International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
1Associate Professor, Dept. of Computer Science, Jeppiaar Engineering college, Tamil Nadu, India 2 3Student, Dept. of Computer Science, Jeppiaar Engineering College, Tamil Nadu, India. ***
Abstract Among around the world, farming has the significant obligation regarding working on the monetary commitment of the country. In any case, still the most agricultural fields are immature because of the absence of sending of biological system control innovations. Because of these issues, the harvest creation is not further developed which influences the farming economy. Consequently an advancement of agrarian efficiency is improved in view of the plant yield expectation. To forestall this issue, Agricultural areas need to foresee the harvest from given dataset utilizing AI methods. The investigation of dataset by directed AI technique which is SMLT to catch a few data's like, variable ID, uni variate examination, bi variate and multi variate investigation, missing worth medicines and so on. A near report between AI calculations had been done to figure out which calculation is the most reliable in anticipating the best harvest. The outcomes show that the viability of the proposed AI calculation procedure can measure up to best exactness with entropy computation, accuracy, Recall, F1 Score, Sensitivity, Specificity and Entropy.
Key Words: Supervised Machine Learning Technique, Entropy, Crop Production, Price prediction, Yield, Agriculture.
In our country, agribusiness is the primary mainstay of theeconomy.Mostoffamiliesarereliantonagribusiness. The country's GDP is basically centered around agriculture. The greater part of the land is utilized for agribusinesstoaddresstheissuesofthenumberofinhabitantsin thedistrict.Itisimportanttomodernizefarmingpractices tomeettherequestingnecessities.Ourexplorationmeans to tackle the issue of harvest cost forecast all the more successfully to guarantee ranchers' wages. To concoct improved arrangements, it utilizes Machine Learning strategies on various information. Agri technology and precision farming, now termed virtual farming, have emerged as new scientific areas ofinterest thatuse data intensive methods to boost agricultural productivity and reducetheimpactontheenvironment
Cropdevelopmentforecastisavitalpieceofagribusiness and is essentially founded on variables, for example, soil, naturalhighlightslikeprecipitationandtemperature,and the quantum of compost utilized, especially nitrogen and phosphorus. These elements, be that as it may, fluctuate from one locale to another: subsequently, ranchers can't developcomparativeharvestsineachdistrict.Foreseeing areasonableyieldfordevelopmentisbasictoagriculture. Inthis work,theMRFEisa clevermethodology, hasbeen proposed for choosing notable highlights utilizing a change crop informational collection and a positioning strategy to distinguish the most reasonable yield for a specificlocale.
The primary drawbacks of the existing system are: They are not using any machine learning and deep learning concepts and they have not mentioned any metrics reports.
Thegoalistodevelopa machinelearning modelforCrop yield Prediction, to potentially replace the updatable supervised machine learning classification models by predicting results in the form ofbestaccuracy by comparing supervisedalgorithm.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
disregarded, and they have been fruitful with further developing outcomes with that. If there should arise an occurrence of this dataset, a great many people seldom investigatethehigh requestsnapshotsofthehighlights.
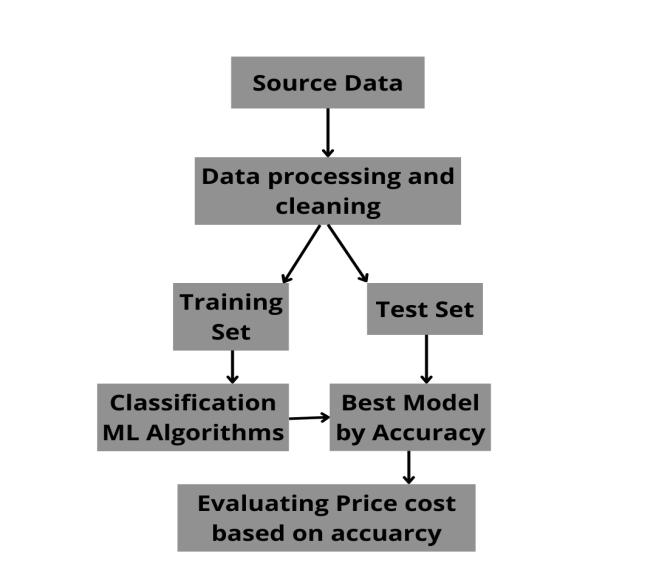
Fig 1:WorkflowDiagram

Our objective is push for helping ranchers, government utilizing our expectations. This large number of distributions state they have shown improvement over their rivals however there is no article or public notice of their work being utilized basically to help the farmers. Assumingthereareacertifiedissuesincarryingoutthatworkto nextarrange,thenrecognizethoseissuesandhaveagoat addressingthem.

Core modules of the proposed system are: Data Pre processing, Data Analysis of Visualization, Comparing Algorithm with prediction in the form of best accuracy resultandDeploymentUsingGUI.
ThedemodatasetiscurrentlyprovidedtoAImodelbased on this informational collection the model is prepared. Each new detail occupied at the hour of utilization structure goes about as a test informational index. After the activityoftesting,modelforecastinviewofthesurmising it finishes up based on the preparation informational indexes. Satellite Imagery (Remote Sensing Data), has been broadlyutilizedforanticipatingcropyield.Thisdatasetis gathered utilizing the sensors mounted on satellites or planes, which recognize the energy (electromagnetic waves), reflected or diffracted from surface of the earth. Remotedetecting informationhas a ton of energy groups to offer, yet principally just not many of them have been utilized for crop yield expectation. However, there are certainindividualswhohavehadagoatcreatingapplicable highlights utilizing the groups which are commonly
Fig 2:DescriptionoftheDataset
Fig 3:ArchitectureDiagram
Everything the investigation of the informational index was finished utilizing ―ANACONDA NAVIGATOR USING JUPYTER NOTEBOOK. It performs errands like preprocessing, order, relapse, bunching and representation. The informational index must be taken care of into the productandwantedtaskischosen.Itgivesnumberofclassifierstobuildingmodelsandtacklesinsightfulissues.Ithas the intelligent Graphical User Interface (GUI) with every one of the choices that are expected for information examination.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
InAIandmeasurements,arrangementisanadministered gainingapproachinwhichthePCprogramgainsfromthe information input given to it and afterward utilizes this figuringouthowtogroupnovelperception.Thisinformational index may just be bi class (like distinguishing whether the individual is male or female or that the mail isspamornon spam)oritcouldbemulti classaswell.A few instances of order issues are: discours and penmanship acknowledgment, bio metric distinguishing proof, archive grouping and so forth. In Supervised Learning, calculationsgainfrommarkedinformation.Subsequentto understandingtheinformation,thecalculationfiguresout whichnameoughttobegiventonewinformationinlight of example and partner the examples to the unlabeled newinformation.
It is one of the most remarkable and famous calculation. Choice tree calculation falls under the classification of managed learning calculations. It works for both nonstop as well as all out yield factors. Decision tree fabricates order or relapse models as a tree structure. It breaks downan informational index into increasingly small subsetswhilesimultaneouslyarelatedchoicetreeisgraduallyevolved.
Randomtimberlandsorarbitrarychoicebackwoodsarea troupelearningstrategyforcharacterization,relapse and different assignments, that work by building a huge numberofchoicetreesatpreparingtimeandyieldingthe class that is the method of the classes (arrangement) or mean forecast (relapse) of the singular trees. Irregular choice backwoods right for choice trees' propensity for over fitting to their preparation set. Random Forest is a kind of administered AI calculation in view of gathering learning.
The Naive Bayes calculation is a natural technique that utilizes the probabilities of each trait having a place with each class to make an expectation. It is the managed learning approach you would concoct if you had any desiretoprobabilisticallyshowaprescientdisplayingissue. Naïve bayesworksonthecomputationofprobabilitiesby expecting that the likelihood of each quality having a place with a given class esteem is free of any remaining credits.
Support vector machines are directed learning models with related learning calculations that examine informationutilizedforgroupingandrelapseexamination.
DatavalidationprocessistheblunderpaceoftheMachine Learning (ML) model, which can be considered as near thegenuineblunderpaceofthedataset.Iftheinformation volume is sufficiently enormous to be illustrative of the populace, you may not require the approval procedures. Notwithstanding, in true situations, to work with tests of information that may not be a genuine delegate of the numberofinhabitantsingivendataset Toviewingasthe missing worth, copy worth and depiction of information type whether it is float variable or number. The example ofinformationusedtogiveafair mindedassessmentofa model fit on the preparing dataset while tuning model hyper boundaries. The assessment turns out to be more one sided as expertise on the approval dataset is integrated into the model arrangement. The approval set is utilized to assess a given model, yet this is for successive assessment.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
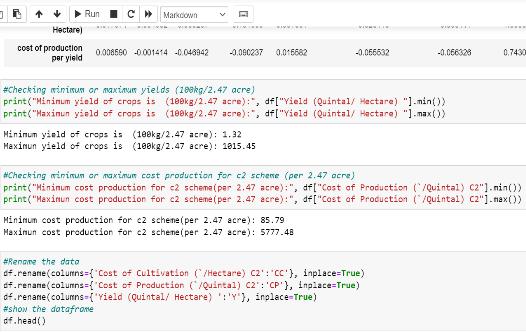
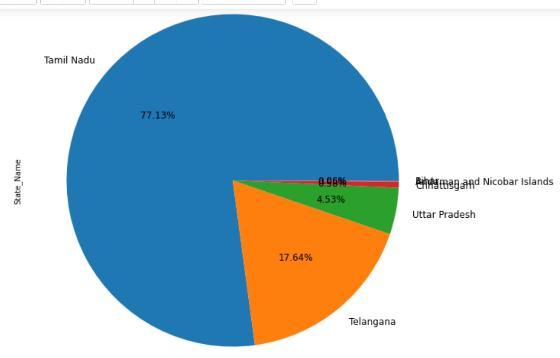
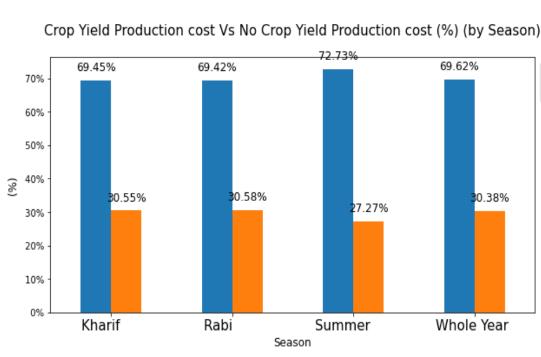
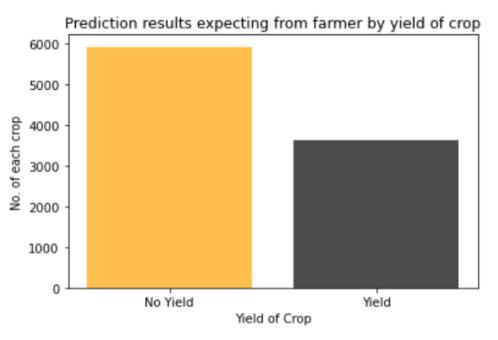
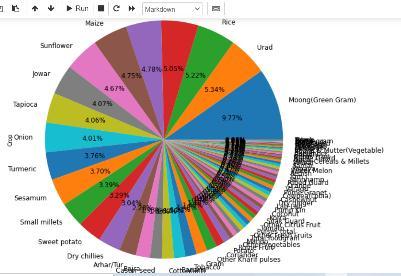
Fig 5:Yieldofcropsmin/maxvalues
Data Visualization is a significant ability in applied insights and AI. Measurements really does without a doubt zero in on quantitative portrayals and assessments of information. Information representation gives a significant set up of apparatuses for acquiring a subjective comprehension.Thiscanbeusefulwhileinvestigatingandgetting to know a dataset and can assist with distinguishing designs, degenerate information, anomalies, and considerablymore.Withalittlespaceinformation,informationperceptions can be utilized to communicate and exhibit key connections in plots andgraphs thataremoreinstinctive and partners than proportions of affiliation or importance. Information perception and exploratory information investigation are entire fields themselves and it will suggest a more profound jump into a few the books referencedtowardtheend.
Fig 6:Cropproductioninvariousstates
Fig 7:ProportionofCrops Fig -8:CropVsNoCropyieldproductioncostInternational Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
It is vital to analyze the exhibition of numerous different AIcalculationsreliablyanditwillfindtomakeatestoutfit to look at various changed AI calculations in Python withscikit learn.Itcaninvolvethistestbridleasaformat onyourownAIissuesandaddmoreandvariouscalculationstoanalyze.Eachmodelwillhavedifferentexecution qualities. Utilizing resampling techniques like cross approval, you can get a gauge for how exact each model might be on concealed information. It should have the option to utilize these appraisals to pick a couple of best models from the set up of models that you have made. Whenhaveanewdataset,itisreallysmarttopicturethe information involving various strategies to check out at the information according to alternate points of view. A similar thought applies to show choice. You ought to utilizevariousperspectivesonassessedprecisionofyourAI calculationstopicktheacoupletoconclude.Amethodfor doingthisistoutilizedifferentrepresentationtechniques toshow thetypical exactness, changeanddifferent properties of the dissemination of model correctness. In the example below 4 different algorithms are compared namely: Random Forest, Decision Tree Classifier, Naive BayesandSVM.TheK overlaycrossapprovalmethodology is utilized to assess every calculation, critically designedwithasimilararbitraryseedtoguaranteethatsimilar parts to the preparation information are performed and that every calculation is assessed in definitively the same way. Before that looking at calculation, Building a MachineLearningModelutilizingScikit Learnlibraries.In this library bundle need to done preprocessing, straight model with calculated relapse strategy, cross approving by KFold technique, troupe with irregular timberland strategyandtreewithchoicetreeclassifier.Furthermore, parting the train set and test set. To anticipating the outcomebylookingatprecision.
The Proportion of the all out number of forecasts that is right in any case generally speaking how frequently the modelpredictsaccuratelydefaultersandnon defaulters
Accuracycanbecalculatedby:
(TP+TN) / (TP+FN+FP+TN), where TP, TN, FP, FN can bereferredasTruePositive,TrueNegative,FalsePositive, False Negative respectively. Accuracy is the most natural presentation measure and it is basically a proportion of accurately anticipated perception to the all perceptions. One might feel that, on the off chance that we have high exactness, our model is ideal. Indeed, precision is an incredible measure yet just when you have symmetric datasets where upsides of misleading positive and bogus negativesarepracticallysame.
The proportion of positive predictions that are actually correct. Precision = TP / (TP + FP), precisionistheproportion of accurately anticipated positive perceptions to the complete anticipated positive perceptions. The inquirythatthismeasurementanswerisofalltravelersthat named as made due, what number of really made due? High accuracy connects with the low bogus positive rate. Wehave 0.788 accuracywhichisverygreat.
The extent of positive noticed esteems accurately anticipated. (The extent of genuine defaulters that the model will accurately anticipate). Recall = TP / (TP + FN). Recall Sensitivity It is the proportion of accurately anticipated positiveperceptions totheall perceptions in genuineclass yes.
F1ScoreistheweightedordinaryofPrecisionandRecall. Accordingly,thisscoreconsidersbothbogusup sidesand misleading negatives. Instinctively it isn't as straightforward as precision, yet F1 is normally more helpful than exactness,particularlyassumingyouhavealopsidedclass dissemination.Exactnessworksbest
assuming bogus up sides and misleading negatives have comparative expense. On the off chance that the expense ofmisleadingup sidesandbogusnegativesarealtogether different, it's smarter to check out at both Precision and Recall.
F Measure = 2TP / (2TP + FP + FN)
F1Score=2*(Recall*Precision)/(Recall+Precision)
Tkinter instructional exercise gives essential and high level ideas of Python Tkinter. Our Tkinter instructional exerciseisintendedfornovicesandprofessionals.Python givesthestandardlibraryTkintertomakingthegraphical UI for work area based applications. Creating work area based applications with python Tkinter is anything but a complicatederrand.AvoidTkinterhighlevelwindowcan bemadebyutilizingtheaccompanyingsteps. Tkinteris a python library for creating GUI (Graphical User Interfaces). We utilize the tkinter interface and Tkinter will accompany Python as a standard bundle, it tends to be utilizedforsecurityreasonforeveryclientsorbookkeepers. Therewillbetwosortsofpageslikeenlistmentclientreason and login section motivation behind library for mak-
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
ingauseofUI(UserInterface),tomakewindowsandany remaininggraphicalclientclients.
assist the rancher with getting understanding into the interestandtheexpenseofdifferentharvestsinmarket.
[1] P. S. Maya Gopal and R. Bhargavi, “Feature selection foryieldpredictioninborutaalgorithm,”Int.J.PureAppl. Math.,vol.118,no.22,pp.139 144,2018.
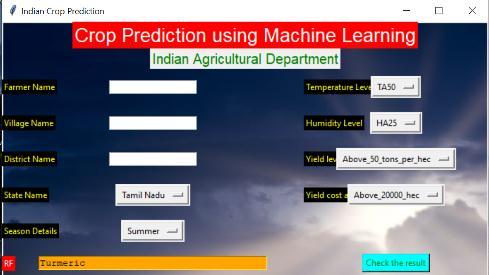
Fig -10:CropPrediction
Remaining SMLT algorithms will be involved in finding the best accuracy with applying to predict the crop yield and cost. Agricultural department wants to automate the detecting the yield crops from eligibility process (real time). To automate this process by show the prediction result in web application or desktop application. To optimizetheworktoimplementinArtificialIntelligenceenvironment.
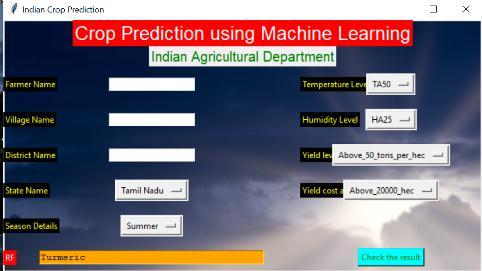
The insightful interaction began from information cleaning and handling, missing worth, exploratory investigation lastly model structure and assessment. At long last we foresee the yield utilizing AI calculation with various outcomes. This brings a portion of the accompanying experiences about crop forecast. As greatest kinds of yields will
becoveredunderthisframework,ranchermightgettobe aware of the harvest which might in all likelihood never havebeendevelopedandrattlesoffeverysingleimaginable harvest, it helps the rancher in decision making of which harvest to develop. Additionally, this framework thinks about the past creation of information which will
[2] S. Ji, S. Pan, X. Li, E. Cambria, G. Long, and Z. Huang, “Suicidalideationdetection:Areviewofmachinelearning methods and applications,” IEEE Trans. Comput. Social Syst.,vol.8,no.1,pp.214 226,Feb.2021.
[3] K. Ranjini, A. Suruliandi, and S. P. Raja, “An ensemble of heterogeneous incremental classifiers for assisted reproductive technology outcome prediction,” IEEE Trans. Comput. Social Syst.early access, Nov.3,2020doi: 10.1109/TCSS.2020.3032640.
[4]H.LiuandR.Setiono,“Aprobabilisticapproachtofeatureselection afiltersolution,”inProc.13thInt.Conf.Int. Conf.Mach.Learn.,vol.96,1996,pp.319 327.
Fig 11:CostPrediction