International Research Journal of Engineering and Technology
(IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN:2395-0072

(IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN:2395-0072
Dr. S. Venkatesh¹, R.Divya², S. Deepeka³ , V. Kousalya⁴
¹Assistant Professor, Department of Computer Science and Engineering, Jeppiaar Engineering college, Chennai 600119 2,3,4Student of Computer Science and Engineering Department, Jeppiaar Engineering College, Chennai 600119 ***
Music grouping is a music data recovery task whose goal is the computational comprehension of music semantics. For a given melody, the classifier predicts applicable melodic traits. In light of the errand definition, there are an almost endless number of characterization undertakings from types, dispositions, and instruments to more extensive ideas including music closeness and melodic inclinations. The recovered data can be additionally used in numerous applications including music suggestion, curation, playlist age, and semantic pursuit. In this classification Recurrent Neural Network(RNN) and Long Short Term Memory(LSTM) algorithms are used. There are many different music classification and these two algorithms are used to classify the music with the train accuracy of 94% and test accuracy of 75%.
Key words: Music genre classification, RNN(recurrent neuralnetwork),LSTM(longshorttermmemory)
There are various sorts of music genres available in the industry. However, the essential kinds will have a couple of guideline viewpoints that make it simpler to distinguish them. Types are utilized to tag and characterize various types of music in light of how they are made or in view of their melodic structure and melodic style. A model is constructed which will take in a melody as an information andanticipateorgroupthatspecifictuneinoneofthemusic genres. We will order among the accompanying fundamental sorts blues. traditional, country, disco, hip jump, jazz, metal, pop, reggae and rock. Themodel will be fabricated utilizing LSTM organizations. There are a couple ofessentialsyoushouldhavebeforeyoustartthis task.The principal thing you would require is the dataset. The music information which has been utilized for this venture can be downloadedfromkaggle.Notethatthisdatasetcontains10 classeswith100tuneswithineachclass.
Inthisexperiment,weusetheframescatteringfeatureasthe inputtotraintheLSTMRNN.TheLSTMRNNisimplemented based on Kaldi's nnet1 framework. In the testing stage, the frame scattering feature is used to get the soft max probability output of LSTM RNN . In the existing paper, we utilizethedispersinghighlightastheunderlyinginclude.The dissipating highlight is an expansion of the Mel Frequency Cepstral Coefficient (MFCC). The MFCC include is by and large extricated by utilizing little windows, whose regular length is 25 ms.Inanycase, whenthelengthofthewindow expands, thedata loss will become critical. For music whose prolonged stretch of time span portrayal is useful for grouping, the MFCC has an unfortunate arrangement execution.The dissipating highlight has been demonstrated fruitfulformusicsortsorder[16 18].Itassemblesinvariant, stable and instructive sign portrayals and is steady to deformations. It is registered by dispersing the sign data along various ways, with an outpouringof wavelet modulus administrators carried out in a profound convolution organization(CNN).
❖ Usedonlysixgenres.Namely:Classical,Electronic,Jazz, Metal,Rock,World.
❖ 79.71% classification accuracy is achieved in fusional segmentfeatures.
Every machine learning project has two main tasks: extractingfeaturesfromdataandtrainingamodel.Toextract audio and music features for machine learning purposes, choke frequency cepstral coefficients (MFCCs) are typically extractedfromsongsoraudio,andthesefeaturesareusedto train models. MFCC feature extraction is a method of extracting only relevant information from audio.To better illustrate this, when representing an audio file in digital form, the computer treatsthefileasawave,usingthex axis astimeandthey axisasamplitude.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
To train the Tensor model and keras is used. The model trained withRNN LSTMalgorithmshould bemadetorunat least for 50 epochs to obtain a train accuracy of 94% and henceitwillpredictthegenrecorrectly.
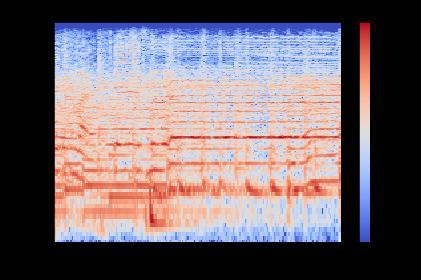
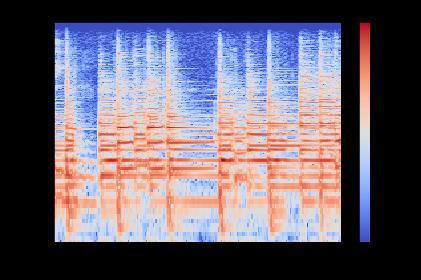
Since this representation format doesn't provide much informationabouttheaudioorthesong,itusessomething called a Fast Fourier Transform (FFT) to represent the audio in the frequency domain. FFT is a mathematical algorithmthatfindsmajorapplicationsinsignalprocessing used to transform the time domain into the frequency domain. This FFT is used totransform the input audio file and represent it in the frequency and time domains. A graph that displays audio data in the frequency and time domainsiscalledaspectrogram,asshown.
In this project almost 10 different genres are used for prediction. Namely blues. classical, country, disco, hip hop, jazz,metal,pop,reggaeandrock.
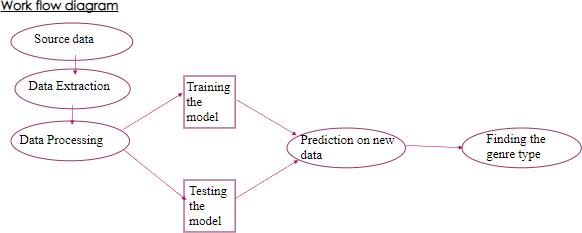
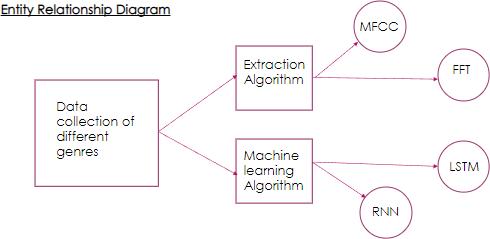
Figure.3.Workflowdiagramofproposedmodel
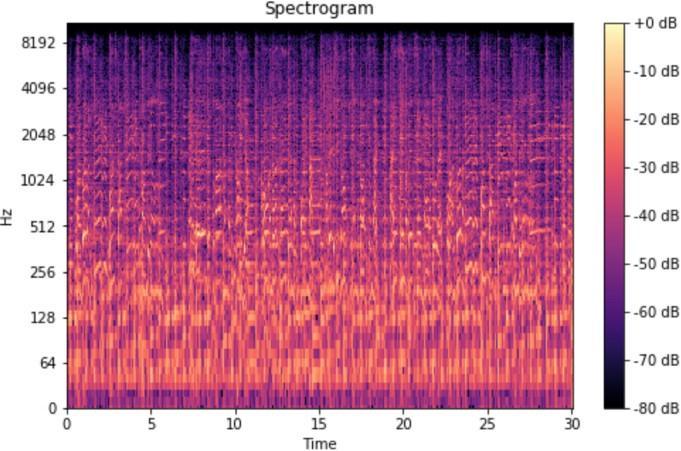
A spectrogram is a lot of FFTs stacked on top of one another. Itis an approach to outwardly address a sign's tumult, or plentifulness, as it changes over the long run at various frequencies. Here, the y axis is changed over completely to a mel scale, and the variety aspect is switchedovercompletelytodecibels(youcanconsiderthis the log size of the sufficiency). This is done as people can see a tiny and concentrated scope of frequencies and amplitudes and the human ear chips away at the guideline ofa logarithmicscale.The ordinaryspectrogram can be utilized for extricating highlights, however this actually contains some measure of extra data which isn't needed. Since the human ear works on logarithms instead of direct ones, we use chalk spectrograms that convert these spectrograms into logarithmic portrayals for more preciseportrayalbyeliminatingordisposingofundesirable elements.
Figure.4.Entityrelationshipdiagramfortheproposedmodel
There are a couple of modules which will be expected to be introduced in your PC/PC to begin. We will construct the wholeLSTM model utilizingTensorflow,codedinpython.We willbeworkingwithpython3.6orhigher(python3.6version oraboveisexpectedtouse).
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
Coming up next are the necessary python bundles to be introduced.
● Tensorflow Machinelearninglibrary
● librosa Speech handling library to extricate highlightsfromtunes
● numpy Mathematicalmodelforlogicalfiguring
● sklearn AnotherAImodel(Wewillutilizethis librarytopartpreparingandtestinginformation)
● json To jsonify the dataset (Explained in the followingsegment)
● pydub Tochangeover mp3 to wav records Thesemodulescanbeintroducedutilizingpiporconda
5.2. Visualizing signal waves and spectrogram for all genres:
Using matplot library signal waves for all the genres is shownfirsttounderstandthe frequencyofeachgenreand how it varies from others. Once the waves are generated
Figure.7.Spectrogramofblues
for different genres their signal strength is plotted against timevisually.
Figure.5.Signalwaveofblues
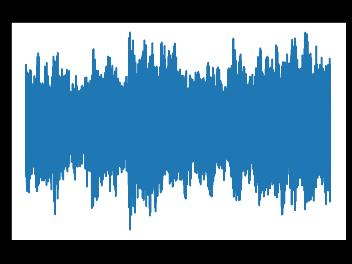
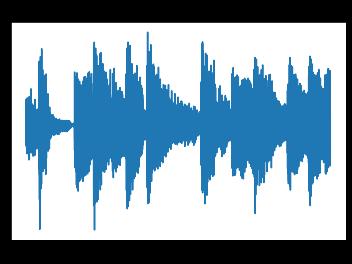
Figure.6.Signalwaveofrock
Figure.7.Spectrogramofrock
5.3. Datapre-processing:
The data set which we will use here is downloaded from Kaggle and has around 100 tunes or songs under every one of the 10 genre classifications. Every one of the tunes is 30 secondsinlength.Asreferencedbefore,thismeasureofdata is fundamentally less for preparing a LSTM model. To experiencethisissue,Isplit eachsoundfile into10portions, each section being 3 seconds in length. Consequently the quantity of tune or songs under each segment is currently 1000,whichisarespectablenumbertopreparethemodelto get a great precision. Since we have our data information prepared, we really want to extract the features which will be appropriate to feed in our organization network. The element extraction will be finished by utilizing MFCCs. Librosa is utilized to extricate the highlights from every one ofthesoundfragments.Wemakea wordreference,with the markorclassificationoftheclassasthekeyandeveryoneof theextricatedhighlightsfromeveryoneofthe1000sections asavarietyofelementsunderthatname.Whenwedothisin a circleforeach ofthe10classifications, wedumpthe word reference into a JSON record. This JSON record subsequently turns into our dataset on which the model will be prepared. Moving into the coding for dataset preprocessing, we initially characterize the quantity of portions and test pace of each section. The example rate is
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
expectedtorealizetheplaybackspeedofthemelody.Here we save it consistent for each fragment. We then make a circleinwhichweopenupeachmelodyrecordfromevery type envelope and split it into 10 fragments. We then remove the MFCC highlights for every one of that section and attach it to the word reference under the class name (which is additionally the organizer name).The above content will make sections and concentrate elements and dumpthehighlightsintodata_json.jsonrecord.
LSTM is utilized for preparing the model. In any case, beforewefabricatethemodel,weneedtostackthemodel into our program and split it into preparing and testing. ThisisfinishedbyopeningtheJSONrecordwhichwemade inthelastarea andchanging over it into numpy clusters for simple calculation.This technique is displayed in the beneath snippet.Afterstackingtheinformation,wesetup the information and split into train and test sets, as referenced prior. This is finished by utilizing sklearn's train_test_split work. Then, the LSTM network is made utilizing tensorflow. Here, we have made a LSTM organization of 4 layers, including two secret layers.The accompanyingcodepieceshowstheorganizationcreation. We introduce the model as successive and add one info layer with 64 as the quantity of neurons in that layer, one secret layer, one thick LSTM layer and a result layer with 10neuronsasthereare10types.Youcanexploredifferent avenues regarding more secret layers and test the exactness.
Wheneveryoneofthetechniquesandcapacitieshavebeen characterized, now is the ideal time to call them and train our grouping model!. First, we call the "prepare_datasets" capacity and finish the assessment date rate and approval informationrate.Approvalinformationisimportantforthe preparation information, with which the model isn't prepared and is utilized to approve the model. Approval set tells us, regardless of whether the information is performing great after the preparation is finished. Then, we call the "build_model" capacity to assemble an LSTM organization and accumulate it. Assembling is utilized to add the analyzer (which characterizes the learning rate) and the misfortune working out work. Here, we have utilizedclearcutcrossentropynumericalcapacity.Youcan peruse more about this on this connection here. Subsequent to arranging, model.fit() is utilized to prepare themodelonourinformation.Thepreparationcanrequire around 1 hour to 90 minutes relying upon your equipment. We would rather not continue to prepare our model to test it, henceforth subsequent to preparing,we save the model so we can utilize the saved document to
anticipate our new information. Toward the finish of the preparation,youcanseetheexactnessaccomplished.
Before we start with the testing and forecast of new melodies, weshouldcharacterizetheconstants. Ifyourecall that, we had prepared our model with tunes of length 30 seconds. Henceforth, the model will acknowledge melody fragments of 30 seconds all at once. So for this, we split the information melody to be anticipated into different fragments of 30 seconds in length. There are three unique situations for this Song length under 30 secs, melody length equivalent 30 secs andtune length more prominent than30secs.Formelodylengthunder
30 seconds, we show a blunder message as least isn't accomplishedandforatuneoflengthmorenoteworthythan 30seconds,wesplitthewholetuneintonumerousfragments of 30seconds each and feed each section into the model. Next, we load the saved model and characterize the various classesor kinds.The model will foreseea numberfrom 0to 9, and each number will address a sort as characterized during training. The model predicts a few classes for every single fragment of the info tune. The most anticipated classificationsconsolidatingeveryoneoftheforecastsofthe multitude of cut fragments of aspecific information melody, gives the last expectation. For instance, assuming that a melody of length 120 seconds is givenas info, it is initially parted into 3 sections of 30 seconds each and every one of the fragments is given as contribution to the model which predicts a specific type. The class which is anticipated generally number of times on normal is the class of the wholetune.
Expectation of class of a melody is finished by parting the whole tune into 30 second clasps and every one of the 30 second clasps are parted into 5 portions and afterward a forecastisdoneoneachfragment.Themostanticipatedclass outofallexpectationsistakenasthegeneralprediction.This is done as the model is trained with 3 seconds sound document bits. After successful prediction on new data we gotatestaccuracyandtrainaccuracyas75%and94%.
Long Short Term Memory (LSTM) networks are an expansion of RNN that broaden the memory. LSTM are utilized as the structure blocks for the layers of a RNN. LSTMs appoint data "loads" which assists RNNs with either giving new data access,failing to remember data or giving it
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN:2395 0072
significanceenoughtoaffecttheresult. Themodelpredicts a few kinds for every single portion of the input tune. The most anticipated music genre joining every one of the predictions of the relative multitude of cut sections of a specific input tune, gives the last prediction. For instance, ontheoffchancethatatuneoflength120secondsisgiven as information, it is initially parted into 3 fragments of 30 seconds each and every one of the sections is given as contribution to the model which predicts a specific kind. The genre which is anticipated generally number of times onnormalisthegenreofthewholetuneorsong.
[1] A. Meng, P. Ahrendt, J. Larsen, and L. K. Hansen, “Temporal feature integration for music genre classification,” Audio, Speech, and Language Processing, IEEETransactionson,vol.15,no.5,pp.1654 1664,2007.
[2] K. He and J. Sun, ‘‘Convolutional neural networks at constrained time cost,’’ in Proc. IEEE Conf. Comput. Vis. PatternRecognit.(CVPR),Jun.2015,pp.5353 5360.
[3] I.H.Chung,T.N.Sainath,B.Ramabhadran,M.Picheny,J. Gunnels,V. Austel,U. Chauhari,and B. Kingsbury,“Parallel deepneuralnetworktrainingforbigdataonbluegene/q,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis,2015,pp.745 753.
[4] David Opitz and Richard Maclin, Popular Ensemble Methods: An Empirical Study, Journal of Artificial IntelligenceResearch11,1999,pp.169 198.
[5] Y.SongandC.Zhang,“Content basedinformationfusion for semi supervised music genre classification,” Multimedia,IEEE Transactions on, vol. 10, no. 1, pp. 145 152,2008.
[6] Piero Baraldi, Enrico Zio , Davide Roverso , Feature Selection For Nuclear Transient Diagnostics, OECD Halden ReactorProject,January2007.