International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
I Shou University No.1, Sec. 1, Syuecheng Rd. Dashu Township, Kaohsiung,Taiwan ***
Abstract - Recently, the amount of XML document is in increasing as electronic document systems adopt XML as the standard format in document exchange. Like the weather, XML document databases rarely stay the same. Information is constantly added or removed, meaning that catalogs and indexes become obsolete or incomplete (sometimes in a matter of seconds). With great increase in online information, dynamic updating XML document takes a critical role in efficient document organization, navigation, and retrieval of a large amount of XML documents. XML document are modeled as a matrix, and a user's query and updating of the XML database is represented as a vector. Relevant XML documents in the XML database are then identified via vector operations. For the LSI model, latent semantic indexing, the most obvious approach to accommodating additions (new paths or documents) is to re compute the SVD of the new path by document matrix, but, for large XML document databases, this procedure is very costly in time and space. Less expensive alternatives, folding in combine with SVD updating, have been presented in this paper. A new proposed method, folding updating, is a combination of folding in and updating the thin SVD that is an even more attractive option. Folding updating offers a significant improvement in computation time when compared with either re computing the thin SVD or updating the thin SVD, and yet it results in little or no loss of accuracy.
Key Words: thin SVD, LSI, folding in, SVD updating, SVD folding updating,SVD re computing
As the size of modern XML databases increases, the importance of having efficient methods of information retrieval (IR) increases accordingly. Latent Semantic Indexing(LSI) isanIR methodthat uses procedures from numericallinearalgebratorepresentatextcollectionasa term document matrix [1]. The term document matrix contains a column vector for each document in the text collection, and a row for each semantically significant term. LSIusesamatrixfactorizationmethodknownasthe thin singular value decomposition (thin SVD). Unfortunately,traditional methods of computingthe thin SVDarecomputationallyintensive;mostoftheprocessing timeinLSIisspentincalculatingthethin SVDoftheterm by document matrix [2, 3]. In a dynamic environment,
such as the Internet, the term document matrix is altered oftenasnewdocumentsareadded.Giventhetremendous size of modern databases, re computing the thin SVD of the matrix each time such changes occur can be prohibitively expensive. LSI traditionally uses a method known as folding in to modify the thin SVD, in order to avoid re computing the thin SVD each time changes are madetotheterm documentmatrix.Thefolding inmethod has the benefit of being very fast, however its accuracy may degrade very quickly. A much more accurate approach is to update the thin SVD using a method introduced by Zha and Simon [4]. This updating method modifies the thin SVD of the term document matrix to reflecttheadditionsthat areto be madetomatrix. A new method, folding updating, is a combination of folding in andupdatingthethin SVDthatisaneven moreattractive option. Folding updatingoffersasignificantimprovement in computation time when compared with either re computingthethin SVDorupdatingthethin SVD,andyet itresultsinlittleornolossofaccuracy. Weinvestigatethe use of thin SVD updating methods proposed by Zha and Simon [4]. Although updating methods have also been proposed by O’Brien [5] and Berry, Dumais and O’Brien [3], research indicates that these methods give inferior resultswhencomparedtothemethodsintroducedbyZha and Simon [4]. The basic idea of LSI is that if two document vectors represent the same topic, they will share many associated words with a keyword and they will have very close semantic structures after dimension reduction via truncated SVD [10, 11]. Recent studies also indicate that retrieval accuracy of the truncated SVD technique can deteriorate if the document sets are large [12,13]. Several strategies have been proposed to deal with LSI on large datasets. The specification strategy was used to remove less important entries in truncated SVD matrices [14]. Clustered and distributed SVD strategies were proposed to partition large datasets [15]. Fan et al. (1999)[16]examinedarandomsamplingbasedapproach toSVDapproximationandpresentedtheirresults.
Therestofthepaperisorganizedasfollows. Thesection 2 gives a brief preprocessing XML documents into vector space model and overview of the SVD process. Section 3 outlines our incremental SVD algorithm. Section 4 presents our experimental procedure, results and discussion. The final section provides some concluding remarksandfutureresearchdirections.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Inthissection,wefirstintroducepre processingstepsfor the incorporation of hierarchical information in encoding the XML tree’s paths. It is based on the preorder tree representation (PTR) [6] and will be introduced after a briefreviewofhowtogenerateanXMLtreefromanXML document. To do so, we have to first go through the following five preprocessing steps for XML documents. The five preprocessing steps are conversion, path extraction, nested and duplicated path removal, similar element identification and transformation, and path elementsencoding.
From five steps preprocess, now XML document is modeled as a XML tree T=(V,E). T is connected tree with V={ v1, v2, ....} as a set of vertices and V 1 , V 2 , E v v ) , ( 2 1 as a set of edges. One distinguished vertex V r is designated the root, and for all V v , there is a uniquepathfrom r to v Asanexample,Figure1depictsa sample XML tree containing some information about collection of books. The book consists of intro tags, each comprising title, author and date tags. Each author contains fname and lname, each date includes year and month tags.Figure1leftshowsonlythefirstletterofeach tagforthesimplicity.
PEL 1 PEL 2 PEL 3 PEL 4 /B/I/T/D /I/T/D /T/D D /B/I/A/F /I/A/F /A/F F /B/I/A/L /I/A/L /A/L L /M/I/A/L /I/T /T /B/I/T/ /I/A /A /B/I/A /I /B/I/ /B /M/I/T /M /M/I
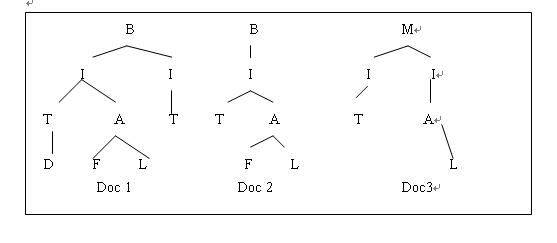
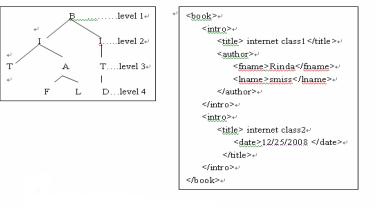
XML document has a hierarchical structure and this structure is organized with tag paths. Each tag path represents document characteristics that can predict the contentsof XML document. Strictlyspeaking, itshowsthe semantic structural characteristics of XML document. In this paper, we propose a method for calculating the similarityusingall tagpaths ofXML tree representingthe semantic structural information of XML document. From now,atagpathasatermiscalleda path element.Figure3 shows path elements obtained from XML document of Figure2.
Vector model represents a document as a vector whose path elements are the weights of the elements within a document. In calculating the weight of each element within a document, Term Frequency and IDF (Inverse Document Frequency) method is used [7]. In this paper, we use path elements of XML tree as a term. And we propose the method to calculate the weights of path elements. We define PESSW (Path Element Structural Semantic Weight) that calculate the weight of a path element in a XML document. The PESSW is PEWF (Path Element Weighted Frequency) multiplied by PEIDF (Path Element Inverse Document Frequency). PESSWij of ith pathelementinthejthdocumentisshowninequation(1). ij ij ij
PEIDF PEWF PESSW (1) ijPEWF isshowninequation(2).
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
n ij ij x freq PEWF 1 (2)
where, ijfreq is a frequency of jth path element in a ith documentanditismultipliedbylevelweight n x 1 inorder toconsiderthesemanticimportanceofapathelementina document. x refers to the level number of thehighest tag ofatagpath. Thelevelnumberoftheroottagis1. Thatof atagundertheroottagis2.Andsoon. n isarealnumber largerthan1. Inthispaper,1ischosenforthevalueofn. PEIDFijisshowninequation(3).
j ij DF N PEIDF log (3)
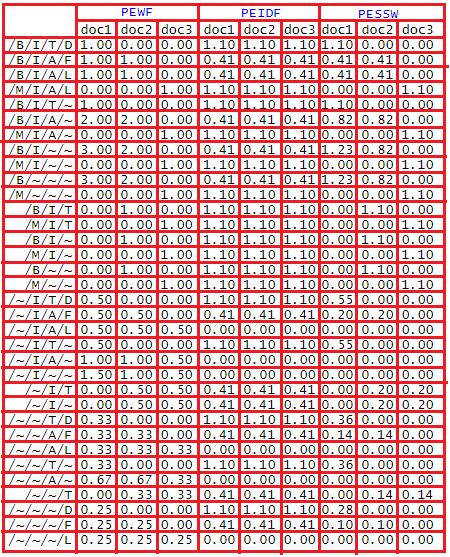
where,NbethetotalnumberofdocumentsandDFj bethe number of documents in which the jth path element appears. Table 1 shows PEWF, PEIDF, and PESSW on an exampletreesinFigure2.
Table1.Anexampleof PTWF, PTIDF and PESSW
commonly used in information retrieval for overcoming the aforementioned problems caused by synonyms and polysemies. In particular, LSI projects a document from theoriginaldocumentfeaturespaceontoacorresponding “semantic” space via singular value decomposition (SVD) so that more robust semantic based document similarity measure can be resulted. Using LSI, the original path element document matrix mxn PESSW is first decompositionintothreematrices:
V S U PESSW
where U and V contain orthonormal columns and S is diagonal. By restricting the matrices U, V and S to their firstk<min(m,n)columns,oneobtainsthematrix
PESSW D
where D ˆ is the best square approximation of D by a matrix of rank k [9]. The newly defined path element document matrix will contain document feature vectors with path element semantics (obtained based on path elementco occurrencestatistics)takenintoconsideration. To deal with novel documents not included in the path element document matrix D, one can project the novel documentvectorontothe“semanticspace”ofdimensionk and measure distance directly in the semantic space. According to [9], a novel document d’s projection can be computedas: 1 S U d d T T LSI
where 1 S U is the transformation for the projection. Another alternative is to use simply U and the correspondingpseudodocumentprojectionbecomes U d d T T LSI
whichisequivalenttoput 0S U d d T T LSI
Vector Space Model (VSM) [8] has long been used to represent unstructured documents as document feature vectors containing element occurrence statistics. By taking the vector space approach for representing XML documents,PEVSMasdescribedprevioussection,inherits the limitation of VSM terms are assumed to be independent of each other. Lacking the capability to represent terms’ semantic relationships could result in problematic cases caused by polysemies and synonyms. Latent Semantic Indexing (LSI) [9] is a technique
To apply SVDLSI to PESSW, XML documents are first partitioned into segments based on the element tags. SVDLSI isthenappliedtothesegment pathelementmatrix. Thus,anXML document willeventuallyberepresented as a matrix kxm x R d , with each column being the projection of the element specific feature vector on the semantic space. The rationale is that each XML element instanceshould bea semanticallyself containedunit. We call this version of PESSW as PESSW SVDLSI in the subsequentsections.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Our new folding updating method uses a combination of folding in and updating to modify the thin SVD of the path document matrix. The method determines when to updatebasedonthenumberofdocumentsthathavebeen folded in, relative to the size of the initial path document matrix,ortothesizeofthe lastupdatedmatrixifupdates havealreadytakenplace.Themethodbeginsbyfolding in documents, but only until the number of documents folded in reaches a predetermined percentage p of the documents in the original matrix. The changes that have beenmadetomatrixVk bythefolding inprocessarethen discarded,andthethin SVDisupdatedusingtheupdating methodsofZhaandSimon[4].Folding inisthenresumed until the number of new documents folded in reaches a predeterminedpercentage p oftheupdatedmatrix,andso on. This process requires saving the document vectors thathavebeenfolded inbetweenupdates,butrepaysthis overhead with faster computation times than updating alone,andbetteraccuracythanfolding inalone.
3.1. Folding In. Folding a new document vector into the column space of an existing path by document matrix amounts to finding coordinates for that document in the basis Uk. The first step in folding a new 1 t document vector p d ˆ into the column space is to project it onto that space.Let p d ~ representtheprojectionof p d ˆ ;then, p T k k p d U U d ˆ ~ (4) This equation shows that the coordinates of p d ~ in the basis Uk are given by the elements of the vector p T k d U ˆ . The new document is then folded in by appending the k dimensional vector p T k d U ˆ as a new column of d k the matrix T k kV S . Because the latter matrix product is not actually computed, the folding in is carried out implicitly by appending 1 ˆ k k T p S U d as a new row of Vk to form a new matrix ' kV . The implicit product ' k kV S is then the desired result. Note that the matrix ' kV is no longer orthonormal.Inaddition,therowspaceofthematrix T kV ' does not represent the row space of the new path by document matrix. Furthermore, if the new document p d ~ is nearly orthogonal to the columns of Uk, most information about that document is lost in the projection step. Our proposed folding document describe as the followingalgorithm.
/*Let d m p d ˆ bethednewdocumentsthatshouldbe foldedtotheexistingdocumentattherightoftheold path documentmatrix.*/
1:Input:k, d m p k n k k k k k m k d V S U ˆ , , ,
2:Computetheprojection: d m T k k p p U U d d ˆ ~
3:Computethe 1 ˆ k k T p k S U d d ,where d m kd .
4:Appendthe 1 ˆ k k T p S U d asanewrowof kV toformanew matrix ' kV wherenewmatrix d d d kV ) ( '
5:Output:Thebestrank kapproximationof ) ˆ , ( p k d d D E isgivenby: T k k k d k V S U E ' , where , , ) ( ' d n k T k k k k k m k V S U
Notethat k k S U , areunchangedand ' kV isnolonger orthonormal.
3.2. SVD Updating. An alternative to folding in that accounts for the effects that new terms and documents might have on term document associations while still maintaining orthogonality was first described in [3] and [5]. This approach comprises the following three steps: updating terms, updating documents, and updating term weights. As pointed out by Simon and Zha [3], the operations discussed in [3] and [5] may not produce the exactSVDofthemodifiedreduced rankLSImodel. Those authors provide alternative algorithms for all three steps of SVD updating, and we now review them. For consistency with our earlier discussion, we use column pivotingintheQRfactorizations,althoughitisnotusedin [3], [5], and [4]. Our proposed SVD Updating document describesasthefollowingalgorithm.
/*Let d m p d ˆ bethednewdocumentsthatshouldbe addedtotheexistingdocumentattherightoftheoldpath documentmatrix.*/
Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056 Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
are compared. For each example, k = 120, where k is the number of singular values and corresponding left and right singular vectors computed, and p = 10; when the folding up methodhas folded in documents equal to 10% of the initial path document matrix, the thin SVD is updated, and then folding in resumes until the number of new documents folded in reaches 10% of the updated matrix,andsoon.
ThefollowingfiveDTDsweredownloadedfromACM’s SIGMODRecordhomepage[17]:300XMLdocumentsfrom OrdinaryIssuePage.dtd (O in short), ProceedingsPage1999.dtd (P 1999 in short), ProceedingsPage2002.dtd (P 2002 in short), IndexTerm1999.dtd (IT 1999 in short), Ordinary2002.dtd (Ord 2002 in short) and Ordinary2005.dtd (Ord 2005 in short). For another real data set we used the documents on ADC/NASA [18]:150 XML documents from adml.dtd (Astronomical Dataset Markup Language DTD). Also we download the nigara data [18]: 150 XML documents from movie.dtd, department.dtd, club.dtd, and personnel.dtd. Based upon these sets of XML documents with their precision for four methods, re computing, folding updating, updating, and folding in, were computed, analyzedandreportedasfollows.
Examples for this paper are run using Rstudio/R i386 4.1.2 on a Window 10. These results are produced using therealsetsoftheXMLdocuments. Baseduponthesesets ofXML documentswithdynamicupdatingcharacteristics, their accuracy of information retrieval were computed, analyzed and reported as follows. The measure of similarityisthecosineoftheanglebetweenthequeryand document vectors. The path document matrix DPESSW is partitionedsuchthatthefirst200columnsformtheinitial matrix, and the remaining 600 columns are added incrementally. In eachexample,theaverageprecision for each of the queries at the eleven standard recall levels (0%, 10%, . . . , 100%) is averaged to produce the overall average precision at each increment. The average precisions for the four methods discussed in this paper (re computing, folding updating, updating,andfolding in)
In the first example (see Figure 5), the initial path document matrix of 862 terms and 200 documents has 600 documents added to it in 60 increments of 10 documents each, simulating a dynamic environment in which frequent small changes are made to the path document matrix. Note that the initial matrix more than doublesinsizeasaresultoftheincrementaladditions.As expected,Figure5indicatesthattheaverageprecisionfor thefolding inmethoddeterioratesrapidlycomparedwith theothermethods.Theaverageprecisionfortheupdating method does not deteriorate until the initial matrix has approximately doubled in size,andthen thedeterioration is very slight. The folding up method gives similar results to re computing the thin SVD at every increment, but as Table 2 illustrates, in this example the folding up method is more than 400 times faster than re computing. The folding up method gives even better results than the updating method for much of Figure 5 and yet, in this example, it is more than three times faster than the updatingmethod.
In the second example (see Figure 6), the initial path documentmatrixwith862termsand200documentsonce againhas600documentsaddedtoit,butinthiscasethere are 30 increments of 20 documents each. As in the first example, this simulates a dynamic environment in which thepath documentmatrixisenlargedfrequently.Asinthe previous example, Figure 6 shows that the average precision for the folding in method deteriorates rapidly comparedtotheothermethods. Inthis exampleboththe
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
updating method and the folding updating method give similar results when compared to the method of re computing at each increment, but the updating method is more than 120 times faster than re computing, and the folding up method is more than 200 times faster than re computing.
Table2:CPUtimes(seconds):600documentsaddedin10 and20. Method CPUtime CPUtime Incrementsof60 Incrementsof30 Recomputing Folding update Updating Folding
Average Precision
Average Precision
2537.84 6.25 19.63 0.61
The experiment result is two fold. First, we have demonstratedthattheupdatingmethodsproposedbyZha and Simon [4] are effective in a dynamic environment in which there are many small updates made to the path document matrix. This method of updating the thin SVD achieves similar average precision to re computing the thin SVD, using only a fraction of the computation time. Thisinitselfissignificant,butwehavealsodemonstrated that our new hybrid method, folding updating, is an even more attractive option than updating alone. As with the updating method, the new folding updating method achievesaverageprecisionsimilartothatofre computing the thin SVD, but the folding up method requires less computation time than either re computing or updating the thin SVD. Next research issue will go through the efficient indexing method such as the R tree in order to efficientlysearchinterestingdocumentsbyuser’srequest.
0.6
0.55
0.5
0.45
1341.55 6.05 10.66 0.34 0.3
[1] S. C. Deerwester, S. T. Dumais, T. K. Landauer, G. W. Furnas, and R. A. Harshman, Indexing by latent semantic analysis. Journal of the American Society of InformationScience,41(6):391 407,1990.
0.4
0.35
0.65 200 300 400 500 600 700 800 900 NumberofDocuments
[2] M. W. Berry, S. T. Dumais, and T. A. Letsche. Computational methods for intelligent information access, 1995. Presented at the Proceedings of Supercomputing.
[3] M. W. Berry, S. T. Dumais, and G. W. O’Brien, Using linear algebra for intelligent information retrieval. SIAMRev.,37(4):573 595,1995.
[4]H.ZhaandH.D.Simon,Onupdatingproblemsinlatent semantic indexing. SIAM J. Sci. Comput., 21(2):782 791,1999.
0.6
0.55
0.5
0.45
0.4
0.35
Recompution Folding-UP Updating Folding-in FFigure5:Averageprecisionsforfourmethodsusing DPESSW:600documentsaddedin60incrementsof10. 0.3
0.65 200 300 400 500 600 700 800 900 NumberofDocuments
Recompution Folding-UP Updating Folding-in
[5] G.W. O’Brien. Information tools for updating an SVD encoded indexing scheme, 1994, Master’s Thesis, The UniversityofKnoxville,Tennessee.
[6] Berry M.W. and Dumasis S.T. (1995): Using linear algebra for intelligent information retrieval SIAM Rev.,Vol.37,No.4,pp.573 995.
[7]BerryM.W.,DrmacZ.andJessupE.R.(1999): Matrices, vectorspaces,andinformationretrieval. SIAMRev., Vol.41,No.2,pp.335 362.
[8]GaoJ.andZhangJ.(2005): ClusteredSVDstrategiesin latent semantic indexing Inf. Process. Manag., Vol. 41,No.5,pp.1051 1063.
Figure6:AverageprecisionsforfourmethodsusingDPESSW: 600documentsadd
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
[9] Ye Y.Q. (2000): Comparing matrix methods in text based information retrieval. Tech. Rep., School of MathematicalSciences,PekingUniversity.
[10]GaoJ.andZhangJ.(2005):ClusteredSVDstrategiesin latent semantic indexing Inf. Process. Manag., Vol. 41,No.5,pp.1051 1063.
[11] Landauer T.K., Foltz P.W. and Laham D. (1998): Introductiontolatentsemanticanalysis Discourse Processes,Vol.25,pp.259 284.
[12]BalinskiJ.andDanilowiczC.(2005): Rankingmethod based on inter document distances Inf. Process. Manag.,Vol.41,No.4,pp.759 775.
[13] Berry M.W. and Shakhina A.P. (2005): Computing sparse reduced rank approximation to sparse matrices ACM Trans. Math. Software, 2005, Vol. 31,No.2,pp.252 269.
[14]GaoJ.andZhangJ.(2005):ClusteredSVDstrategiesin latent semantic indexing. Inf. Process. Manag., Vol. 41,No.5,pp.1051 1063.
[15] Bass D. and Behrens C. (2003): Distributed LSI: Scalable concept based information retrieval with high semantic resolution Proc. 2003 Text Mining Workshop,SanFrancisco,CA,USA,pp.72 82.
[16] Fan J., Ravi K., Littman M.L. and Santosh V. (1999): Efficient singular value decomposition via document samplings Tech. Rep. CS 1999 5, Dept. Computer Science,DukeUniversity,NorthCarolina.
[17] ACM SIGMOD Record home page [http://www.acm.org/sigmod/record/xml]
[18]http://www.cs.wisc.edu/niagara/data/
1’st
Athor Photo
Hsu Kuang Chang He is associative professor in the Department of Information Engineering, I Shou University, Taiwan. His research interests include data mining, multimedia media database, and informationretrieval.
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
