International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
Ishika Sharma1 Shivjyoti Dalai2, Venktesh Tiwari3, Ishwari Singh 4, Seema Kharb5
1,2,3 Students, Computer Science Engineering, SRM University, Sonipat 4Asst. Professor, Dept. of Computer Science Engineering, SRM University, Haryana, 5Asst. Professor, Dept. of Computer Science Engineering, SRM University, Haryana, India ***
Abstract A method for 'Credit Card Fraud Detection' is created in this study. As the number of scammers grows every day. Credit cards are used for fraudulent transactions, and there are several sorts offraud. As a result, various techniques such as Logistic Regression, Random Forest, and Naive Bayes are utilized to tackle this problem. This transaction is evaluated individually, andwhateverworksbestiscarriedout. The primary purpose is to detect fraud by filtering the aforementioned strategies in order to achieve a better outcome.
Key Words: Credit Card, Fraud Detection, Random Forest, Naïve Bayes, Logistic Regression
Credit card fraud is a broad word for theft and fraud perpetratedusingorutilizingacreditcardatthemomentof payment.Thegoalmaybetobuysomethingwithoutpaying for it or withdraw money from an account without permission. Identity theft is often accompanied by credit cardfraud.AccordingtotheFederalTradeCommissionof theUnitedStates,therateofidentitytheftremainedsteady duringthemid 2000s,butitjumpedby21%in2008.Even though credit card fraud, the crime most people connect withIDtheft,felltoafractionoftotalIDtheftcomplaintsin 2000,roughly 10milliontransactions,oroneoutof every 1300, were fraudulent. In addition, 0.05 percent (5 out of 10,000) of all monthly active accounts were fake. Today, fraud detection systems keep track of a twelfth of one percentofalltransactionsperformed,resultinginbillionsof dollarsinlosses.Creditcardfraudisoneofthemostserious issues facing businesses today. However, to successfully detect fraud, it is necessary first to comprehend the processes of fraud execution. Fraudsters use a variety of methodstoperpetratecreditcardfraud.CreditCardFraudis described as "when an individual uses another person's creditcardforpersonalreasonswhilethecardownerand the card issuer are unaware that the card is being used." Theftoftheactualcardorthecriticaldatalinkedwiththe account, such as the card account number or other informationthatmustbegiventoamerchantduringavalid transaction, is where card fraud begins. Card numbers, usually the Primary Account Number (PAN), are often reproducedonthecard,andthedataisstoredinmachine readableformatonamagneticstripeonthereverse.
Thispartshould provide themethodandanalysisused in yourresearchproject.Usingkeywordsfromyourtitleinthe firstfewphrasesisasimpleandeffectivemethodtofollow.
Thedata gatheringphaseisthefirststepintheproject;this datasetcomprisesacollectionoftransactions,someofwhich arerealandothersarefraudulent.Thedata gatheringphase is the first step in the project; this dataset includes a collectionoftransactions,someofwhicharerealandothers thatarefraudulent.Thedata gatheringphaseisthefirststep in the project; this dataset comprises a collection of transactions, some of which are real and others are fraudulent.
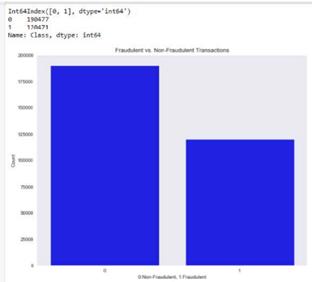
AcreditcardtransactiondatasetwasgatheredviaKaggle, anditcomprisesatotalof2,84,808creditcardtransactions fromaEuropeanbank.Itdividestransactionsinto"positive class" and "negative class." The data set is highly skewed, withroughly0.172percentoftransactionsbeingfraudulent andtheremainderbeinglegitimate;thisindicatesthatjust 492ofthe2,84,808transactionsarefraudulent,andtherest aregenuineones. So, weoversampledtobalance the data set,resultingin60%offraudtransactionsand40%genuine ones.
Selected data is formatted, cleaned, and sampled in this module.Thefollowingaresomeofthedatapre processing steps:
a)Formatting:Thechosendatamightnotbeinthecorrect format.Wemaypreferdatainafileformatoverarelational databaseorviceversa.
b)Cleaningistheprocessofremovingorcorrectingmissing data.Thedatasetmaycontainrecordsthatareincompleteor havenullvalues.Suchrecordsmustbedeleted.
c) Sampling: The class distribution in credit card transactionsisunevenbecausethenumberoffraudsinthe datasetisfewerthanthetotalnumberoftransactions.Asa
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
result, the sampling approach is utilized to tackle this problem.
The dataset is loaded after it has been pre processed. Variouslibraryfunctionscanbeusedtoloadthedataset.In thiscase,weusedthereadCSVmethodofPython'sPandas librarytoloadadatasetinCSVorMicrosoftExcelformat;in terms of python, it is called a DATAFRAME. dataset = pd.read_csv('creditcard.csv')
To compensate for the dataset's imbalance, weused the ADASYNoversamplingtechnique,whichoversamplesboth the number of fraudulent and genuine transactions to a specificnumber,resultinginapositiveandnegativerange that is nearly equal. After the dataset is oversampled, the samplesaresplitintoTrainandTestdata.Asuitableratiois tobeperformedforthemodel(Usually,70%forTraindata and30%forTestdataarechosen,anyonecanchoosetheir ration).Thetraindatasetcanbefurthersplitintotraindata andvalidationdata.
Afterthedatahasbeensplitintotrainandtestdatawhichis 70%and30%,respectively,thetrainingdataisnowutilized forthemodelbuilding.Thedatasetcontains31features,out of which 30 features or columns are the independent features,andthelastcolumncalledtheCLASScolumn,isthe dependent feature. So here, the dataset is split into four categories: xtrain, ytrain, xtest, and ytest, representing independenttrainingfeatures,dependenttrainingfeatures, independenttestfeatures,anddependenttestfeatures.
a) Logistic Regression Regressionisa regressionmodel thatanalysestherelationshipbetweenmultipleindependent variables and has a categorical dependent variable. There are many different logistic regression models, including binary,multiple, and binomial logistic models.TheBinary Logistic Regression model calculates the likelihood of a binaryresponsebasedononeormorepredictors
The above equation represents the logistic regression in mathematicalform
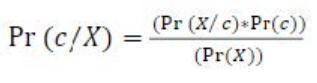
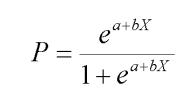
b) Random Forest RandomForestcanbeusedtorankthe importance of variables in a regression or classification problem in a natural way. Random forest is a tree based
algorithmthatcreatesseveraltreesandcombinestheresults toimprovethemodel'sgeneralizationability.Anensemble method is a technique for combining trees. Ensembling is nothingmorethanputtingtogetheragroupofweaklearners (individualtrees)tocreateastronglearner.RandomForests can be used to solve problems involving regression and classification. The dependent variable in regression problems is continuous. The dependent variable in classificationproblemsiscategorical.
c) Naïve Bayes ABayesianclassifierisastatisticalmethod thatusesBayes'theoremtocalculatetheprobabilitythata featurebelongstoaspecificclass.Itisreferredtoasnaive because it assumes that the possibilities of individual components are independent of one another, which is extremelyunlikelytooccurintherealworld.Theprobability of an event occurring is calculated by considering the likelihoodofanothereventoccurring.It'spossibletowriteit as:
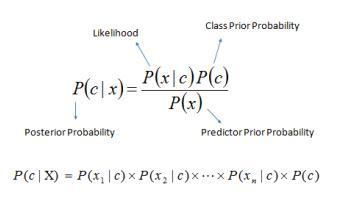
Where the posterior probability of target class c P(c|X) is calculatedfromP(c),P(X|c),andP(X).
After buildingthemodel,themodel istrainedusingTrain data and validation data. The model is trained using the libraryfunctionfit()function.
I.EvaluatingtheModelThemodelcanbeevaluatedbyusing variousmetrics.Theseare
a) Interpreting Loss and Validation loss Lossistheresult ofabadprediction.Alossisanumberindicatinghowbad themodel'spredictionwasonasingleexample.Losscanbe validationlossandtrainingloss.
b) Interpreting Accuracy and Validation Accuracy Validationaccuracyandaccuracyneedtobeconvergedina goodmodel.
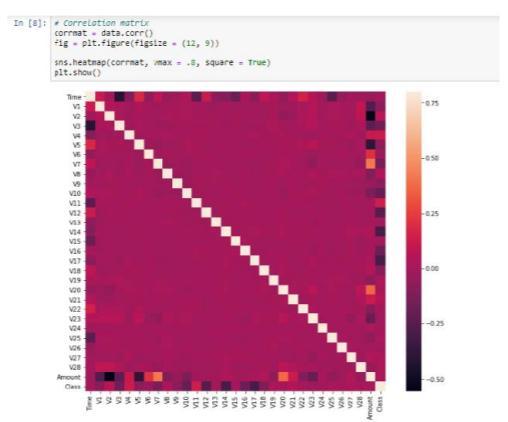
c) Confusion Matrix A confusion matrix summarizes classification problem prediction results. The correct and
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

incorrectpredictionsaretotaledandbrokendownbyclass usingcountvalues.Theconfusionmatrix'skeyisthis.The confusion matrix depicts the various ways in which your classification model becomes perplexed when making predictions. It reveals the number of errors made by a classifierandthetypesoferrorsmade.
used.IhaveusedthePicklelibraryandsavedthemodelsin .pklformat.
Here,
•Class 1: Positive
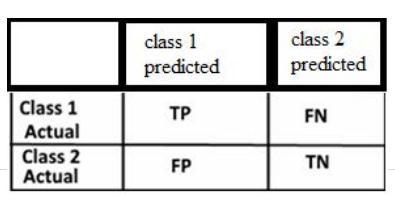
•Class 2: Negative Classification Rate/ Accuracy ClassificationRateorAccuracyisgivenbytherelation:
Recall Recallcanbedefinedastheratioofthetotalnumber ofcorrectlyclassifiedpositiveexamplesdividedbythetotal numberofpositiveexamples.HighRecallindicatestheclass iscorrectlyrecognized(asmallnumberofFN).
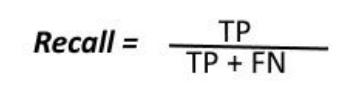
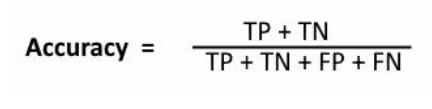
Fig 7- LogisticRegression
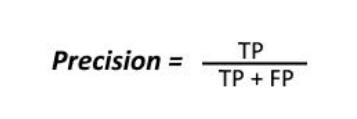
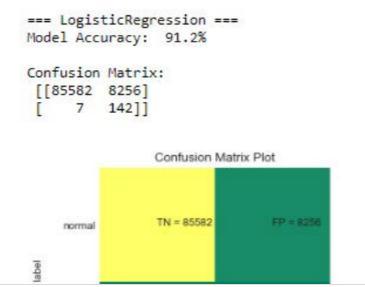
Fig 8 RandomForestClassifier
Precision To get the precision value, we divide the total numberofcorrectlyclassifiedpositiveexamplesbythetotal number of predicted positive examples. High precision indicatesthatanexamplelabeledaspositiveispositive(a smallnumberofFP).
Afterbuildingthemodel,themodelissavedtoourdevice. Themodelcanbesavedin.pklformator.h5format.Tosave themodelin.pklformat,pythonprovidesusalibrarynamed Pickle,andtosaveitin.h5format,theTensorflowlibraryis
Fig 9: NaïveBayesmodel
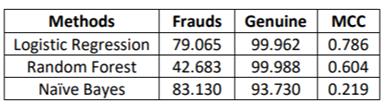
Theaccuracyresultswegotfromthethreealgorithmsare showninthefollowingtablebelow.
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal
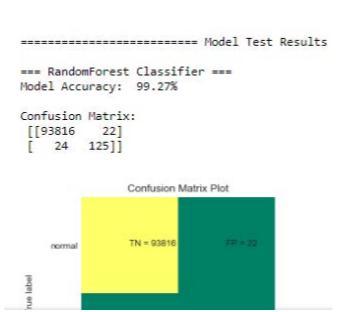
Variousmachinelearningalgorithmsfordetectingfraudin credit card transactions were reviewed in this paper. The accuracy, precision, and specificity metrics are used to evaluatetheperformanceofthistechnique.Toclassifythe transaction as fraudulent or authorized, I used three supervised learning techniques: Logistic Regression, Random Forest, and Naive Bayes. Using feedback and delayedsupervisedtraining,theseclassifiersweretrained onadelayedsupervisedsampledatasetofalmost284807 transaction records. Due to the massive imbalance, the datasetwassubjectedtoanOversamplingtechnique,which resulted in the number of fraud and normal transactions beingnearlyequal.Thetrainingandtestdata weretested usingthethreeModels,andtheresultswereobtained.The accuracy of the Random Forest, Logistic Regression, and NaiveBayeswas99.27%,91.20%,and89.40%,respectively. FromtheAboveproject,itcanbeconcludedthattheRandom Forest model is somewhat trustworthy, and its accuracy couldbeimprovedfurtherwithalargerandmorebalanced dataset.Ifsomeotheralgorithmscanbecombinedwiththis one to form a Hybrid Algorithm, the results will be even better.
The success and outcome of this project required a lot of guidance and assistance from many people, and we are highly privileged to have got this all along with the completionofourproject.Allthatwehavedoneisonlydue tosuchsupervisionandassistance,andwewillnotforgetto thankthem.
Weareextremelygratefulto Dr. Paramjit S. Jaswal, Vice Chancellor,SRMUniversity,and Dr. Puneet Goswami, Head of the Department, Department of Computer Science and Engineering,forprovidingalltherequiredresourcesforthe completionofmyseminar.
Ourheartfeltgratitudetoourguide Dr. Ishwari Singh,for their valuable suggestion and guidance in preparing the research paper. Last but not least, we would express our obligationtoallthepeoplewhohaveworkedextensivelyon thetopicandmakethecontentavailableforfreetoallthe aspiring people who want to grow in their community. I wouldsaythisreportcanbehelpfultoanyaspiringstudent who wants to gain an overall idea about how high performancecomputingworksinpracticallife.
[1] T. Mohana Priya, Dr. M. Punithavalli & Dr. R. Rajesh Kanna,MachineLearningAlgorithmforDevelopmentof EnhancedSupportVectorMachineTechniquetoPredict Stress, Global Journal of Computer Science and Technology:CSoftware&DataEngineering,Volume20, Issue2,No.2020,pp12 20
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | Jun 2022 www.irjet.net p ISSN: 2395 0072
[2] Ganesh Kumar and P.Vasanth Sena, “Novel Artificial Neural Networks and Logistic Approach for Detecting CreditCardDeceit,”InternationalJournalofComputer Science and Network Security, Vol. 15, issue 9, Sep. 2015,pp.222 234
[3] GyusooKimandSeulgiLee,“2014PaymentResearch”, BankofKorea,Vol.2015,No.1,Jan.2015.
[4] ChengweiLiu,YixiangChan,SyedHasnainAlamKazmi, Hao Fu, “Financial Fraud Detection Model: Based on RandomForest,”InternationalJournalofEconomicsand Finance,Vol.7,Issue.7,pp.178 188,2015.
[5] Hitesh D. Bambhava, Prof. Jayeshkumar Pitroda, Prof. Jaydev J. Bhavsar (2013), “A Comparative Study on Bamboo Scaffolding And Metal Scaffolding in Construction Industry Using Statistical Methods," International Journal of Engineering Trends and Technology (IJETT) Volume 4, Issue 6, June 2013, Pg.2330 2337.
[6] P. Ganesh Prabhu, D. Ambika, "Study on Behaviour of Workers in Construction Industry to Improve Production Efficiency," International Journal of Civil, Structural, Environmental and Infrastructure Engineering Research and Development (IJCSEIERD), Vol.3,Issue1,Mar2013,59 66
[7] Manideep, A. P. S., and Seema Kharb. "A Comparative AnalysisofMachineLearningPredictionTechniquesfor Crop Yield Prediction in India." Turkish Journal of Computer andMathematicsEducation(TURCOMAT) 13.2 (2022):120 133.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal