International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
DetectingTheDamageAssessmentTweetsIsBeneficialToB othHumanitarianOrganizations And Victims During A Disaster. By far most Of The Previous Works That IdentifyTweetsDuringADisasterHaveBeenRelatedTo Situational Information, Availability/Requirement Of Resources,InfrastructureDamage,Etc.ThereAreOnlyA Few Works Focused On Detecting The Damage Assessment Tweets. A Novel Method Is Proposed For Identifying The Damage Assessment Tweets During A Disaster. The Proposed Method Effectively Utilizes The Low Level Lexical Features, Top Most Frequency Word Features, And Syntactic Features That Are Specific To Damage Assessment. These Features are Weighted By Using Simple LSTM (Long Short Term Memory) And Tensor Flow Frame work Algorithms. Further, Random Forest Technique Is Used As A Classifier For Classifying TheTweets.Examined14StandardDisasterDatasetsOf Different Categories For Binary And Multi Class Classification. Most Importantly, The Proposed Method Can Be Applied In A Situation Where Enough Labeled Tweets Are Not Available And Also When Specific Disaster Type Tweets Are Not Available. This Can Be Done By Training The Model With Past Disaster Datasets.
In the past several years, there has been an enormous improvement in the usage of little adding to a blog stages like Twitter. Pushed by that turn of events, associations, and media affiliations are logically searching for approaches to digging Twitter for information about what people think and feel about their thingsandorganizations. Associations like Twitter (twitrratr.com), tweet feel(www.tweetfeel.com), and Social Mention (www.socialmention.com) are just an interesting kinds of individuals who advance Twitter assessment as one of their organizations. While there has been an impressive proportion of assessment on how suppositions are imparted in sorts, for instance, online overviews and reports, how sentiments are conveyed given the relaxed language and message lengthconstraintsofscaleddowndistributingcontentto a blog has been essentially less examined. Components, for instance, customized linguistic element names and resources, for instance, assessment vocabularies have shown supportive for feeling assessment in various regions, yet will they also exhibit important for assessment in Twitter? In this undertaking, we begin to
explore this request. Another trial of scaled down composition for a blog is the fabulous broadness of subject that is covered. It's everything except a distortion to say that people tweet about everything no matter what. Consequently, to have the choice to develop systems to mine Twitter assessment on some irregular point, we truly need a technique for quickly perceivingdatathatcanusedfortrain.Inthisendeavor, we research one method for building such data: using Twitterhashtags(e.g.,#bestfeeling,#epicfail,#news)toide ntifypositive,negative,andfair mindedtweetstousefor planning three way feeling classifiers. The electronic medium brings transformed into an enormous way for peopletothetablefortheirperspectivesandwithonline diversion, there is an abundance of evaluation informationopen.
Using feeling examination, the furthest point of assumptions can be found, similar to great, critical, or unprejudiced by separating the text of the appraisal. Feeling assessment has been useful so that associations might hear their client's contemplations on their things expecting consequences of choices , and getting appraisals from film studies. The information gained from assessment is useful for associations going with future decisions. Various standard strategies in feeling assessment uses the sack of words strategy. The sack of words method doesn't ponder language morphology, and it could mistakenly arrange two articulations of having a comparative significance since it could have comparativebunchofwords.
Assessment of in the space of little composition for a blog is a tolerably new investigation point so there is as yetalotofsexaminationofclientreviews,records,web online diaries/articles and general expression level inclination assessment. These differentiation from twitter generally because of the farthest reaches of 140characters per tweet which drives the client to present perspective stuffed in very short message. The best results showed up at in feeling game plan use controlledlearningmethodslikeLSTMandTensorFlow framework, but the manual checking expected for the regulated methodology is expensive. Some work has been done on performance and semi managed approaches, and there is a lot of room of progress. Various experts testing new features and classification techniques often just compare their results to base line performance. There is a need of suitable and formal
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
examinations between these outcomes showed up through different components and plan systems to pick the best features and most efficient classification techniquesforparticularapplication.
Assessment:
Ensuing to inspecting the prerequisites of the assignment to be performed, to break down the issue and sort out its particular circumstance. The principal development in the stage is focusing on the ongoing structure and other is to sort out the necessities and region of the new system. Both the activities are similarlysignificant,yettheessentialactivityfillsinasa reason of giving the functional conclusions and afterward fruitful plan of the proposed framework. Understandingthepropertiesandnecessitiesofanother framework is more problematic and requires inventive thinking and cognizance of existing running framework is in like manner irksome, misguided perception of the ongoingsystemcanleadredirectionfromarrangement.
Tensor Flow:
Tensor stream is used for the execution with Word Net group using Python. As a component of the pre dealing with step, the dataset is similarly different over into a sensible construction to be given to the profound learning models. The information arrangement incorporates Stop Words evacuation, Punctuation expulsion, Stemming, Lemmatization, and Bag of words development, count Vectorization and TF IDFVectorization. Count Vectorization and TF IDF Vectorizationareappliedtothedatasetafteritisparted into bigrams, i.e., n grams with n=2. It yields better accuracy while considering unigrams orn gramswithngreaterthan2.Theunbalanced rough informational index is changed over in to a decent informational index by adding a restricted amount of Gaussian disturbance to each disaster event test. The informational collection test is only pre prepared with wordimplantinglikeWordNet.
InRecurrentNeuralNetworks,allofthesentencesinthe datasetareseparatedintowordsandchangedoverusing theembeddinglayerintowordembedding.Then,atthat point, the word introducing is applied alongside cerebrumnetworklayers LongShort TermMemory,Bi directionalGatedRecurrentUnitwith3 layerswhichis totally related. These layers finally interact with the outcome layer. The precision of the mind networks that arearrangedusingthoselayersisshownintheFig.3,for 5iterations. Specifically, the GRU and LSTM went with the decision from one side of the planet to the other, where the flow of its assumption for testing set determinedlyaccomplicesthereadinessset.
Execution is the period of the endeavor when the speculative arrangement is changed out into a working system. Subsequently it will in general be seen as the most essential stage in achieving a productive new system and in giving the client, sureness that the new structurewillworkandbestrong.
The execution stage incorporates wary readiness, assessment of the ongoing system and it's limits on execution, arranging of methods to achieve change over andevaluationofprogressovermethodologies.
Simulated intelligence (ML) is doing something worth remembering, with a creating affirmation that ML can expect a fundamental part in a considerable number of essential applications, for instance, data mining, normal language taking care of, picture affirmation, and expert systems.MLgivesexpectedplansinthishugenumberof spaces and anything is possible from that point, and is settobepillarofourfutureadvancement.
ThestockofableMLorganizersactuallyapparentlycan't find a workable pace to this interest. A huge legitimization behind this is that ML is tremendously intriguing. This Machine Learning informative activity presents the basics of ML speculation, setting out the typicalsubjectsandthoughts,simplifyingittofigureout the reasoning and come out as comfortable with AI essentials.

In any event, the thing unequivocally is "Artificial intelligence?" ML is a lot of things. The field is exceptionally immense and is developing rapidly, being reliably separated and sub distributed adnoun wrinkle into different sub distinguishing strengths and sorts of AI.
There are a couple of basic predictable thoughts, in any case, and the general subject is best summed up by this habituallyreferedtodeclarationmadebyArthurSamuel way back in 1959: "[Machine Learning is the] field of study that engages PCs to learn without being explicitly tweaked."
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Besides, more lately, in 1997, Tom Mitchell gave a "especially introduced" definition that has shown more significant to planning sorts: "A PC program is said to acquire for a reality E concerning a couple of undertaking T and some show measure P, accepting at least for now that its display on T, as assessed by P, improveswithexperienceE.
So expecting that you accept your program ought to anticipate, for example, traffic plans at an involved intersection(task T), you can run it through an AI estimation with data about past trafficpatterns(experienceE)and,ifithassuccessfully"lear ned",itwillthendobetteratpredictingfuturetrafficpatterns (executionmeasureP).
ML handles gives that can't be settled by numerical meansalone.
Among the different sorts of ML tasks, a huge capability isdrawnamongcoordinatedandsololearning:
• Coordinated AI: The program is "ready" on a pre describedsetof"planningmodels",whichthenwork with its ability to show up at a careful goal when given newdata.
• Solo AI: The program is given a great deal of dataandoughttofindmodelsandassociationstherein.
We will mainly focus in on coordinated learning here, but the completion of the article consolidates a brief discussionofsoloadvancingforspecificassociationsfor individualswhoareexcitedaboutseekingafterthepoint further.
In the greater part of coordinated learning applications, a conclusive goal is to encourage a finely tuned pointer work h(x)(sometimes called the "hypothesis")."Learning" contains using refined mathematical computations to smooth out this limit so that, given input data x about a certain domain(say, region of a house),it will definitively predict some captivatingworthh(x)(say,marketcostforsaidhouse).
Overhauling the pointer h(x) is done using planning models.Foreachplanningmodel,wehaveadataregard x train, for which a relating yield, y, is known early. For eachmodel,wetrackdownthequalificationbetweenthe known, right worth y, and our expected worth h(x train).With enough readiness models, these differentiations give us a supportive strategy for assessing the "shakiness" of h(x). We can then change h(x) by tweaking the potential gains of and to make it "lesswrong".Thisprocessisrepeatedoverandoveruntilthes ystemhasconvergedonthe most desirable characteristics forand.Thusly,themarkerbecomesready,andisready todosomeauthenticworldpredicting.
Essential issues here for portrayal, but the clarification ML exists is in light of the fact that, truly, the issues are impressively really baffling. On this level screen we can draw you a picture of, presumably, a three layered educational record, yet ML issues by and large oversee data with a colossal number of viewpoints, and outstandingly complex pointer limits. ML handles gives thatcan'tbesettledbynumericalmeansalone.
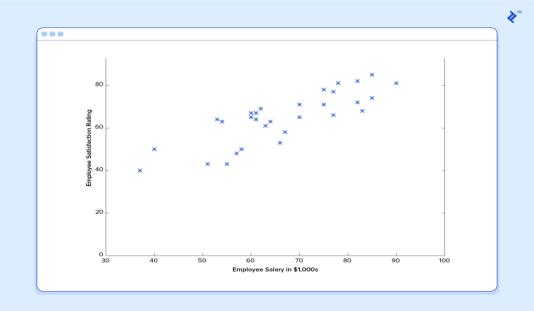
Consideringthat,weoughttolookatanessentialmodel. Weshouldexpectwehavethegoingwithplanningdata, where in association delegates have assessed their satisfactiononascaleof1to100:
Assuming we request this indicator for the fulfillment from a representative making $60k, it would anticipate ratingof27:
Clearlythiswasahorribleestimateandthatthismachine doesn'tknowdefinitely.
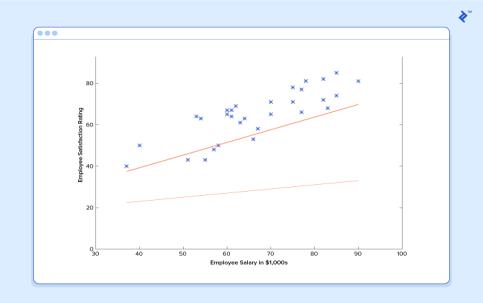
So presently, we should give this indicator every one of thecompensationsfromourpreparationset,andtakethe distinctions between the subsequent anticipated fulfillmentappraisalsandthereal fulfillmentevaluations of the relating workers. Assuming we play out a little numerical wizardry(whichIwillportrayinnotime),we canworkout,withextremelyhighsureness,thatupsides of13.12forand0.61forwillgiveusasuperiorindicator.
Where and are constants. We need to find the best potential gains of and to make our predict or fill in also ascouldbeanticipated.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
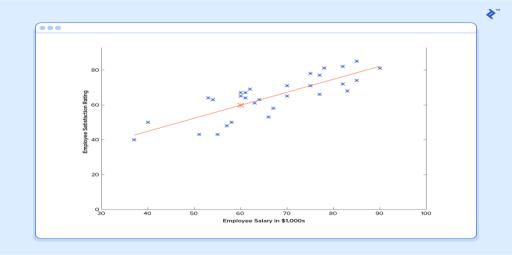
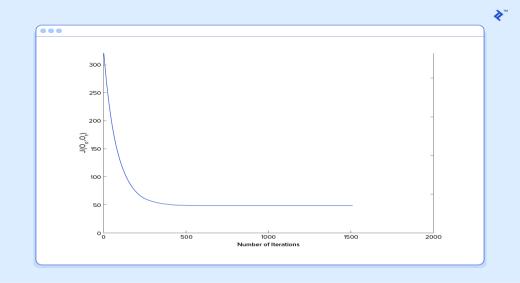
Andifwerepeatthisprocess,say1500times,ourpredictorwil lenduplookinglikethis:

At this point, if we repeat the process, we will find that and won’t change by any appreciable amount anymoreandthusweseethatthesystemhasconverged. Ifwehaven’tmadeanymistakes,thismeanswe’vefound the optimal predictor. Accordingly, if we now ask the machineagainforthesatisfactionratingoftheemployee whomakes$60k,itwillpredictaratingofroughly60.
Different undeniable level ML issues take thousands or evenuncommonvariouspartsofinformationtoassemble measuresutilizingvariouscoefficients.
Luckily, the iterative methodology taken by ML structuresisextensivelymoreextraordinarydespitesuch diverse plan. Rather than utilizing beast force, an AI structure "feels its course" to the response. For huge issues, this works much better. While this doesn't recommend that ML can manage all considering no certain extreme objective complex issues (it can't), it makesforabrilliantlyflexibleandsupportiveasset.
SlantDescent Minimizing"Instability"
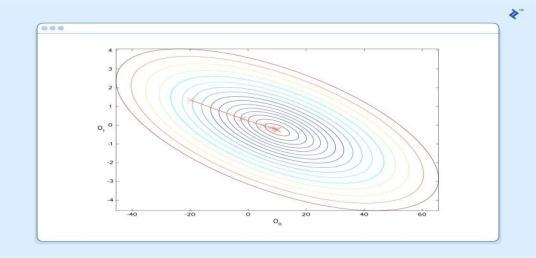
We ought to explore how this iterative connection capacities.Intheabovemodel,howdoweguaranteeand are getting better with every movement, and not more awful?Thereactionliesinour"assessmentofshakiness" proposedaheadoftime,closebyalittlemath.
Asofnowwe'regettingsomespot.
Man made intelligence Regression: A Note on Complexity
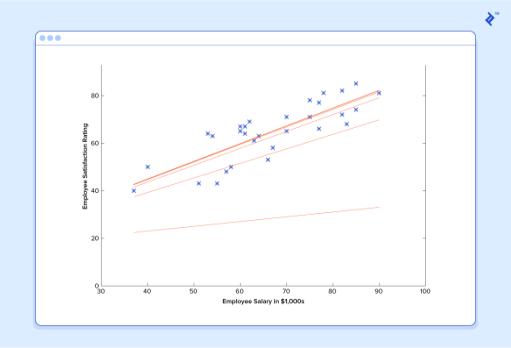
The above model is truth be told a clear issue of univariate direct backslide, which when in doubt can be handled by deciding a fundamental commonplace condition and evading this "tuning" process completely. Regardless,consideramarkerthatisbyallaccountsthis:
With least squares, the penalty for a bad guess goes up quadraticallywiththedifferencebetweentheguessand the correct answer, so it acts as a very “strict” measurement of wrongness. The cost function computes anaveragepenaltyoverallofthetrainingexamples.
This cutoff takes input in four perspectives and has a gathering of polynomial terms. Concluding an ordinary condition for this cutoff is a colossal test. Different significant level AI issues take thousands or even
uncommon countless information to make guesses utilizing various coefficients. Foreseeing how a life design's genome will be conferred, or what the environment will resemble in fifty years, are events of suchcomplexissues.
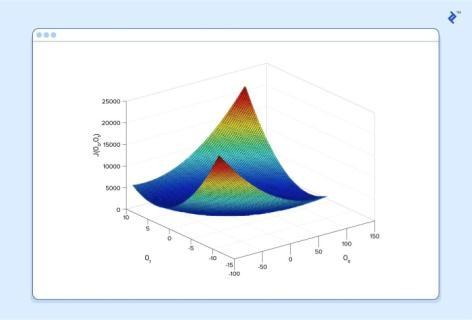
Herewecanseethecostassociatedwithdifferentvalues of and .Wecanseethegraphhasaslightbowltoits shape.Thebottomofthebowlrepresentsthelowestcost our predictor can give us based on the given training data.Thegoalisto“rolldownthehill”,andfind and correspondingtothispoint.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

fortestingtraditionalsoftwaresystemsanddevelopinghigh qualitysoftware.
• Unit tests which work on at omicpieces of the codebaseandcanberunrapidlyduringadvancement,
• Relapse tests reproduce bugs that we've recentlyexperiencedandfixed,
That covers the central speculation essential a large portion of overseen Machine Learning structures. Regardless, the fundamental thoughts can be applied in extensive variety of ways, dependent upon the focal issue.
GatheringProblemsinMachineLearningShow:
The justification for testing is to track down bumbles. Testing is the most widely recognized approach to endeavoring to track down everyconceivabledeficiency orweaknessinaworkthing.Itgivesastrategyfortruly taking a gander at the handiness of parts, sub assemblages,get togethersalongwithafinished thingIt is the most widely recognized approach to working on programming fully intent on ensuring that the Software structure meets its necessities and client suspicions and doesn't slump in an unacceptable manner. There are various types of test. Each test type addresses as pacific testingessential.
The essential objective of testing is to find flees in requirements, plan, documentation, and code as soon as could be expected. The test cycle ought to be with the end goal that the product item that will be conveyed to the client is deformity less. All Tests ought to be follow readytoclientnecessities.
What's different about testing machine learnings ystems?
• combination tests which are commonly longer running tests that notice more significant level ways of behavingthatinfluencevariouspartsinthecodebase, what'smore,followshows,forexample,
• try not to combine code except if all tests are passing,
• continuously compose tests for recently presentedrationalewhilecontributingcode,
An ordinary work stream for programming improvement.
At the point when we run our testing suite against the new code, we'll get a report of the particular ways of behaving that we've composed tests around and check thatourcodechangesdon'tinfluencethenormalwayof behaving of the framework. In the event that a test comes up short, we'll know which explicit way of behaving is not generally lined up with our normal result. We can likewise see this testing report to get a comprehension of how broad our tests are by seeing measurementslikecodeinclusion.
Amodelresultfromaconventionalprogrammingtesting suite.
We should balance this with a run of the mill work stream for creating AI frameworks. In the wake of preparing another model, we'll commonly deliver an assessmentreportincluding:
Executionofalaidoutmeasurementonanapproval dataset,
However, in machine learning systems, humans provide desired behavior as examples during training and the model optimization process produces the logic of the system.Howdoweensurethis learned logic isgoingto consistentlyproduceourdesiredbehavior?
We should begin by taking a gander at the prescribed procedures
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
Models where the model was generally certainly erroneous,andfollowshows,forexample,
Saveallofthehyper limitsusedtosetupthemodel,
Just advance models which offer an improvement over the current model (or gauge) when assessed onsimilarinformationalcollection.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Atypicalworkstreamformodelnewdevelopment.
While keeping an eye on another AI model, we'll research estimations and plots which summarize model executionoveranendorsementdataset. We'reprepared to contemplate execution between various models and settleonrelativechoices,yetwe'renotquicklyprepared to portray express model approaches to acting. For example,figuring
out where the model is tumbling commonly requires extra savvy work; one ordinary practice here is to look through an overview of the top most disgraceful model botches on the endorsement instructive assortment and genuinelygroupthesefailuremodes..
AIframeworksaretrickiertotestbecauseofthewaythat we're not expressly composing the rationale of the framework.Nonetheless,computerizedtestingisasyeta significant instrument for thedevelopmentofhigh qualitysoftwaresystems.Thesetestscanprovideuswithabe havioralreportoftrainedmodels,whichcanserveasasystem aticapproachtowardserroranalysis.
Allthroughthisblogentry,I'veintroduced"conventional programming improvement" and "AI modeldevelopment"astwoseparateconcepts.Thissimplific ationmadeiteasiertodiscusstheuniquechallengesassociate dwithtestingmachinelearningsystems;unfortunately, this present reality is more chaotic. Creating AI models likewise depends on a lot of "customary programming improvement" to handle information inputs, make highlight portrayals, perform information increase, organize model preparation, open entomb countenances to outside frameworks, and substantially more. In this way,compellingtestingforAIframeworksrequiresboth a customary programming testing suite (for model improvement foundation) and a model testing suite (for preparedmodels).
In this technique in light of the weighted highlights of LSTM has been proposed to recognize the harm evaluation tweets during a calamity. The proposed frameworkshowsthecapacitywaytodeal withperform well with and without marked information of explicit debacle informational indexes separately. The consequences of this work recommend that the utilizationoftheproposedtechniqueespeciallyprepared with tremor debacle datasets in the identification of tweetsapplicabletoharmevaluationforanyfiasco.
1. Madichetty, S. and Sridevi, M., 2021. A novel method foridentifyingthedamageassessmenttweetsduring
disaster. Future Generation Computer Systems, 116, pp.440 454.
2. Hara, Y., 2015. Behaviour analysis using tweet data andgeo tagdatainanaturaldisaster. Transportation Research Procedia, 11,pp.399 412.
3. Seddighi,H.,Salmani,I.andSeddighi,S.,2020.Saving lives and changing minds with Twitter in disasters and pandemics: a literature review. Journalism and Media, 1,pp.59 77.
4. Muhammad Imran, Carlos Castillo, Fernando Diaz, Sarah Vieweg, Processing social media messages in massemergency:Asurvey, ACM Comput.Surv. 47 (2015)67.
5. Kate Starbird, LeysiaPalen, Amanda L. Hughes, Sarah Vieweg, Chatter on the red: what hazards threat reveals about the social life of microblogged information, in: Proceeding of the 2010 ACM Conference on Computer Supported Cooperative Work,ACM,2010,pp.241 250.
3.






UG Student GATES Institute of Technology Dept .of CSE Gooty, Andhra Pradesh, India.
2.
UG Student GATES Institute of Technology Dept .of CSE Gooty, Andhra Pradesh, India
UG Student GATES Institute of Technology Dept .of CSE Gooty, Andhra Pradesh, India
Assistant Professor GATES Institute of Technology Dept .of CSE Gooty, Andhra Pradesh, India