International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
Kamal1 , O. Sowmya2 , B. Bharath3 , B. Ramu4
1,2,3,4students, CSE department, SVP Engineering College, Andhra Pradesh, India. Guided by: Mr. K. T. Krishna Kumar Nainar, Associate professor & T.P.O ***
Daily tens of thousands of recent apps area unit other to the Google Play Store, with Associate in Nursing ever increasing variety of designers operating alone or in teams to create them noted, all whereas facing stiff competition from around the world. as a result of most Play Store apps area unit free, the revenue model for the way in app purchases, adverts, and AssociateinNursingmembershipscontributetoanapp'ssuccessishazy.Asaresult,insteadofthequantityofcashgenerated, thesuccessofanAssociateintheNursingapplicationisusually determinedby{thevarietytheamountthequantity}oftimes it's beenputinandalsothenumber ofclientevaluationsit'sreceivedoveritslife.However,thanksto inadequateormissing votes, these rating area units ofttimes compromised. what is more, theirarea unit respectable variations between numerical ratingsanduserreviews?ThegoalofthisanalysisworkistousemachinelearningalgorithmstopredicttheratingsofGoogle PlayStoreapps.
ELEMENTS: RANDOMFOREST,CONVOLUTIONALNEURALNETWORKS,K NEAREST.
Usersmighttransferandutilizeseveral third party appsfromthegoogleplaystore.Totransferandusetheseapplications ontheirhumanoidphonesandtablets,alegionof folksregisterspersonalinfowithGoogleandthird partybusinesses.oneof thefastest growingsegmentsofthedownloadedpackageapplicationtradeismobileapps. wedecideontheGoogleplaystore overallalternativemarkets attributabletoitsgrowingqualityanditsfastgrowth.Theratingsforhumanoidappswouldthen seemtouserssupportedtheregionwherevertheirdeviceisregistered.Developersandusersprimarilyconfirmtheinfluence ofmarketinteractionson futuretechnology.However, eachdeveloperanduser’ssquare measuresuffersfromanabsenceof awareness of common app markets' inner workings and characteristics. This project aims todeliver insights to grasp client demandshigherandsofacilitatedevelopers‘popularization.
Feedback is provided in 2 forms, text review and numeric ratings, as illustrated in Figure one. A text review, on the one hand, might contain positive or negative comments submitted by a user on a couple of specific apps or policies. This knowledge isextremely helpful for performing arts selling analysis, managing publicity, conducting product reviews, web promoterevaluation,givingproductfeedback,deliveringclientservice,andsoon.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
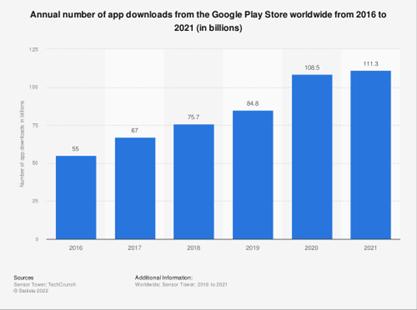
Fig1:EvolutionofappsontheGooglePlaystore[1,2]:(A)TotalappsontheGooglePlayStore,
(B) TotalappsdownloadedfromtheGooglePlayStore
Machine learning algorithms, as well as the random forest (RF), the gradient boosting classifier (GBM), the acute gradient boosting classifier (XGB), the AdaBoost classifier (AB), and also the additional tree classifier (ET) was applied to predict numericratings.
• The classifier accuracy was analyzed from the subsequent 2 perspectives: (a) exploitation of the matter options derived from the reviews alone, and (b) exploitation of each of the matter options and also the emoticons offered within the reviews.
• Forvalidation,notedappshappinesstoeveryclasswereaccustomedcomparethenumericratingsexpectedbyensemble learningwiththeuser'sactualratings.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
Fig2:Flowdiagramofappaccessibility
PandasandtheScikitLearnpackagewereusedtocleanthedata.
1. WeencounteredNullvaluesincolumnsthatwerelaterdiscarded.
2. VariableswithanincorrectdatatypeandInconsistentformattingwascorrected.
2.1 SizecolumnhassizesinKBaswellasMB.
2.2 Reviewisanumericfieldthatisloadedasastring
2.3 Installsfieldiscurrentlystoredasastringandhasvaluesof1,000,000+.
2.4 Pricefieldisastringandhasasymbol.
3. Rowswithincorrectvaluesareidentifiedanddiscarded.
4. Outliersexistincolumnssuchasinstalls,reviews,andpricing,whichareremovedusingIQR.
5. Droppedunnecessarycolumnslike“Appand”,“LastUpdated”,“CurrentVersion”,and“Android Version”.
App Ratings are expected to support the options provided for the app. Experiments were performed on the BlackBerry World and Samsung golem stores to gather the raw options provided for the apps, together with their value, the rank of downloads,ratings,andmatterdescriptions.Theoptionswere thenencodedintoanumericalvectortobeemployedincase based reasoningand to predictthe app rating.Indistinctionto the above cited studies,differentauthors.Review based pre dictionsystems permitthis unstructured infoto bemechanicallyremodeledintostructuredknowledgereflective belief.This structured knowledge is often used as a life of users' sentiments regarding specific applications, products, services, and brands.theywillthusgivevitalinfoforproduct servicevicesrefinement.thissortofsentimentanalysiswasconductedinthe followingstudies.
Various sentiment analysis ways are performed to summarizethe ensembles of comments and reviews. These ways use mathematical and applied math ways (especially involving mathematician distributions) to beat the issues encountered in sentimentanalysis.thoughtheseauthorsprojectedamodel,itwasnotenforced.Arecentstudyinvestigatedtheapplianceofa machine learningruletoadatasetcovering,forinstance,theappclass,thenumbersofreviewsanddownloads,thesize,type, Associate in Nursing golem version of an app, and therefore the content rating, to predict a Google app ranking. call trees, regression, supplying regression, support vector machine, NB classifiers, k means bunch, k nearest neighbors, and artificial neuralnetworkswerestudiedforthatpurpose.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
Approachesaresupervisedlearning,unsupervisedlearning,semi supervisedlearning,andreinforcementlearning. inkeeping with our study, we decide on the supervised machine learning approach because the approach is incredibly smart atthe subsequentclasses’binaryandmulti classclassification,regression,andaggregation.
Fig3:Existingfeaturesin apprating
This section describes the planned approach, its modules, andthereforethedatasetemployedintheexperiment.
The design of the planned approach for predicting numeric ratingsis printed in Figure three. It involves many subtasks, represented on an individual basis below, prompt adopting an applied mathematics analysis supported by a spin model, to extractthelinguisticsorientationsofwords.Mean fieldapproximationsweretheaccustomedreasonfortheapproximatechance withinthespinmodel.linguistics orientations area unitisthen evaluatedas fascinatingorundesirable.Asmaller rangeofseed words for the planned model turns out extremely correct linguistic orientations supported English lexicon. Google apps. First, text mining techniques are unit ineffective once applied to app reviews, because it has Unicode supported language with a restrictedrangeofwords.Second,thosestudiesareaunitbasedmostlyeitheronratingpredictionscreatedexploitationinherent app options or on external options (e.g., price, bug report, etc.). None of these studies investigated the potential discrepancies betweenusers'numericratingsandreviews.Toourinformation,thisstudyistheinitialresearchonsuchdiscrepancies.
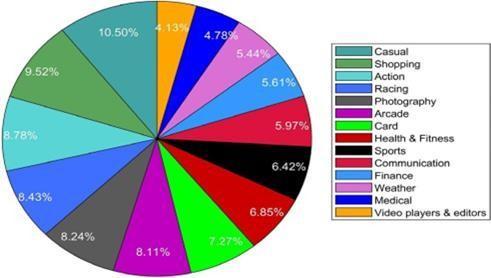
Fig3: Piechartofuserratings
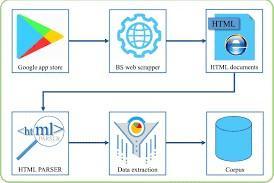
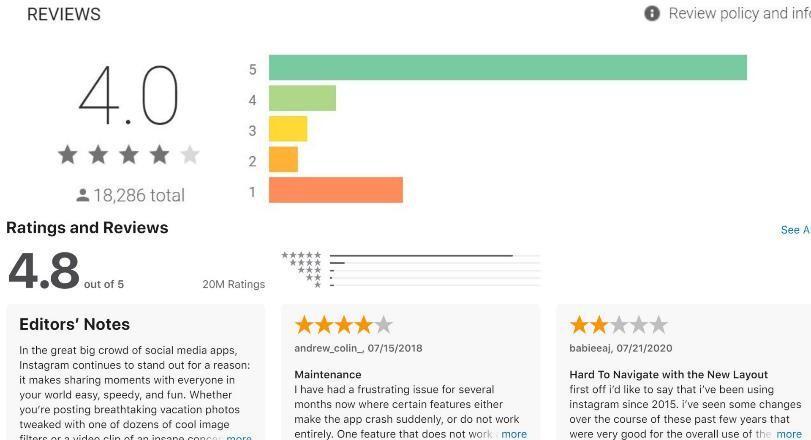
DATA SET: The Google apps dataset was scraped from the GooglePlaystore using the Beautiful Soup web scraper. Thedata were scraped for applications released no later than 2014 to ensure a minimum period of 5 years. The following criteria were applied:
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
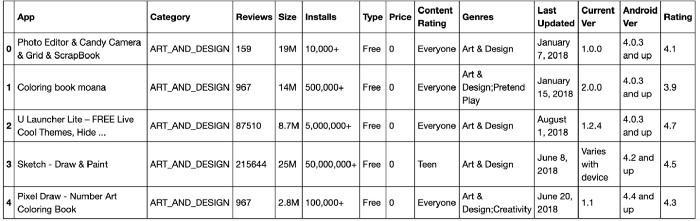
Fig4:DataSetofgoogleplaystore
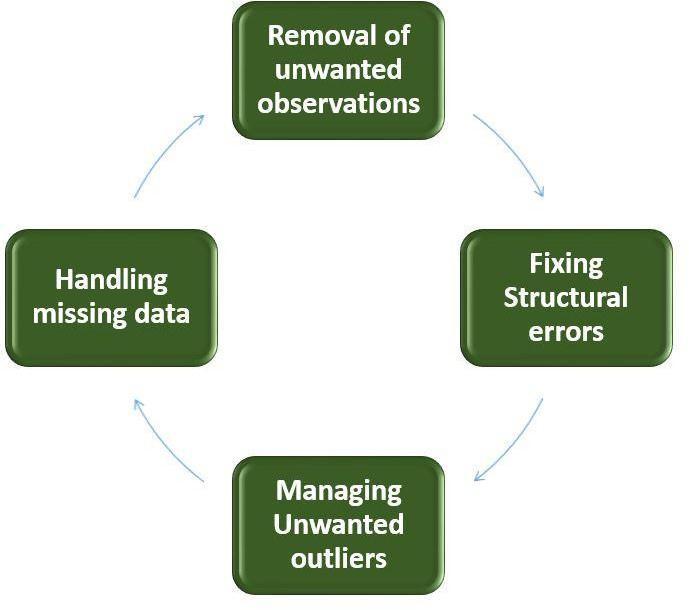
Preprocessing information is split into two elements, namely: cleanup information and information reduction. information cleanup is the method of cleanup incomplete information onthe attributes within the dataset to create the information additionalconsistent.Meanwhile,informationreductionisthemethodofremovinginformationonlessdominantattributesso informationisreducedbutstillmanufacturecorrectinformation.withintheinformationcleanupmethod,theauthorclassifies andassignstherankinginformationlabeltobehigh rated(>three.5)andlowrated(≤three.5),removethekandm symbols within the size column, removes the + image within the installs column and within the information reduction method the author deletes the information that's within theattributes current version, automaton version, genre, and last updated, understandtherecordformatandthenneededtocheck thetuplesandattributesandsameornottheyarebeingunderstood andneedtochangetonormalobjects.
DATACLEANING:Inthisset,ifanynoisesorinconsistenciesarethereitwillcheckandcleanthedatatoget clearandperfect datainaperfectstreamwithouthavinganymissingorduplicateddata.
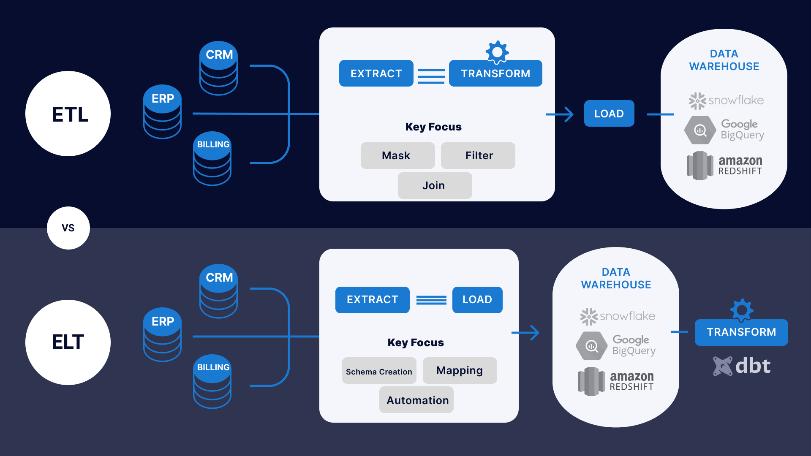
Data transformation is the method of adjusting the format, structure, or values of knowledge. For knowledge analytics comes, knowledge could also be reworked at 2 stages of the info pipeline. Organizations that use on premises knowledge warehouses usually use AN ETL most organizations use cloud based knowledge warehouses, which may scale cipher and storageresourceswithlatencymeasuredinsecondsorminutes.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
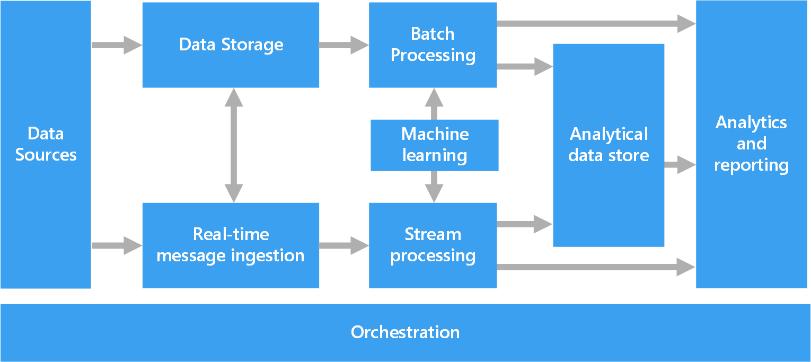
Thedatashouldsobenormalizedbeforebeginningthecoachingmethodexploitationoftheplannedapproach.Toperceive text preprocessing, take into account the instance of a review for the mobile app. A series of preprocessing steps and their output are shown in fig4. when the completion of preprocessing, the ensemble learning classifiers are often applied to the processeddataset. Fig5:Architectureoftheproposedapproach
2GB.
©
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
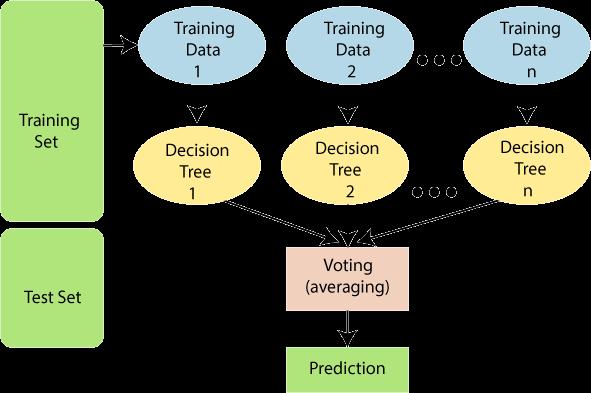
method of mixing multiple classifiers to unravel a fancy drawback and improve the performance of the model Dependent variable: the variable, that's to beunderstood or to be forecasted that variable is thought because of the variable. Since the randomforestcombinesmultipletreestopredicttheclassofthedataset,somedecisiontreesmaypredictthecorrectoutput, whileothersmaynot.Buttogether,allthetreespredictthe correctoutput.Therefore,belowaretwoassumptionsforabetter RandomForestclassifier:
Independent variable: this factor that influences the target variable or the dependent variable and provides the information that belonging therelationship withthedependentvariableorthetargetvariable.
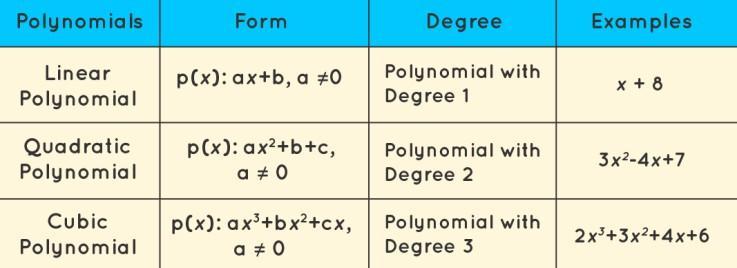
Inpolynomialregression,thelinkbetweentheexperimentalvariablexandthereforethevariablequantityyisdelineatedas associate ordinal degree polynomial in x. Polynomial regression, abbreviated E(y|x), describes the fitting of a nonlinear relationshipbetween the worth of x and therefore the conditional mean of y. it always corresponded to the least squares methodology.consistentwiththeGaussAndreMarkoffTheorem,thesmallestamountsq. approachminimizesthevarianceof thecoefficients.thisisoftenasortofregressiontowardthemeanduringwhichthedependent andfreelancevariableshavea curving relationship and therefore the polynomial equation is fitted to the data; we’ll check that in additional detail later withinthearticle.MachinelearningisadditionallycitedasasetofMultipleregressionstoward themean.asaresult,wehave converted the Multiple regressiontoward the mean equation into a Polynomial regression of y on x as well as a lot of polynomialregressions.
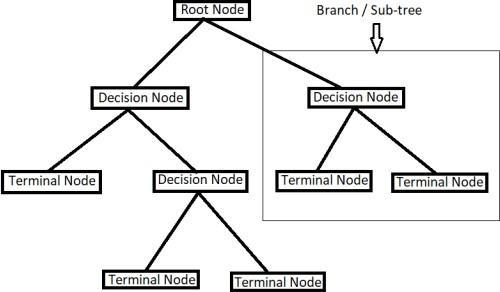
A decision tree may be a flowchart like structure within which every internal node represents a check on a feature (e.g., whether or not a coin flip comes up with heads or tails), every leaf node represents a category } label (decision taken when computingalloptions)andbranchesrepresentconjunctionsoffeaturesthatresultinthoseclasslabels.Themethodsfromthe foundationtotheleafrepresentclassificationrules.Thebelowdiagramillustratesthe fundamentalflawofthechoicetreefor highercognitiveprocesseswithlabels(Rain(Yes),NoRain(No)).
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page2194
International Research Journal
Engineering
Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
Feedingtheinfotothemodel,abigquantityofpre-processingis
needed.ThequantitativescoreofappswithintheGooglePlay Storemightalsobeskewandexaggeratedasaresultofhigher userratingsthatmightattractadditionalnewusers.However, becauseofinadequateormissingvotes,thisratingarea isa notaryandoftentimesbiased.Thisanalysisaimstousemachine learningtechniquestoforecasttheratingsofGooglePlayStoreapps.
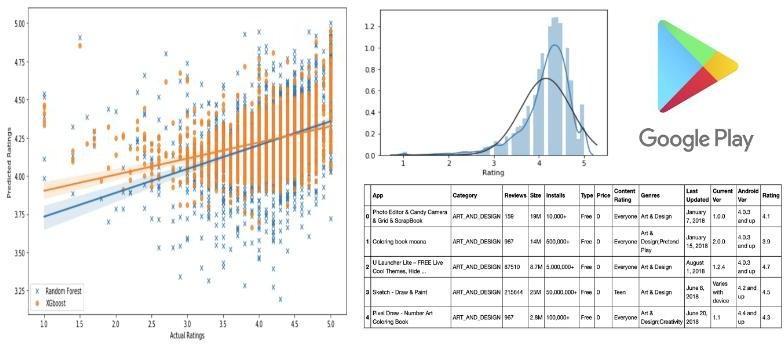
GooglePlaystoresappssupportedtheuserreviewsforthoseapps.manyensembleclassifierswereinvestigatedto judgetheir performance on the reviews scraped from the Google Appstore. TF/IDF options with unigrams, bigrams, and trigrams were utilized with the chosen classifiers. the bottom truth was calculated employing a technique supported by text Blob analysis, that identifies the reviews showing a discrepancy withthe user awarded rating. later, it had been accustomed to judging the performanceofthechosenclassifiers.TextBlobanalysisshowedthattwenty four.72%oftheuser definedappratingsquare measure biased. Results demonstrate that tree based textile ensemble classifiers perform far better than boosting based classifiersonaccountoftheirsupportfornonlinearity,collinearity,andtolerancetoinformationnoise.Theanalysisconjointly reveals thattheuserviews squaremeasureinconsistentwithusernumericratingswhichnumeric ratingsquaremeasureon thetopofuserreviews wouldpossiblyrecommend.Futureworkincludestheimplementationofthedeeplearningtechnique to predict numeric ratings. The authors declare no conflict of interest. The funders had no role within the style of the study; within the assortment, analyses, orinterpretation of data; within the writing of the manuscript; or in the call to publish the results. This model gives the result mostly depending on the world healthorganization basis of data.This model gives the highestaccuracyandsurelybeusedforcorrectivemeasures.
Experimentsdemonstratethatthepredictionaccuracyisoftenimproved.Forthispurpose,everyapplicationclasswastrained one by one exploitation RF before creating predictionsshowing the result obtained by coaching every class of Google apps exploitation RF. The exactitude, recall, and F score values were obtained by averaging the ratings from every category. Averages were calculated exploitation the Scikit learn analysis metrics library. The results demonstrate that coaching every classonebyonetoformapredictionyieldshigheraccuracythanonceexploitingallclassescombined.
TheaccuracyofRFandGBMreflectsthediscrepanciesbetweentheuser specifiednumericratingandreviews.Thenumeric ratingisapproximately20%higherthanthe outcomeofensembleclassifiers.
In this study, the improvement is to explore the exploitation of associate degree updated information for predictions. For futureworkandanyimprovementmaybedonebythispredictionmethodologytourgetheverybestcorrectresultsandmay be done on varied knowledge sets like IOS apps and additional economical google play stores within the immense data set assortmentgivenbygoogle.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
The following aspects area unit learned whereas collaboratingontheproject:
• Pandasareaunitessentialforknowledgevalidation,cleaning,selection
• Seaborn,Matplotlibisemployedforvisualimage.
• They recognized outliers and knowledge distribution in every various victimization numerous plots like box, bar, and accumulativedistributionplotsforeveryassortment ofattributes.
• Statistics area unit important in deciding the accuracy in knowledge, like mean, median, and variance, that aims to attenuateerrorrates.
• Victimization Inter Quartile Range and a log transformation to get rid of non linearity, outliers area unit treated, and lopsidednessisreduced.
• Different algorithms were wont to take a look at prediction models. Comparing the outcomes of varied R2 scores and errorratesaidsintheidentificationofasuperiormodel.
• I’mplottingtheresultsonthegraphvictimizationseaborn,visualizingtheoutputtoknowthebest fittinglinehigher.
• Massiveamountsofknowledgeareaunitneededtofeedtherulewanttoobserveandvisualizepatterns.
[1] Tressa, Eleonora MC, etal."Mobile Applications in Otolaryngology:A SystematicReviewoftheLiterature,Apple App StoreandtheGooglePlayStore."AnnalsofOtology, Rhinology&Laryngology130.1 (2021):78 91.
[2] Hassan, Safwat, et al. "Studying the dialogue betweenusers and developers of free apps in the google play store." EmpiricalSoftwareEngineering23.3(2018):1275 1312.
[3] Venkatakrishnan, Swathi, Abhishek Kaushik, and Jitendra Kumar Verma. "Sentiment analysis on google play store datausingdeeplearning."ApplicationsofMachine Learning. Springer, 2020. 15 30.
[4] Karim,Abdul,etal."ClassificationofGooglePlayStoreApplicationReviewsUsingMachineLearning." (2020).
[5] Reddy, Palagati Bhanu Prakash, and Ramesh Nallabolu. "Machine learning based descriptive statistical analysis on Google play store mobile applications." 2020 Second International Conference on Inventive Research in Computing Applications (CIRCA). IEEE, 2020.
[6] Karim, Abdul, et al. "Methodology for Analyzing the Traditional Algorithms Performance of User Reviews Using MachineLearning Techniques." Algorithms13.8(2020): 202.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 05 | May 2022 www.irjet.net p-ISSN: 2395-0072
[7] Islam, Mir Riyanul. "Numeric rating of Apps on Google Play Store by sentiment analysis on user reviews." 2014 InternationalConference on Electrical Engineering and Information & Communication Technology. IEEE,2014.
[8] Ali, Mohamed, Mona Erfani Joorabchi, and Ali Mesbah. "Same app, different app stores: A comparative study." 2017 IEEE/ACM4thInternational Conference on MobileSoftwareEngineeringandSystems(MOBILESoft).IEEE,2017.
[9] Sadiq,Saima,etal."DiscrepancydetectionbetweenactualuserreviewsandnumericratingsofGoogleAppstoreusing deeplearning."ExpertSystems with Applications 181 (2021): 115111.
[10] Mahmood, Ahsan. "Identifying the influence of various factors of apps on google play apps ratings." Journal of Data, InformationandManagement2.1(2020):15 23.[11]Umer,Muhammad,etal."PredictingnumericratingsforGoogleapps usingtextfeaturesandensemblelearning."ETRIJournal43.1(2021):95 108.