
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
DHWANI- THE VOICE OF DEAF AND MUTE
Amarthya Vishnu V1, Amrita Sree S2 , Blessy Geevarghese3 , Jessline Elezabeth Jacob4 , Er. Gokulnath G 5
1,2,3,4 B. Tech Student, Dept. of Computer Science and Engineering, Saintgits College of Engineering, Kerala, India 5 Assistant Professor, Dept. of Computer Science and Engineering, Saintgits College of Engineering, Kerala, India ***
Abstract - Humanbeingswiththeabilitytosee,hear,and speakareoneofGod'smostmagnificentcreations.However, some people do not have access to this precious benefit. Deaf mute people are most affected since, speech is the primarymediumofcommunicationthatallowsindividuals to exchange information, ideas, and expressions in both verbal and nonverbal ways. A hand gesture recognition system for deaf persons is used to communicate their thoughts to others. Folks have a hard time to understand what these people are saying since they utilize sign languagestoconnectwiththerestoftheworld.Asaresult, thisinitiativemakesuseofgesturesthatareanintegralpart of such people's lives and converts them into words. The communicationhappenswhenothersareabletounderstand and respond to one's message. This method bridges the communication gap between deaf mute people and the generalpublic,allowingforamoreproductivedialogue.This artificially intelligent system uses Kera's as a platform for converting gestures taken in real time via camera and trained using a convolutional neural network (CNN) are convertedintotextasoutput.
Key Words: CNN, Hand Gesture, ReLU, deaf muteCHAPTER 1
INTRODUCTION
KittyO’NeilwasanAmericanstuntwomanandspeedracer, mostfamousinthe1970s.Shewasdeafandmute.Butshe was known as ‘the fastest woman in the world. She conqueredtheworldwithouthearingandspeaking.Shewas trulyaninspirationformanyofthedeafandmutepeople. Butinthiscurrentscenario,sincealmosteverythingisgoing online,peoplewithspeechandhearingdisabilitiesarenot abletocommunicatenormallyandconveytheirthoughtsto others. Sign language is used by deaf and hard hearing people to exchange information between their own communityandwithotherpeople.So,inoursystem,welend a helping hand for the exceptional creation of God by providingthemaplatformonwhentheycancommunicate withothersnormallywithoutanydifficulty.Therearesome applications such as hand gesture technology which can detectsignlanguageandconvertittohumanlanguage.But theseapplicationsneedtobeinstalledinthesystemwhich they are using, which is not very easy. Server creating a uniformly usable plugin that can be used in any of the
applicationswiththehelpofGoogle.Itismucheasierand less costly. The scope of this sign language detector is to expandtootherapplicationssuchaszoom,teams,etc.
1.1 GENERAL BACKGROUND
Theprojectisabouthelpingthedeafandmutepeopleinthe country to work easily on the system, with the help of gestures.Itincludesstaticaswell asdynamicgesturesfor the working of this system. Here machine learning, deep learning and image processing concepts are incorporated. The fundamental point of building a sign language acknowledgment is to make a characteristic collaboration amonghumansandcomputer.Motionscanbestatic(poseor certainposture)whichrequirelesscomputationalintricacy or dynamic (grouping of stances) which are more complicatedhoweverreasonableforconstantconditions.
1.2 RELEVANCE
Peopleusegestureslikenoddingandwavingthroughout their daily lives without even noticing it. It has become a majorfeatureofhumancommunication.Newapproachesof humancomputerinteraction(HCI)havebeendevelopedin recent years. Some of them are based on human machine connectionviathehand,head,facialexpressions,voice,and touch, and many are still being researched. The problem occurs when sign language is studied by self learning method. Having the ability to sense gesture based communicationisanintriguingcomputer visionissue,but it's also incredibly useful for deaf mute individuals to communicate with people who don't understand sign language.Thisprojectismostlyfocusedondeafandmute people, who find it difficult to communicate with others. Sincethesignspresentedbythesepersonsarenotseenby regularpeople,themeaningofmotionswillbedisplayedas text and this text will be transformed into dialogue. This allows deaf and mute people to communicate much more successfully. The proposed system provides a motion acknowledgement, which differs from commonly used frameworks in that it is obviously difficult for the visibly unable to deal with. Here, users can work the framework withthehelpofmotionswhileremaininginasafedistance fromthecomputerandwithouttheneedtousethemouse
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
1.3 Socio Economic Importance
Theprojectismainlyfocusedonasociallyrelevantissuefor oursociety'sdeafandmutepeople.Theprojectaimstomake iteasierforthedeafandmutecommunitytointeractwith othersbycapturingmotionswiththehelpofawebcamand displayingtheresultingmessageonthescreen,whichthen generates text, making it much easier for them to connect withothers.
1.4 Applications
Thissystemisusedinwebinarsforinteractingwith deafandmutepeople.
characteristics from raw video streams without any prior knowledge,reducingtheneedtobuildfeaturesareoffered. Multi channels of video streams, including colour information,depthclues,andbodyjointlocations,areused as input to the 3D CNN to integrate colour, depth, and trajectoryinformationinordertoimproveperformance.On arealdatasetacquiredwithMicrosoftKinect,theproposed model is validated and is shown that it outperforms the previousapproachesbasedonhand craftedfeatures.
Thissystemisusedtotrainmutepeople.
This system can be used in live classes for interactingwithdeafandmutepeople.
1.5 Advantages
Thisprojectdealswithprovidingeasinesstothe dumbtocommunicatewithpeopleusinggestures whichwillbecapturedbythewebcamandthe resultantmessagebeingdisplayedonthescreen, whichgivesitmuchmoreeasinessforthedeaf mutepeopletocommunicatewithothers.
Thissystemisaplugin.So,thereisnoneedofan externalapplication.
Itneedsonlylessstoragespace.
CHAPTER 2
LITERATURE SURVEY AND EXISTING SYSTEMS
Inthischapter,theliteraturereviewandexistingsystems relatedtoourprojectwillbecovered
2.1 LITERATURE SURVEY
Sign Language Recognition using 3D convolutional neural networks [1]. Jie Huang University of Science and TechnologyofChina,Hefei,China;WengangZhou;Houqiang Li;WeipingLi.ThegoalofSignLanguageRecognition(SLR) istotranslatesignlanguageintotextorspeechinorderto improvecommunicationbetweendeaf mutepeopleandthe general public. Due to the complexity and significant variances in hand gestures, this activity has a wide social influence,butitisstilladifficultwork.ExistingSLRmethods rely on hand crafted characteristics to describe sign languagemotionandcreateclassificationmodelsbasedon them.However,designingreliablefeaturesthatadapttothe widerangeofhandmovementsisdifficult.Toaddressthis issue, a new 3D convolutional neural network (CNN) that automatically extracts discriminative spatial temporal
Factor value:
Real Time Sign Language Recognition Using a Consumer DepthCamera[2].AlinaKuznetsova;LauraLeal Taixe;Bodo Rosenhan. In the field of computer vision and human computerinteraction,gesturedetectionremainsadifficult job(HCI).Adecadeago,thechallengeappearedtobenearly impossible to complete using only data from a single RGB camera.Thereareadditionaldatasourcesavailabledueto recentimprovementsinsensingtechnologies,suchastime of flight and structured light cameras, which make hand gesturedetectionmorepractical.Itoffersa highlyprecise approach for recognizing static gestures from depth data providedbyoneofthesensorsspecifiedaboveinthispaper. Rotation,translation,andscaleinvariantcharacteristicsare derived from depth pictures. After that, a multi layered random forest (MLRF) is trained to categorize the feature vectors,resultinginhandsignrecognition.Whencompared to a simple random forest with equal precision, MLRF requiressubstantiallylesstrainingtimeandmemory.This makesitpossibletorepeattheMLRFtrainingmethodwith minimaleffort.Todemonstratethebenefitsofthismethod,it is tested on synthetic data, a publicly accessible dataset containing24AmericanSignLanguage(ASL)signals,anda new dataset gathered with the recently released Intel CreativeGestureCamera.
Indian sign language recognition using SVM [3]. Machine Vision Lab CSIRCEERI, Pilani, India J. L. Raheja; School of Instrumentation D.A.V.V. Indore, Pilani, India A. Mishra; Researcher, Pilani, India A. Chaudhary. People are always inspiredtocreatenewmethodstoengagewithmachinesby needs and new technologies. This interaction can be for a specific purpose or as a framework that can be used in a varietyofapplications.Signlanguagerecognitionisacritical fieldinwhicheaseofengagementwithhumansormachines willbenefitmanyindividuals.Atthemoment,Indiahas2.8 millionpeoplewhoareunabletotalkorhearcorrectly.This research focuses on Indian sign identification in real time using dynamic hand gesture recognition techniques. The acquiredvideowastransformedtoHSVcolorspaceforpre processing, and skin pixels were used for segmentation. Depth data was also used in parallel to provide more accurateresults.HuMomentsandmotiontrajectorieswere recoveredfromimageframes,andgestureswereclassified using a Support Vector Machine. The system was tested usingbothacameraandanMSKinect.Thistypeofdevice mightbeusefulforteachingandcommunicatingwithdeaf people.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Sign Language Recognition Using Convolutional Neural Networks[4].UniversityCollegeLondon LourdesAgapito; University of Lugano, Switzerland Michael M. Bronstein; TechnischeUniversitätDresden,Dresden,Germany Carsten Rother.TheDeafpopulationandthehearingmajorityhave anundeniablecommunicationchallenge.
Automatic sign language recognition innovations are attempting to break down this communication barrier. A recognition system based on the Microsoft Kinect, convolutionalneuralnetworks(CNNs),andGPUacceleration isthemainfocusofthecontribution.CNN'scanautomatethe processoffeaturebuildingratherthancreatingintricately handcrafted features. It has a high level of accuracy in recognizing 20 Italian gestures. With a cross validation accuracy of 91.7 percent, the predictive model may generalizetousersandenvironmentsthatwerenotpresent during training. In the ChaLearn 2014 Looking at People gesture spotting competition, the model have received a meanJaccardIndexof0.789.
Sign language recognition using wifi[5]. Ma, Y., Zhou, G., Wang,S.,Zhao,H.andJung,W.,2018.Signfi:Signlanguage recognition using wifi. Proceedings of the ACM on Interactive,Mobile,WearableandUbiquitousTechnologies, 2(1), pp.1 21. SignFi is a WiFi based gesture recognition system that is proposed. SignFi's input is Channel State Information (CSI) measured by WiFi packets, and the classificationmechanismisaConvolutionalNeuralNetwork (CNN). Existing WiFi based sign gesture detection algorithmshaveonlybeenevaluatedon25movementsusing handand/orfingergestures.SignFicanrecognise276sign gestureswithexcellentaccuracy,includinghead,arm,hand, and finger gestures. SignFi collects CSI measurements in ordertorecordwirelesssignalpropertiesofsigngestures. RawCSIdataarepre processedtoreducenoiseandretrieve CSI changes across subcarriers and sample times.For sign gesturecategorization,preprocessedCSImeasurementsare suppliedintoa9 layerCNN.
TheCSItracesarecollectedandtestedSignFiinthelaband athome.Thereare8,280gestureinstances,5,520fromthe lab and 2,760 from home, for a total of 276 sign motions. SignFi's average recognition accuracy for 5 fold cross validationutilisingCSItracesofoneuseris98.01percent, 98.91 percent, and 94.81 percent for the lab, home, and lab+home environments, respectively. In the lab, it also executestestswithCSItracesfromfivedistinctusers.For 7,500instancesof150signgesturesperformedby5distinct users,SignFi'saveragerecognitionaccuracyis86.66percent.
American Sign Language recognition using rf sensing [6]. SevgiZ.Gurbuz;AliCaferGurbuz;EvieA.Malaia;DarrinJ. Griffin;ChrisS.Crawford;MohammadMahbuburRahman; EmreKurtoglu;RidvanAksu;TrevorMacks;Robiulhossain Mdrafi;.Manyhuman computerinteractiontechnologiesare built for hearing people and rely on vocalised
value:
communication,thereforeusersofAmericanSignLanguage (ASL) in the Deaf community are unable to benefit from theseimprovements.Whilevideoorwearablegloveshave madesignificantprogressinASLdetection,theuseofvideo inhomeshasraisedprivacyproblems,andwearablegloves significantlyrestrictmovementandencroachon dailylife. Methods:TheuseofRFsensorsinHCIapplicationsforthe Deaf community is proposed in this paper. Regardless of lightingconditions,amulti frequencyRFsensornetworkis employed to provide non invasive, non contact measurementsofASLsigning.Timefrequencyanalysiswith the Short Time Fourier Transform reveals the distinctive patterns of motion contained in the RF data due to the micro Dopplereffect.Machinelearningisusedtoexamine thelinguisticfeaturesofRFASLdata(ML).Theinformation contentofASLsigningisproventobegreaterthanthatof otherupperbodyactionsseenindailylife,asevaluatedby fractalcomplexity.Thiscanbeutilizedtodistinguishdaily activities from signing, while RF data shows that non signers'imitationsigningis99percentdistinguishablefrom nativeASLsigning.Theclassificationof20nativeASLsigns is72.5percentaccuratethankstofeature levelintegrationof RF sensor network data. Implications: RF sensing can be utilizedtoinvestigatethedynamiclinguisticfeaturesofASL and to create Deaf centric smart environments for non invasive,remoteASLidentification.ASLdatathatisnatural, not imitation, should be used to test machine learning techniques.
CHAPTER 3
OBJECTIVES AND PROPOSED INNOVATION
Inthischapter,objectivesandproposedinnovationofour projectwillbediscussed
3.1 OBJECTIVES
In a number of computer applications, gestures offer an innovativeinteractionparadigm.Adeafandmuteperson’s thoughts are communicated to others via a sign language recognitionsystem.Themajorityofsuchindividualinteract withtheoutsideworldthroughsignlanguage,whichmakes itdifficultforotherstocomprehend.Deafandmutepeople are the most affected since speaking is the most common wayofcommunication.Thegoalofthisprojectistoemploya pluginthatallowsuserstointerpretdeafandmutepeople's signlanguage.
3.2Broad Objectives
Make a system allowing the deaf and mute to recognizehandgestures.
Theprimarygoalistotransformsignlanguagesinto text.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
3.3Specific Objectives
Gesture train design: The camera records each gesture,whichissubsequentlytaught.
Featureextraction: Applied togetcharacteristics that will aid in picture classification and recognition.
Gesture recognition: Every gesture made is recognized.
A. DatasetCreation
Fig4.2.1
Gesture to text translation: Display the result on thescreenwhenthemotionshavebeenrecognized.
CHAPTER 4
HYPOTHESIS, DESIGN AND METHODOLOGY
Inthischapterthehypothesis,designandmethodology abouttheprojectwillbecovered.
4.1HYPOTHESIS
Due to the challenges of vision based problems such as varyinglightingconditions,complexbackgrounds,andskin colordetection,efficienthandtrackingandsegmentationis thekeytosuccessinany gesturerecognition. Variation in human skin color variations required the robust developmentofanalgorithmforthenaturalinterface.For objectdetection,colorisahighlyusefuldescriptor
Fig4.11Architecture
4.2DESIGN
Thesystemisdividedinto3parts:
•DatasetCreation
•GestureTraining
•Gesture to Text
Design
This model will be having a live feed from the video cameraandeveryframethatdetectsahandintheROI (regionofinterest)createdwillbesavedinadirectory (heregesturedirectory)thatcontainstwofolderstrain andtest,eachofthe10folderscontainsimagescaptured using Sign_Language.py The creation of the dataset is done by using a live camera feed with the help of OpenCVandcreatinganROIthatisnothingbutthepart oftheframewhereitneedstodetectthehand inforthe gestures.TheredboxistheROIandthiswindowisfor getting the live camera feed from the webcam. To distinguish between the background and the foreground, the background's cumulative weighted averageiscomputedandremovedfromtheframesthat havesomeiteminfrontofthebackgroundthatmaybe recognizedasforeground.Calculatingtheaccumulated weightforcertainframes(herefor60frames)andthe accumulated average for the backdrop accomplishes this.
B. GestureTraining
It deals with training the gestures collected from the deaf muteindividuals.Thesystemtrainsthecaptured gestures using Convolutional Neural Network (CNN). Convolutional neural networks (CNN) have brought a revolutioninthecomputervisionarea.Italsoplaysan important role for generic feature extraction such as scene classification, object detection, semantic segmentation,imageretrieval,andimagecaption.
The convolution neural network contains three types of layers:
Convolution layers: The convolution layer is the corebuildingblockoftheCNN.Itcarriesthemain portionofthenetwork’scomputationalload.
Pooling layers: The pooling layer replaces the output of the network at certain locations by derivingasummarystatisticofthenearbyoutputs. This helps in reducing the spatial size of the representation, which decreases the required amountofcomputationandweights.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Full connection layers: Neurons in this layer have full connectivity with all neurons in the preceding and succeeding layer as seen in regular Fourier Convolutional Neural Network. This is why it can be computedasusualbyamatrixmultiplicationfollowed byabiaseffect.
Thesystememployedthirty twoconvolutionalfiltersof size 3x3 over a 200x200 picture with an activation functionReLu,followedbyMax Pooling.TheRectified LinearUnit,orReLu,isalinearactivationfunctionwith athresholdof0,whichmeansthemodelwilltakeless time to train or execute. The goal of employing Max Poolingistominimizethegeographicdimensionsofthe activation maps as well as the number of parameters employed in the network, lowering computational complexity.Followingthat,adropoutof0.5isemployed topreventthemodelfromoverfittingandtogenerate somepicturenoiseaugmentation.
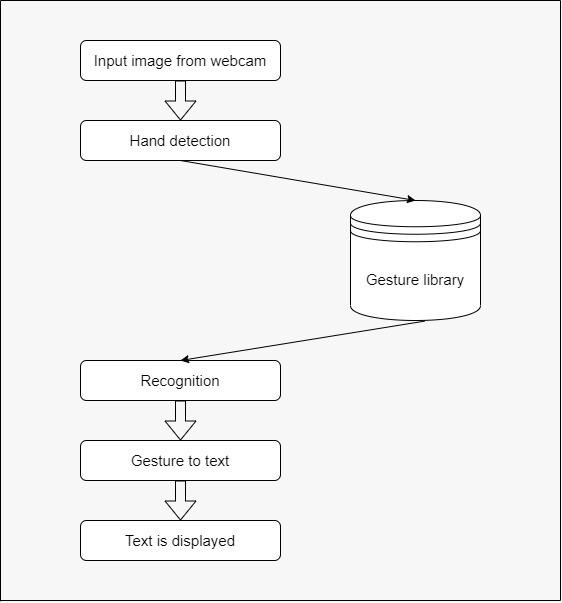
Fig4.23GesturetoText Flowchart
4.3 METHODOLOGY
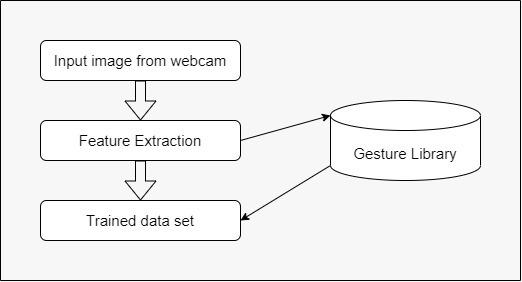
A. DATA COLLECTION: It is a process of capturing imageusingwebcamera.
Fig4.2.2GestureTraining
C. Gesture to Text
This phase is concerned with identifying motions andturningthemtotext.CroppingtheROIdetects thehand,whichisthencomparedtothemovements inthelexicon.Usinganofflinepythonpackage,the identified motions are translated to text. The traininggesturesarelaterrecognizedatthisphase. The movements are exhibited inside a region of interest(ROI)thathasbeenclipped.Ifthegesture shownbytheuserispresentinthedatabase,then therelevanttextmessageisshownonthescreen.
B. IMAGEPROCESSING:Thepicturesdeliveredarein RGBshadingspaces.Thehandmotionturnsoutto be harder to section dependent on skin tone. Therefore,weconvertthepicturestoHSVshading space. HSV is an integral asset for further developing picture security by isolating splendor fromchromaticity.
C. FEATURE EXTRACTION: After we have extricated the significant highlights, we can utilize include extractiontodecreasetheinformation.Itlikewise assists with keeping the classifier's precision and worksonitsintricacy.Bylesseningthepicturesize to64pixels,wehadtheoptiontogetanadequate numberofelementstoviablyordertheAmerican SignLanguagesignals.
D. CLASSIFICATION:Subsequenttodissectingtheinfo hand picture. The motion grouping strategy is utilizedtoperceivethesignalandafterwardcreate thevoicemessageinalikemanner.
E. EVALUATION:The exhibitionoftheframework is evaluatedsubsequenttopreparing.
F. PREDICTION: Predicts contribution of client and showcasesresult.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
G. REALTIMEDETECTION:Acontinuousmotionthat is shown by the client is recognized by the framework.
H. DISPLAYING WORD SEQUENCE: The communicationthroughsigningischangedoverto wordandisshowninthechatbot.
CHAPTER 5
FUTURE SCOPE
Thefuturescopeofourprojectincludes:
Augmented Reality
The rear future is in the hands of Augmented Reality. People in public places can communicate using sign language easily with others by the integration of augmented reality to this. So the sign language the person is showing will be displayed in the space as words so communication will be easier without the usageofasystem.
Conversion of voice and text to sign language
In future work, proposed system's image processing part should be improved so that System would be capableofconvertingnormallanguagetosignlanguage. We will try to recognize signs which include motion. Moreover,wewillfocusonconvertingthesequenceof gesturesintowordandsentencesandthenconvertingit intothespeechwhichcanbeheard.
As a Translator
Asweall useGoogletranslatorfortranslating normal languages, with the help of artificial intelligence this plugin can be modified and used as a translator for translatingdifferenttypesofsignlanguages.
Music
Peoplewithspeechandhearingdisabilitycansingsong using this sign language system. There will be certain signs for musical notes. The person can show this particular musical note sign and the system will recognizethemusicalnotesandwillcombinethisina specific pattern and will be played correspondingly using Artificial intelligence and Machine learning techniqueswiththehelpofcomputervision
CHAPTER 6
CONCLUSION
Thissystemcanbeusedtoassistdeaf mutepeopletoconvey theirmessagestonormalpeoplewithouttheassistanceofan interpreter. In this undertaking work, communication through signing will be more useful for the simplicity of correspondence between quiet individuals and ordinary individuals.Theundertakingbasicallytargetslesseningthe hole of correspondence between quiet individuals and ordinary individuals. Here the strategy catches the quiet signsintodiscourse.Inthisframework,itbeatsthetroubles looked by quiet individuals and helps them in further developingtheirway.Theprojectedframeworkisextremely simpletoconveytoanyplacewhencontrastedwithexisting frameworks.Tohelpthequietindividuals,thelanguagegets changedoverintotextkindandontheadvancedshowcase screen, it will be shown. Who can't speak with ordinary individualsforexampletragicallychallengedindividualsthe frameworkisespeciallyuseful Theessentialelementofthe taskistheonethatwillbeappliedinlikemannerputsthat the recognizer of the signals might be an independent framework.
REFERENCES
[1] Kuznetsova, A., Leal Taixé, L. and Rosenhahn, B., 2013. Real timesignlanguagerecognitionusingaconsumerdepth camera.InProceedingsoftheIEEEinternationalconference oncomputervisionworkshops(pp.83 90).
[2] Kuznetsova, A., Leal Taixé, L. and Rosenhahn, B., 2013. Real timesignlanguagerecognitionusingaconsumerdepth camera.InProceedingsoftheIEEEinternationalconference oncomputervisionworkshops(pp.83 90).
[3] Raheja, J.L., Mishra, A. and Chaudhary, A., 2016. Indian sign language recognition using SVM. Pattern Recognition andImageAnalysis,26(2),pp.434 441.
[4]Pigou,L.,Dieleman,S.,Kindermans,P.J.andSchrauwen,B., 2014, September. Sign language recognition using convolutionalneuralnetworks.InEuropeanConferenceon ComputerVision(pp.572 578).Springer,Cham.
[5] Ma, Y., Zhou, G., Wang, S., Zhao, H. and Jung, W., 2018. Signfi:Signlanguagerecognitionusingwifi.Proceedingsof the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies,2(1),pp.1 21.
[6] Gurbuz, S.Z., Gurbuz, A.C., Malaia, E.A., Griffin, D.J., Crawford,C.S.,Rahman,M.M.,Kurtoglu,E.,Aksu,R.,Macks,T. and Mdrafi, R., 2020. American sign language recognition usingrfsensing.IEEESensorsJournal,21(3),pp.3763 3775.