International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056

Volume: 09 Issue: 05 May| 2022 www.irjet.net p ISSN: 2395 0072
A Review of machine learning approaches to mine Social Choice of voters.
Ankita Sengar 1Assistant professor
Abstract Mining the intention of user and predicating their future behavior is biggest tool for any commercial or noncommercial organization. Also Predicting election results is new area where intent mining is applied. In last decade, social platforms has been immensely used in elections There are many statistical and AI based model which has predicted the result of a national election to a great accuracy. This paper presents a literature review of various machine learning based strategies used to analyze voter intent from their social media handle like twitter and predicting the results of elections.
Key Words: Social Choice theory, Intent Mining, Lexicon Model, Supervised Model, NLP, Ensemble, Naïve Bayes, SVM, Tfid vectorization, Election, Twitter
1.INTRODUCTION
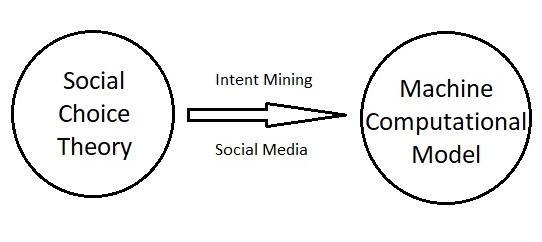
Today social media provide various platform where intellectuals of various field connect and interact their ideologiesbeitsocial,politicalorpersonal.Theseplatforms withtimehavebecomelikeadataminewhichholdspeople intentfromseveralaccepts,whichifproperlyexcavatedand analyzedareworththemillionsforseveralcommercialand noncommercialorganizations.DataMiningistheprocessof knowledge discovery from data (KDD) by sorting and analyzinglargedatasets.Thisdatacouldextractknowledge like user opinion regarding there likeness or unlikeness towards a product, favor or against certain government policy,theirsentimentstowardsomethingortheirintentto voteinfavorofcertainpartyorpersonetc.
governance).Socialchoiceisaboutagroupofindividualsor society choosing a winning outcome (e.g., policy, electoral candidate)fromagivensetofoptions.ManyAImodelsare usedthesedaystoharnessuseropinionregardingcertain policyorelectoralchoices.
Intentofausercanbepositive,negativeorneutraltowards certainpoliticalpartyorrepresentative.Theseintentsofa voterareimplicitlyorexplicitlysharedbythemonvarious social media platforms like twitter, Facebook etc. These implicitandexplicitopinioniscollecteddependingonwell articulatedfeatures.Andseveralofthesefeaturesofmany peoplemakesadatasetwhichisusedtoextractpatternsand knowledgewhichcouldeitherdirectlypredictvoterintent or could be used to train a machine which will in future predictsuchresultsifprovidedwithsimilarfeatures.
Therehavebeenmanyearlyworksforpredictingelection. Tumasjan1showedthatbyusingonlyvolumeoftweetswith merementionofpoliticalpartiescanbeusedtostatistically representelectionpollsfavor. Wang2attemptedtoimprove Tumasjan1 proposed work by combining and separting tweets into positive sentiment and negative sentiment of voters. Franch F3 proposed vote share prediction model usingARIMA(autoregressiveintegratedmovingaverage) model,whichexceededtheaccuracyoftraditionalexpensive polls. Barkha Bansal4 used lexicon based model to collect data against positive and negative sentiments and then statisticallypredictedelectionresultsforUP. Ontheother hand,Marozzo5usedasupervisedmachinemodel(Random Forestalgorithm)tofindpolarityoftweetsandnewstexts relatedtopoliticalcampaigns.
In next section literature review of machine learning and intent mining approaches which are generally used to predictsocialchoiceorelectionresultarecovered.
2. LITERATURE REVIEW
Fig 1: Blockdiagramrepresentationofapproach
Social choice theory is the field of microeconomics which studycollectivedecisionprocessesofSociety.Itconcernsa cluster of actions and results concerning to that action (individual inputs like votes,preferences,judgments)into collectiveoutputs(e.g.,collectivedecisions,preferences of
Anyapproachbeitmanualstatisticalpredictionorbuildinga modelwhichwillpredictforus,boththeapproachesheavily dependondatasetsusedforthisprediction.Datasetsused tomakeconclusioncanbreakormakeamodel.Therefore, before reviewing specification of various algorithm and model used to predict a social choice. It’s necessary to considerseveralstepswhichgointomakingdatasetsuseful. Datatomakepredictionortrainamachinecanbecollected fromsocialmediaplatformlikeTwitter. Twitterprovides
©
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3671 ***
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 05 May| 2022 www.irjet.net
theopportunitytocollectdatafromitforresearchpurpose forwhichmanytoolsandlibraryareprovidedbypythonand google colob. But this data is raw and unstructured consisting large amount of information which could be removedformoreoptimizeandquickmodel.
2.1 Natural Language Processing
Fig 2: NLPPipeline
NLP uses Language Processing Pipelines to read and decipherhumanlanguagestomachinereadableform.These pipelinesconsistoffivesubprocesses.Thatbreakstextinto smallchunks,reconstructsittobeanalyzed,andprocessed tobringusthemostrelevantinformationwhendoingtext analysis.
Sentence cleaning:Clearallwhitespacerows,html tags,smileyandsegmentparaintosentence.
Tokenization:BreakSentenceintoworks(Token)
Stop Words removal: Remove prepositions and postpositionsfromtokens.
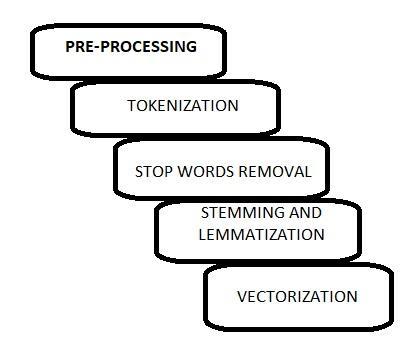
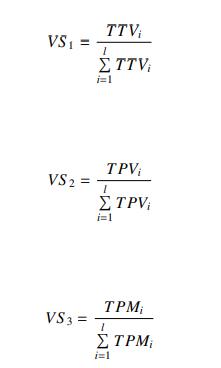
Stemming and Lemmatization: Stem token into base form and check grammar or if word is meaningful.
Vectorization: Convert textual data into numeric vectorform.
2.2 Approaches to predict Social Choice
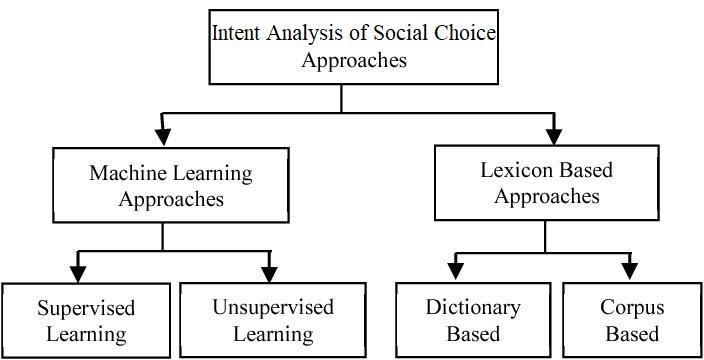
Onceproperlystructuredandcleandataisachievedvoter intentispositive,negativeorneutralcanbepredictedusing eitheroflexiconbasedmodelorasupervisedmodeloran unsupervisedmodel.Inthis paperwewilllimitourselfto priortwoapproaches.
2.2.1 lexicon based Model
The lexicon model based approach, make use of pre preparedsentimentlexicontoscoreadocument.Thepre
e ISSN: 2395 0056
p ISSN: 2395 0072

prepared sentiment lexicon should contain a word and correspondingsentimentscoretoitorawordsormultiword taggedaspositive,negativeorneutral.Thelexiconmaybe developed manually, for example, Taboada6 or semi automaticallyderivingsentimentvaluesfromresourcessuch asWordNet,forexample,EsuliandSebastiani7
Fig 3: LexiconModel
Topredicttheoverallsentimentofadocument,aformula,a functionoranalgorithmisneededtocalculatethepolarityof intentofvoter.
After finding sentiment score (sentiment polarity and magnitude) of each tweet of the datasets, Barkha Bansal4 usedbelowformula to calculatetotal positivevolumeand totalpositivemagnitudeineachdataset.Finally,voteshare for each party was statistically calculated using three methodspresentedinfollowingequations.
© 2022, IRJET | Impact
7.529 | ISO 9001:2008 Certified Journal | Page3672
Factor value:
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 May| 2022 www.irjet.net p ISSN: 2395 0072
Fig 4: IntentAnalysisApproach
2.3 Machine Learning Approaches
Machine-learning methods to model a machine which can predict user intent of social choice can be supervised learning based or unsupervised learning based. Most research till now has been constricted to deploying a supervisedmodelforintentpredictionwhichafterfirstfour preprocessing steps either use a ‘bag of words’ approach (usually cleaned stemmed and lemmatized) or feature vectorization of corpus as independent feature vector (CounterVectorization)orMultiwordtermsfeaturevector (Tfidfvectorizationorhashingvectorization)toconverttext intonumericalformatforfurthercalculationandtraining Supervisedlearningapproacheswhichweintendtocoverin thisliteraturereview isusedtodevelopa classifier which canlearnfromminedfeaturesfromsocialmediaandclassify intentofuserintopositiveornegativeorneutraldepending onmodelisbi-classifierortri-classifier.
The most used Supervised machine-learning methods in intent analysis are the support vector machine (SVM) [8,9] ,NaiveBayesmethod [10] ,MaxEntandlogisticregression
2.3.1
Maximum Entropy Model
ModelbasedonmaximumentropyadheretoProbabilistic classification. In this model instead of making inferences basedonincompleteinformation,wedrawthemfromthat probability distribution that has the maximum entropy permittedbytheinformation.
2.3.2 Naïve Bayes Model
NaïveBayesisasupervisedmachineclassificationalgorithm, builtonBayes Theorem. Dueto its Naïve assumption that predictors hold Conditional Independence among themselvesitiscallednaïvebayes.Itisbasedonassumption thatallthefeaturesinaclassareunrelated.
BayesTheorem:
Let’s take two events A and B. Then formula to calculate posteriorprobabilityP(B/A).
Posterior probability of single feature is easy to calculate butwhenwehavetwoormorefeatures,wecangetazeroprobabilityproblem.Therefore,westartbymakingaNaïve assumptionofconditionalindependenceamongfeaturesto calculateposteriorprobability.
Supposewehave,Predictors:[X1,X2]andTarget:Y Theformulatocalculatetheposteriorprobabilityis-
TakingConditionalIndependenceforP(X1,X2/Y=1),
Maximum entropy distributions function could be representedas.
This is the formula to calculate the posterior probability usingNaïveBayesClassifier.
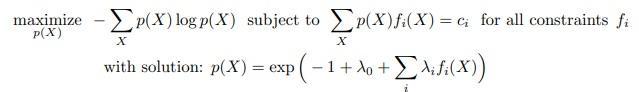
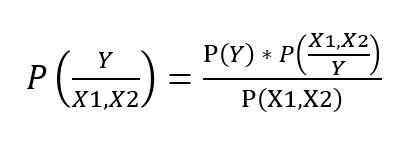
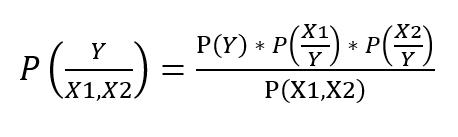
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3673
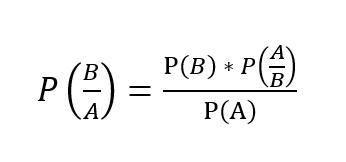
International Research Journal of Engineering and Technology (IRJET)
e ISSN: 2395 0056
Volume: 09 Issue: 05 May| 2022 www.irjet.net p ISSN: 2395 0072
2.3.3 Support Vector Machine
2.3.5 Deep Learning
Deeplearningisanadvancerepresentationofunsupervised learningwhichoffersasetofalgorithmsinspiredbyhowthe human brain works, they are called neural nets. Deep learning architectures are being used heavenly for text classificationbecausetheyareprovingtoperformatsuper highaccuracyandprecision
Thetwodeeplearningarchitectureswhicharemostlyused for text classification are Convolutional Neural Networks (CNN)andRecurrentNeuralNetworks(RNN).
Deeplearningworkssimilartohowthehumanbrainworks tomakedecisions,usingdifferenttechniquessimultaneously toprocesshugeamountofdatacollectingfromsocialmedia


Fig:5 Data Visualization of various Algorithms
SVMisa regressionandclassificationsupervisedmachine learningalgorithm.InSVM,weaimtofindthebestdecision boundarycalledhyperplaneamongthedatapointsthatare plotted in n dimensional space where n is the number of features. For a n dimensional space i.e. n feature visualization of data set, the hyper plane has (n 1) dimensions. SVM can be used for Linearly separable data called Linear SVM model and also non linearly Separable data using a special SVM called Kernel SVM. Below Expression is representation of one such kernel function whichcouldbeusedtoseparatenonlineardata.
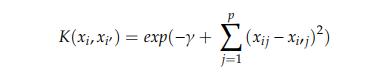
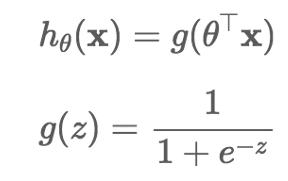
2.3.4 Logistic Regression
Alogisticregressionis likeageneralizedlinearmodel but with a canonical link function. i.e. output of generalized linear function is squashed in range of [0,1] using the sigmoidfunction(logisticfunction).Sigmoid Functionisan S shaped curve that is discrete unlike continuous output resultinlinearclassification.Ifoutputvalueisgreaterthan threshold value or lower than a minimum threshold. we assignitaslabel1,elseweassignitalabel0respectively In terms of easy computation, it is the best model among othergeneralizedlinearmodelsforbinaryclassificationor regression Function used to calculate the Logistic regression.
3. CONCLUSIONS
TherearelotsofmodelusingArtificialintelligencetopredict election up to acceptable accuracy but still each day with newensembleorbetterdataprocessingthisaccuracycanbe furtherincrease.DeeplearningmodelsuchaRNNwhichcan train from unlabeled data and identify the hidden pattern andrelationalamongthatdata,holdsthefutureofmachine model which can predict social choice of voters by using theirminedintent.
[1] Tumasjan A, Sprenger TO, Sandner PG, Welpe IM. “Predicting elections with twitter: What 140 characters revealaboutpoliticalsentiment.” Icwsm. 2010;10(1):178–
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3674
REFERENCES 185.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 May| 2022 www.irjet.net p ISSN: 2395 0072
[2] JungherrA,JurgensP,SchoenH.“Whythepirateparty won the german election of 2009 or the trouble with predictions:Aresponseto ¨ tumasjan,a.,sprenger,to, sander, pg, & welpe, im ”predicting elections with twitter: What 140 characters reveal about political sentiment?” Social science computer review. 2012;30(2):229 234.
[3] FranchF.(WisdomoftheCrowds)2:2010UKelection prediction with social media. Journal of Information Technology&Politics.2013;10(1):57 71.
[4] Barkha Bansala, Sangeet Srivastava. ”On predicting electionswithhybridtopicbasedsentimentanalysisof tweets”.ProcediaComputerScience,Volume135,2018, https://miro.medium.com/max/1400/1*o4Dy1w4n2kDOLA 8UEwGC9g.pngPages346 353
[5] Marozzo F, Bessi “A. Analyzing polarization of social mediausersandnewssitesduringpoliticalcampaigns. SocialNetworkAnalysisandMining”.2018;8(1)
[6] TaboadaM,BrookeJ,TofiloskiMetal. “Lexiconbased methodsforsentimentanalysis”.ComputLinguist2011; 37:267 307.
[7] Esuli A and Sebastiani F. SentiWordNet: “a publicly available lexical resource for opinion mining”. In: Proceedingsofthe5th
[8] CortesCandVapnikV.“Supportvectornetworks”.Mach Learn1995;20(3):273 297.
[9] Vapnik VNand Vapnik V. “Statistical learning theory” . NewYork:JohnWiley&Sons,1998.
[10] Zhang H. “The optimality of naive Bayes”. In: Proceedings of the seventeenth Florida artificial intelligenceresearchsocietyconference,MiamiBeach, FL, 12 14 May 2004, pp. 562 567. Palo Alto, CA: AmericanAssociationforArtificialIntelligence
BIOGRAPHIES

Ankita Sengar
AssistantProfessor +8yearExperenice AreaofInterest: Machinelearning,IOT © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3675
