International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Kendre1 , Vivek Parit2 , Asazad Pathan3, Akash Kamble4 , Prof. T.V. Deokar5
1,2,3,4 Students, Department of Computer Science & Engineering, Sanjeevan Engineering and Technology Institute Panhala (Maharashtra)
5 Assistant Professor, Department of Computer Science & Engineering, Sanjeevan Engineering and Technology Institute Panhala (Maharashtra) ***
Abstract – Purpose of This study is to know the enhancements in speech recognition field From starting of the 21st century people are working and researching in the area of voice recognition. Researchers have contributed many things in this area. Normal speech without any noise is easy to understand by computers, but if the speech includes noise, then it is very difficult to understand by computer and separate the noise from the speech. There are various reasons to have noise in speech like background noise, environmental noise, signal noise, crowded places, etc. In this paper, we are going to present various techniques to enhance the speech recognition system to work in any environment by researchers. Also, some advanced enhancements in speech recognition to use this system in other situations like emotion recognition.
Key Words: Robust Speech Recognition, Artificial Intelligence, Feature Extraction, Noise Reduction, Deep Learning.
The technique through which a computer (or anothersortofmachine)recognizesspokenwordsisknown asspeechrecognition.Essentially,itisconversingwithyour computer and having it accurately recognize your words. Simply, it means talking to the computer and having it correctlyrecognizewhatyouaresaying.
Voice is the most common and fastest mode of communication,andeachhumanvoicehasadistinctquality thatdistinguishesitfromtheothers.Asaresult,notonlyfor humansbutalsoforautomatedmachines,voicerecognition isrequiredforeasyandnaturalinteraction[12].
Speechrecognitionhasapplicationsinavarietyof sectors,includingmedicine,engineering,andbusiness.The general problemwithspeechrecognitionisspeakingrate, gender,age,andtheenvironmentinwhichthediscussionis takingplace,andthesecondissueisspeechnoise[12].Ifwe can solve these issues with speech recognition, it will be mucheasiertocreategoodsorsystemsthatpeoplecanuse everywhere, even in crowded areas or in noisy environments.
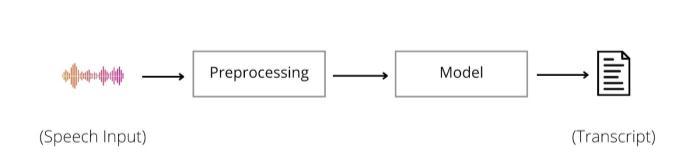
Therefore,itisnecessarytoremoveorreducethe amount of noise in a speech to do effective recognition of speech or voice. And to reduce or remove the noise from speechwehavetoknowthebasicsofrecognition.Thebasic model of speech recognition or speech to text model is showninfigure1.Figure1depictsthebasicmodelofspeech recognition,alsoknownasthespeech to textparadigm.
A human voice is captured or recorded using a microphoneandsoundcardconnectedtothecomputeras speech input. Modern sound cards can record audio at samplingratesrangingfrom16kHzto48kHz,withbitrates rangingfrom8to16bitspersample,andplaybackspeedsof upto96kHz[12].
Signal processing takes place in this step. This process convertsananalogsignaltoadigitalsignalanddoesnoise reduction,aswellaschangesaudiofrequenciestomakeit machine ready[12][13].
Thenextstepinpre processingistochoosewhich featureswillbevaluableandwhichwillbeunnecessary.We need to understand MFCCs (Mel Frequency Cepstral Coefficients)inordertoextractfeatures.
MFCCs is a method for extracting features from audiosignals.Itdividestheaudiosignal'sfrequencybands using the MEL scale, then extracts coefficients from each frequency band to create a frequency separation. The DiscreteCosineTransformisusedbyMFCCtoconductthis operation. The MEL scale is based on human sound
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
perception,orhowthebrainanalysesaudioimpulsesand distinguishesbetweendifferentfrequencies.
Stevens,Volkmann,andNewmannproposedapitch in1937thatgavebirthtotheMELscale.It'sascaleofaudio signalswithvaryingpitchlevelsthatpeoplejudgebasedon theirdistancesbeingequal.It'sascalethat'sbasedonhow peopleperceivethings.Forexample,ifweheartwosound sourcesthatarefarapart,ourbrainwillbeabletodetermine thedistancebetweenthemwithouthavingtoseethem.This scaleisbasedonhowwehumansuseoursenseofhearingto determinethedistancebetweenaudiosignals.Thedistances on this scale increase with frequency because human perceptionisnon linear.
This MEL scale is used to separate the frequency bands in audio, after which it extracts the needed informationforrecognition.
Classificationmodelsaremostlyusedinthemodel sectiontorecognizeorsearchforwordsdetectedinaudio.It isnowsimple to recognize speech using neural networks, andemployingneuralnetworksforspeechrecognitionhas proventobequitebeneficial.Forspeechrecognition,RNNs (Recurrent Neural Networks) are commonly used. Speech recognition can also be done without the use of neural networks,althoughitwillbelessaccurate.
Belowaresomemodelsusedforspeechrecognition, likerecurrentneuralnetwork,HiddenMarkovModeletc.
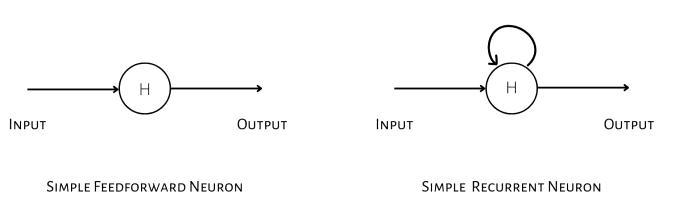
Recurrent Neural Networks are a type of neural network that is used mostly in NLP. RNNs are a type of neural network that uses past outputs as inputs while maintaininghiddenstates.RNNfeaturesamemorynotion thatpreservesalldataaboutwhatwascalculateduptothat timestep.RNNsarereferredtoasrecurrentbecausetheydo thesametaskforeachcombinationofinputs,withtheresult dependent on past calculations. Fig 2 shows the simple illustrationofrecurrentnetwork[15]
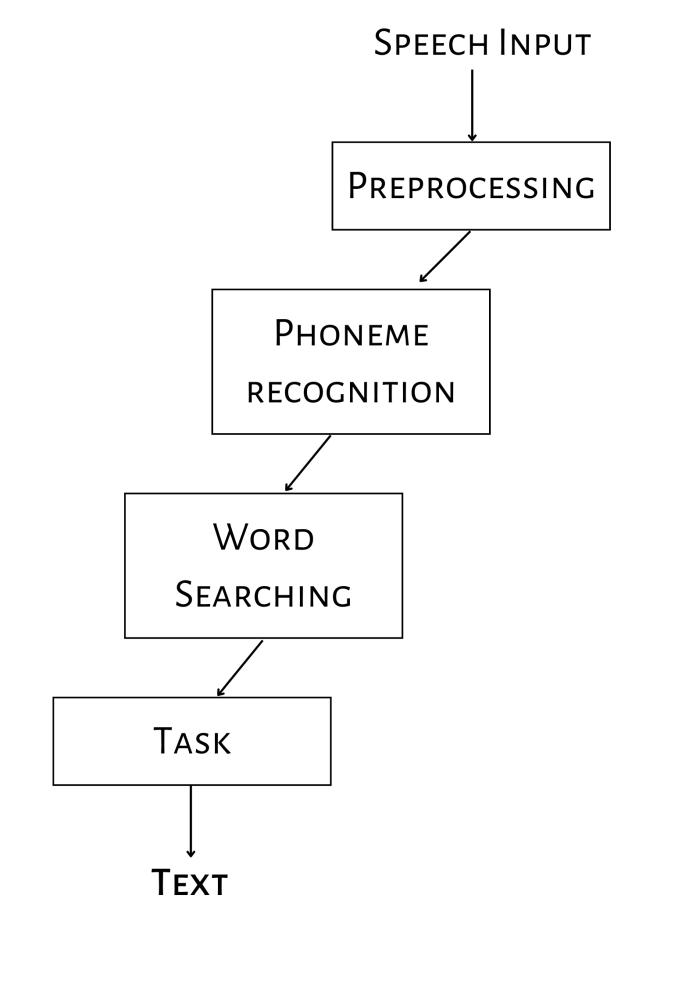
When any person speaks, basically it creates the vibrations.Toconvertthisspeechintotextcomputeruses several complex steps. First it converts our analog speech signalsintodigitalsignals.Thenitdoespre processonthat signal, like it removes non needed part from signals, it removesnoiseanddofeatureextraction.That is,itselects required features from signals and pass it to the Hidden Markov Model, now HMM do the search for word in Database.Thenafterwordsearchingitsenttotheusers[14]
Fig 3 shows the simple architecture of Hidden MarkovModelforSpeechRecognition.
Recurrentneuralnetworkisusedforvoiceclassificationin speechrecognition.Also,itisusedforlanguagetranslation.
Thetranscriptisthetextobtainedaftertheuser's audiohasbeenconvertedtotext.TheSpeechtoTextmethod isthenamegiventothisprocedure.Thetranscriptisthen sentintoatext to speechmodelorsystem,whichallowsthe computertospeak.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
"Audrey,"asystembuiltbyBellLaboratoriesinthe 1950s, was the first authorized example of our contemporary speech recognition technology. However, audreytakesafullroomtobesetupandcanonlyidentify9 numbersutteredbyitsinventorwith90%accuracy.Itsgoal was to assist toll operators in taking more telephone call overtheline,butitshighpriceandinabilitytodetectawide rangeofvoicesrendereditunfeasible.
The next innovation was IBM's Shoebox, which debutedattheWorld'sFairin1962,tooknearly12yearsto buildandwasabletodetectanddiscriminatebetween16 words. However, person had to pause and talk slowly to ensurethatthesystempickeduponwhattheyweresaying.
Then,TheDefencedepartmentbegantoappreciate thesignificanceofvoicerecognitiontechnologyintheearly 1970s. The capacity of a computer to interpret genuine human language might be extremely useful in a variety of militaryandnationaldefenceapplications.
As a result, they invested five years on DARPA's Speech Understanding Research programme, one of the largest initiatives of its sort in speech recognition history. One of the most notable discoveries to emerge from this researcheffortwas"Harpy,"asystemcapableofrecognising over1000words.
Speechrecognitionsystemsweresocommoninthe late1970sandearly1980sthattheyfoundtheirwayinto children'stoys.TheSpeak&Spell,whichusedavoicechip, wascreatedin1978toassistkidsspellwords.Thevoicechip includedthereinwouldprovetobeasignificantinstrument for the next stage of speech recognition software development.
Thenthe"Julie"dollwasreleasedin1987.Juliewas capable to answer to a person and identify between speaker'svoicesinanamazing(ifnotdisturbing)exhibition.
Then after Three years AT&T was experimenting withover the phonevoicerecognitiontechnologiestohelp answercustomersupportcalls
Then Dragon launched "Naturally Speaking" in 1997,whichallowednaturalvoicetobeinterpretedwithout theneedofpauses.
Andafterthatmuchinnovationsandresearchinthis fieldtodaywehavedigitalassistantslikeGoogleAssistant, Alexa, Siri, Cortana which can process natural speech withoutpausesandcanrecognizethousandsofwordsinany language.
Many researchers have worked on various techniquestoenhancethespeechrecognitionsysteminany environment.Givenenhancementsinvariouspapersproved helpfulinspeechrecognitionsystems.
JisiZhanget.al.[1],haveexploredAframeworkfor trainingamonoauralneuralaugmentationmodelforrobust voice recognition. To train the model, they used unpaired speech data and noisy speech data. They conducted trials usinganend to endacousticmodelandfoundthattheWER was lowered by 16 to 20%. In the real development and evaluation sets, using a more powerful hybrid acoustic model,theprocessedspeechreducedWERby28%and39%, accordingly,whencomparedtotheunprocessedsignal.
XuankaiChanget.al.[2],enhancedtheend to end ASR (Automatic Speech Recognition) model for powerful voicerecognition.Whencomparingtheirsuggestedmodelto atraditionalend to endASRmodel,wecanseethattheirs incorporates a speech augmentation module and a self supervised learning representation module. The voice enhancement module improves the sound quality of loud speech.Theself supervisedlearningrepresentationmodule, ontheotherhand,performsthefeatureextractionandpicks usefulfeaturesforvoicerecognition.
Developingaspeechrecognitionsystemthatworks in noisy surroundings necessitates a vast amount of data, includingnoisyspeechandtranscripts,totrainthesystem, yetsuchlargedataisnotreadilyavailable.ChenChenetal. havesuggestedagenerativeadversarialnetworktorecreate a noisy spectrum from a clean spectrum with only 10 minutesofin domainnoisyvoicedataaslabels.They'vealso proposeda dual pathspeechrecognitionmethodtoboost thesystem'srobustness in noisysituations. The proposed techniqueimprovestheabsoluteWERonthedual pathASR system by 7.3% to the best baseline, according to the experimentaldata[3].
SurekhaReddyBandelaet.al.[4],havepresenteda strategy that combines unsupervised feature selection in combination with INTERSPEECH 2010 paralinguistic characteristics, Gammatone Cepstral Coefficients (GTCC), and Power Normalized Cepstral Coefficients (PNCC) to improvespeechrecognitionforemotionrecognition.Inboth cleanandnoisysituations,theproposedsystemistested.For de noisingthenoisyvoicesignal,theyadoptedadenseNon
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Negative Matrix Factorization (denseNMF) approach. For Speech Emotion Recognition analysis, they employed the EMO DBandIEMOCAPdatabases.Theywereabletoachieve anaccuracyof85%usingtheEMO DBdatabaseand77% usingtheIEMOCAPdatabase.Withcross corpusanalysis,the proposed system can be improved for language independence[4].
BecausetheEnglishlanguagehastheadvantageof huge datasets in speech recognition, everyone loves it for speech recognition systems. Speech recognition in the Englishlanguageisasimpletaskthankstobigdatasetsanda widecommunity.Asaresult,ZhaojuanSongetal.[5],chose English Speech as their study topic and created a deep learningspeechrecognitionmethodthatincorporatesboth speechfeaturesandspeechattributes.Theyusedthedeep neuralnetworksupervisedlearningapproachtoextractthe high level qualities of the voice and train the GMM HMM ANNmodelwithadditionalspeechfeatures.Theyalsouseda speechattributeextractorbasedonadeepneuralnetwork trained for several speech attributes, with the retrieved featuresbeingcategorizedintophonemes.
Then, using a neural network based on the linear featurefusiontechnique,speechcharacteristicsandspeech attributes are integrated into the same CNN framework, considerablyimprovingtheperformanceoftheEnglishvoice recognitionsystem[5].
A.I.Alhamada,etal.al[6],havelookedintoprevious workanddiscoveredasuitabledeeplearningarchitecture. Toimprovetheperformanceofspeechrecognitionsystems, theyusedaconvolutionalneuralnetwork.Theydiscovered that a CNN based approach had a validated accuracy of 94.3%.
Gueorgui Pironkov, et.al. [7]. presented a new technique named Hybrid Task learning. This method is based on a mix of Multi Task and Single Task learning architectures, resulting in a dynamic hybrid system that switchesbetweensingleandmulti tasklearningdepending onthetypeofinputfeature.Thishybridtasklearningsystem is especially well suited to robust automatic speech recognitioninsituationswheretherearetwotypesofdata available:realnoiseanddatarecordedinreal lifeconditions, andsimulateddataobtainedbyartificiallyaddingnoiseto cleanspeechrecordedinnoiselessconditions[7]
As a result of Hybrid Task Learning, ASR performanceonactualandsimulateddatabeatsMulti Task Learning and Single Task Learning, with Hybrid Task
Learningbringinguptoa4.4%relativeimprovementover SingleTaskLearning.ThisHybridTaskLearningtechnique canbetestedondifferentdatasetsinthefuture[7].
An audio visual speech recognition system is believedto beoneof themostpromisingtechnologies for robustvoicerecognitioninanoisyenvironment.Asaresult, PanZhouetal.[9]proposedamultimodalattention based approachforaudio visualspeechrecognition,whichcould automatically learn the merged representation from both modes depending on their importance. The suggested method achieves a 36% relative improvement and beats previous feature concatenation based AVSR systems, according to experimental results. This strategy can be testedwithalargerAVSRdatasetinthefuture[9].
Hearing impaired persons would benefit greatly fromartificialintelligence;approximately466millionpeople worldwidesufferfromhearingloss.Studentswhoaredeaf orhard ofhearing depend onlip readingto grasp what is beingsaid.However,hearing impairedstudentsencounter otherhurdles,includingashortageofskilledsignlanguage facilitatorsandtheexpensivecostofassistivetechnology.As aresult,LAshokKumaretal.[8],proposedanapproachfor visualspeechrecognitionbuiltoncutting edgedeeplearning methodsTheymergedtheresultsofaudioandvisual.They also suggested a novel audio visual speech recognition algorithm based ondeeplearningfor efficientlipreading. TheyreducedtheworderrorrateintheAutomaticSpeech Recognitionsystemtoabout6.59%andestablishedalip readingmodelaccuracyofnearly95%usingthismodel.In thefuture,aBERT basedlanguagemodelcouldimprovethe suggestedmodel'sWordErrorRate[8]
The goal of Deep Neural Network based voice enhancement is to reduce the mean square error among improvedspeechandacleanreference.Asaresult,Yih Liang Shenetal.[10]suggestedareinforcementlearningapproach to improve the voice enhancement model based on recognitionresults.TheyusedtheChinesebroadcastnews dataset to test the proposed voice enhancement system (MATBN).TheRL Basedvoiceenhancementmayeffectively reducecharactermistakeratesby12.40%and19.23%by using recognition errors as the goal function. More noise kindswillbeinvestigatedinthefuturewhendevelopingthe RL basedsystem[10]
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
We'veseenthatreducingspeechnoiseisessential forconstructingreliablespeechrecognitionsystemsinnoisy contexts. As a result, Imad Qasim Habeeb et al. [11] suggestedanensembleapproachthatusesnumerousnoise reducingfilterstoincreasetheaccuracyofAutomaticSpeech Recognition. To boost Automatic Speech Recognition Accuracy,theyappliedthreenoisereductionfilters.These threefiltersgeneratenumerouscopiesofthespeechsignal, withthebestcopychosenforthevoicerecognitionsystem's finaloutput.Theystudiedthismodelandfoundpromising results,suchasa16.61%drop incharactererrorrateandan 11.54% reduction in word error rate when compared to previousstrategies[11]
The results of the experiments showed that alternativenoisereductionfilterscouldpotentiallyprovide additional information about the phonemes to be categorized,whichcouldbeusedtoimprovetheAutomatic SpeechRecognitionSystem'saccuracy.However,becausea humancanguesswordsorphrasesevenifhedoesn'thear them completely, a technique based on the n gram model canbedevelopedtogiveamechanismsimilartothehuman hearingsystem[11]
Thisstudydiscussesstrong voicerecognitionand critical factors in speech recognition, as well as diverse methodologiesusedbydifferentresearchers.We'velooked athowspeechrecognitionworks,coveringaudiorecording, voice pre processing, classification models, and neural networksforspeechrecognition.Wealsospokeabouthow toextractfeaturesfromspeechsignals.Anoverviewoftests conducted by authors with their work has also been included.
Robustspeechrecognitionisstillalongwayofffor humans, and developing such a system with good performanceisadifficultundertaking.Inthispaper,wehave tried to provide a comprehensive overview of key advancementsinthefieldofAutomaticSpeechRecognition. We've also attempted to list some research that could be useful in developing systems for physically challenged people.
[1] Jisi Zhang, Catalin Zoril a, Rama Doddipatla and Jon Barker “On monoaural speech enhancement for automaticrecognitionofrealnoisyspeechusingmixture invariant training.” arXiv preprint arXiv:2205.01751, 2022.
[2] Xuankai Chang, Takashi Maekaku, Yuya Fujita, Shinji Watanabe “End to End Integration of Speech Recognition,SpeechEnhancement,andSelf Supervised
Learning Representation.” arXiv preprint arXiv:2204.00540,2022.
[3] ChenChen,NanaHou,YuchenHu,ShashankShirol,Eng Siong Chng “NOISE ROBUST SPEECH RECOGNITION WITH 10 MINUTES UNPARALLELED IN DOMAIN DATA.”arXivpreprintarXiv:2203.15321,2022
[4] Surekha Reddy Bandela, T. Kishore Kumar “UnsupervisedfeatureselectionandNMFde noisingfor robustSpeechEmotionRecognition”,AppliedAcoustics, Elsevier,Vol172,January2021.
[5] Zhaojuan Song “English speech recognition based on deeplearningwithmultiplefeatures.”Springer,2019.
[6] A. I. Alhamada, O. O. Khalifa, and A. H. Abdalla “Deep Learning for Environmentally Robust Speech Recognition”,AIPConferenceProceedings,2020
[7] Gueorgui Pironkov, Sean UN Wood, Stephane Dupont “Hybrid task learning for robust automatic speech recognition.” Elsevier, Computer Speech & Language, Volume64,2020.
[8] LAshokKumar,DKarthikaRenuka,SLovelynRose,MC ShunmugaPriya,IMadeWartana“Deeplearningbased assistivetechnologyonaudiovisualspeechrecognition forhearingimpaired.”,InternationalJournalofCognitive ComputinginEngineering,Volume3,2022.
[9] PanZhou,WenwenYang,WeiChen,YanfengWang,Jia Jia“MODALITYATTENTIONFOREND TO ENDAUDIO VISUAL SPEECH RECOGNITION”, arXiv preprint arXiv:1811.05250,2019.
[10] Yih LiangShen,Chao YuanHuang,Syu SiangWang,Yu Tsao, Hsin Min Wang, and Tai Shih Chi, “REINFORCEMENT LEARNING BASED SPEECH ENHANCEMENTFORROBUSTSPEECHRECOGNITION“, arXivpreprintarXiv:1811.04224,2018.
[11] Imad Qasim Habeeb, Tamara Z. Fadhil, Yaseen Naser Jurn,ZeyadQasimHabeeb,HananNajmAbdulkhudhur, “Anensembletechniqueforspeechrecognitioninnoisy environments.”, Indonesian Journal of Electrical EngineeringandComputerScienceVol.18,No.2,May 2020
[12] Pranjal Maurya, DayasankarSingh “A Survey Robust SpeechRecognition”,InternationalJournalofAdvance ResearchinScienceandEngineering,Volume7,2018.
[13] AtmaPrakashSingh,RavindraNath,SantoshKumar,“A Survey: Speech Recognition Approaches and Techniques”,IEEEXplore,2019.
[14] Neha Jain, Somya Rastogi “SPEECH RECOGNITION SYSTEMS ACOMPREHENSIVESTUDYOFCONCEPTS ANDMECHANISM.”,ActaInformaticaMalaysia,2019
[15] Dr.R.L.K.Venkateswarlu,Dr.R.VasanthaKumari,G.Vani JayaSri“SpeechRecognitionByUsingRecurrentNeural Networks.”, International Journal of Scientific & EngineeringResearchVolume2,2011
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal