International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072
I Shou University, No.1, Sec. 1, Syuecheng Rd., Dashu Township, Kaohsiung,Taiwan ***
Abstract XML documents on the web are often found without DTDs, particularly when these documents have been created from legacy HTML. Yet having knowledge of the DTD can be valuable in querying and manipulating such documents. Recent work (cf. [1]) has given us a means to (re )construct a DTD to describe the structure common to given set of document instances. However, given a collection of documents with unknown DTDs, it may not be appropriate to construct a single DTD to describe every document in the collection. Instead, we would wish to partition the collection into smaller sets of “similar” documents, and then induce a separate DTD for each such set. It is this partitioning problem that we address in this paper. Given two XML documents, how can one measure structural (DTD) similarity between the two? We develop a dynamic programming algorithm to find this distance for any pair of documents. We validate our proposed distance measure experimentally. Given a collection of documents derived from multiple DTDs, we can compute pair wise distances between documents in the collection, and then use these distances to cluster the documents.
Key Words: DTD,XML,LED,Cluster,SimilarityThe Extensible Mark up Language (XML) is seeing increased use, and promises to fuel even more applications in the future. In [1] the authors provide a method to automatically extract a DTD for a set of XML documents.Theyprovideseveralbenefitsfortheexistence ofDTDs.AnXMLdocumentcanbemodeledasanordered labeled tree [2]. There is considerable previous works on finding edit distances between trees [3 6, 7 11]. Most algorithms in this category are direct descendants of the dynamic programming techniques for finding the edit distancebetweenstrings[12].Thebasicideainallofthese tree edit distance algorithms is to find the cheapest sequence of edit operations that can transform one tree into another. There are several other approaches that allow insertion and deletion of single nodes anywhere within a tree [8 11]. We account for this by introducing edit operations that allow for the cutting and pasting of whole sections of a document. Using our resulting pair
wise distance measure, we show that standard clustering algorithms do very well at pulling together documents derivedfromthesameDTD.
In thissection, wefirst introduce the pre processingsteps for the incorporation of hierarchical information in encodingtheXMLtree’spaths. Itisbasedonthepreorder treerepresentation(PTR)[13]andwillbeintroducedafter abriefreviewofhowtogenerateanXMLtreefromanXML document. We then describe dynamic programming mining approach to compute the similarity between two sets of encoded paths, i.e., two XML documents. To doso, we have to first go through the following five preprocessing steps for XML document. The five preprocessingstepsareconversion,pathextraction,nested andduplicatedpathremoval,similarelementidentification andtransformation,pathencoding.
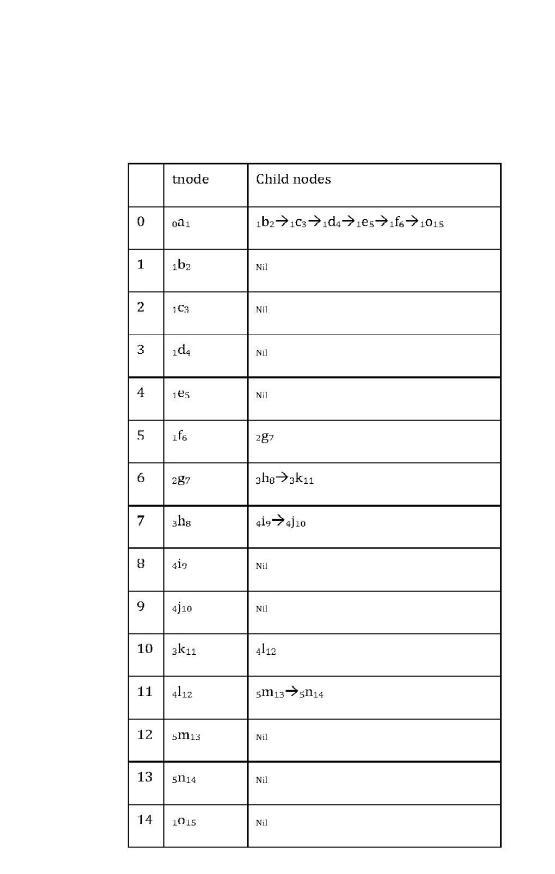
There are essentially two programming APIs for processing XML: SAX (Simple API for XML) and DOM (Document Object Model) DOM treatsaXMLdocument conceptually as a tree. It provides an API that allows a programmer to add, delete or edit nodes within the tree. The DOM is a collection of Recommendations maintained by the W3C (World Wide Web Consortium) [14]. We use JDOM to convert the XML document to tree format. The valuesoftheelementsinthetreearenotconsidered here and only the structural information will be passed to the subsequentsteps. TheXML’shierarchicalstructurecanbe representedbyalabeledrootedtree[14]. TheXMLtreein Figure 1 can be presented by Prefix String Pattern (depthNodeNameOrder) Encoding. Finally, the XML tree in Figure can be further use the adjacent linked list tnode structure wheredNodeO d is the node depth and o is the visiting order in preorder traversing in the xml tree as shownintheTable1.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072
each identifier is associated with its depth in the tree. Finally a depth first exploration of the tree will give the corresponding prefix pattern. The DFS_Prefix_Encoding algorithm is shown in Table 2 and prefix pattern tree of XML shown in Figure 1 should be as the result 0a1 1b2 1c3 1d4 1e5 1f6 2g7 3h8 4i9 4j10 3k11 4l12 5m13 5h14 1o15 where dNodeO d is the node depth and o is the visiting order in preorder traversing. Once the whole set of prefix pattern (corresponding to the XML documents of a collection) is obtained,thepair wisedXMLdocumentdistanceisableto calculatebydynamicprogramming.
DFS_Prefix_Encoding
1. foreachxmltreexi=1~n inadjacent list
Figure1SimplifiedXMLtree
Table1XMLTreeinAdjacentListmodel
We used depth first search (DFS) technique intended to transform XML tree into a prefix pattern sequence. In order to perform such a transformation, the nodes of the XML tree first have to be mapped into identifiers Then
2. callDFS_Prefix_Encoding(xi,v0) 3.
4. ProcedureDFS_Prefix_Encoding(xi,v)
5. visited(v) 1
6. foreachvertexwadjacenttovdo
7. ifvisited(w)=0then
8. callDFS_Prefix_Encoding(xi,w)
9. endDFS_Prefix_Encoding
10.
Our algorithm for calculating the least edit distance between structural summaries of root order label trees that represent XML documents uses a dynamic programmingalgorithm.Inordertotransformonesource tree T1 of preorder x[1..m] to a target tree T2 of preorder y[1..n],wecanperformvarioustransformationoperations. Our goal is, given tree T1 and T2, to produce a series of transformations that change T1 to T2. Initially, i=j=1. We are required to examine every node in T1 during the transformation, which means that at the end of the sequence of transformation operations, we must have i =m+1. Given two xml tree x[1..m] and y[1..n] and set of transformation operationcosts,theeditdistancefromxto yisthecostoftheleastexpensiveoperationsequencethat transforms x to y. We use a dynamic programming algorithm that finds the edit distance from x[1..m] to y[1..n] and prints an optimal operation sequence, also analyze the running time and space requirements of our
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072
algorithm. Therearefivepossibilities.Wedenotebyc[i,j] thecostofanoptimalsolutiontotheXi →Yj problem,and thecorrespondingoperationputsintotheop[i,j]table.
TheFigure2showstwoxmltreesTi andTjwhichwetook feature extraction firstly, and calculates the distance
betweenthem.
Given two xml tree x[1..m] and y[1..n] and set of transformation operationcosts,theeditdistancefromxto yisthecostoftheleastexpensiveoperationsequencethat transforms x to y. We use a dynamic programming algorithm that finds the edit distance from x[1..m] to y[1..n] and prints an optimal operation sequence, also analyze the running time and space requirements of our algorithm.

The Least Edit Distance (LED) complete algorithm as Table3shows:
Table3LeastEditDistance(LED)
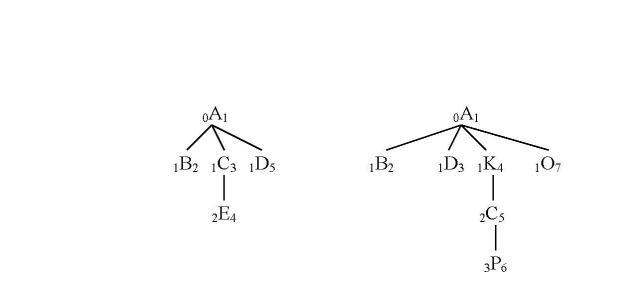
Figure2

We calculate the distance between Ti and Tj using LED(Ti,Tj) algorithm and the result as following Table 4 shown.
Table4ThedistancebetweenTi andTjusingLED(Ti,Tj)
Likelongestcommonsubsequence(LCS),ourpseudo code fills of the Table 4 in row major order, i.e., row by row from top to bottom, and left to right within each row. Column majororder(column by columnfromlefttoright, and top to bottom within each column) would also work. Along with the c[i, j] table, we fill in the table op[i, j ], holding which operation was used. To reconstruct this sequence, we use the op table returned by Least Edit Distance. As the Table 5, LED Operation Print Algorithm, theprocedureOP PRINT (op, i, j ) reconstructstheoptimal operationsequencethatwe foundtotransform Xi into Yj The base case is when i = j = 0. The first call is OP PRINT(op,m, n)
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072

downloaded from ACM’s SIGMOD Record homepage[15]: OrdinaryIssuePage.dtd, ProceedingsPage.dtd, SigmodRecord.dtd,Index.dtdandIndexTerm.dtd Wealso downloaded the XML document generator from IBM’s homepage[16]. ThisgeneratoracceptstheaboveDTDsas input and creates the sets of XML documents for simulations. BaseduponfivesetsofXMLdocumentswith similarcharacteristics,theirleasteditdistance(LED)were computed, analyzed and reported as follows. We use the formulatocomparepair wisexmltreessimilarity ,and
, where the Matched Unmatched is difference sum of xml tree Ti and Tj in the common matched and common unmatchedelements,and
Finally, we got the following operations which transform TixmltreeintoTjxmltree.
Replace(Ti[1],A) /*orCopy(Ti[1],A) */
Insert(Tj[2],Ti[1],1)
Replace(Ti[2],D)
Replace(Ti[3],K)
Replace(Ti[4],C)
Insert(Tj[6],Ti[4],1)
Replace(Ti[5],O)
Also, those of the differences of two xml trees are calculatedasthefollowing: ) cos 7( ) cos 5( ) cos 7( t insert t delete t update =0.58dissimilarity
The goal ofour work isto finddocuments withstructural similarity, that is, documents generated from a common DTD. We apply a standard clustering algorithm based on the distance measures computed for a given collection of documents with known DTDs. For any choice of distance metric, we can evaluate how closely the reported clusters correspond to the actual DTDs. The experiments were conducted as follows. The following five DTDs were
Nistotalnumberoflevel 1subtree, Nt istotalnumberofthepathsinthetth subtree, Mt,p isnumberofelementsinthe(t,p)th path,
mt,p is number of common elements (maximal sequential pattern),ct,p issumof thecommonunmatched element in the(t,p)th path.
SothedifferencebetweenTi andTj intheTable4canbeas followed:
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072
We show the similarity between the first document OrdinaryIssuePageasthebasedocument,the2nd ,3rd ,4th , 5th , and 6th as the query document. Figure 3 shows the similarity between the first document OrdinaryIssuePage asthebasedocumentandthequerydocument2,3,4,5and 6.
Similarity (Ratio)
The Similarity ofXMLfrom OrdinaryIssuePage using base document1 0.94 0.96 0.98 1 1.02 1,2 1,3 1,4 1,5 1,6
Base document1
from OrdinaryIssuePage.dtd (the 3rd document) and documentxfromProceedingsPage(the1st document~the 4th document)andbetweendocumentbaseanddocument y form SigmodRecord.dtd and between document base and document z form index.dtd. As the XML documents come from different DTDs, this is called heterogeneous XMLdocumentsimilarity.
Similarity (Ratio)
TheSimilarity Comparison of XMLs From differentDTDs Using Proposed Method 0 0.1 0.2 0.3 0.4 3,1,1,1 3,2,1,1 3,3,1,1 3,4,1,1
DocSet(OrdinaryIssuePage,ProceedingsPage,SigmodRecord,Index)
Figure
DocumentSet(OrdinaryIssuePage,OrdinaryIssuePage)
documents2 6
Wealsocompare ourproposedmethodwithLee etal.’s methodandPTR+ESmethodasshownontheFigure4. It can be seen that the similarity values obtained by the proposedmethods,i.e.,TED,areprettysimilartothoseof Lee et al.’s and PTR+ES method. On the Figure 4 shows the ratio similarity of the DocumentSet(base,x)=(1,2) whichusesthe1st ordinaryIssuePageasbaseandthe2nd OrdinaryIssuePage as query document, DocumentSet(base,x)=(1,5), DocumentSet(base,x)=(2,5), and DocumentSet(base,query)=(3,4), are better than the Leeetal.’sandPTR+ESmethod’ssimilarityratio.
In this experiment, the similarities between documents of different DTDs were analyzed. Figures 5~7 show the results of heterogeneous XML document similarity. The XML documents from OrdinaryIssuePage.dtd were adopted as the base documents while those from ProceedingsPage.dtd , SigmodRecord.dtd and index.dtd wereusedasquery documents. Theexperimental results are shown in Figure 5 where DocumentSet(base,x,y,z) is used to denote the similarities between document base
Ordinary-Proceeding Ordinary-Sigmod Ordinary-Index
Figure5.DocumentSet(the3rd Ordinaryasbase, Proceeding,Sigmod,Index)
Figure 6 shows that DocumentSet(base,x,y,z) is used to denotethesimilaritiesbetweenthe2nd documentasbase from OrdinaryIssuePage.dtd (the 2nd document) and document x from ProceedingsPage (the 1st document ~ the 4th document) and between document base and document y form SigmodRecord.dtd and between documentbaseanddocumentzformindex.dtd.
Similarity (Ratio)
TheSimilarityComparisonofXMLs from DifferentDTDs UsingProposedMethod 0 0.05 0.1 0.15 0.2 0.25 2,1,1,1 2,2,1,1 2,3,1,1 2,4,1,1
DocSet(OrdinaryIssuePage,ProceedingsPage,SigmodRecord,Index)
Ordinary-Proceeding Ordinary-Sigmod Ordinary-Index
Figure6.DocumentSet(the2nd Ordinaryasbase, Proceeding,Sigmod,Index)
Figure7isshownwhereDocumentSet(base,x,y,z)denotes the similarities between the 1st document as base from Sigmodrecord.dtd and document x from ProceedingsPage (the 1st document ~ the 4th document) and between document base and document y form OrdinaryIssuePage.dtd (the 1st document ~ the 4th document) and between document base and document z formindex.dtd.
Similarity (Ratio)
TheSimilarityComparisonofXMLs from differentDTDs UsingProposedMethod 0 0.02 0.04 0.06 0.08 1,1,1,1 1,2,2,1 1,3,3,1 1,4,4,1
DocSet(SigmodRecord,ProceedingsPage,OrdinaryIssuePage,Index)
Sigmod-Proceeding Sigmod-Ordinary Sigmod-Index
Figure7.DocumentSet(the1stSigmodasbase, Proceeding,Ordinary,Index)
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 06 | June 2022 www.irjet.net p ISSN: 2395 0072
For efficiently serving versatile queries, a new XML data representation referred to as Prefix String Pattern Encoding (PSPE) has been presented in this paper. PSPE reserves level and path depth of XML paths, the semantic information enables the inference of deriving XML path relationship. By using the algorithm LED is to find documents with structural similarity, that is, documents generatedfromacommonDTD.Weprepareforclustering based on the distance measures computed for a given collection of documents with known DTDs, and give a satisfiedexperimentresult.
[1] M.Garofalakis,A.Gionis,R.Rastogi,S.Seshadri,and K. Shim, Xtract: A system for extracting document type descriptors from XML documents. In Proc. of ACM SIGMOD,pages165 176,2000.
[2] World Wide Web Consortium. The document object modelhttp://www.w3.org/DOM/.
[3] S.Chawathe,Comparinghierarchicaldatainextended memory.In Proc. of VLDB,pages90 101,1999.
[4] S. Chawathe , H. Garcia Molina, Meaningful change detection in structured data. In Proc. of ACM SIGMOD, pages26 37,1997.
[5] S. Chawathe, A. Rajaraman, H. Garcia Molina, and J. Widom, Change detection in hierarchically structured information. In Proc. of ACM SIGMOD, pages 493 504, 1996.
[6] Gregory Cobena, Serge Abiteboul, and Amelie Marian, DetectingchangesinXMLdocuments,In Proc. of ICDE, 2002.
[7] S. Selkow, The tree to tree editing problem. Information Processing Letters, 6(6):184 186, December1977.
[8] D. Shasha and K. Zhang, Approximate tree pattern matching, In Pattern Matching in Strings, Trees and Arrays,chapter14,OxfordUniversityPress,1995.
[9] K. C. Tai, The tree to tree correction problem. Journal of the ACM,26:422 433,1979.
[10] J.Wang,K.Zhang,K.Jeong,andD.Shasha,Asystemfor approximatetreematching, IEEE TKDE,6(4):559 571, 1994.
[11] K.ZhangandD.Shasha,Simplefastalgorithmsforthe editing distance between trees and related problems.
SIAM Journal of Computing, 18(6):1245 1262, December1989.
[12] V. Levenshtein, Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl., 6:707 710,1966.
[13] Sedgewick R (1996) Chapter 5 trees, an introduction to the analysis of algorithms. Addison Wesley, pp 221 298
[14] [14] World Wide Web Consortium. The document objectmodel.http://www.w3.org/DOM/.
[15] ACM SIGMOD Record home page [http://www.acm.org/sigmod/record/xml]
[16] IBM’s XML Generator homepage [http://www.alphaworks.ibm.com]
Hsu Kuang Chang He is associative processor in the Department of Information Engineering, I Shou University, Taiwan. His research interests include data mining, multimedia media database, and informationretrieval. 1’st Athor Photo
