International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Harika, Avula Sai Sruthi, Maddina Syamala, Guide Name: Mrs. Jyostna Devi Bodapati
Department of Computer Science and Engineering, Vignan’s foundation for science Technology and research university Guntur 522213, India ***
This paper offers a hybrid version of imaginative and prescient Transformer,referred to as Swin Transformer and CNN (Convolutional Neural Network). The problems in adapting Transformer from language to imaginative and prescient stem from variations among the 2 domains, which includes massive versions withinside the scale of visible entities and the excessive decision of pixels in pictures as compared to phrases in text.Overfitting, exploding gradient, and sophistication imbalance are the fundamental demanding situations at the same time as education the version the use of CNN. These problems can lessen the overall performance of the version.To deal with those distinctions, we advise a hybrid version of Vision Transformer whose illustration is computed with Shifted home windows and CNN.The shifted windowing scheme improves performance via way of means of limiting self interest computation to non overlapping neighborhood home windowsat the same time as nevertheless taking into account cross window connections. Weshow that the fusion of the transformer and CNN primarily based totally fashions outperforms the respective baseline version. We additionally show theonlymannertomixthetransformerandCNN.
Convolutionalneuralnetworks(CNNs)havelongdominatedcomputervisionmodeling.TheCNNarchitecturehasevolvedto becomemoreandmorepowerfulwithlarger,largerinterconnects,andmoresophisticatedconvolutionalformats, including AlexNet and its innovative performance in ImageNet image classification challenges. I did. These architectural advances have improvedperformanceandimprovedtheoverallfield.CNNsserveasthebackbonenetworkforvariousimagingtasks.
Ontheotherhand,theevolutionofcommunityarchitecturesinNaturalLanguageProcessing(NLP)hastakenanexceptional path, with the Transformer now being the dominant architecture. The Transformer, which became designed for series modeling and transduction tasks, is exceptional for its use of interest to version long time period dependencies in data. Its out of the ordinary achievement withinside the language area has brought on researchers to analyze its version to laptop vision, wherein it has currently established promising effects on particular tasks, consisting of photo category and joint vision languagemodeling.
In thispaper,weaimtobroadenTransformer'sapplicabilitysothatitcanserveasageneral purposebackboneforcomputer vision, as it does for NLP and as CNNs doin vision. We find that differences between the two modalities explain significant challengesintransferringitshighperformanceinthelanguagedomaintothevisualdomain.Scaleisoneofthesedistinctions. Unlike word tokens, which serve as the basic processing elements in language Transformers, visual elements can vary significantly in scale, a problem that is addressed in tasks such as object detection. Tokens in existing Transformer based modelsareallfixedscale,whichisunsuitableforthesevisionapplications.Anotherdistinctionisthatpixelsinimageshavea much higher resolution than words in text passages. Many vision tasks, suchas semantic segmentation, necessitate dense predictionatthepixellevel,whichwouldbeintractableforTransformeronhigh resolutionimagesduetothecomputational complexity of its self attention being quadratic to image size. To address these issues, we propose Swin Transformer, a general purposeTransformerbackbonethatconstructshierarchicalfeaturemapsandhaslinearcomputationalcomplexityto imagesize.
SwinTransformerbuildsahierarchicalrepresentationbystartingwithsmallpatchesandgraduallymergingthemindeeper Transformerlayers.Withthesehierarchicalfeaturemaps,theSwinTransformermodelcaneasilyleverageadvanceddense prediction techniques such as feature pyramid networks or U Net. Self attention is computed locally within non overlapping windows that partition an image to achieve linear computational complexity. Because the number of
International Research Journal
Engineering
(IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
patches in each window is fixed, the complexity is proportional to image size. Swin Transformer, in contrast to previous Transformer basedarchitecturesthatproducefeaturemapsofasingleresolutionandhavequadraticcomplexity,issuitable asageneral purposebackboneforvariousvisiontasks.
Swin Transformer's window partition shift between consecutive self attention layers is a key design element. The shifted windowsconnectthewindowsofthepreviouslayer,providingconnectionsthatsignificantlyincreasemodelingpower. This strategyisalsoefficientintermsofreal worldlatency:allquerypatches withina windowsharethesamekeyset1,making memory access in hardware easier. Earlier sliding window based self attention approaches, on the other hand, suffer from lowlatencyongeneralhardwareduetodifferentkeysetsfordifferentquerypixels.
Ourexperimentsshowthattheproposedshiftedwindowmethodhasmuchlower latencythanthesliding windowmethod whileprovidingcomparablemodeling power.Theshiftedwindowapproachis alsoadvantageous forall MLParchitectures. Our experiments have revealed the best combinations of Swin transformer blocks and CNN. The proposed hybrid architecture of Swin Transformer and CNN performs well on image classification, object detection, Face Emotion Recognition, and semantic segmentation tasks. On all three tasks, it significantly outperforms the ViT / DeiT and ResNet modelswithcomparablelatency.
We believe that unified structure for pc imaginative and prescient and herbal language processing might advantage each field due to the fact it might permit for joint modeling of visible and textual alerts and greater deeply shared modeling knowledge.WewishthatSwinTransformer`srobustoverallperformanceonnumerousimaginativeandprescientissueswill supportthisnotionandinspireunifiedmodelingofimaginativeandprescientandlanguagealerts.
CNN isthe mostcommonly used network model in computervision. CNN has been aroundfor decades, but it wasn'tuntil AlexNet came out that it gained momentum and gained popularity. Since then, deeper and more effective convolutional neural architectures such as VGG, GoogleNet, ResNet, DenseNet, HRNet, and EfficientNet have been proposed to further accelerate the wave of deep learning in computer vision. Apart from architectural advances, much work has been done to improve the individual convolution layers, such as: B. Depth convolution and deformable convolution. CNNs and their variantsremainthemainbackbonearchitecture forcomputervisionapplications, but emphasizetheimportant potential of Transformer like architectures for integrated modeling of vision and language combined with CNNs. Our work hopes to achievehighperformanceinavarietyofbasicvisualrecognitiontasksandcontributetoaparadigmshiftinmodeling.
Someworkusesself awarelayerstoreplacesomeorallofthepopularResNetspatialconvolutionlayers.Again,itisinspired bythesuccess of theself awarenesslayerandtransformerarchitectureintheNLPspace.Tospeedup optimization,these taskscalculateself awarenesswithin the local window for each pixel, achieving slightly better accuracy / FLOPtrade offs thanthecorrespondingResNetarchitecture.However,duetothehighcostofmemoryaccess,theactualdelayissignificantly higher than that of a convolutional network.Instead of moving windows, we suggest moving windows between successive layerstoallowforamoreefficientimplementationoncommonhardware.
Another area of research is to add self attention layers or Transformers to a standard CNN architecture. The self attention layers can supplement backbones or head networks by encoding distant dependencies or heterogeneous interactions. Transformer's encoder decoder design has recently been used for object detection and instance segmentation tasks. Our workinvestigatestheadaptationofTransformersforbasicvisualfeatureextraction,whichisthencombinedwithCNN.
VisionTransformer(ViT)anditsderivativesare mostrelevanttoourwork.For imageclassification,ViT'spioneeringwork applies the transformer architecture directly to non overlapping medium sized image fields. It provides an impressive compromisebetweenthespeedandaccuracyofimageclassificationcomparedtoconvolutionalnetworks.WhileViTneedsa largetrainingdatasettorunproperly, DeiThasintroducedseveraltrainingstrategiesthatenableViTtorunwellona small ImageNet 1K dataset. Due to the low resolution functional map and the secondary complexity of image size, ViT's architectureisnotsuitableforuseasahigh densityimageprocessingtaskorageneral purposebackbonenetworkwithhigh inputimageresolution.ThereissomeworktoapplytheViTmodeltohigh densityvisiontaskssuchasobjectdetectionand
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
semanticsegmentationusingdirectupsamplingordeconvolution,buttheperformanceisrelativelypoor.Inparallelwithour work, others are changing the ViT architecture to improve image classification. Empirically, our work focuses on general performance rather than specific classification, but our Swin Transformer architecture is the best of these image classificationmethodsbetweenspeedandaccuracy.Youwillfindthatyouwillreachacompromise.Anotherparallelworkis looking at a similar idea for creating multi resolution feature maps in Transformers. Its complexity is still quadratic with respecttoimagesize,butourcomplexityworks linearlyandlocally.Thishasprovenusefulinmodelingthehighcorrelation ofvisualsignals.
4.1 Architecture:
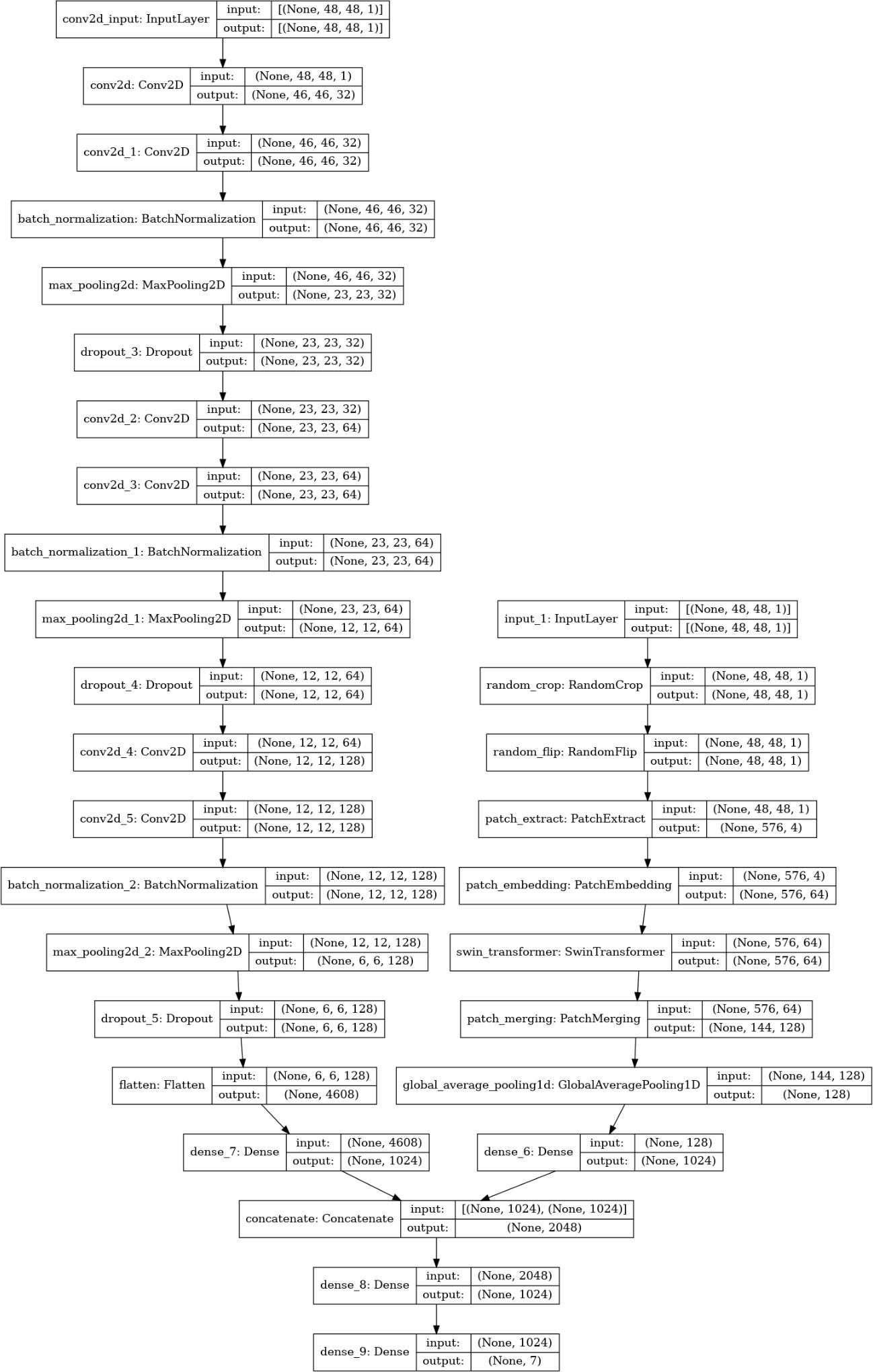
InthispaperwehaveproposedthehybridmodelofCNNandSwinTransformersothattheadvantagesofboththemethods canbeprioritizedbyreducingthedrawbacksinbothmethodsandtoimprovetheaccuracyof themodel.Inourmodelfirst theCNNisappliedonthedataset.WehaveusedthedatasetFER2013. ThentheSwinmodelisapplied.Wehavemergedthe two models and resulted in the accuracy in various types of merging and making the variations in the Swin transformer blocks.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Thearchitectureofourhybridmodelisasshowninthefig
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
ThearchitectureoftheSwintransformerishaving4maincomponents:
4.2.1 PatchExtraction
4.2.2 LinearEmbedding
4.2.3 PatchMerging
4.2.4 SwintransformerBlock
Asingleimageofthedatasetispartitionedintoseveralsmallpatches.Thesepatchescanbeoverlappingornon overlapping, it is completely based on our perspective. In this paper we preferred non overlapping patch partitions. In our implementation,weusedapatchsizeof2×2.
4.2.2
Inthissteptheoutputofthepreviousstepistakeni.e.thepatchesaretakenas input.Thisstepconvertsthepatchintoac dimensionalvector.Forconvertingthepatchesintovectorsthisstepismoreuseful.
Every image has 2x2 patches. These patches are merged into a single patch by using a linear layer. The merging is done becausebyasinglepatchwecandefinethesizeoftheoutputwewant.Exploitingthisadvantagewedoublecsothatnowc becomes2c.Herewehavedecreasedthepatchesby2butincreasecby2aswell.
Itisa standardattentionmechanismandwell forlanguageprocessingtasks,but images are different, in caseof images we dividetheimageintoseveralnon overlappingpatches.Eventhoughwedividetheinputimageintodifferentpatches we still have to compute the self attention for a given patch with all the other patches in the image. So, this becomes compute intensiveevenforareasonablylargesizedimage.
Inorder to overcome this, swin transformer introduces the windows. A window divides the input image into several parts, whenever we compute self attention between patches within that window and we ignore the rest of the patches. In swin transformer, one layer of transformer is replaced by two layers, they are WMSA and SWMSA where W stands for window basedSWstandsforshiftedwindow
Working of WSMA layer: The input image is divided into four windows and computes attention for patches within the window. The window is straightforward and the first layer of the swin transformer block. The next stage is the shifted window MSA. The window is shifted by two patches and then computes the attention within these windows while the windows shift the empty space created without and within any pixels. A naive solution for this is to zero pad that space. A moresophisticatedsolution whichiscalledcycleshiftinginthispaper.Thisisto copyoverthepatchesfromtoptobottom andfromlefttorightandalsodiagonallyacrosstomakeupforthemissingpatches.
Thefirstmoduleusesaregularwindowpartitioningstrategywhichstartsfromthe top leftpixel,andthe8×8featuremap isevenlypartitionedinto2×2windowsofsize4×4(M=4).Then,thenextmoduleadoptsawindowingconfigurationthatis
shifted from that of the preceding layer, by displacing the windows by pixels from the regularly partitionedwindows.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Withtheshiftedwindowpartitioningapproach,consecutiveSwinTransformerblocksarecomputedas where �� �� and �� denote the output features of the (S) W MSA module and the MLPmoduleforblockl,respectively
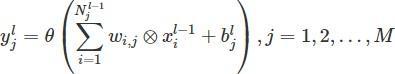
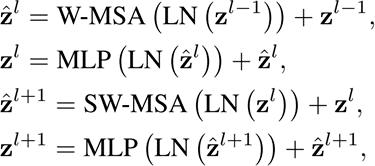
Finallythemergelayerisestablishedusingadenselayerwithsoftmaxactivation function.Thesoftmaxactivationfunctionis appliedinthedenselayersofFER netarchitecture.Softmaxisusedtocalculatetheprobabilitiesofthepredictedclasses. The classwiththehighestprobabilityisconsideredasanoutput.
Aconvolutionalneuralcommunity(CNN)isashapeofsyntheticneuralcommunitythisisspeciallymeanttoinvestigatepixel enter and is utilized in photograph popularity and processing. A CNN employs a era just like a multilayer perceptron this is optimizedforlow processingneeds.An enterlayer,an output layer, anda hiddenlayer with numerous convolutional layers, poolinglayers,completelyrelatedlayers,andnormalizinglayersmakeupCNN`slayers.
The statistical homes of various sub blocks in a herbal photograph are commonly consistent, implying that the capabilities found out from a selected subblock of the photograph may be used as a detector. To attain the activation price with the identical characteristic, all subblocks of the whole photograph are traversed. To carry out convolutional summation over all characteristicmapswithadmiretotheprecedinglayeranduploadoffsets,specialtrainableconvolutionkernelsareused. The activation feature then outputs the neuron withinside the cutting edge layer. The cutting edge layer is made from characteristicmapswithdiversecapabilities. Ingeneral,theconvolutionallayercalculationexpressionis: Where,lrepresentsthecurrentlayer l 1representsthepreviouslayer ��representsthejthfeaturemapinthecurrentlayer �� �� representstheconvolutionkernelbetweentheithfeaturemapinthe ��,�� previouslayerandthejthfeaturemapinthecurrentlayer.
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page2511
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
�� 1 �� representsthebiasofthepreviouslayer'sithfeaturemap �� ��representsthebiasofthecurrentlayer'sjthfeaturemap. �� Theterm �� issettozero,i.e. �� ��=0totrainthenetworkquicklyandreduce �� thelearningparameters. �� 1 �� ��
�� �� ��
isthenumberoffeaturemapsinthecurrentlayerthatconnecttoall featuremapsinthepreviouslayer Misthenumberoffeaturemapsinthecurrentlayer.
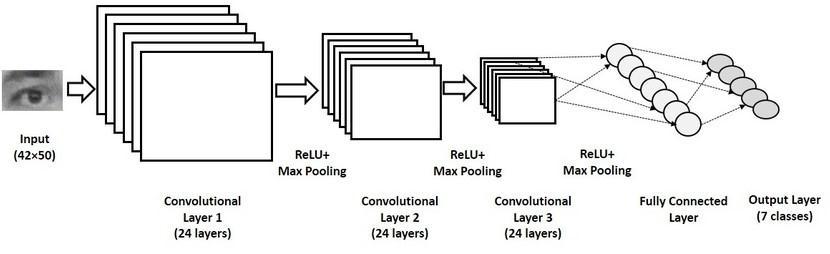
It consists of one input layer, five convolution layers, three max pooling layers and one fully connected layer. Batch normalization is applied to the outputs of convolutional layers. The first and second convolution layers consist of 32 and 64 filtersofkernel_size3x3respectively.Theinputshapeis(48,48,1)where48x48isthepixelsizeand1indicatesthattheimage isgrayscale.Thethird,fourthandfifthconvolutionlayersconsistof64,128and128filtersrespectively. TheschematicblockdiagramoftheFER netisshowninfig
The convolution layers perform convolution operations. The convolutional layersproduce feature maps, which denote high levelfeaturessuchasedges,cornerpoints,colorfromthefaceregionautomatically.Oncethefeaturemapsareextracted,the next step is to move them to a ReLU layer. This layer introduces non linearity to the network and performs element wise operation and the output is a rectified feature map. The rectified feature map now goes through a pooling layer. Pooling operation is also called subsampling which reduces the overfitting problem. Pooling is a down sampling operation that reducesthedimensionalityofthefeaturemap.Wehavedonepoolingoperationswith2x2filtersandstride2. θ(x) represents the activation function. The Rectified Linear Units (ReLU) function is used instead of the usual sigmoid or hyperbolictangentfunctionbecauseitismoresparse..TheexpressionfortheReLUfunctionis: θ(x)=max(0,x)
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
��
�� ��
Thenumberoffeaturemapsgrowsinproportiontothenumberofconvolution layers,resultinginasharpincreaseinfeature dimensions.IfallofthefeaturesareusedtotraintheSoftmaxclassifier,thedimensionswillbeenormous.Toavoidthisissue,a pooledlayeristypicallyusedtoreducethefeaturedimension.The pooling layer performs downsampling. The pooling layer reduces the number of featuremaps whileincreasing theirsize.Thatis,thepoolinglayercanmakesomeoperations such as translation,scaling,androtationmorerobust.Ifthesampling windowsizeisnn,thefeaturemapwillbe(1/n)x(1/n)ofthe originalfeatureafterdownsampling.Thegeneralexpressionforthepoolingis: Where, �� �� represents jthfeaturemapinthecurrentlayer �� �� 1 �� �� representsthepreviousfeaturemapinthecurrentlayer down()representsadown samplingfunction �� β representsthemultiplicativebias �� �� representsadditivebiastothe j featuremapinthecurrentlayer �� Intheexperiment, β =1, �� �� =0 �� θ(x)representstheactivationfunction
Cross validation isafunctionwhichevaluatesdataandreturnsthescore.K foldisaclasswhichletsussplityourdatatok folds.Herewehaveusedthe10foldsi.ethevalueofkis10.K foldcrossvalidationisaprocedureusedtoestimatetheskillof themodelonnewdata.
To attain the best model that gives the best accuracy, we have worked with variousvariations. We have varied the Swin transformer blocks, we have worked out each time by increasing the number of Swin blocks. We worked with one to four Swinblocks.Outofallthebestaccuracyisproducedonusing2Swinblocks. Aswedecidedthat2Swinblocksgivethebestresult,wevariegatedthetypeof mergingtheCNNandSwintransformer.We havemergedthelayersbyconcatenating,Dot,Maximum,Multiplyandaveraging
We Used the standard dataset for face emotion recognition i.e. FER2013 which contains 34034 unique values(grayscale images).Eachimageisofsize48x48pixel.80%ofthedatasetisusedfortrainingwhiletherestfortesting.
Alltheimagesarenormalizedto0 1scalebynormalizing.Weproposed7categoriesofemotions:anger,disgust,fear,happy, neutral, sadness and surprise. We also used preprocessing by Randomcrop. This layer will crop all the images in the same batchtothesamecroppinglocation.NextweusedRandomflipwhichflippedtheimageshorizontally.

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Thenumberofclassesare7,eachpatchsizeis2x2andthedropoutrateis0.03. The number of attention heads are 8, the MLP layer sizeis 256andbatchsizeis128.Thesizeoftheattentionwindowis2andthesizeoftheshiftingwindowis1.
All the experiments in this paper are done on the standard dataset for Face EmotionRecognition FER2013. We have performed the experiments with the Swin blocks one at a time, two at a time, three at a time, four at a time. Out of all the experiments with two Swin blocks at a time resulted in the best accuracy. And by varying the type of merge of layers by Concat,Dot,Maximum,MultiplyandAveragewegottheconcatenationoftwolayersgivesthebestaccuracy.

Theresultsareasshownbelow:
CNN 55.7 CNN + Swish 57.39 VGG19 + CNN 79.9 VGG16 + CNN 81.3
Swin 1+ CNN + KFold 82.03 (+ 7.29)
Swin 2 + CNN + KFold 82.75 (+ 7.85) Swin-3 + CNN + KFold 82.72 (+- 9.51)
Swin 4 + CNN + KFold 82.58 (+ 8.68)
Swin 1 + CNN (Concat)+ KFold 82.70 (+ 7.75)
Swin 2 + CNN (Concat)+ KFold 83.00 (+ 7.63)
Swin 2 + CNN (Dot) + KFold 39.65 (+ 12.16)
Swin 2 + CNN (Max) + KFold 81.78 (+ 7.35) Swin 2 + CNN (Multiply) + KFold 80.00 (+ 6.39)
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
This paper presents Swin Transformer and CNN, a vision Transformer hybrid model(ConvolutionalNeuralNetwork).The difficultiesinadaptingTransformerfrom language to vision stem from differences between the two domains, such aslarge differencesinvisualentityscaleandthehighresolutionofpixelsinimagescomparedtowordsintext.Themajorchallenges while training the model with CNN are overfitting, exploding gradients, and class imbalance. These issues may impairthe model'sperformance.Toaddressthesedistinctions,weproposeaVisionTransformerhybridmodelwhoserepresentationis computedusingShifted windowsandCNN.Bylimitingself attentioncomputationtonon overlapping localwindowswhile still allowing for cross window connections, the shifted windowing scheme improves efficiency. We show that combining transformer andCNN based models outperforms the respective baseline model. We also showed how to combine the transformerandCNN mosteffectivelyandfoundoutthebest performingmodelforFaceEmotionRecognitiononstandard FER2013dataset.
[1] B.Ko,“ABriefReviewofFacialEmotionRecognitionBasedonVisualInformation,”Sensors,vol.18,no.2,p.401,2018.
[2] R. C. Chivers, V. V Ramalingam, and A. Pandian, “Facial Emotion Recognition System AMachine Learning Approach FacialEmotionRecognitionSystem±AMachineLearning,”2018.
[3] Alvarez,V.M.,Velazquez,R.,Gutierrez,S.,&Enriquez Zarate,J.(2018).AMethodforFacialEmotionRecognitionBasedon InterestPoints.2018InternationalConferenceonResearchinIntelligentandComputinginEngineering(RICE),1 4.
[4] Y.Zhangetal.,“FacialEmotionRecognitionBasedonBiorthogonalWaveletEntropy,FuzzySupportVectorMachine,and StratifiedCrossValidation,”pp.8375 8385,2016.
[5] M.J. Lyons, J. Budynek, S. Akamatsu, “Automatic Classification Of Single Facial Images”,IEEE Transactions on Pattern AnalysisandMachineIntelligence21(12)(1999)1357 1362.
[6] M.H.Siddiqi etal.,“ABrief Reviewof Facial Emotion RecognitionBased on Visual Information,”2018IEEMAEng.Infin. Conf.eTechNxT2018,vol.5,no.1,pp.196 201,2018.
[7] Y.Tian,“EvaluationofFaceResolutionforExpressionAnalysis”,CVPRWorkshoponFaceProcessinginVideo,2004.
[8] Y. Gao and K.H. Leung, “Face recognition using line edge map,” IEEE Transactions onPattern Analysis and Machine Intelligence,vol.24,no.6,June2002.
[9] Zhao,L.,Peng,X.,Tian,Y.,etal.:Semanticgraphconvolutionalnetworksfor3dhumanposeregression.In:Proceedingsof theIEEE/CVFConferenceonComputerVisionandPatternRecognition,pp.3425 3435(2019)
[10] Tian,Y. I.,Kanade,T.,Cohn,J.F.: Recognizing actionunits forfacial expressionanalysis.IEEE Trans. PatternAnal. Mach. Intell.23(2),97 115(2001)
[11] Meng,Z.,Liu,P.,Cai,J.,etal.:Identity awareconvolutionalneuralnetworkforfacialexpressionrecognition.In:201712th IEEEInternationalConferenceonAutomaticFace&GestureRecognition(FG2017),pp.558 565(2017)
[12] S. Deshmukh, M. Patwardhan, and A. Mahajan, “Survey on RealTime Facial ExpressionRecognition Techniques,” IET Biom.,pp.1 9,2015
[13] Yang, H., Ciftci, U.,Yin, L.: Facial expression recognition by deexpression residue learning.In: Proceedings of the IEEE ConferenceonComputerVisionandPatternRecognition,pp.2168 2177(2018)
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
[14] Defferrard, M., Bresson, X., Vandergheynst, P.: Convolutional neural networks on graphswith fast localized spectral filtering.Adv.NeuralInf.Process.Syst.29,3844 3852(2016)
[15] Gogi´c, I., Manhart, M., Pandži´c, I.S., et al.: Fast facial expression recognition using localbinary features and shallow neuralnetworks.Vis.Comput.36(1),97 112(2020)
[16] T. Kundu and C. Saravanan, "Advancements and recent trends in emotion recognition usingfacial image analysis and machine learning models," 2017 International Conference on Electrical, Electronics, Communication, Computer, and OptimizationTechniques(ICEECCOT),Mysuru,2017,pp.1 6
[17] H. Ebine, Y. Shiga, M. Ikeda and O. Nakamura, "The recognition of facial expressions withautomatic detection of the referenceface,"2000CanadianConferenceonElectrical and ComputerEngineering. ConferenceProceedings.Navigatingtoa NewEra(Cat.No.00TH8492),Halifax,NS,2000,pp.1091 1099vol.2.
[18] Lucey P, Cohn JF, Kanade T, Saragih J, Ambadar Z, Matthews I (2010) The extended Cohn Kanade dataset (ck+): a completedatasetforactionunitandemotion specifiedexpression. In:2010IEEEcomputersocietyconferenceoncomputervisionandpatternrecognition workshops.IEEE,pp94 101
[19] M. F. Valstar et al., « FERA 2015 second Facial Expression Recognition and Analysis challenge », in 2015 11th IEEE InternationalConferenceandWorkshopsonAutomaticFaceandGestureRecognition(FG)
[20] NebauerC.Evaluationofconvolutionalneuralnetworksforvisualrecognition.IEEETransactionsonNeuralNetworks,9 (4)(1998),pp.685 696
[21] Uçar, A. (2017, July) “Deep Convolutional Neural Networks for facial expression recognition.” In Innovations in IntelligentSystemsandApplications(INISTA),2017IEEEInternationalConferenceon(pp.371 375)..
[22] ZhaoweiCaiandNunoVasconcelos.Cascader cnn:Delvingintohighqualityobjectdetection.InProceedingsoftheIEEE ConferenceonComputerVisionandPatternRecognition,pages6154 6162,2018
[23] Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In ProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition,pages9308 9316,2019.
[24] Xianzhi Du, Tsung Yi Lin, Pengchong Jin, Golnaz Ghiasi, Mingxing Tan, Yin Cui, Quoc V Le,and Xiaodan Song. Spinenet: Learningscale permutedbackboneforrecognitionand localization.InProceedingsoftheIEEE/CVFConferenceonComputer VisionandPatternRecognition,pages11592 11601,2020.
[25] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is 11 worth 16x16 words:Transformersforimagerecognitionatscale.InInternationalConferenceonLearningRepresentations,2021.
[26] KaimingHe,XiangyuZhang,ShaoqingRen,andJianSun. Deepresiduallearningforimagerecognition.InProceedingsof theIEEEConferenceonComputerVisionandPatternRecognition,pages770 778,2016.
[27] Vinyals&Kaiser,Koo,Petrov,Sutskever,andHinton.Grammarasaforeignlanguage.InAdvancesinNeuralInformation ProcessingSystems,2015.
[28] Kunihiko Fukushima. Cognitron: A self organizing multilayered neural network. Biologicalcybernetics, 20(3):121 136, 1975
[29] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin.Attentionisallyouneed.InAdvancesinNeuralInformationProcessingSystems,pages5998 6008,2017.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
[30] BharatSingh,MahyarNajibi,andLarrySDavis.Sniper:Efficientmulti scaletraining.InAdvancesinNeuralInformation ProcessingSystems,volume31.CurranAssociates,Inc.,2018.
[31] https://ieeexplore.ieee.org/document/8606597L.Xu,M.Fei,W.ZhouandA.Yang,"FaceExpressionRecognitionBased on Convolutional Neural Network," 2018 Australian & New Zealand Control Conference (ANZCC), 2018, pp. 115 118, doi: 10.1109/ANZCC.2018.8606597.
[32] https://ieeexplore.ieee.org/document/9751735 R. Appasaheb Borgalli and S. Surve, "DeepLearning Framework for FacialEmotionRecognition usingCNN Architectures,"2022 International ConferenceonElectronicsandRenewableSystems (ICEARS),2022,pp.1777 1784,doi:10.1109/ICEARS53579.2022.9751735.
[33] https://www.researchgate.net/publication/336858850_A_Face_Emotion_Recognition_Method_Using_Convolutional_Neu ral_Network_and_Image_Edge_Computing Zhang, Hongli & Jolfaei, Alireza & Alazab, Mamoun. (2019). A Face Emotion Recognition Method Using Convolutional Neural Network and Image Edge Computing. IEEE Access. PP. 1 1.10.1109/ACCESS.2019.2949741.
[34]https://www.researchgate.net/publication/351056923_Facial_Expression_Recognition_Using _CNN_with_KerasKhopkar, 47 50.10.21786/bbrc/14.5/10.
Apeksha & Adholiya, Ashish. (2021). Facial ExpressionRecognition Using CNN with Keras. Bioscience Biotechnology ResearchCommunications.14.
[35] https://arxiv.org/abs/2103.14030SwinTransformer:HierarchicalVisionTransformerusingShiftedWindowsZeLiu, YutongLin,YueCao,HanHu,YixuanWei,ZhengZhang,StephenLin,BainingGuo
[36] https://paperswithcode.com/method/swin transformer Liu et al. in Swin Transformer:Hierarchical Vision TransformerusingShiftedWindow