International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
1,2,3BTech CSE, Vellore Institute of Technology, Vellore. 4Associate Professor, Dept of IoT, VIT, Vellore. ***
Abstract Sign Language Recognition, SLR, is an important and promising tool for assisting hearing impairedpersonsincommunicating.Thegoalofthisworkis to develop an efficient solution to the sign language recognition problem. This study uses deep neural networks to create a sign language recognition framework that directlytranscribesfilmsofSLsignalstoEnglishandspeech.
Previous techniques for SL recognition have often used hidden Markov models which is not very efficient for sequence modeling that involves temporal analysis. Convolutional Neural Networks, CNN, are used for spatial characteristics, and Recurrent Neural Networks, RNN, are usedfortemporalanalysis.
Key Words: Sign Language(SL), Gesture Recognition, Convolutional Neural Network(CNN), Recurrent Neural Network(RNN), Transfer Learning, Spatial Features, TemporalFeatures.
According to the World Health Organization(WHO), more than five percent of humans suffer from hearing impairment.Signlanguage(SL)isalanguagethatisusedto communicate with the help of hands and expression by making hand movements, and it is often used to communicate with hearing or speech impaired people. sign language is often regarded as one of the best grammatically structured languages which is very easy to learn. Because of this reason, SL recognition is a good study subject for creating algorithms to handle problems like Gesture Recognition, Sequence Modelling, and user interface design, and it has received a lot of interest in multimediaandcomputervision.Takeinputfromtheuser intheformofavideowheretheuserwearsgreenandred coloured gloves on their left and right hand respectively. Use Convolutional Neural Networks (CNN) to get the spatial features of the hand to feed them to the RNN. Use Recurrent Neural Networks (RNN) to analyze the hand movements to recognize the sign in the video given as input. Convert the recognized sign from RNN to text and speech.
There have been many methods used to tackle Gesture recognition problems. Some used RNN with Long Short Term Memory(LSTM) to train the model, choosing angles between the bones of fingers as training features to train the neural network[4]. To acquire the hand features they used a Leap Motion Controller (LMC) sensor with the support of infrared light, which can track the hand movementswithhighprecisionbutusingtheLMCisnota feasible solution. [3] To determine the boundary between eachsign,Reinforcementlearninghasbeenusedtodivide the signs in the video. Weakly supervised Learning has been used for training. The first stage's output is utilized as the second stage's input. [2] Used CNN to detect and extract features like the hand, and face details and also both hands have been taken into consideration. used Bi LSTM for temporal analysis which is not required as it is not very necessary for sign language because future signs will not decide the probability of the present sign. [1] Inspired by the Automatic speech recognition, they used Transition action modeling for segmentation of signs in the video, so they can be classified just like in isolated video format, but transitions can be very indefinite and subtle, so finding transitions can be ambiguous using the proposedapproach.Soinaccuratesegmentationleadstoa significantloss.
Earlierwehave seen[17] [19]usinghardware supported devices to extract the spatial features, but of late many newdeeplearningapproacheshasbeencametolightwith high accuracy and efficiency for gesture recognition [11],[20],[21]. It shows that CNN is one of the best approaches to extract the features than using Hardware devices which is costly and not feasible. for Video based signlanguage recognition,therearetwo problems todeal with, one is spatial features and another one is temporal analysis. Many popular architectures of CNN like ResNet, Inception v3, AlexNet, GoogleNet etc., [22] [25] are very good at extracting features from any given image as they havebeentrainedonimagestoagreaterextentwithvery largedatasets.2D CNNand3D CNNarebecomingpopular techniques to use for video classification problems like gestureanalysis[27][28],determiningtheperson[29]and
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
describing and captioning the video tasks [30]. 3d CNN has also performed well both for space and time series analysis with high efficiency [20], [31] [34]. To do the temporal analysis, Recurrent Neural Networks have been widelyused.[21]useda heapedversionofconvolution to distinguish the boundaries between signs of continuous Sign Language. Some used the combination of various deep learning concepts [10], [26] for temporal feature analysis.
For sequential data, Recurrent Neural Network has been using a lot these days, Earlier Hidden Markov Model used tobetheoneusedforthiskindofactivities.butnow RNN has been very impressive with the data that has time series attached to it. two types of RNN, LSTM[37] and GRU[38] are being used in many time series related tasks like speech recognition[35], Forecasting problems, Prediction problems that have sequential figures, neural machine translation[36], sign language translation[40][12] etc., because they help in solving the problems that basic RNN cell does. basic RNN does not have the memory to withhold the memory of previous datafromthatisfromlongback.Anarchitecture,thathas encryption that will get the subject of the signs and decryption that will give the final result, has also done very good with SL recognition. Many hybrid versions of different architectures of RNN, CNN, 3D CNN, and CTC have been used to make these SL detection problems and sequentialmodellingrelatedtasks[6],[10],[16].
Usually, we use image classification for sign language but itwon'tworkforallthesigns,sothereisnoscalabilityfor new signs that take motion to perform. And for video classification, some hardware is used to capture the hand spatial features to find the sign, but it requires extra hardwaretouseandisalsonotveryaccurateaswell.

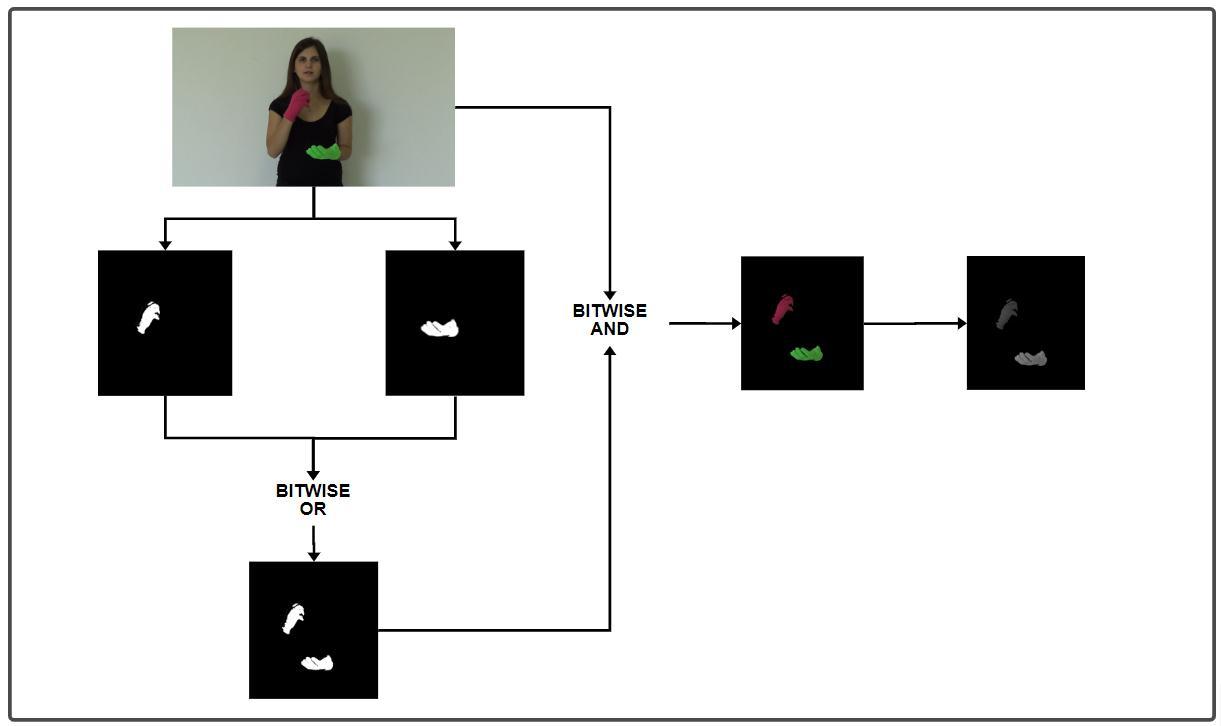
Colour segmentation is used to segment specific colours from anygivenframe or image.The requiredcolour RGB values range will be considered and pixels out of that region will be blacked out. Pixels in the range will be extracted.Weusedcoloursegmentationto extractfistsof thehands.Theuserwearscolouredglovesforbothhands with different colours. We extract red and green colours from the frames and merge them into one frame where we can extract only hands from the image or frame. Figure 1showstheuserwearingglovesandperforminga sign facing the camera. In Figure 2, we can see that the hands of the user have been extracted using colour

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
The Frame ‘F’ from the video is taken and Both colours from the hands will get extracted separately, say H1 and H2. Both H1 and H2 will be merged by doing Bitwise OR operation after which we get F2., which then will be multiplied with the original image F to get a coloured image of hands (COL_FRAME) and then be converted to grayscaleimage(GRAY_IMG) F=>H1 F=>H2 (H1+H2)=>F2 (F2ANDF)=> COL_FRAME COL_FRAME=>GRAY_IMG
Convolutional Neural Networks are a kind of neural network used in classification processes and computer visionproblems.UsingabasicNeuralNetworkonimages will not be compatible because an Image consists of numerous pixels, so we convolute them with convolutional filters in CNN. Using CNN we can extract spatial features from the image. CNN uses a special technique called convolution, where convolutional filters are applied to get various features of an image. In this paper,weusedittogethandspatialfeatures.Weusedthe transfer learning concept to train the frames using the Inception V3 model. wehavetakenthe ImageNet dataset trained weights for the model. We have used the Inception V3 model because it requires less computational
powerandalsokeepstheperformancehigh.Theaccuracy of the trained CNN model was 95% after testing on around85000images.
RNN ( Recurrent Neural Network )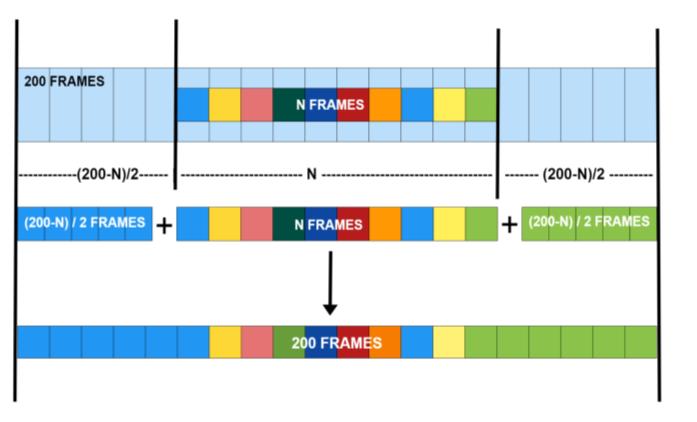
RNNs,orRecurrentNeuralNetworks,areatypeofNeural Network that has memory and is used to evaluate time relateddata,alsoknownasSequentialData.RNNisatype of neural network that is used in voice recognition systems like Apple's Siri and Google's voice search. Usually, Basic RNN does not do well with sequences that requirememory.So,Topredictthesigngivenasequence of frames, we employed the Long Short Term Memory (LSTM) Model which is a kind of RNN that has memory. TheLSA64dataset,anArgentinianSignLanguagedataset,
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
wasusedtotrainfor63words.WeutilizedRNNtoassess the series of spatial features acquired from the CNN model because it is often used for sequential data. we have given obtained spatial features from CNN to RNN Model,whereinputisof200length.sowedivideavideo into200frames,agiveittotheLSTMmodelwecreated. So,inordertogiveaninputofaspecificlengthweneedto pad videos that are smaller in length. so we used a functiontopadthevideothatissmallerinsize.wedivide a video into 200 frames if the video is larger in size. we padframesbytakingfirstandlastframesofthevideoand fill both ends of the video with respective frames evenly tomakeitof200length.
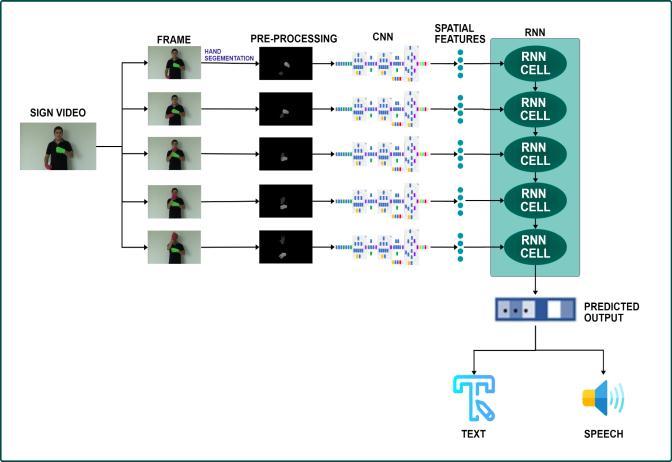
The architecture provides the complete process of the model from beginning to end. Figure 5 shows the entire architecture of the system. We start by taking video and dividethemintoframes.
CNN model we trained will be given all the frames of the video, the CNN model will output the spatial features which are in the form array. The arrays will then be padded to 200 arrays if the video is short. All the arrays willbegiventotheLSTMmodel.Bytakingspatialfeatures and by doing the temporal analysis of those frames, the LSTMmodelwillpredictthesigngiveninthegivenvideo. The resulted output from LSTM will be converted to text andspeechwillbepresentedtotheuser.
The proposed system was put to the test and found to be effectiveandfeasible.Theperformanceofthetwomodels hasbeentestedseparatelyandcombined.TheCNNmodel which we trained on around 320000 images has been tested on 80000 images, the accuracy of the CNN was 94.91%. theaccuracyoftheRNNmodelwhentestedgave 97.22%. when the combined model was tested on 10 images per video which is exactly 630 videos, 588 videos out of those 630 videos have correctly predicted the sign in the video which is around 94%. Figure 6 shows the number of correctly predicted outputs per 10 videos for everysigninthedataset.
We presented a Deep learning model, which is based on computer vision, that can recognise sign language and present it to the user with text and sound form. Rather than utilising image classification to solve sign language recognition, we approached it as a video classification problem. For this video classification problem, we used a combination of CNN and RNN models which is very efficient with an accuracy of around 94%. This can be expanded to other areas of gesture recognition as it is
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
providinghigherperformance.Thiscannotonlyrecognise sign language, but also other gestures which can be used inotheractivities.
We can extend the system to recognise continuous sign language where multiple signs can be detected using single video. for that, a semantic=c boundary detection modelhastodevelopedtoseparatethesignsinthevideo and predict them separately. since the grammar is very much different from English, we can also use Natural Language Processing to convert Sign language to English withitsgrammar.
We express our sincere gratitude to our guide, Associate Professor Dr. Narayanamoorthy M, Dept of IoT, Vellore Institute of Technology, Vellore for suggestions and supportduringeverystageofthiswork.
[1]Kehuang Li, Zhengyu Zhou, Chin Hui Lee; Sign TransitionModelingandaScalableSolutiontoContinuous SignLanguageRecognitionforReal WorldApplications
[2]Multi Information Spatial Temporal LSTM Fusion ContinuousSignLanguageNeuralMachineTranslation
[3]Chengcheng Wei; Jian Zhao; Wengang Zhou; Houqiang Li, Semantic Boundary Detection With Reinforcement LearningforContinuousSignLanguageRecognition
[4]D. Avola, M. Bernardi, L. Cinque, G. L. Foresti, and C. Massaroni, ‘‘Exploiting recurrent neural networks and leapmotioncontrollerfortherecognitionofsignlanguage andsemaphorichandgestures.’’
[5]O. Koller, H. Ney, and R. Bowden, “Deep hand: How to train a CNN on 1 million hand images when your data is continuousandweaklylabelled,”
[6]N. C. Camgöz, S. Hadfield, O. Koller, and R. Bowden, “Subunets: Endto end hand shape and continuous sign languagerecognition,”
[7]A Chinese sign language recognition system based on SOFM/SRN/HMM
[8]Subunit sign modelling framework for continuous sign languagerecognition
[10]R.Cui,H. Liu,andC. Zhang,“Recurrentconvolutional neural networksforcontinuous signlanguagerecognition bystagedoptimization,”
[11] O. Koller, S. Zargaran, and H. Ney, “Re Sign: Re aligned end to end sequence modelling with deep recurrentCNN HMMs,”
[12]O.Koller,C.Camgoz,H.Ney,andR.Bowden,“Weakly supervised learning with multi stream CNN LSTM HMMs todiscoversequentialparallelisminsignlanguagevideos,”
[13] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neuralnetworks,”
[16]R.Cui,H.Liu,andC.Zhang,“Adeepneuralframework for continuous sign language recognition by iterative training,”
[17] T. Starner, J. Weaver, and A. Pentland, “Real time American sign language recognition using desk and wearablecomputerbasedvideo,”
[18]N.Habili,C.C.Lim,andA.Moini,“Segmentationofthe face andhands in sign language video sequences using colorandmotioncues,”
[19] L. C. Wang, R. Wang, D. H. Kong, and B. C. Yin, “Similarity assessment model for chinese sign language videos,”
[21] S. Wang, D. Guo, W. G. Zhou, Z. J. Zha, and M. Wang, “Connectionist temporal fusion for sign language translation,”
[22] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,”
[23] K. Simonyan and A. Zisserman, “Very deep convolutionalnetworksforlarge scaleimagerecognition,”
[24]C.Szegedyetal.,“Goingdeeperwithconvolutions,”
[25] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learningforimagerecognition,”
[26] L. Pigou, A. van den Oord, S. Dieleman, M. Van Herreweghe, and J. Dambre, “Beyond temporal pooling: Recurrence and temporal convolutions for gesture recognitioninvideo,”
[27] S. Ji, W. Xu, M. Yang, and K. Yu, “3D convolutional neuralnetworksforhumanactionrecognition,”
[28] J. Carreira and A. Zisserman, “Quo vadis, action recognition?Anewmodelandthekineticsdataset,”
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
[29] J. Li, S. Zhang, and T. Huang, “Multi scale 3D convolution network for video based person re identification,”
[30] S. Chen, J. Chen, Q. Jin, and A. Hauptmann, “Video captioningwithguidanceofmultimodallatenttopics,”
[31] J. Huang, W. Zhou, H. Li, and W. Li, “Sign language recognitionusing3Dconvolutionalneuralnetworks,”
[32]P.Molchanov,X.Yang,S.Gupta,K.Kim,S.Tyree,andJ. Kautz, “Online detection and classification of dynamic hand gestures with recurrent 3D convolutional neural networks,”
[33] Z. Liu, X. Chai, Z. Liu, and X. Chen, “ ous gesture recognitionwithhand orientedspatiotemporalfeature,”
[34] D. Guo, W. Zhou, A. Li, H. Li, and M. Wang, “Hierarchical recurrent deep fusion using adaptive clip summarizationforsignlanguagetranslation,”
[34] D. Guo, W. Zhou, A. Li, H. Li, and M. Wang, “Hierarchical recurrent deep fusion using adaptive clip summarizationforsignlanguagetranslation,”
[35] A. Graves, A. R. Mohamed, and G. Hinton, “Speech recognitionwithdeeprecurrentneuralnetworks,”
[36] Y. Wu et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,”
[37] S. Hochreiter and J. Schmidhuber, “Long short term memory,”
[38] K. Cho et al., “Learning phrase representations using RNNencoderdecoderforstatisticalmachinetranslation,”
[39] D. Guo, W. Zhou, H. Li, and M. Wang, “Hierarchical lstmforsignlanguagetranslation,”
[40] N. C. Camgoz, S. Hadfield, O. Koller, H. Ney, and R. Bowden,“Neuralsignlanguagetranslation,”