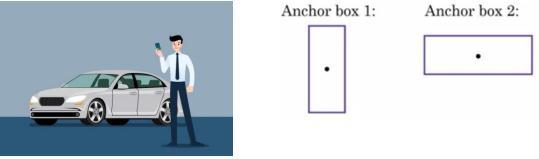
Eachanchorboxofeachgridcellcanpredictoneobjecti.e., foramodelwhichtakesSxSgridcellsandnanchorboxes.It can predict S*S*n objects in an image. The anchor boxes predicttheobjectsintheimagewhichhavesimilarratiosas them.Forexample,wehave2objectsinanimage(fig2)a person and a car. Here the anchor box 1 will predict the person as it is in similar ratio and the anchor box 2 will predictthecarintheimage
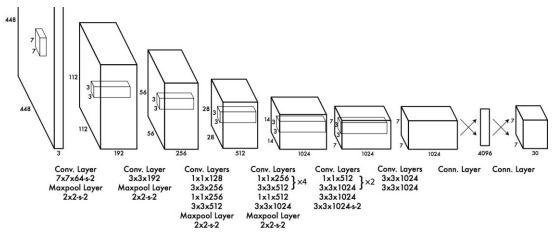
YOLOusesmultipleConvolutionallayersfollowedbyfully connected layers. The output of the last layer has (S, S, B*(5+C)) dimensions. The architecture in the above Fig. 3 uses 7 x 7 grid cells and 2 anchor boxes per cell with 10 classes
YOLO predicts many bounding boxes per grid cell. To compute the loss for the true positive, we only select the boundingboxwhichisresponsiblefortheobjectdetection. WeselecttheboxwiththehighestIoUwiththeobject.YOLO usessquarederrorbetweenthepredictionsandtheground truthtocalculateloss.Theloss functioncomposesof:The classificationloss:Thisfixestheerrorinclassificationofthe object. The localization loss: This fixes the position of the boundingbox.Theconfidenceloss:Improvestheconfidence aboutthedetectionofanobject
Eachboundingboxhas5+Coutputvalues.The5valuesare (x,y,w,h,confidencescore).Thex,yaretheco ordinatesof thecenteroftheboundingbox.w,harethewidthandheight of the bounding boxes and confidence score is the value whichtellshowconfidentthemodelisthatthereisanobject inthatboundingbox.Cisthenumberofclasses.TheCvalues are the conditional class probabilities of the box. It is the
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
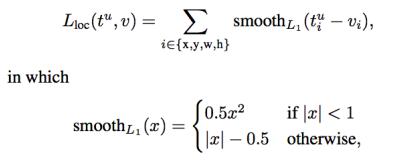
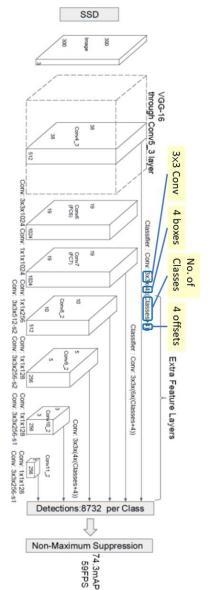
Tohavemoreaccuratedetection,differentlayersoffeature maps are also going through a small 3×3 convolution for objectdetectionasshowninthebelowFig.4
Thelossfunctionisthecombinationofclassificationlossand regressionloss.TheregressionlossusedhereisSmooth L1 loss,whichisthesameasFasterRCNNandFastRCNN.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
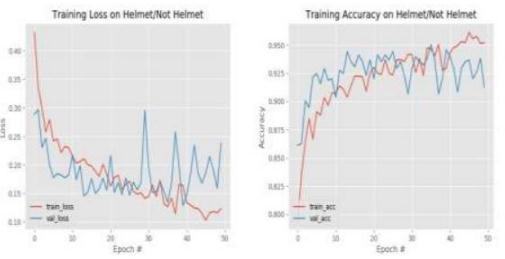
Nowyouhaveyourcompletetrainingdata.Thereisonlyone stepstillmissing:dataaugmentation.Itcanhelpalgorithm learntheinvarianceofdata.Infact,dataaugmentationplays anessentialroleinSSD.
TheworkhasbeendevelopedusingYOLOv3andclassified basedonLeNetarchitecture.Fig.5.1showstheblockdiagram fortheproposedsystem.First,weapplytheobjectdetection algorithm YOLOv3 to obtain the two wheeler riders. The boundingboxesobtainedcontainalltheobjectsdetectedin theimagebelongingtothe80classesoftheMSCOCOdataset anditfiltersonlytheclassesofpersonsandlargevehicles. Theseboundingboxesarethencroppedfromtheimageand forwardedtotheimageclassificationalgorithm.Theimage classifier uses the LeNet architecture and is trained to recognizethehelmetsfromnon helmets.
Thefirststepistopre processtheinputimages.Inthis,first steptheinputimageistakenthroughthesystemfromthe consolewithattributeandextractedtheimagedimensions.In thecaseofvideos,thevideoframesaretakenasanimagefor pre processing.ThenitisforwardedtotheYOLOmodelfor the next process. This is done by creating a blob (Binary Large Object) constructed from the input image. This is followed by non maxima suppression with subtraction, normalizing, and channel swapping. After the successful creationoftheblob,aforwardpass throughYOLOmodelis performed. This is an important step used to remove redundantboundingboxes.Thisisaresultofdetectingthe sameobject multiple timeswithvaryingconfidencelevels. Hence for accurate detection, non maxima suppression is required.
YOLOv3algorithmdetectsallobjectsintheMSCOCOdataset. However, themodel requires onlythe persons ridingtwo wheelers. For this, large vehicles such as cars, buses, and trucksaredetectedandstored.Themodelthenfiltersallthe personsdetected.Itthenensuresthepersonsarenotinthese large vehicles by checking the center coordinates of the person with the bounding box of the large vehicle. The croppedimagesofthepersonsfoundarethenforwardedto theimageclassifier.
Theobtainedimagecontainsthetwo wheelerrider.Thenext stepistofind,therideriswearinga helmetornot.Thisis doneusinganimageclassifiertrainedtoclassifyhelmetsand nonhelmetobjects.TheclassifierusestheLeNetarchitecture. Thisarchitectureperformswellforlowresolutionandsmall images as it was originally meant to classify handwritten letters. This model trained to classify helmets showed an accuracyof95.2%.Theinputfortheclassifieristhecropped image. It detects the presence or absence of a helmet and returnsthelabelfound.Iftheriderisnotwearingahelmet theboundingboxfortheriderintheimageorvideoisshown inadifferentcolor.
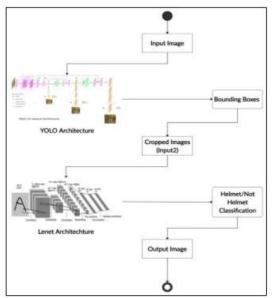
Fig. 5: BlockDiagramoftheArchitecture
To perform this, we trained a set of 1000 images of registrationplates.Thelosswasgoodattheend(0.01).But theproblemasNumberplatesisverysmallinthebigframe therecognitionoftheseplatesisnotthataccurateandhere, wecomewiththedrawbackoftheproject.Wewereunableto detect most of the number plates. This work will be continued.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Fig. 7: Losschartofhelmetplatedetection
TheoutputofcustomYOLOisthedataoftheboundingboxes andtheonehotencodedarrayofclasslabels(assailantand hostage).Theboundingboxdataobtainedfromthemodelis used to draw the boxes on the images and display the probabilityscoresusingOpencv3.

Fig. 9: Testingimageofhelmet 1
In order to calculate the map scores, we used 70 testing imagesandmapscorecameouttobe48%.


It has not totally failed but it was predicting for some test imagesandsomeoftheworkingandnon workingtestcases:
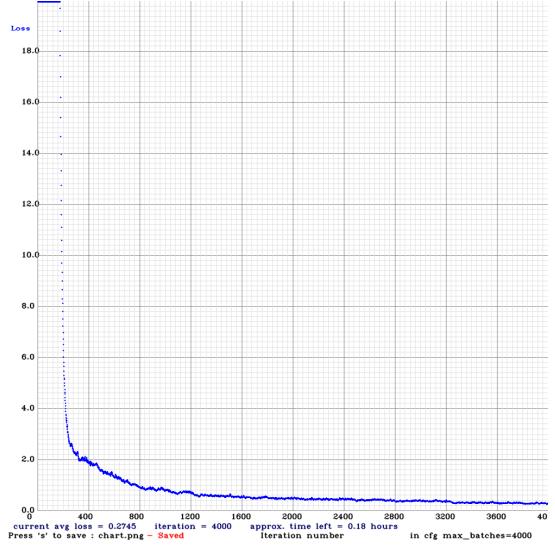
Fig. 8: Testingimageofhelmet 1
Fig. 10: TestingforRegistrationplate 1
We first started the whole thing by using a CNN classifier whichjustclassifiesthem.Asexpected,thatgaveaverybad resultandwecan’tusevideosinthattypeofdetection.Then next we tried it using MobileNetSSD that was giving a partially good result but it was very slow and not a GPU based.Finally,whenwestartedwithYOLO,wecametoknow thatitismuchfasterthanmanyofthedetectors.Initially,the helmetsweredetectableliketheywillbeinagoodsizeinthe framesotheywereperforminggood.Butasmentionedthere isaslightproblemwithYOLOwhiledetectingnumberplates.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Thereweresomeincorrectpredictionsforhelmettoowhich wasresolvedtotallybysettingthresholdto0.7.Helmetswere good but the problem is totally with registration plates as theyareverysmalltodetectinalargeframe.
SSD has better performance than YOLO in all 3 cases i.e., small,mediumandlargeimages.Butwhenonlyfewlabels areavailableyoloperformedmuchfaster.
TrainingtheobjectdetectionalgorithmtoworkonVehicle registration plates and Helmets. The model can further be trained by using Pose estimation which helps us in taking careofacasewherethepersonisactuallyridingabikeor not.Wecanalsogetthetotalnumberplatecharactersintoa text form by using OCR (Optical Character Recognition) whichistheelectronicormechanicalconversionofimagesof typed, handwritten or printed text into machine encoded text, whether from a scanned document, a photo of a document,ascene photoorfromsubtitletextsuperimposed onanimage.
[1] JosephRedmon;AliFarhadi,“YOLO9000:Better,Faster, Stronger”, 2017 IEEE Conference on Computer Vision andPatternRecognition(CVPR)
[2] JosephRedmon,AliFarhadi,”YOLOv3:AnIncremental Improvement”,2018
[3] https://towardsdatascience.com/yolo you only look once
[4] IRJET V8I4235.pdf MaskandHelmetDetectioninTwo WheelersusingYOLOv3andCannyEdgeDetection
[5] A.Adam,E.Rivlin,I.Shimshoni,andD.Reinitz,“Robust real time unusual event detection using multiple fixedlocationmonitors,”IEEETransactionsonPattern Analysis and Machine Intelligence, vol. 30, no. 3, pp. 555 560,March2008.
[6] C. Y.Wen,S. H.Chiu,J. J.Liaw,andC. P.Lu,“Thesafety helmetdetectionforatm’ssurveillancesystemviathe modified hough transform,” in IEEE 37th Annual International Carnahan Conference on Security Technology.,2003,pp.364 369.
[7] C. C. Chiu, M. Y. Ku, and H. T. Chen, “Motorcycle detection and tracking system with occlusion segmentation,”inWIAMIS’07,USA,2007
[8] A. Hirota, N. H. Tiep, L. Van Khanh, and N. Oka, ClassifyingHelmetedandNon helmetedMotorcyclists. Cham:SpringerInternationalPublishing,2017,pp.81 86.
[9] Z. Y. Wang,Design and Implementation of Detection SystemofWarningHelmetsBasedonIntelligentVideo Surveillance, Beijing University of Posts and Telecommunications,Beijing,China,2018.
[10] A.H.M.Rubaiyat,T.T.Toma,M.Kalantari Khandaniet al.,“Automaticdetectionofhelmetusesforconstruction safety,” inProceedings of the 2016 IEEE ACM International Conference on Web Intelligence Workshops(WIW),ACM,Omaha,NE,USA,October2016
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal