International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
1PG Scholar, Department of Computer Applications and Research Centre, Sarah Tucker College (Autonomous), Tirunelveli, Tamil Nadu, India
2Associate Professor, Department of Computer Applications and Research Centre, Sarah Tucker College (Autonomous), Tirunelveli, Tamil Nadu, India ***
Abstract - The rapid and wide ranging dissemination of data and information through the internet has resulted in a large dispersion of normal language textual holdings. In the currentenvironmentforselecting, distributing,andretrieving avastsupplyofinformation,excessiveattentionhasemerged. Processing large amounts of data in a reasonable amount of timeisasignificantdifficulty andacriticalneedinavarietyof commercial and exploratory industries. In recent years, computerclusters,distributedsystems,andparallelcomputing paradigms have been more popular, resulting in significant advances in computing presentation in data intensive applications like as Big Data mining and analysis. NLP is one of the key aspects that may be used for text explanation and initial feature extraction from request areas with high computing resources;as a result, these duties can outperform comparable designs. This research presents a distinct architecture for parallelizing NLP operations and crawling online content. The mechanism was discovered using the Apache Hadoop environment and the MapReduce programming paradigm. In a multi node Hadoop cluster, authenticationisdoneutilizingtheexplanationforextracting keywords and crucial phrases from online articles. The proposed work's findings indicate greater storage capacity, faster data processing, shorter user searching times, and correct information from a huge dataset stored in HBase.
Key Words: Natural Language Processing, Hadoop, Text Parsing,WebCrawling,BigDataMining,HBase.
BigDataisdescribedasacollectionofdatasetswithascale thatmakesitdifficulttogovernanddistributeinformation using standard technologies (i.e., management of N dimensional data circles by necessary text files and SQL files). These challenges create Big Data monoliths [1] as plentifulassecondaryinformationsystems(Pollock,2013a), resulting in primary failure for the largest isolated and publicdataprovidersinwhichasmallervolumeofdatadoes not imply easier administration (Akers, 2013) [2]. Informationmaybeextractedusingavarietyofapproaches utilizingNLP.Textmining(Pandeetal.,2016)[3]isoneof themosteffectivewaysforextractinginformationfromtext data.Theaccuracy,sloterrorrate,F measure,andrecallof information extraction are all elements to consider. The
technology of Information Retrieval (IR) and Information Management (IM) arose from the emergence of efficient information. [4] Extraction (IE) 2018 (Sonit Singh). In IE systems,naturallanguageisusedasaninput,anditprovides structured information according on certain criteria that may be used to a specific application. Data mining techniques handle large datasets to extract key patterns fromdata;socialnetworkingsitesprovidealargenumberof datasetsforitspractice,makingthemideal candidatesfor miningdata usingdata miningtools(CharuVirmanietal., 2017)[5].Asaresult,webminingordataminingprovides critical insight to a social network in order to correctly develop and interact in a user friendly manner. Web data mining based on Natural Language Processing (Yue Chen, 2010) [6] involves knowledge representation. The corpus testismadeupof400wordsretrievedfromtheWebnew corpus,andthissortofinformationincludesdescriptionsof events,relationships,andobjectproperties.Atthesemantic level, this model exemplifies the web page, and its knowledgestructureisscalable.
NLPisatheoreticallygroundedsetofcomputerapproaches foranalysinganddemonstratinghumanlanguage.Itallows computerstodoawiderangeofcommonlanguage related activities at all levels, ranging from analysing and part of speech (POS) categorization to machine conversion and conversationschemes.Inadditiontomethods,deeplearning designs comprise previously accomplished imposing indicators of success in realms like processor vision and design thankfulness. Following this trend, contemporary NLP research is increasingly focusing on the use of novel deeplearningalgorithms(Mikolovetal.,2010;Mikolovetal., 2013)[7,8]anddeeplearningmethodologies(Socheretal., 2013) [9]. Multilevel programmed feature representation learningispossiblewithdeeplearning.Traditionalmachine learning basedNLPsystems,ontheotherhand,relyheavily on human crafted structures. Handcrafted arrangements taketimetocreateandareusuallyflawed.
Barbosa et al., (2015) discussed several strategies for information extraction [10]. And he went on to discuss knowledgeinferencing,whichentailsusingavarietyofdata sources and extraction techniques to check existing and
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal

International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
current knowledge. Deep natural language processing utilizing machine learning approaches, large scale probabilistic reasoning, data cleansing using integrity techniques, and using human experience for domain knowledge extraction are the four inferencing methodologies.
Asaresult,suchalgorithmsmaybeemployedinavarietyof systems to extract information from online phrases. Chandurkaretal.,(2017)presentedaQuestionAnswering (QA) system that integrates the domains of information retrieval(IR)andnaturallanguageprocessing(NLP)[11]. The QA system was based on the UI's intended topic and inquiry(UserInterface).ToencodetheXMLdocument,the TREC 2004 dataset is used. By adding a text box to the system,theusermayaskhisorherowninquiry.Theexact DBpediapageisbasedonthetargetsubject,aswellasthe StanfordDependencyParser,whichincorporatestheother process for extracting the target or focused topic in the inquiry. However, it is entirely dependent on the factoid questionclassifierinPython.
Florenceetal.,(2015)introducedthesummarizersystem, whichisbasedononlinedocumentsemanticanalysis[12]. ThesystemconstructsthesummaryusingClustervaluesin ResourceDescriptionFramework(RDF)space.Basedonthe originallengthofthepapers,thissystemmaygenerateshort and lengthy summaries. Finally, the clustering method extractsthesubject,object,andverb(SOV),whichmaythen be grouped together using the RDF triples produced. The chosen important phrases are then extracted using the SentenceSelection(SS)algorithmforthefinalsummary.In several NLP tasks such as Semantic Role Labeling (SRL), Named EntityRecognition(NER),andPOStagging,Collobert et al. (2011) discovered that a simple in depth learning approachoutperformsmostcomplextechniques.Meanwhile, several difficult deep learning based processes to address tight NLP obligations have been proposed [13]. Goldberg (2016) easily exposed the key ideology centered on smearingneuralnetworkstoNLPinapedagogicalwayinhis research. The researchers hoped that their effort will provide readers a more comprehensive picture of current research in this field [14]. NLP techniques, according to Azcarraga et al., (2012), are the foundation of language based solutions that often deliver more precise outcomes using statistical approaches; nevertheless, they are computationallyextremelyexclusive[15].
Pavithra et al., (2013) investigated the wrapper induction techniquefordataextraction.Thesystemisadvancedbythe usageofacombinationofXSLTandDOMthroughXML.For web based applications, XML methods are quite useful. According to the content, this approach provided efficient informationextractionandchainedwrappermodification.It enhancedusabilityandflexibility[16].Sridevietal.,(2016) proposed a Viterbi technique for constructing medical corpus data, which included information extraction from clinical language based on context, allowing clinicians to makequickerandimproved conclusions.Italsoimproved
value:
thetreatment'squality[17].WuWeietal.(2013)developed anewextractionrulelanguagethatdescribedtheintegrated logicfordataintegration,informationextractiondirection finding, and web page extraction. A source data object is usedtorepresentandencapsulateawebdataarea,including informationrecordsandobjects.Thesystemenablesusers to construct sophisticated target data entities using XML, explains the structure of the target data entity, and previously approved integration scripts to transform and map information taken from source to target data objects [18]. Jindal et al. (2013) developed a similar NLP system basedontheLearningBasedJava(LBJ)methodology[19].In additiontousingCharm++,RizzoloandRoth(2010)useda similar software design approach [20]. Exner and Nugues (2014)describedtheKoshikmulti languageNLPplatform, whichwasdesignedforlarge scaleprocessing,suchasthe analysisofunstructurednaturallinguisticmaterialsspread throughout a Hadoop cluster [21]. Text tokenization, dependencyparsers,andco referencesolversareamongthe algorithmsitoffers.UsingaHadoopdistributedarchitecture and its Map Reduce program design methodology to professionally and easily grow by adding low cost commodity hardware to the cluster is a competency advantage. Barrio and Gravano (2017) explained how to extract information schemes in natural language script to identify classified information. When opposed to a likely finished native linguistic document, knowing controlled techniqueallowsformuchmoreaffluentenquiringanddata mining.However,outsideilluminatingacompetencyofan extraction technique with text groups of fragile attention, extractingasubstanceisacomputationallypriceymission.
Thestudyfocusesonawell knownfamilyoftextgroups,the so called deep web text groups, whose insides aren't crawlableandcanonlybeaccessedbyquerying.Forefficient content extraction from deep web text groups, there is a crucial step [22]. Wang and Stewart (2015) investigated geographic information science by modeling spatial dynamics discovered in spatiotemporal content collected from the Internet, especially unconstructed facts such as onlinenewsheadlines.Takingintoaccountbothspatialand temporaldatafromacollectionofWebformsenablesusto create a rich exemplification of geographic elements identified in the text, such as where, when, and what occurred.Thisstudylooksathowpartontologiesoperateas a key component in a semantic material abstraction approach.Theydemonstratedhowontologiesmightbeused in teaching grammatical process material around hazard spatially and proceedings complement abstraction with semantics by combining them with traditional linguistic gazetteers[23].
MatchandAvdan(2018)presentedamethodforremoving obstacles(suchastypographicalerrors,spellingmistakes, andinappropriatearrangements)thatimpedetheaccuracy ofageocodingapproach.Thedataofanaddressisexamined using NLP methods in the present methodology. Both the MatchRatingComputeMethodandtheLevenshteinDistance
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Procedureareunaffectedbymisspellings,abbreviations,or omissions.Asaresult,theaddressesarerearrangedintoa preciseorder.Calculatethetechnique'spropertiesbasedon the results of the geocoding operation. A test dataset comprising Eskishehir elementary school addresses is created. Both beforeandafter the calibration method, the geocodingtechniqueisvalidatedusingacurrentsampleof addresses [24]. Glauber and Claro (2018) described strategiestoguaranteethatallrelevantprimaryresearchis included.Evenifwestrewourinquirythreadsoverfivefiles, anEMNLPconversationdistilsthemostimportantprinciple.
• DatasetCollection
• MapReducer
• Mappertasks
• Reducertasks
• HadoopStorage
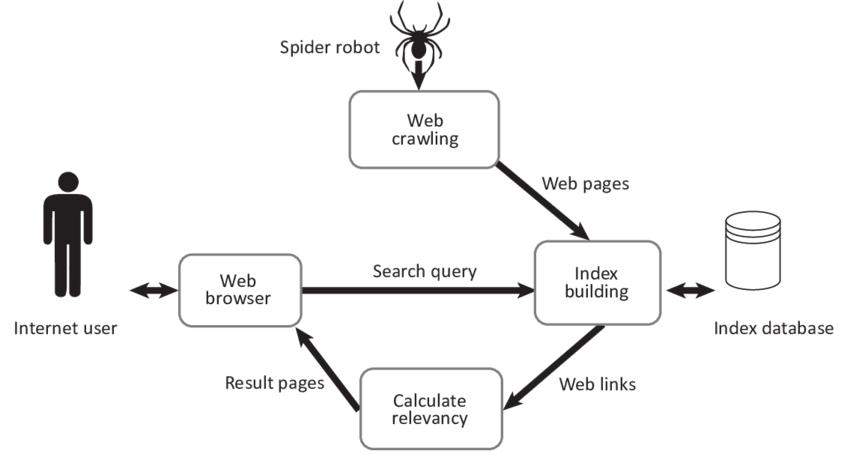
TheInputnameissuppliedasaURLinthisModule,and thenvariouscontentsaretakenfromwebsitesandshownin thetextbox.WebHarvesting(WH)andWebScrawlingare tworelatedmethodsusedbywebsitestodirectuserqueries to their site. The URL is used to collect the processed and extracteddataset(uniformresourceallocation).
Fig -1:Architecturediagram
Usersmayseekfortrendsininteractivedataminingfroma varietyofperspectives.Becauseitisdifficulttoknowwhat mightbedisclosedinsideadatabase,storinglargeamounts of data, and processing data quickly, the data mining approach must be interactive. Different types of data are storedindatabasesanddatawarehouses.Itisunthinkable thatonesystemcouldharvestallofthesedifferentformsof data.Asaresult,thedifferentdataminingsystemsmustbe interpretedforvarieddatatypes.
The framework accepts the input name as a URL and extractsallformsofmaterialfromwebsites,whichisthen showninthetextbox.Thephrasesfromnounorverbclauses areextractedusingParts of Speech(POS).Itassignsdatato eachtokenthathasbeenidentified.MapandReducearetwo critical jobs in the Map Reduce system. The individual componentsaresmashedintoatupleinthiscase.Inthiscase, the map translates a particular collection of data into a variableset.
The activity of the guide or mapper is to put the knowledge into practice. The information is stored as a document or registry in the Hadoop record framework (HDFS)forthemostpart.TheReducer'sjobistoprocessthe data that comes in from the Mapper. Following the preparation,itgivesanotheryieldtechnique,whichwillbe usedintheHDFS.
Tokenization is the process of breaking down lengthy strings of material into smaller tokens. Larger chunks of materialmaybetokenizedintosentences,whichcanthenbe tokenized into words, and so on. Additionally, much preppingisdoneafterapieceofwritinghasbeenproperly tokenized.
Tokenizationisreferredtoasalexicalstudyoracontent division. Tokenization refers to the breakdown of a large chunkoftextintosmallerbits(e.g.,passagesorsentences), whiledivisionreferstothebreakdowntechniquethatjust produceswords.
Awebharvestingsoftwarefindswebsiteswithspecific materialtargetedatacertainwebharvestrequest.Theweb data iscollectedby the web harvestingapplication,which also includes a link that takes the user to the company's website. This information is then indexed by well known search engines like Yahoo and Google, making it easier to find it in future searches. Increasing visibility via web harvestingiscriticalforacompany'sonlineexpansionand growth. The use of web harvesting is a major aspect in generatingonlinecompanyincome.Asaresult,therewillbe ahigherchancethataprospectiveconsumerwillfindyour websiteviaaninternetsearch.
Asaresult,obtainingoutsidesupportintheirattemptsto expand their online presence has become critical for corporatesuccess.Finally,organizationsshouldlookforthe most cost effective and user friendly web harvesting softwareavailabletoguaranteethattheireffortsarealways rewardedwithfavourableresults.Theterms"webscraping" and "web harvesting" are interchangeable, while "web harvesting"referstocrawlingseveralsitesandextractinga
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
specificcollectionofdata.It'salsoknownastargetedweb crawling.
FMinerisanimportanttoolforwebharvesting.Multiple siteURLsmaybeusedasthebeginningURLinanextraction project file, and the extracted results can be stored to the same database. The application may then collect page contentsfromnumeroussitesconstantlyandgraduallyusing the"schedule"and"incremental"capabilities.
Naturallanguageprocessingforbigdatamaybeusedto automatically locate important information and/or summarize the content of documents in vast quantities of data for collective understanding. Natural Language Processing (NLP) is a technique for analysing understandabletextproducedbyhumansforthepurposes oflanguageprocessing,artificialintelligence,andtranslation.
ThereareseveralNLPapproachesfordealingwithissues such as text corpus collection and storage, as well as text analysis, in order to effectively and precisely analyse the text. NLP techniques benefit and acquire experience from linguistics and artificial intelligence research. Intelligence, machinelearning,computationalstaticsandothersciences.
However, at recent times, because of the explosion of information, the utilization of traditional NLP faces many challenges such as the volume of unstructured and structured data, accuracy of the results and velocity of processingdata.Inaddition,therearesomanyslangsand indefinite expressions used on social media networking sites, which give NLP pressure to examine the meanings, whichmayalsobedifficultforsomepeople.
Furthermore, nowadays, people heavily depend on searchenginessuchasGoogleandBing(whichuseNLPas their core technique) in their daily study, work, and entertainment.Alloftheabove mentionedfactorsencourage computer scientists and researchers to find more robust, efficientandstandardizedsolutionsforNLP.
Tokenizationmaybedescribedastheprocessofsplitting the text into smaller parts called tokens, and this is deliberatedasacrucialstepinNLP. Theprocessofslicing the given sentence into smaller parts (tokens) is called as tokenization. In general, the given raw text is tokenized basedonagroupofdelimiters.Tokenizationisusedintasks suchasprocessingsearches,spell checking,identifyingparts ofspeech,documentclassificationofdocuments,sentence detectionetc.
• Simple Tokenizer − Tokenizes the available raw textusingcharacterclasses.
• Whitespace Tokenizer − Uses whitespaces in ordertotokenizethegiventext.
• Tokenizer ME − Converts raw text into separate tokens. ItusesMaximumEntropy to makeits decisions.
• Tokenizethesentences
• Printthetokens
• Instantiatingtherespectiveclass.
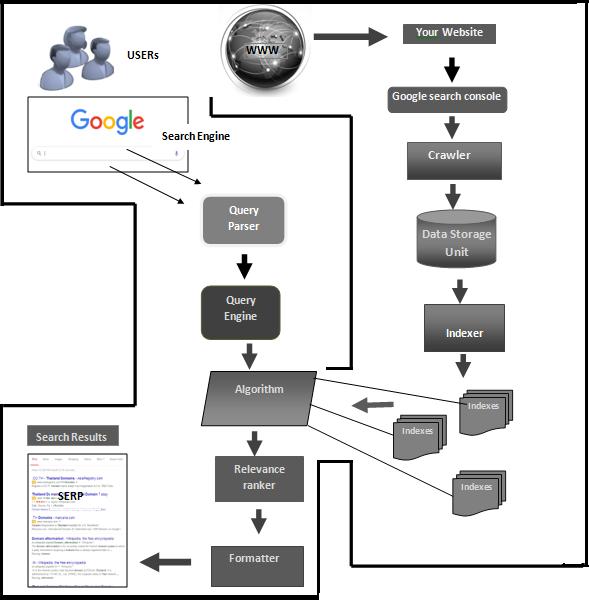
Fig -2:Dataflowdiagram
ThePartsofSpeechofagivensentencecanbedetected usingOpenNLPandthencanbeprinted.Insteadoffullname of the parts of speech, OpenNLP uses short forms of each partofspeech.Then,amapinadditiontoreducephasesrun inslotsimpliesthateachnodecouldrunbeyondoneMapor elseReducetaskinmatching;generally,theslotsquantityis correlatedthroughcoresquantitypresentinaspecificnode.
ReducerisaphaseinHadoopwhichcomesafterMapper stage. The yield of the mapper is provided as the contribution for Reducer which proceeds and creates anotherarrangementofcreation,whichwillbeputawayin theHDFS.Reducerfirsthandlesthein betweenvaluesfor individualkeyproducedasaresultofthemapfunctionin addition to further providing an output. Where output informationofamapphase, numberofmaptasks, single reducetask.
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
Theexpectedsystemscalabilityperformanceisprovidedina mannersimilarto the earlierauthentication.Ontheother hand,thestudyexpandedthedatasetfrom10,000to20,000 web pages and documents and evaluated the time of dispensation for Keyword Extractor Module (KEM) implementation on the text content of a previously investigateddatasetusingaNutch basedcrawler.TheWeb Extraction technique is shown in Figure 2. As a result, no additional external network access will be required for keyword extraction or keyword extraction. This strategy eliminates bottlenecks while also removing the need for processparallelization.Figure3.
process and organize the data collected. The document's keywords are extracted. The keyword and the keyword exchange information. The document's words are recognized. The report is determined using the neural networkbetweenthekeywordandthewordsinside.Onlyif themodelisdetectedisthetextchosen.Figure4depictsthe ContentExtractionTesting.
Methodofprocessingwithrespecttotheversionanticipated in Nesi et al., (2015), several advances have defined the possiblesolutionsfortheseoverallchangestoacodeaswell asatestformation,bothintermsoftimepresentationsand scalability. The Hadoop cluster design used in the testing wasassessedinavarietyofconfigurations,rangingfromtwo tofivenodes.ByutilizingHadoopHDFS,eachnodeisaLinux 8 coreworkstation.Hadoopallowscompletingarebalancing ofdepositedblocksacrosstheclusteractivenodestoavoid data integrity problems and disappointments due to decommissioning and recommissioning of cluster nodes [26].
TheMapReduceconceptallowsforspeculativejobexecution andisdesignedtoprovideredundancyforfaulttolerance.As aresult,theJobTrackermayberequiredtopostponefizzled orotherwiseterminatedtasks,whichmayaffectthetimeit takestocompletetheentireoperation.Asaresult,theideal prepared conditions have been picked for execution correlationamongafewtestoccasionsthathavebeenlead foreachhubconfiguration.Theamountofworkrequiredto retry failed or eliminated jobs must be lowered using the existingsystem.Approximately3.5milliondocumentswere retrievedfromtheentireexaminationdataset.
AfterprovidingaURL,allcontentcategoriesareextracted fromwebsitesandshowninatextbox.NLPisusedtopre
Asanexaminationterm,runningtheonasinglenon Hadoop workstation, the same CiteSeerExtractor, a RESTful API application on a comparable corpus dataset took roughly 115hours.TheMap ReducertechniqueisdepictedinFigure 5.ThefactthatthestandaloneCiteSeerExtractor,aRESTful APIapplication,isnotoptimizedformulti threadingmaybe a possible explanation for this important presentation opening. Despite the way that Hadoop's Map Reduce adaptation may take benefit of MapReduce configuration choices that describe the largest number of guides and
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
reduce errand spaces, all of this can be accomplished by usingmulti centerinnovationevenonasinglehubcluster. TheHadoopStoragedatasetisshowninFigure6.
TheMapReducecontainstwoessential tasks,namelyMap andReduce.Themapconsistsofagroupofdataandchanges itintoanalternativegroupofdata,whereseparateessentials arefragmenteddownintothetuple.Themapormapper's workistodeveloptheinputdata.Generally,thecontribution data is present in the procedure of directory or file and stored in the Hadoop file system (HDFS). Hadoop assigns MapandReduce taskstotheappropriatemachines in the cluster.Thediagramaccomplishesalldata passingdetails, such as assigning duties, checking job completion, and moving data fromthe group tothe nodes.Themajority of computationoccursonnodesonoriginalrecordings,which reducesnetworkcirculation.Aftercompletingtheassigned tasks,theteamgathersandreducesthedata toproduce a sufficientresultbeforereturningittotheHadoopserver.
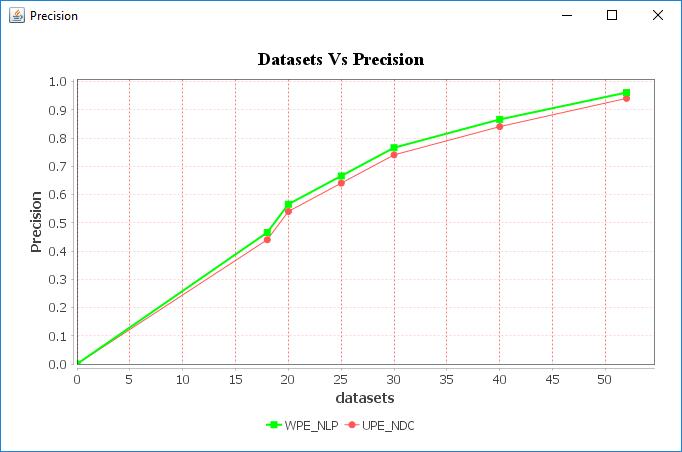
Our proposed WPE_NLP methods have the highest precisioncomparethanExistingUPE_DCmethod.
OurproposedWPE_NLPmethodshavethehighestRecall comparethanExistingUPE_DCmethod
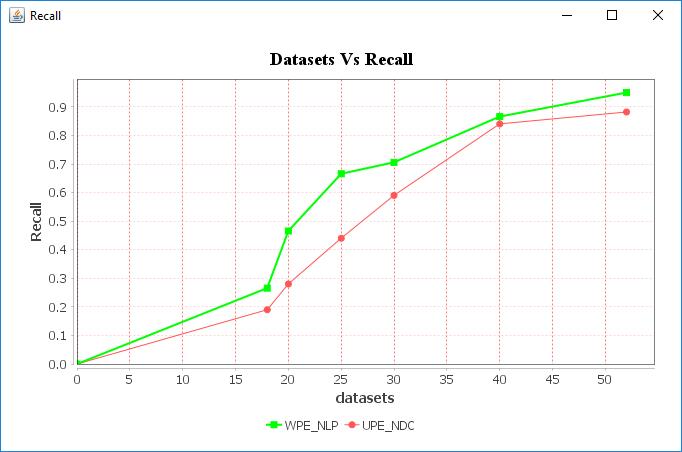
Fig -9:Datasetscomparewithrecall
Our proposed WPE_NLP methods have the highest F MeasurecomparethanExistingUPE_DCmethod
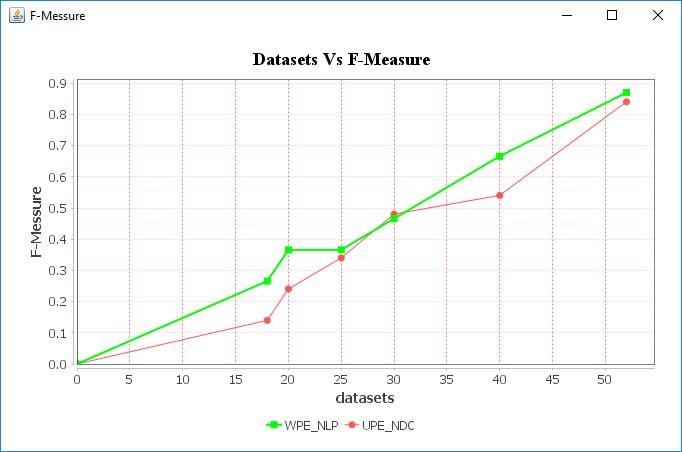
Fig 10:DatasetscomparewithF Measure
The findings of this investigation point to web based datasetsandthebenefitsofBigData.Itiscriticaltodevelop amethodthatensurestheuse,administration,andre useof information sources, including online URL information, as wellasthecollectionofusefulURLandservicesacrossthe country. It's critical to decide the strategy to use for Information Extraction using Neural Natural Language Processing(IE NLP).HadoopwithMapReducemaybeused to improve analytic processing. The basics of MapReduce software are developed by the open source Hadoop backdrop,accordingtothepresentstudy.Hadoop'sexcellent contextraisesthemanagementoflargeamountsofdataover the distribution process and reacts quickly. Big data processinginthefuturewillincludemultipletypesofdata, suchasunstructured,semi structured,andstructureddata.
Fig 8:Datasetscomparewithprecision
International Research Journal of Engineering and Technology (IRJET) e ISSN: 2395 0056
Volume: 09 Issue: 05 | May 2022 www.irjet.net p ISSN: 2395 0072
[1] Pollock, R., 2013a. Forget Big Data; Small Data is the Real Revolution d Open Knowledge Foundation Blog. http://blog.okfn.org/2013/04/22/forget bigdatasmall data is the real revolution.
[2] Akers, K.G., Feb. 2013. Looking out for the little guy: smalldatacuration.Bull.Am.Soc.Inf.Sci.Technol.39 (3),58 59.
[3] Pande, V., & Khandelwal. Information Extraction Technique: A Review. IOSR Journal of Computer Engineering(2016)16 20.
[4] Sonit Singh, Natural Language Processing for InformationExtraction,IEEEpublications(2018)1 24.
[5] Virmani,C.,Pillai,A.,&Juneja,D.ExtractingInformation fromSocialNetworkusingNLP.InternationalJournalof Computational Intelligence Research (13) (4) (2017) 621 630.
[6] Chen, Y. Natural Language Processing in Web data mining. IEEE 2nd Symposium on Web Society, 2010, 388 391.
[7] Mikolov, T., I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, "Distributed representations of words and phrases and their compositionality," in Advances in neuralinformationprocessingsystems,2013,pp.3111 3119.
[8] 8. Mikolov,T.,M.Karafiat,L.Burget,J.Cernock´y,and S. Khudanpur, "Recurrent neural network based languagemodel."inInterspeech,vol.2,2010,p.3.
[9] Socher,R.,A.Perelygin,J.Y.Wu,J.Chuang,C.D.Manning, A. Y. Ng, C. Potts et al., "Recursive deep models for semanticcompositionalityoverasentimenttreebank," inProceedingsoftheconferenceonempiricalmethods in natural language processing (EMNLP), vol. 1631, 2013,p.1642.
[10] Barbosa, D., Wang, H., & Yu, C. (2015). Inferencing in information extraction: Techniques and applications. 2015 IEEE 31st International Conference on Data Engineering,1534 1537.
[11] Chandurkar, A., & Bansal, A. (2017). Information RetrievalfromaStructuredKnowledgebase.2017IEEE 11thInternationalConferenceonSemanticComputing (ICSC),407 412.
[12] Florence, A., & Padmadas, V. (2015). A summarizer systembasedonasemanticanalysisofwebdocuments. 2015 International Conference on Technologies for SustainableDevelopment(ICTSD),1 6.
[13] Collobert, R., J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa, "Natural language processing(almost)fromscratch,"JournalofMachine Learning Research, vol. 12, no. Aug, pp. 2493 2537, 2011.
[14] Goldberg, Y. "A primer on neural network models for natural language processing," Journal of Artificial IntelligenceResearch,vol.57,pp.345 420,2016.
[15] Azcarraga, A., M. David Liu, and R. Setiono, "Keyword ExtractionUsingBackpropagationNeuralNetworksand Rule Extraction," in Proc. of IEEE World Congress on ComputationalIntelligence(WCCI),Brisbane,Australia, June2012.
[16] Pavithra, Monisa, & Ramya. (2013). A Design of InformationExtractionSystem.InternationalJournalof AdvancedResearchinComputerScience,4(8),109 111.
[17] Sridevi,&Arunkumar.(2016).InformationExtraction from Clinical Text using NLP and Machine Learning: Issues and Opportunities. International Journal of ComputerApplications,11 16.
[18] Wei,W.,Shi,S.,Liu,Y.,Wang,H.,Yuan,C.,&Huang,Y. Extraction Rule Language for Web Information ExtractionandIntegration.201310thWebInformation System and Application Conference (2013), 65 70. doi:10.1109/wisa.2013.21
[19] Jindal,P.,D.Roth,andL.VKale,"EfficientDevelopment of Parallel NLP Applications," Tech. Report of IDEALS (IllinoisDigitalEnvironmentforAccesstoLearningand Scholarship),2013.
[20] Rizzolo,N.,andD.Roth,"Learning BasedJavaforRapid Development of NLP Systems." In Proc. of the International Conference on Language Resources and Evaluation(LREC),2010.
[21] Exner, P. and Nugues, P., "KOSHIK A Large scale DistributedComputingFrameworkforNLP,"inProc.of the International Conference on Pattern Recognition ApplicationsandMethods(ICPRAM2014),pp.463 470, 2014.
[22] PabloBarrioandLuisGravano.Samplingstrategiesfor informationextractionoverthedeepweb.Information ProcessingandManagement53(2017)309 331.
[23] Wei Wang and Kathleen Stewart. Spatiotemporal and semanticinformationextractionfromWebnewsreports about natural hazards. Computers, Environment and UrbanSystems50(2015)30 40
[24] Dilek Küçük Match and Uğur Avdan. Address standardizationusingthenaturallanguageprocessfor improvinggeocodingresults.Computers,Environment andUrbanSystems,2018.
[25] Rafael Glauber, Daniela Barreiro Claro, A Systematic MappingStudyonOpenInformationExtraction,Expert Systems with Applications (2018), doi: 10.1016/j.eswa.2018.06.046
[26] Nesi, P., G. Pantaleo, and G. Sanesi, "A Distributed Framework for NLP Based Keyword and Keyphrase ExtractionfromWebPagesandDocuments,"inProc.of 21stInt.Conf.onDistributedMultimediaSystems
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal