International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Nitin M B1, Anil Venkatraju N2, Preethi B3
1Nitin M B, Student, Dept. of CSE, BIET
2Anil Venkatraju N, Student, Dept. of CSE, BIET
3Preethi B, Asst. Professor, Dept. of CSE, BIET ***
Abstract - Diabetes mellitus is a very common and serious disease in many American Indian nations, as well as many other citizens of the world. Few known risk factors such as parental diabetes, genetic predisposition, overeating are considered to be the main risk factors for diabetes while the exact nature of genes or genes is unknown. The findings of this study may be used by health professionals, participants, students and researchers who are involved in research and development of diabetes predictors. We used the Random Forest Classifier algorithm to predict diabetes and later obtained a accuracyof0.903.
Key Words: AmericanIndianTribes,RandomForest.
Diabetes is a condition that occurs when your blood sugar, also called sugar, is too high. Blood sugar is your main source of energy and it comes from the food you eat. Insulin, a hormone produced by pancreas, helps glucoseinfoodtoenteryourcellsforenergy.Sometimes our bodies do not produce enough insulin. Glucose is in your blood and does not reach your cells. As we predict diabetes in pregnant womenand thistypeof diabetesis called Gestational diabetes. Most of the time this type of diabetes disappears once the baby is born. However, if you have ever had gestational diabetes, you are more likely to have type 2 diabetes later in life. Sometimes diabetesduringpregnancyistype2diabetes.
Early predictions of diabetes can be controlled to save lives. To get the best results, we test for diabetes prognosisbytakingavarietyoftraitsrelatedtodiabetes. We use the *Pima Indian Diabetes Dataset and use classificationstrategiesandusethesemethodstopredict diabetes. The purpose of this report is to look at a good diabetespredictormodelwithbetteraccuracy.
Machine Learning is a program of computer algorithms thatcanbelearnedfromthemodelbyself improvement without being explicitly coded by the programmer. Machine learning is part of Artificial Intelligence that integratesdataandmathematicaltoolstopredictoutput thatcanbeusedtocreatedata.
Success comes with the idea that the machine can read individually from the data (i.e., for example) in order to produce accurate results. Machine learning is closely related to data mining and speculative Bayesian model The machine receives data as input and uses an algorithmtogenerateresponses.
Typical machine learning activity is to provide recommendation. Google gives recommendations based on the persons browsing history and all these recommendations are based on the historical data. The data collected about past events and these events (browsing history).The data canbegeneratedmanually orautomatically.
Machinelearning is also used for a variety of tasks such as fraud detection, speculative care, portfolio optimization,automatedworkandmore.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Traditional systems are very different from machine learning.Intraditionalediting,theeditorcodeisallrules in consultation with an expert in the software industry. Each rule is based on a sound foundation; the machine willoutputtheoutputfollowingthelogicalstatement.As the system grows more complex, more rules should be written.Itcanquicklybecomeuncontrollabletocare.
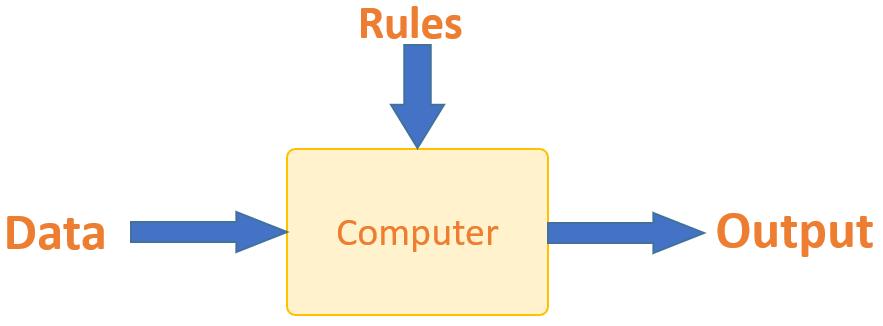
An approach to create artificial intelligence , here the computer algorithm is trained on input data which has beenlabelledforparticularoutput.
The model is trained till it detects the underlying patterns and relationships between input and output labelswhichleadstoobtainingaccuratelabellingresults wheninterpretedwithnever before seendata
Supervised learning performs good at classification and regression problems for predicting the volume of sales foragivenfuturedate.
A supervised learning is based on training. During trainingthesystemisfedwithlabelleddatasetswhichin turn instructs the system what output related to each specificvalue.
The trained model is presented with test data. The data which has been labelled and these labels are not disclosedtothealgorithm.
Theaimoftestingthedataistomeasurehowaccurately thealgorithmperformswellonunlabelleddata.
Machine learning should overcome this issue. The machine learns how inputs and outputs are related and writes the rule. Program planners do not need to write newruleseverytimethereisnewdata.Algorithmsadapt and respond to new data and information to improve efficiencyovertime.
Therearemanymachinelearningalgorithms.Thechoice of algorithm is based on purpose. In the machine learningexamplebelow,thetaskistopredictthetypeof floweramongthethreespecies.Predictionsarebasedon thelengthandwidthofthepetal.Thediagramshowsthe results of ten different algorithms. The image at the top left is a database. The data is divided into three categories: red, light blue and dark blue. There are certaincollections.Forexample,fromthesecondpicture, everything on the left is red, in the middle, there is a mixtureofuncertaintyandlightbluewhilethebottomis in the dark. Some images show different algorithms and howtheytrytoseparatedata.
Machine learning can be combined into two broad learningactivities:SupervisedandSupervised.
Fig -4: Supervisedlearning.
Supervised techniques uses a model to reproduce outputs known from a training set. The system receives input as well as output data and its task is to create appropriate rules that maps input to the output. This training process should continue until the performance is high. After the training the system must be able to assignanoutputwhichhasnotbeenobservedduringthe training phase. This process is fast and accurate. There are two types of supervised learning techniques i) classificationandii)regression
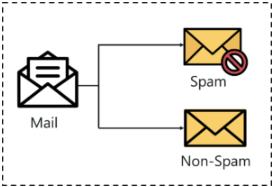
The technique aims to reproduce class assignments. It predicts the response value and the data is separated into classes. Example: recognition of spam messages in themailbox
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
i.CLUSTERING
A method of unsupervised learning and a common technique for statistical data analysis. Clustering involves grouping of data points For a given set of datapoints we use clustering to classify each datapoint intospecificgroup.
Fig 5: Classifyingmailasspamornotspam.

A fundamental concept in machine learning in supervised learning here the algorithm is trained with both input features and output labels. It helps in establishing relationship among the variables by estimating howonevariable affectstheother. Example: to predict the price of a product or price of house in a cityandpredictingthevalueofthestockinthemarket.
InunsupervisedlearningtheAIsystemgroupsunsorted informationaccordingtosimilaritiesanddifferences but therearenocategoriesprovided.
The algorithms are now allowed to classify , label or group the data points which are present in the dataset without having any external guidance in performing the task.
Performsmorecomplexprocessingtasksascomparedto supervised learning and subjecting the system to unsupervisedlearningisonewayoftestingAI.
These algorithms develop specific output from unstructured input and looks for relationship between eachsampleorinputobject.
Analyses underlying structure of datasets by extracting usefulinformationorfeaturesfromthem
The datapoints which are in same group should have similarpropertiesorfeaturesanddatapointsindifferent groupswillhavedissimilarpropertiesorfeatures.
Weuseclusteringtogainvaluableinsightsfromourdata to notice what groups the datapoints fall into when clusteringisapplied.
Anomalydetectionisaprocessofidentifyingunexpected items or events in the dataset which differs from the norm
Anomalydetectionisappliedonunlabelleddatawhichis calledunsupervisedanomalydetection.
Theanomalydetectionhastwobasiccomponents
a. Anomaliesoccurveryrareinadata b. Theirfeaturesdifferfromnormalinstances
a.
A machine takes lots of data for most of the algorithms to function. The tasks like speech and image recognition the machine needs lakhs of examples. Now we can clearly justify that training dataisinsufficient
Fig -6: UnsupervisedLearning
Thetrainingdatawillhavelotsoferrorsoutliersand noise and it is impossible for a machine learning model to detect proper underlying pattern and the model does not perform well. We may end up cleaning the data for getting accurate machine learningmodel.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Our training data must contain more relevant and less number of irrelevant features. For a successful machinelearning tocomeupitshouldhavegoodset offeaturesincludingfeatureselection,extractionand creatingnewfeaturesinthemachinelearningmodel.
The training data should be representative of new cases that we need to generalize. If a model trained using nonrepresentative training set as the model won’t be accurate in predictions as it will be biased against one class or group. Our model works well if we used representative data during training and model won’t be biased among one or two classes whenworksontestingdata.
Overfitting: A machine learning model is said to be overfittedwhentrainedwithlotofdata.Ifamodelis trained with so much of data it starts learning from noise and inaccurate data entries in our dataset. The model will not classify data correctly because of too manydetailsandnoise.
Underfitting: Amachinelearningalgorithmissaidto have underfitting when it cannot capture the underlyingtrendsofthedata.Underfittingmeansour model doesn’t fit the data enough well. The underfitting destroys the accuracy of machine learningmodel.
InrecenttimesAIandML developershavemadeAIand ML think more like humans performing complex tasks and making decisions based on in depth analysis. Sometimes machine learning implementation is not necessary and it is not well thought out and also can cause more problems than it solves therefore machine learningisnotanappropriatesolution.
Since machine learning has profoundly impacted the world we are slowly evolving to the philosophy called “dataism”meaningthepeopletrustdatamorethantheir personalbeliefs.
There are five key limitations of Machine Learning algorithms
1. Ethical Concern: We have been benefited from relying on computer algorithms to automate
processes , analyse large amounts of data and also makecomplexdecisions.Algorithms comeinforbias at any level development because the algorithms are developed and trained by humans so it is impossible to eliminate bias. For example if self driving car met with an accident who is responsible the driver, car manufacturer or the developer. Hence machine learning cannot make ethical or moral decisions on itsown
2. Deterministic problems: A powerful technology suited for many domains which includes weather forecasting , climate and atmospheric research. The ML models can be used to calibrate and correct sensors which allows us to adjust the operation of sensors that measure environmental indicators like temperaturepressureandhumidity. Thelimitationis depending on the amount of data and complexity of model and this can be intensive and takes up to a month.
3. Lack of Data: Neural Networks re complex architectures and it needs enormous amounts of training data to produce viable result. If the neural networkarchitecturegrowsandalsotherequirement of the data will grow and if we may try to reuse the databutreusingthedatadoesn’tbringgoodresults.
4. Lack of Interpretability: Let us consider we are working for the financial firm and we are assigned a task to build a model which detects fraudulent transactions and our model should be able to justify howitclassifiestransactions.
5. Lackofreproducibility: Thelackofreproducibility is due to complex and growing issue which is lack of code transparency and model testing methodologies. If the models are developed to take into account the latest research advances the model will not work in realtimeenvironment.
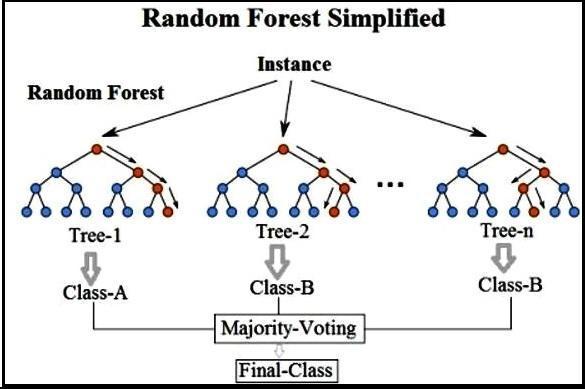
Random forest is an ensemble learning method for classification and regression and other tasks which operates by constructing multitude of decision trees in training time For the classification tasks the output of random forest is class selected by most trees. Similarly for regression the mean or average prediction of an individualtreeisreturned
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
and Random Forest (RF). The accuracy is different for every model when compared to other models. The Project work gives the accurate or higher accuracy model shows that the model is capable of predicting diabetes effectively. Our Result shows that Random Forest achieved higher accuracy compared to other machinelearningtechniques.
Fig -7: RandomForest
Itisthecomparisonofvariousauthorswhohaveworked on the Diabetes Prediction and also have tried various machinelearningalgorithmsforthesame.
[1] P. Saeedi, I. Petersohn, P. Salpea, B. Malanda, S. Karuranga, N. Unwin, S. Colagiuri, L. Guariguata, A. A. Motala,K.Ogurtsova,J.E.Shaw,D.Bright,andR.Williams are used Logistic Regression to generate smoothed age specific diabetes prevalence estimates (including previously undiagnosed diabetes) in adults aged 20 79 years.
[2] A.MirandS.N.DhageareusedWEKAtooltopredict diabetes disease by employing Naive Bayes, Support Vector Machine, Random Forest and Simple CART algorithm by taking an approach in Big Data Analytics whichisemergingapproachinhealthcare.
[3] D. Sisodia and D. S. Sisodia are used Decision Tree, SVM and Naive Bayes are used in this experiment to detectdiabetesatanearlystage.
[4] J. Smith, J. Everhart, W. Dickson, W. Knowler, and R. JohannesareusedADAPan earlyneural network model to forecast Diabetes in high risk population of PIMA Indians. The algorithm's performance was analysed using standard measures for clinical tests: sensitivity, specificity,anda receiveroperatingcharacteristic curve. Thecrossoverpointforsensitivityandspecificityis0.76. They have further examined these methods by comparing the ADAP results with those obtained from logistic regression and linear perceptron models using preciselythesametrainingandforecastingsets.
[5] Mitushi Soni and Dr. Sunita Varma are Machine Learning Classification and ensemble techniques on a datasettopredictdiabetes.TheyareK NearestNeighbor (KNN), Logistic Regression (LR), Decision Tree (DT), Support Vector Machine (SVM), Gradient Boosting (GB)
Itisevidentfromtheliteraturesurveythattheincidence ofdiabetesmellitusisincreasingandthatalthoughthere is evidence that the complications of diabetes can be prevented, there are still patients who lack the required knowledge and skills to manage and control their condition. It is generally accepted that diabetic patients must take responsibility for their own care and treatment. Patients therefore have to acquire the relevant knowledge, for their diabetes condition and we alsoneedtoeducatefamilymembersofthepatient This study is an attempt to determine patients and family members knowledge and views on diabetes mellitus, to make recommendations towards improved diabetic education which might lead to improved adherence to thediabetictreatmentregimen.
Classification is one of the most important decision makingtechniques in many real world problems.In this project, the main objective is to classify the data as diabetic or non diabetic and improve the classification accuracy. For many classifications problem, the higher number of samples chosen but it doesn’t lead to higher classification accuracy. In many cases, the performance of algorithm is high in the context of speed but the accuracyofdataclassificationislow.Themainobjective of our model is to achieve high accuracy. Classification accuracycanbeincreasedifweusemuchofthedataset for training and few data sets for testing. This study analysed ways to categorise diabetic and non diabetic data. Therefore, it is noted that Random Forest has achieved higher when compared with other machine learningmodels
1. Todeterminethegoodaccuracyscoreofthepatient andpredictthatpatientisdiabeticornon diabetic
2. Todevelopamodelwhichactsashealthassistantto the patient to take early prediction and make early decisiontocurediabetes
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN:2395 0072
Table 1: Thetableshowingwomenhavebeenpredicted diabetesornot
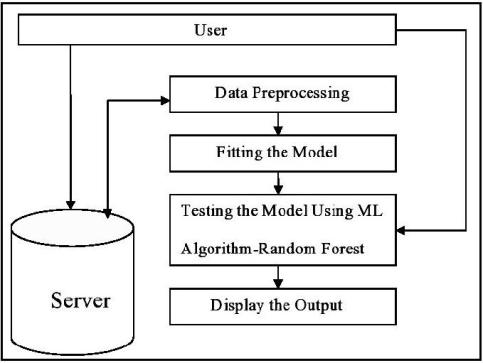
Fig 8: UseruploadshismedicaldatarelatedtoDiabetes totheserver
The system is implemented in four phases. It includes collection and pre processing of dataset. The training is donewithtraindataandvalidationwithtestdata. *This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. Severalconstraintswereplacedontheselectionofthese instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indianheritage. Thedatasetsconsists ofseveral medical predictor variables and one target variable,Outcome Predictor variables includes the number of pregnancies the patient has had, their BMI, insulin level, age, and so on
In the PIMA Indian Diabetes Dataset there are 9 attributes they are pregnancies glucose blood pressure skin thickness insulin bmi and diabetes pedigree functionageandoutcome
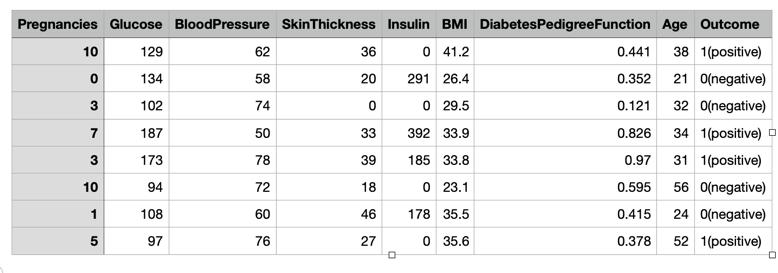
a. Pregnancies = npreg = number of times women is pregnant
b. Glucose=glu=plasmaglucoseconcentration
c. BloodPressure = bp = Diastolic Blood Pressure (mm Hg)
d. SkinThickness=skinthicknessfoldthickness
e. BMI=bmi=bodymassindex(kg/m2)
f. DiabetesPedigreeFunction=ped
g. Age=age(years).
h. Outcome=womenhasdiabetesornot.

The dataset consists of 768 patients; 268 patients are diabetic and the rest of them are non diabetic. The outputvariabletakes‘0or‘1’values,where‘0’and‘1’are depict the non diabetic instance and diabetic instance respectively.
Table -2: Thetableshowing therangeoflabelspresent inthediabetesdataset
The main aim of our project was to design and implement Diabetes Prediction Using Machine Learning Methods and performance analysis of methods and it hasbeenachieved.Theproposedapproachusesvarious classification and ensemble learning method in which Support Vector Machine, K Nearest Neighbour ,Random forest, Decision Tree, Logistic Regression and Gradient Boosting classifiers are used. Accuracy achieved is 77%. The experimental results can be assistant health care to take early prediction and make early decision to cure diabetes.
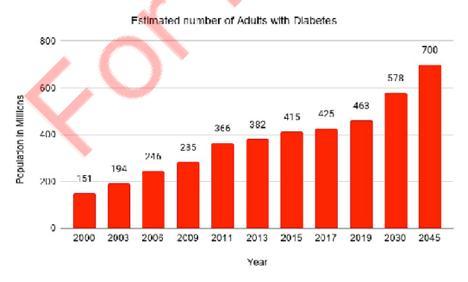
[1]Globalandregionaldiabetesprevalenceestimatesfor 2019andprojectionsfor2030and2045
[2] Diabetes disease prediction using machine learning onbigdataofhealthcare
[3]Predictionofdiabetesusingclassificationalgorithms
[4] Using the adap learning algorithm to forecast the onsetofdiabetesmellitus
[5] Diabetes Prediction using Machine Learning Technique