International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Department of Computer Science, Kamla Nehru Mahavidyalaya, Nagpur, India1
Assistant Professor, Department of Information Technology, Dr. N. G. P Institute of Technology, Coimbatore, Tamil Nadu, India2
Assistant Professor, Department of Computer Science and Engineering, Vishwakarma Institute of Technology, Pune, India3
Assistant Professor, Department of Computer Science and Engineering, College of Engineering, Roorkee, India4 Research Scholar, Department of Computer Science and Engineering, Chaudhary Devi Lal University, Sirsa, Haryana, India5 ***
Abstract Sentiment Analysis is an expression that alludes to an assortment of methodology for classifying feeling addressed in text. Sentiments investigation, frequently known as data mining, is a Natural language Processing (NLP) technique for characterizing tweets as good, pessimistic, or nonpartisan. The fundamental issue while managing Twitter is the tweets. We have presented the methodology of breaking down the sentiments of tweets obtained from the sentiments 140 dataset utilizing the most significant and reliable machine learning classifiers: Decision trees, random forest, support vector machine, Naive Bayes, logistic regression and XGBoost. The accuracy estimations are then used to assess the capacity of the calculation we developed in this work. The dataset we used in this study comprises of 1,600,000 tweets recovered utilizing the Twitter API. The issue with this approach is figuring out which model is generally appropriate for breaking down tweet Sentiments. In this space, various methodologies for sentiment analysis are presently being used, which are momentarily looked into in this article we utilized an supervised machine learning approach in this scenario and evaluated about the few calculations and stated below. We evaluated every one of the most significant chose classifiers from a wide assortment of classifiers to see which of the carried out models gave us the best exactness.
:Estimation,Efficacy,Sentimentanalyzing,dataset,MachineLearningalgorithms,Twittertweets.
SentimentAnalysisisawordthatalludestothemethodinvolvedwithfollowingclientperspectivesoropinionsacross a few channels. In the present advanced world, different regions or significant innovation spaces have created ways of inspiring client or client feelings or sentiments about an item or administration. The universe of computerized stages is quickexpandingorfillinginthe presentconditions.Quitepossiblythemostimportantthinginlayingoutapresenceina seriousmarketisone'sstanding. Sentiment examinationpermitsus tomonitorwhatclientorclientseesareona virtual entertainmentstageforaspecifichelporitem.
Since it works with human composed content, feeling examination requires natural language processing. While managing human composed material, we generally utilize the natural language toolkit, which is utilized to deal with the text.Therearenumerousweb basedentertainmentstage,weareindividualsusedtosharetheirinsightandpointofview. There are numerous utilization of the sentiment analysis , for example, securities exchange expectations, governmental issues,Healthcareissues,advertising,filmsuggestionsandsomeofthemarecommendedinthisstudy.
ThefirstisTwitter,whichisastagethatconsolidatessentimentsinvestigation.Twitterisafundamentalstagewherea great many people from everywhere the world examine or distribute their considerations or articulations on a specific subject.Consistently,alargenumberofclientsuseTwittertoconveytweets.
Then,atthatpoint,there'sbusiness,whereorganizationshaveconceivedstrategiespointedtowardzeroinginonclient criticism or sentiments in regards to newly sent off items. This is the main standard, as it permits the association to supportitemcreationtosomeevenoutjustbasedongreatclientcriticismormind settowardtheitem.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Politicalmissionsareonemorehugeangletothinkaboutwhileleadingsentimentanalyzing.Consistently,around60% of the populace in India tweets political comments on Twitter. Individuals are acquainted with communicating their perspectives on decisions. We will actually want to observe individuals' contemplations on a given applicant utilizing Twitteropinionongovernmentalissues.
Wecandistinguish theopponent's approachthatisproducingideal inputfromclientsinthemarketinvolving feeling investigationforadvertisingorcutthroatexploration.Wewillactuallywanttoinspectadversaries'promotingsystemsto workontheiradministrationorkeepupwiththeirsituationintheseriousadvertisingclimate.
Dataset Sentiment 140 Dataset
Preprcoessing Feature Vectoririzationn Dataset Segmentation
Machine Learning ClassifiersResult Visualization
Fig-1:Flowdiagramofoverallprocess
Thesentiment140dataset,whichcanbefoundonkaggle,wasutilizedinthisexamination.Thereare1.6milliontweets inthedataset.TheTwitterAPImightbeutilizedtoacquirethesetweetsfromTwitter.Therearethreeobjectiveclassesfor thetweets.Theyaremarked'0'fornegativetweets,'2'forneutraltweets,and'4'forpositivetweets.
Simply by giving the suitable username, the Twitter API is used to recover client profile components and other indispensable realities from Twitter. The information is accumulated and converted into a configuration that can be advantageously taken care of into the prepared model. The Twitter API content's fundamental capacity is to return this information,whichisthenutilizedascontributiontothemodel.[20]
The NLTK comprises for the most part of a few libraries for text classification, marking, stemming, tokenization, and parsing.TheNLTKlibrarywasusedbroadlyintheclassification,anditadditionallydirectedlemmatization.Forexecution, weusedpandas,scikit Learn,Matplotlib,Numpy,anddifferentlibraries.[21]
We should preprocess our information without preprocessing while at the same time working with text based information.Therecommendedmodelcan'tbetakencareofthedataset.
Weatfirstbelievereachtweetinthetwitterdatasetfromuppertobringdowncaseinthisstage.
Thetextcleaning method beginswith erasinganycommotion,forexample, HTML labels<>,URL joins,Hashlabels#, the@sign,trailedbyausername,dates,oraparticularwordslike('rt').[1]
Tokenizationisdoneoutafterthenoiseremoval stage.Tokenizationisthemostcommon wayofseparatingmessage, words,orsentencesintomoremodestpartsknownastokens.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Stopwordswill bewordsthatareroutinelyutilizedina languagehoweverhavelittleeffect.Thetokenizedwordsfor eachtweetwerethenhandledforstopwordevacuationaftertokenization.[2]
The Normalization technique is a vital stage in preprocessing. Standardization is the method involved with changing overanassortmentofwordsintoamorecoherentrequest.Thecalculationaccomplishesamoreexactorderbychanging thewordsovertoastandardconfiguration.[3]
In this stage, the Porters Stemmer Algorithm will be utilized. The stemming technique's primary objective is to separatea wordintoitsstemword orrootword.Considerthedrawingsabovefor instance.Thestemword"wait"might beutilizedtochangeoverthewords"waiting","waited"and"waits.""Computing""computerized"and"computer"maybe generallydecreasedtotheirstemword,"compute".
In this stage, the word goes through a kind of progress to get back to its unique structure. For example, 'drove' was renamed 'drive,' and 'driving' was renamed 'drive.' The name WordNetLemmatizer is utilized in this stage to depict the lemmatizationinteraction.[4]
To work on the model's computational rightness, we utilized term frequency and inverse document frequency vectorizer [22]The Term Frequency Inverse Document Frequency Vectorizer is a capacity or procedure for changing textual information over to numeric information design. We should manage numeric information in the AI model; along these lines we use a Term Frequency Inverse Document Frequency Vectorizer to change our text based input over to numericinformation.
Precedingtakingcareoftheutilizeddatasettothemodel,weshouldisolateitintotwoessentialparts:thepreparation datasetandthetestingdataset,withageneralparcelproportionof80%ofthedatasetfortrainingand20%ofthetesting datasetfortesting.
OrderinAI,thereisdifferentclassifiersaccessibleforarrangement;someofthemareexaminedaboveinthispart.
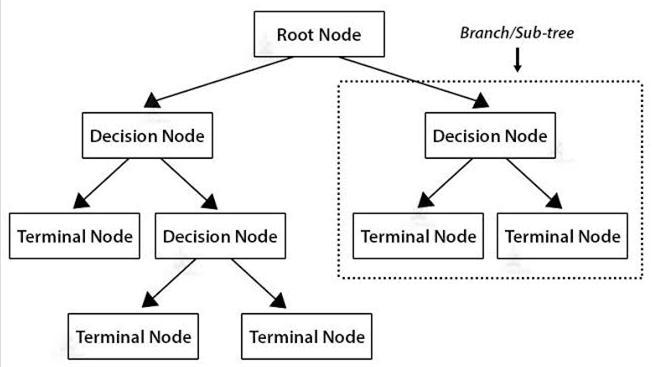
ThisclassifiercreatesdecidesinEnglishexpressionsthatareeasytocomprehend.Decisiontreescanbeutilizedtotake care of issues including arrangement or relapse. No presumptions are made about the fundamental conveyance of information in Decision trees. The model's shape isn't foreordained; all things being equal, it squeezes into the best practicalarrangementrelyingupontheinformation.[5]
Fig 2: DecisionTreeClassifier.[6]
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3052
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
ADecisiontree,asthenameinfers,isachoiceemotionallysupportivenetworkthatisaddressedby atree likedesign. Theroothub,otherwisecalledtherootorstartinghubofthetree,isthemainpieceofachoicetree.Apreparationdataset isisolatedinto branchesbyutilizingdecisiontrees,and afterwardfurtherseparated intosubbranches.The decisionwill keep on developing until it arrives at the issue's last stage. It stops at the point that the leaf hub, otherwise called the terminalhub,isjoinedin,andthecalculationendsitsexecution.
The decision tree is outlined in the chart above, with the root hub isolated into decision hubs, which are their sub hubs, and the decision hubs isolated into the terminal hub, which is the last advance of the calculation and where the strategyexecutionwrapsup.
TherandomforesttechniqueismadeutilizingDecisiontrees,inwhichcountlessDecisiontreesarejoinedtogivean outcomerelyinguponmostofvotes.Asrecentlysaid,anarbitraryrandomforestcalculationistalkedabout.
Randomforestisanessentialyetsuccessfuldecisiontree basedgroupapproach.ItcreatesvariousDecisiontreesand arranges the information tests independently. Their decisions are then added together to distinguish the class with the mostvotes,bringingdownalloutbotches.PackingisthemethodinvolvedwithbrushingDecisiontrees.[7]
Fig 3: RandomforestClassifier.[9]
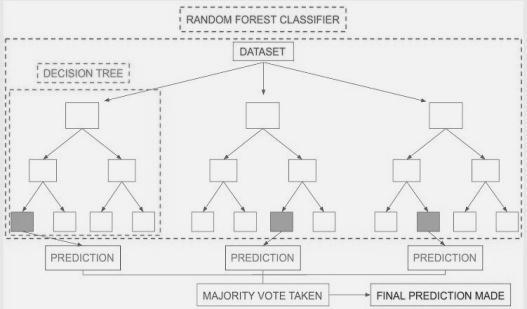
When another information thing is gotten, every one of these trees groups it, and the outcomes given by them act as decisions in favor of each class. At long last, every one of the votes is counted, and the class with the biggest number of votesispickedasthenewdatapointclass.[8]
Atlonglast,theDecisiontreeisfoundtobethefundamentalandbuildingsquareoftherandomforestclassifier.
ASupportVectorMachineisadirectedAIprocedurethatisutilizedtotackleissueslikeclassificationandRegression. Inanycase,itisforthemostpartutilizedforarrangementchallengesinmostofcircumstances.
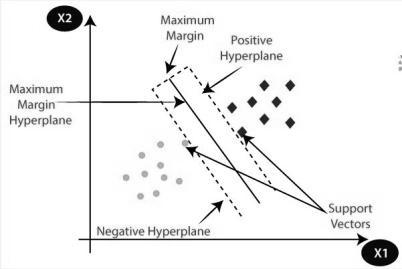
Thehyperplaneisutilizedtoarrangethetwoseparateclassesaddressedintheimageunderneath.
Fig 4: SupportVectorMachine.[10]
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Theobjectiveofthisapproachistocreateahyperplanethatcanbeutilizedtosegmentn layeredspaceintoclassesso the calculation can without much of a stretch spot elements in the suitable classification. The support vectors that contributeinthemakingofthechoicelimitarepickedbythecalculation.
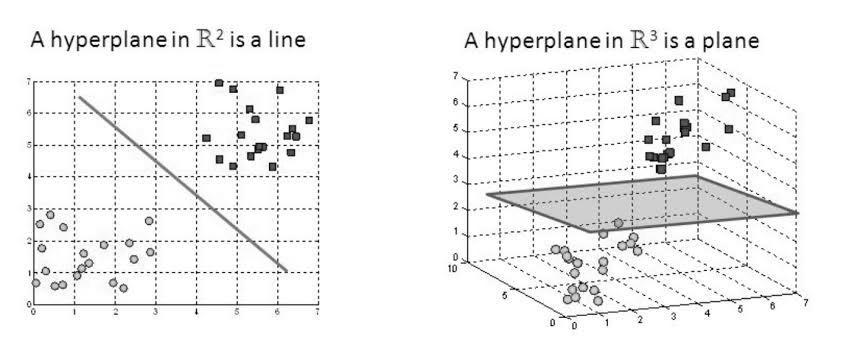
Order in Support vector machine depends on the translation of the hyper plane, what separates items into two classifications.Correspondingtothehyperplane,quiteafewperipheralplanescanbedrawn.Thealgorithmpicksthebest peripheralplanewiththebestseparationfromthehyperplane,andtheinformationfocusesnearesttoitarealludedtoas supportvectors.[11]
The margin is the distance between the hyperplane and the closest support vectors. The distance between the two classesisolatedbythe best notsetinstone.Themostextrememarginhyperplaneistheplanethathasthe best distance betweenthetwoclasses.[12]
The most fundamental factors that assist with arranging the elements in the calculations are hyperplane. The two delineationsoutlinedintheabovepicturesarethefirstwheretherearetwo informationhighlights,andthehyperplaneis just a line with support vectors on the two sides of the hyper plane. Consider the situation where the quantity of informationattributesisbiggerthantwo,saythree,andthehyperplaneturnsintoatwo layeredplane.Atthepointwhen the quantity of qualitiessurpassesthree, asfoundin theimageabove, itturns outtobeincrediblyhardtoanticipatethe result.[13]
Fig-5:SupportVectors[13]
,,,11 nnxyxy
wherexi addressesagenuinevectorandyi indicatestheclasstowhichxi hasaplacewithaworthof 1,1.Ahyperplaneischaracterizedasfollowsandisutilizedtoupgradethedistancebetween thetwoclassesy=1, 1.[12]
Forinstantthedatapoints
The Bayes hypothesis is utilized to make a kind of probabilistic classifier known as Naive Bayes. It's a model of contingent likelihood. In many managed learning settings, a likelihood model is utilized. Naive's Bayes classifiers can prepareinanexceptionallyproductiveandviableway.[14]
The Naive Bayes calculation is a direct methodology for applying the Bayes hypothesis to grouping issues. [16] What makes it novel is that it is named after the Bayes: It utilizes Bayes hypothesis to move the probabilities of seeing info attributes that compare to classes to a likelihood dissemination over classes. It is gullible on the grounds that it accepts thatprescientqualitiesarefreetogether,whichimprovesonlikelihoodcalculations.[17]
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Fig 6: NaiveBayesAlgorithm.[15]
The XGBoost technique is an inclination supported decision tree execution that produces extraordinary speed and precision and overwhelms datasets on characterization and relapse issues. XGBoost is a decision tree based machine learning calculationthatmightbeutilizedtodeal with relapseandcharacterizationissues. To expandits presentation, it utilizes the inclination supporting engineering.[20] The XGBoost calculation is an adaptable, convenient, and productive technique.XGBoostutilizestheinclinationsupportingstructuretochipawayatMachinelearning procedures.XGBoostis an answer for an assortment of information science issues, giving speedy and dependable responses. Ensemble method, thenagain,blendsdifferentmachinelearningtechniquestoresolveaparticularissue.Itoutflankssinglemachinelearning techniqueswithregardstoprecision.[23]
Fig 7:XGBoostAlgorithm.[25]
WeightsassumeasignificantpartinXGBoostalgorithm.Everyoneoftheautonomousfactorsarethenstackedintothe decisiontrees,whichutilizesthepredefinedweightstoanticipatetheresults.Theloadsofthetreeerroneouslyevaluated were changed and placed into the subsequent decision tree. Individual classifiers are then connected together to make a moreproficientandcomparethemodel,asfoundintheoutlineunderneath.TheXGBoostalgorithmcanpromptlyaddress relapse,grouping,ratingandclientdeterminedexpectationchallenges [25]
Itisthebestanddirectmethodologyforanticipatingtheclassificationmark.Itfindschoicelimitsinacomponentspace and endeavors to anticipate the name in light of those cutoff points. Sigmoid function is applied on the given inputs in binaryclassification.[24]
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Fig 8:LogisticRegression.[26]
Subsequent to taking care of the informational index into the fitting model, evaluating the model's performance is fundamental.
True positives, true negatives, and false positive, false negative make up the disarray lattice, which has a plain like design.Thedisarraylatticeshowsgenuineclassesofexamplesinthelineandanticipatedclassesofeventsinthesection.
Table1. ConfusionMatrix
Actual
Positive (1) Negative (0)
Predicted
Positive (1)
TruePositive (TP) FalsePositives (FP)
Negative (0) False Negatives(FN) TrueNegatives (TN)
Upsidesthatarevalid TruePositives
Themodel'sprojectedanticipatedworthandtherealwortharebothpositive.
Negativesthatarevalid TrueNegatives
Themodel'sprojectedanticipatedworthandtherealwortharebothnegative.
Up sidesthataren'taccurate FalsePositive
Albeitthemodelprojectedapositiveoutcome,thegenuineoutcomeisnegative.
Negativesthataren'tcorrect FalseNegatives
Albeitthemodelprojectedanadverseoutcome,thegenuineoutcomeispositive.
After we've finished our expectation, we'll have to make a grouping report that remembers data for execution boundarieslikePrecision,Recall,andF1 Score.
It'sdeterminedbypartitioningthequantityofrightexpectationsmadebythealloutnumberoffiguresmade.Aboveis theconditionforascertaining
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3056
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
TPTNFPFN TPTN Accuracy ...(1)
We wanted True up sides, True Negatives, False Positives, and False Negatives before we could decide the accuracy. Theprecedingthingscanbeobtainedbyconfusionmatrix.
7.2.2 Precision
Precisionischaracterizedastheamountofgenuinepositiveandfalsepositiveexpectationsisolatedbythequantityof genuineup sides.
TPFP TP Precision ...(2)
7.2.3 Recall
Thequantityofgenuineup sidesisolatedbytheabsoluteofgenuineup sidesandfalsenegativesisknownasrecall.
TPFN TP Recall ....(3)
7.2.4
AnF1ScoreisdefinedastheHarmonicmeanofPrecisionandRecall. F1_Score(2*(Precision*Recall))/(PrecisionRecall) .....(4)
In this study, we have utilized different classifiers to do the sentiment analysis on tweets utilizing the sentiment 140 dataset available on Kaggle. The dataset used here comprises of 1.6 million tweets that have been partitioned into two gatheringsfromtrainingandtestingsegments:80%fortrainingdatasetand20%toconjectureexactnessoraccuracy. We procure an accuracy score of support vector machine of 94.01%, random forest of 89.71% , Naive Bayes of 83.34%, Decisiontreeof74.03%,XGBoostof92.14%&Logisticregressionof90.70%
Algorithm Accuracy
SupportVectorMachine 94.01% Randomforest 89.71% NaiveBayesTheorem 83.34% DecisionTrees 74.03% XGBoost 92.14% LogisticRegression 90.70%
Theaccuraciesobtainedbythedistinctalgorithmisplottedingraphicalformat.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056 Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Plot of Classifiers with Accuracies
Support
Fig 9:GraphicalillustrationofResults.
This examination tries to offer an extensive comprehension of machine learning techniques that might be utilized to dissect sentiment in Twitter messages. In wake of assessing the models we have a carried out in this study we got the unmistakableaccuracyofeveryclassifiers. Wecomeout totheconclusionthatthesupportvectormachine andXGBoost has accomplished the most noteworthy accuracy of 94.01% and 92.14% which states that the model is equipped for analyzingthesentimentsofthetweetsinacriticalway.
[1]. HamoudAA,AlwehaibiA,RoyK,BikdashM.ClassifyingPolitical TweetsusingNaive'sBayesandSupport Vector Machine. InInternational Conference on Industrial, Engineering and other Applications of Applied Intelligent Systems2018Jun25(pp.736 744).Springer,Cham
[2]. Rushee KI, Rahim MS, Levula A, Mahadavi M. How Australian Are Copying with the Longest Restrictions: An ExploratoryAnalysisofEmotion&SentimentfromTweets.InAdvancedInformationNetworkingandApplications ANA2022.LectureNotesinNetworksandSystems,Vol451.Springer,cham.
[3]. NaingHw,ThweP,MonAC,NwN.AnalyzingSentimentLevelofSocialMediadatabasedonSumandNaiveBayes algorithms. InInternational Conference on Big Data Analysis and Deep Learning Applications 2018 May 14 (pp. 68 76).Springer,Singapore.
[4]. Ye Z, Liv W, Jiang Q, Pan Y A. Cyrptocurrency Price Prediction model based on Twitter Sentiment Indicators InInternationalConferenceonBigDataandSecurity2021Nov26(pp.411 425).Springer,Singapore.
[5]. DangetiP.Statisticsformachinelearning.PacktPublishingLtd;2017Jul21.
[6]. [internet]. 2022 [cited 4 April 2022]. Available from: https://www.google.com/amp/s/techvidvan.com/tutorials/decision tree in r/%3famp=1
[7]. Sakib S, Yasmin N, Tanzeem AK, Shorna F, Alam SB. Breast Cancer Detection and Classification: A Comparative AnalysisUsingMachineLearningAlgorithms.InProceedingsofThirdInternationalConferenceonCommunication, ComputingandElectronicsSystems2022(pp.703 717).Springer,Singapore.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056 Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
[8]. Kumar P, Bhatnagar A, Jameel R, Mourya AK. Machine Learning Algorithms for Breast Cancer Detection and Prediction.InAdvancesinIntelligentComputingandCommunication2021(pp.133 141).Springer,Singapore.
[9]. IntroductiontoRandomforestinMachinelearning[internet].EngineeringEducation(EngEd)Program ׀ Section. 2022 [cited 4 April 2022]. Available from: https://www.section.io/engineering education/introduction to random forest in machine learning/
[10]. SVM Interview Questions׀ Questions on SVM to Test your skills [internet]. Analytics vidhya. 2022 [cited 4April 2022]. Available from: https://www.analyticsvidhya.com/blog/2021/05/top 15 questions to test your data science skills on svm/
[11]. RuthJA,MaheshVG,UmaR,RamkumarP.AHierarchicalMachineLearningFrameworktoclassifyBreast TissueforIdentificationofCancer.InProceedingsofthe11thInternationalConferenceonComputerEngineering andNetworks2022(pp.504515).Springer,Singapore.
[12]. Padmavathi MS, Sumathi CP. A Novel Approach Using Support Vector Machine for Outlier Removal and Multilayer Perceptron in Classifying Medical Datasets. InInternational Conference on Soft Computing and Signal Processing2019Jun21(pp.339 352).Springer,Singapore.
[13]. SupportVectorMachine IntroductiontoMachineLearningAlgorithms[internet].Medium.2022[cited4 April 2022]. Available from: htttps://towardsdatascience/support vector machine introduction to machine learning algorithms 934a444fca47
[14]. Shrivastava AK, Singh PK, Kumar Y. A taxonomy on machine learning based technique to identify heart disease. InInternational Conference on Next Generation Computing Technologies 2018 Nov 21 (pp. 13 25). Springer,Singapore.
[15]. Navie Bayes Algorithm [internet]. Medium. 2022 [cited 4 April 2022]. Available from: https://kdagiit.medium.com/naive bayes algorithm 4b8b990c7319.
[16]. Omondiagbbe DA, Veeramani S, Sidhu AS. Machine Learning classification techniques for breast cancer diagnosis. InIOP Conference Series: Materials Science and Engineering 2019 Apr 1 ( Vol. 495, No. 1, p. 012022). IOPPublishing.
[17]. LiuYH.PythonMachineLearningByExample.PacktPublishingLtd;2017May31.
[18]. Gupta P,Sehgal NK. IntroductiontoMachineLearningintheCloud withPython:Conceptsandpractices SpringerNature;2021.
[19]. Twitter sentiment analysis: Implement twitter sentiment analysis model [Internet]. Analytics Vidhya. 2021 [cited 2022May20]. Available from:https://www.analyticsvidhya.com/blog/2021/06/twitter sentiment analysis a nlp use case for beginners/#:~:text=Sentiment%20analysis%20refers%20to%20identifying,about%20a%20variety%20of%20to pics.
[20]. Joshi MM, Kambale Ms, Shastry NS, Khan MO, Nagarathna A. A Comprehensive approach to misinformation analysis and detection of low creditability News. InInternational Conference on Soft Computing andSignalProcessing2021Jun18(pp.23 33.Springer,Singapore.
[21]. Brijpuriya S, Rajalakshmi M. Deployment of Sentiment Analysis of tweets using various classifiers InProceedings of International Conference on Deep Learning, Computing, and Intelligence 2022 (pp. 167 178). Springer,Singapore.
[22]. Bhargavi K, Mashankar P, Sreevarsh PV, Biolikar R, Ranganathan P. Machine Learning Based Sentiment Analysis Twords Indian Ministry. In Computational Vision and Bio Inspired Computing 2022 (pp. 381 391). Springer,singapore.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056 Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
[23]. Kunte A, Panicker S. Personality prediction of social network users using ensemble and XGBoost. InProgressinComputing,analyticsandnetworking2020(pp.133 140).Springer,Singapore.
[24]. vasiyani P, Prakash P, Santhivel V. A comparative Study of Students Online Learning During Pandemic UsingMachineLearningModel.InICCCE2021,2022(pp.17 27).Springer,Singapore.
[25]. Nisha KA, Kulsum U, Rahman S, Hossain M, ChakrabortyP, Choudhary T. A Comparative Analysis of Machine ELarnign Approaches in Personality Prediction Using MBTI. InComputational Intelligence in Pattern Recognition2022(pp.13 23).Springer,Singapore.
[26]. Saxena GD, Tembhare NP. Analytical and Systematic Study of Artificial Neural Network. International ResearchJournalofEngineeringandTechnology.2022;9(3);653 658.