
Fake news Detection using Machine Learning
ABSTRACT
We are in the period of data, each time we read a snippet of data or watch the news on TV, we search for a solid source. There is so much phony news spread all over the web and web based entertainment. Counterfeit News is deception or controlled word that is gotten out across social media to harm an individual, office, or association. The spread of deception in basic circumstances can cause catastrophes. Because of the spread of phony news, there is a need for computational strategies to identify them. Thus, to forestall the mischief that should possibly use innovation, we have executed Machine Learning calculations and strategies like NLTK, and LSTM. Our commitmentisbifold.Inthefirstplace,weshouldpresent the datasets which contain both phony and genuine news and direct different analyses to coordinate phony news finder. We came by improved results contrasted with the existingframeworks.
Keywords: Embedding, LSTM, NLTK.
1. INTRODUCTION
Counterfeit News will be news, stories, or lies made to purposelymisleadorbamboozleperusers.Typically,these accounts are made to impact individuals s sees, push a political plan or create turmoil, what's more, can frequently be a productive business for the web distributers. The motivation behind picking this subject is thatitisturningintoaserioussocialtest.Itispromptinga toxic air on the web also, causing mobs and lynchings out andabout.Models:politicalphonynews,newsconcerning touchy themes like religion, Coronavirus news like salt Furthermore, garlic can fix crown and all such messages weovercomevirtualentertainment.Weasawholecansee the harm that can be caused on account of phony news which is why there is a critical requirement for an instrument that can approve specific news whether it is phony or genuine and give individuals a feeling of validness given that they can choose whether or not to make a move, among so much commotion of phony news and phony information if individuals lose confidence in data, they will presently not be capable to get to even the most essential data that can indeed, even once in a while begroundbreakingorlifesaving.Ourthemethodologyisto fosteramodelwhereinitwillrecognizewhetherthegiven newsisbogusorgenuinebyutilizing
LSTM (long transient memory) and another machine learningideas,forexample,NLP,wordimplantingone hot
portrayal,andsoon.Themodelwillgiveusthe resultsfor thedatasetgiven.Itsurrendersprecisionto99.4%
2 RELATED ACTIVITIES
Alltopgoliathsareendeavoringtocovertheirselvesfrom the pieces of tattle, and the spotlight should be on apparent data and approved articles. Essentially, the procedurethatgoesonintheextractionreliesuponAIand Natural language taking care of. The classifiers, models, andcleverestimationsareexpectedtoturnoutindivisibly fortheapprovaloftheinformation
Facebookinanarticlereferredtotheyare endeavoring to fight the spread of false news in two key locales. First is upsetting financial inspiration because most counterfeit newsisfiscallyawakened.Thesubsequentoneis,Building newthingstotakealookatthespreadoffalsenews
To stop the spread of deception, WhatsApp has executed somesafetyeffortsandfurtherfeltnewsacknowledgment, inanycase,theseareunderthealphastageandareyet to be done to the beta clients. WhatsApp testing, Dubious Link Detection‟ feature: This part will alert users by puttingarednameonjoinsthatitknowstoprovokeafake or elective site/news. Besides, accepting that a message has been sent from a device past what on numerous occasions,themessagecouldbehindered.
Acoupleofphilosophieshavebeentakentorecognizethe fake news after tremendous extensive fake news of late. There are three kinds of fake news providers: social bots, savages, and cyborg clients. According to social Bots, in case an online media account is being obliged by a PC computation,then,itissuggestedasasocialbot.Thesocial bot can subsequently make content. Besides, the savages are authentic individuals who "hope to upset web based networks" to actuate online media clients into an excited response.Anotheris,Cyborg.Cyborgclientsareablendof "robotized practices with human info. People create records and use tasks to perform practices in web based media. For the false information area, there are two arrangements:LinguisticCueandNetworkAnalysismoves close. The strategies, overall, used to do such sorts of works
TermFrequency(TF):
Term Frequency is the inclusion of words present in the dreport or a figure out the disparity between the document[5][13].Each recordis portrayed in a the vector that contains the word count. This term is determined by

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
the times the term shows up in a the archive is separated bytheabsolutenumberoftermsintheDocument[3].
InverseDocumentFrequency(IDF):
Backward Document Frequency is the number of normal or uncommon words that are in the entire report or dataset. This term is determined by an all out number of records, partitioning it by the number of reports that contain a word[5][3]. Assuming the word is extremely normal and shows up in countless reports, then this will resultas
0.Otherwise1.
GullibleBayes:
Gullible Bayes utilizes probabilistic methodologies and depends on the Bayes theorem[8]. They manage the likelihood conveyance of factors in the dataset and anticipate thereactionvariableof significant worth.They have generally been utilized for text characterization. Bayeshypothesisis
P(a|b)=p(b|a)p(b)/p(a)
Thereareprimarily3kindsofgulliblebasemodels
GaussianNaïveBayes,MultinomialinnocentBayesand BernoulliNaïveBayes.WehaveutilizedMultinomialNaïve
Bayes model for our venture to distinguish counterfeit news[5][13].
A benefit of guileless Bayes classifiers is just as they requiredlesspreparationinformationfortheorder.
LSTM:
Long Short Term Memory is a sort of repetitive brain network. In RNN yield from the last advance is taken care ofasacontributiontotheongoingadvance.Ithandledthe issueoflonghaulconditionsofironinwhichtheRNNcan not anticipate the word put away in the drawn out memory however can give additional exact forecasts from the new information[5]. LSTM can naturally hold the data for an extensive period. It is utilized for processing, anticipating, and ordering based on time series information.
WordEmbedding:
Word implanting is a bunch of languages demonstrating andhighlighting extraction strategiesinNatural Language Processing (NLP). In word implanting, words from vocab earlyarechangedoverintovectorsofgenuinenumbers.
Word inserting is a kind of word portrayal that permits words with comparable implications to have a comparativeportrayal.
3. EXISTING SYSTEM
Distinguishing counterfeit news is accepted to be a mind boggling task what's more, a lot harder than identifying counterfeit item surveys. With the open idea of the web andvirtualentertainment,notwithstandingthenewhigh level pay advancements improve on the method involved with making and getting out the counterfeit words. While it's more obvious also, follow the aim and the effect of phony surveys, the goal and the effect of making promulgation by getting out counterfeit words can not be estimatedorseenwithoutanyproblem.
For example, counterfeit survey influences the item proprietor,clients,andonlinestores;ontheanotherhand, itisn'tdifficulttorecognizetheelementsthatimpacted by thephonynews.
This is because recognizing these substances requires estimatingthenewsspread,whichhasdemonstratedtobe complexandassetescalated.
WorkingofexistingSystem:
Each is a portrayal of off base or misleading announcements. Besides, the creators gauge the unique sortsofphonynewsandtheadvantagesanddisadvantages of utilizing different text investigation and prescient mod‐el ling strategies in identifying them. In their paper, the y isolatedthephonynewstypesinto3gatherings:
1. Serious creations are news not distributed in m standard or member media, yellow press, or ta blood, which,thusly,willbemoreearnestlytogather[3].
2. Large‐Scale scams are imaginative and remarkable and frequently show up at various stages. The creators contended that it may require strategies past text investigationtoidentifythissortofphonynews.
3. Hilarious phony news is expected by their essayists to be engaging, deriding, and, surprisingly, ludicrous. As per the creators, the idea of the style of this sort of phony the news could antagonistically affect the adequacy of text characterizationprocedures.
It begins with preprocessing the dataset by eliminating pointless characters and words from the information. The n‐ gram highlights are separated, and a framework of elementsisshapedtoaddresstherecordsinquestion.The last step in the characterization cycle is to prepare the classifier.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Weexaminedvariousclassifierstoforeseetheclass ofthe reports. We explicitlyresearched6unique AIcalculations, in particular, stochastic angle descent(SGD), SVM, straight helpvectormachines(LS
VM),K‐nearestneighbor(KNN),LR,andchoicetrees(DT).
Term Frequency is a strategy that utilizations word count fromtextstotrackdownlikenessesbetweentexts[5].Each recordisaddressedbyavectorofequivalentle thelength thatcontainswordcounts.Then,everyvectormadesothat the amount of its component s will be added to the next. Each number of words changed over into open doors for suchawordthatispresentinthearchives.Forinstance,if the word is something report, will be addressed as 1, furthermore,ifanyarenotinthearchive,itwillbesetto0. Thus, each the archive is addressed by bunch s of names. The average TF of the word w in wording record d is characterizedasfollows:StandardTime=Anincentivefor Documentary/Total Number record narrative Opposition (IDF) term w about record corpus D, characterized as IDF(w) D[5], by the the the the logarithm of the complete numberofarchivesinthecorpusisolatedbythenumberof lettersinwhicht
Hisspecificnameshowsupandisdeterminedasfollows: AlteredarchiveTF=1+log(absolutereports /noofarchiveswiththespecificthing)
TF‐IDF is a weighting metric frequently utilized to illuminateactivityrecoveryandNLP[3].Itisameasurable measurementusedtoquantifyhowsignificantatermisto arecordinadataset.Around80%ofthedatasetisusedfor preparing and 20% for testing. After extractiong the elementsutilizing eitherTF orIDF,wetraina AIclassifier to conclude whether the example's substance is honest or counterfeit.
GuilelessBayesModel:
Amongthefields,thatareavailableinthedataset,acouple ofthemwereutilized.TheyareconnectedtotheFacebook postswiththemessageofthenewsstory andthe mark of themessage.
The message of the news stories was recovered utilizing Facebook API [8]. News stories with the names "combination of valid and bogus" and "no verifiable substance" were not considered. Several of the articles in thedatasetare brokentheycontainnotext byanystretch of the imagination (or on the other hand contain "invalid" as a text). These articles were overlooked also. After such sifting informational index with 1771 news stories were gotten.

The dataset was arbitrarily rearranged, and after that partitionedintothreesubsets:preparingdataset,approval dataset, and test information The preparation of nine datasets was utilized for preparing the gullible Bayes classifier[8]. An approval dataset was utilized for tuning some worldwide parameters of the classifier. Test dataset was utilized to get a fair assessment of how well the classifierperformsonnewinformation
If all of the words in the news story are obscure to the classifier(neverhappenedinthepreparationdataset),the classifier reports, that it cannot order the given news article.
Ontheoffchancethata wordhappenedinthenewsstory a few times, it added to the complete likelihood of the reality, that a the news story is a phony a similar number oftimes.
Condition (4) is computationally unsteady if ascertained straightforwardly.Thisisbroughtaboutbythereality,that loads of probabilities get increased, and the aftereffect of such augmentation turns out to be near zero quick. Most programming dialects don't give the required level of accuracy, and that is the reason they decipher the after effect of augmentation as precisely zero [8]. Allow p to be the likelihood of the reality, that a given news story is phony.
One can ascertain the worth 1/p‐1 all things considered, and after that get the worth without any problem. The accompanyingconditionholds
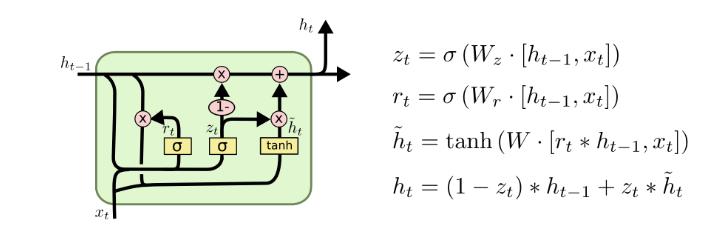
4. PROPOSED SYSTEM
LSTM Model:
Longshort termmemory(LSTM)unitsarebuildingblocks for the layers of a recurrent neural network (RNN). A LSTM unit is made out of a cell, an information door a result entryway, and a neglected door [12]. The phone is liable for" recollecting" values throughout a huge time spansotheconnectionofthewordatthebeginningofthe
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
message can impact the result of the word later in the sentence. Conventional brain networks can't recollect or keep the record of what all is passed before they are executedthisstopstheideal impactofwordsthatcomein the sentence prior to having any effect on the closure words,anditappearstobeasignificantweakness.
Word installing applies include extraction on the gave input vector. In absolute 40 vector highlights are thought of.
MODEL:
Overview of dataset:
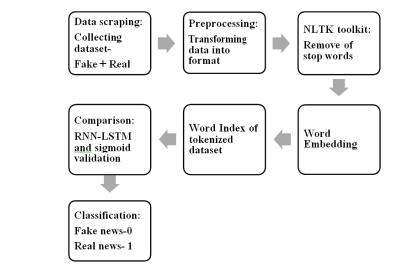
Dataset is taken from the Kaggle stage. It has the accompanying credits: id: extraordinary id for a news story, title: the title of a news story, writer: writer of the news story, text: the data of the news story. The dataset comprises of a sum of 18285 news stories for preparing and testing the model. Dataset has framed with c blend of genuine and counterfeit news. Execution subtleties: PREPROCESSING: To change information into the applicablearrangementtheinformationalcollectionneeds preprocess. Right off the bat, we eliminated all the NAN values from the dataset. Jargon sizes of 5000 words are chosen. Then NLTK (Natural Language Processing) Tool Kit is utilized to eliminate all the prevent words from the dataset. Stop words is a rundown of accentuations + prevent words from nltk toolbox for example Words, for example, 'and' ' the' and 'I' that doesn't pass a lot of data changing over them on to lowercase and eliminating accentuation.Foreachwordinrecords,it'sanythingbuta stopwordthenthatwordtagistakenfrompostage.Then, at that point, this assortment of words is annexed to the report. WORD INDEX OF TOKENIZE DATASET: Word tokenizing, adds text to a rundown and the rundown is namedasrecords.Theresultforthisstageistherundown oftherelativemultitudeofwordsintheportrayal.
WORD EMBEDDING: We can't give input in that frame of mind of message configuration to the calculation so we need to change over them into the numeric structure, for which we are utilizing one hot portrayal. In one hot portrayal,eachwordinthedatasetwillbegivenitsrecord from the characterized jargon size, and these lists are supplanted in sentences. While giving contribution to the word implanting, we need to furnish it with a decent length. Tochangeover eachsentenceintoa proper length cushioning groupings are utilized. We have thought about the maximum length of 20 words while cushioning the title. Possibly we can give cushioning before the sentence (pre) or after the sentence (post), and afterward these sentences pass as contribution to the word installing.
Outputfromthewordinstallingisgiventothemodel.The AI model executed here is a successive model comprising implanting as the principal layer which comprises values jargon size, number of elements, and length of sentence. The following is LSTM with 128 neurons for each layer, trailedbytheDenselayerwithsigmoidenactmentworkas we treat one last result. We have utilized parallel cross entropy to work out misfortune, Adam enhancer for versatile assessment, and lastly added a drop out in the middle between so that over fitting is kept away. Then preparationandtestingofthemodelaredone.
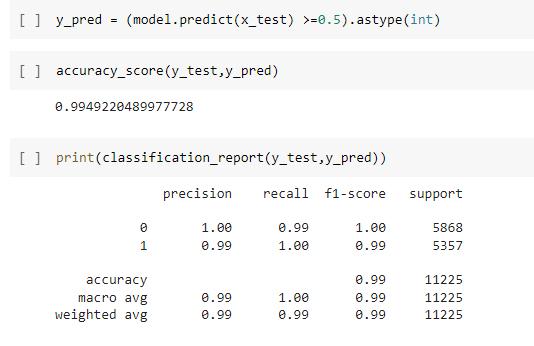
CLASSIFICATION:
For both preprocessed testing information the outcome is anticipated. In the event that the anticipated value>0.5 Classifiedas1isgenuineand0isphony.Precision=(TP+ TN)/Total. The accompanying terms were utilized: True Negative (TN), I. e., the forecast was negative and experiments,aswell,werereallyregrettable;TruePositive (TP) i.e., the expectation was positive and experiments, as well, were truly sure; False Negative (FN) i.e., the expectation was negative, yet the experiments were truly certain; False Positive (FP), i.e., the forecast was positive, yettheexperimentsweretrulynegat
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Usestemming.Insemanticmorphologyanddatarecovery, stemming is the cycle of lessening arched (or at times determined) words to their promise stem, base, or root structure by and large a composed word form[15]. Such procedure assists with treating comparable words (like "state" furthermore "composing") as similar words and mayIimprovetheclassifier'spresentationtoo.
6. EXISTING SYSTEM VS PROPOSED SYSTEM
5. RESULTS
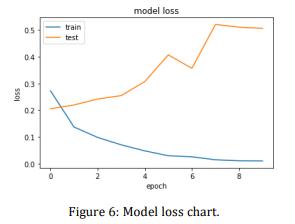

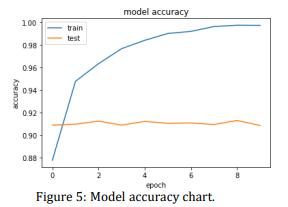
Get more data and use it for preparation. In AI issues it is many times the situation when getting more information essentially works on the execution of a learning calculation.Theinformationset,thatwasportrayedinthis article contains something like 18285 all out news. From which 80% is taken for preparing for example 14628 and 20% is taken for testing for example 3657. Precision can be expanded by preparing the model with additional information.
Utilizethedatasetwithalotmoreprominentlengthofthe news stories. The news stories, that were introduced in the current dataset, generally were not so lengthy. Preparingaclassifierinadatasetwithbiggernewsstories oughttofurtherdevelopitsexhibitionessentially.
Eliminate prevent words from the news stories. Stop words are the words, that are normal to all kinds of texts (likearticlesinEnglish).
These words are normal to such an extent that they don't influencetheaccuracyofthedata inthenewsstory,soit's agoodideatogetfreedofthem[14].
7. LIMITATIONS
Whiletheoutcomesexaminedthusproposeforthemodel a few outside highlights like a wellspring of the news, creator of the news, spot of beginning of the news, time stamp of information were not viewed as in our model which can impact the result of the model. Accessibility of datasets and writing papers are restricted to counterfeit news discovery. The length of the news that is heading or entirenews islesswhichinfluences the outcomeasfar as precision In Fake News with expanding in a layer of modulepreparingtimeincrements.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
8. APPLICATION
The main application of fake news predictions is to identifythecorrectnessoffactsandtoprovidetrustinthe newstheyarereadingandconsidering.
Much fake news is intentionally spread to create the instability in certain groups or worldwide for their self benefits which somehow leads to major destruction in societyandincreasescrimeWeaimstocontrolthecrimes and riots caused due to the false information and to provide the result whether the news is correct or manipulated
9. CONCLUSION
In this advanced age, where scam news is available wherever on computerized stages, there is an extreme requirement for counterfeit news identification and this model fills its need by being the need of their device. Counterfeit News concerning delicate points prompts a harmfulclimateontheweb.CounterfeitNewsDetectionis the examination of socially applicable information to recognizewhetheritisgenuineorcounterfeit.Hereinthis paper, we looked at different techniques like Bag Of Words(BoW), N grams, TF‐IDF, Naïve Bayes, and so on. LSTM to be best of all we utilized different methods like stop word expulsion, one hot r portrayal, word inserting, andhowSTMMcanbeutilizedtoobtainimprovedresults. The model referenced in this paper is extremely successful, Also consents to the current thing framework the model proposed here gives improved results with a precision ofi91.05% which is extremely encouraging, we canadditionallyincrementresultsbyexpandingpreparing information.
10. REFERENCES
[1.][IEEE 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (A VSS) Auckland, New Zealand (2018.11.27 2018.11.30)]2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) Fake Information andNewsDetectionusingDeepLearning.
[2.]International Institute of Information TecInternational InstituteinformationTechnology[2018],Bangalore,India. 3HAN A Deep Neural Network foriFake News Detectionhnology [2018], Bangalore, India. 3HAN A Deep NeuralNetworkforFakeNewsDetection.
[3.]ECE Department University of victoria, CanadaSchool of computer science, University of Windsor r, Canada Detecting Opinion spams and Fake News using Text Classification.
[4.]Fabula AI(UK), USI Lugano (Switzerland), Imperial college of London Fake News Detection on Social Media usingGeometricdeeplearning.
[5.][IEEE 2018 4th International Conference on Computing Communication and Automation(ICCCA) GreateriNoida, India (2018.12.14 2018.12.15)] 2018 4thInternational Conference on Computing Communication and Automation (ICCCA) Fake News DetectionUsingADeepNeuralNetwork.
[6.]Conroy, N. J., Rubin, V. L., & Chen, Y. (2015). Au automatic deception detection: Methods for finding fake news. Proceedings of the Association for Information ScienceandTechnology.
[7.]Wu, Liang, and Huan Liu. "Tracing Fake News Footprints: Characterizing Social MediaMessages by How TheyPropagate."
[8.]Granik, Mykhailo, andVolodymyr Mesyura. "Fake news detection using naive Bayes classifier." Electrical and ComputerEngineering(UKRCON),2017IEEEFirstUkraine Conferenceon.IEEE,2017.
[9.]Buntain, Cody, and Jennifer Golbeck. "Automatically IdentifyingFakeNewsinPopularTwitter Threads." Smart Cloud2017IEEEInternationalConferenceon.IEEE,2017
[10.]Shu,Kai,"Fakenewsdetectiononsocialmedia:Adata mining perspective." ACM SIGKDD Ex plorations Newsletter19.1(2017).
[11.]Bhatt, Gaurav "Combining Neural, Statistical an nd External Features for Fake News Stance Identification." Companion of the Web Conference 2018 on the Web Conference 2018. International World Wide Web ConferencesSteeringCommittee,2018.
[12.] S.Ananth, Dr.K.Radha, Dr.S.Prema, K.Nirajan International Journal of Innovative Research in Computer and Communication Engineering “Fake News Detection using Convolution Neural Network in Deep Learning”. [13.]SupervisedLearningforFakeNewsDetection.
[14.] Stop words. (n.d.) Wikipedia. [Online]. Available: https://en.wikipedia.org/wiki/S top_words. Accessed Feb. 6, 2017. Available: https://en.wikipedia.org/wiki/ Stemming. Accessed Feb. 6, 2017 ifier” [14.] Stemming. (n.d.)Wikipedia.[Online].
[15.] Mykhailo Granik, Volodymyr Mesyura 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering(UKRCON) “FakeNewsDetection”2017