International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056

Volume:09Issue:05|May2022 www.irjet.net p ISSN:2395 0072

International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume:09Issue:05|May2022 www.irjet.net p ISSN:2395 0072
Rohan Shiveshwarkar1 , Om Shende2 , Soudagar Londhe3, Siddhesh Ramane4 , Prof. Prajakta A Khadkikar5
1,2,3,4 Student of Pune Institute of Computer Technology, Pune 5 Assistant Professor at Pune Institute of Computer Technology, Pune ***
Abstract - Feedbacks and Reviews carry a lot of weightage when it comes to E commerce websites/stores. Reviews have time and again proven to be a key to the decision making process. They are utterly helpful in improving their product and services. These reviews come from the end users and the greater the product or system, more the volumeofthereviews. Practically it is not possible, or rather time and resource consuming to read each and every review and perform an analysis. For this purpose, it is very helpful to introduce NLP and Machine Learning algorithms to easily analyze the negative reviews from customers and display graphical representations for the users to derive actionable business critical insights.
Key Words: Sentiment Analysis, Tokenization, Stemming, Feedback, Reviews, Natural Language Processing, Lemmatization, Machine Learning, Bernoulli’s Naive Bayes, Logistic Regression.
Sentimentsarenothingbutthoughtsorjudgmentsprompted by feelings. Sentiment analysis is recognizing these judgmentsandemotionspresentinthetextandconveying them to the end user Sentiment Analysis is used to determine whether the text in focus (here feedbacks/customerreviews)ispositiveornegative.Wecan perform such analysis using Natural Language Processing andMachineLearning.Inshort,SentimentAnalysisconsists of characterizing the reviews received. Tweets are frequently valuable in producing an immense measure of opinioninformationfordeterminingthecoreissuesfacedby the end users/customers of a product of an e commerce store. Reviews are generally made of noisy, incomplete, grammatically incorrect, not well shaped words and/or irregular expressions. Due to this, we have to perform severaltasksonthetextinordertoextractthefeaturesand distinguish them based on labels. On the text, we have to perform a series of pre processing tasks which include removing/replacing unnecessary words which helps in reducingthenoiseandunwanteddata.Oncethedataispre processedandcleaned,vectorizingofdataneedstobedone. Vectorizationtransformsdataintoanumericalformwhich lateronservesasaninputtoourMLClassificationmodel. The ML model then categorizes the data and provides the output. Thisoutputis then usedforanalysisand business insights.Theseinsightsarehelpfulforrecognizingthekey
problemsinfeaturesofthebusiness’product/servicesand improvetheirsaidproduct/servicesaspertheirneeds.This techniquehasproventosustainsuche commercestoresand businessesandcustomizetheservicesasperthecustomers’ needsandsuggestions.Businessescancollectsuchfeedback andsuggestionsfromtheirownwebsite,forums,blogs,and social media platforms and watch out for their brand reputation.Furthermore,theycanrolloutpollsandsurvey formstoreceiveresponsesregardingtheirbrand.
ThebenefitsofSentimentAnalysistobenefitthecompany anditsproductsandservicesare:
Trackclientsentimentsabouttheirproducts.
Analyse the positive/negative impact of products andservicesonthecustomers
Find out about the issues faced by the customers whichwerenotconsideredbefore
Improve the products by working on the suggestionsreceived.
Track the response from the customers when an upgradeisrolledoutintheproduct
Find out your target audience and consider all aspectstocomforteachtypeofaudience
OneofthemajorsourcesforacquiringsuchdataisTwitter, amongothersocialmediaplatforms.Twitterhasmorethan 303 million clients using its platform per month and over 500milliontweetsarepostedonadailybasis.Withsucha hugevolumeoftweetsanduserspostingeverythingabout everything this social media platform has eventually becomeahotspotforalmostallcompaniesandorganizations toproduceastrongimpactwhenitcomestothereputation of their brand, products, and services. Since Twitter is a platformwhereopinionsandreviewsreachmillions,there aremanytweetsaboutbrandsandcompanieswhichcanbe analyzedtobenefitthesaidcompany.Opinioninvestigation offersthesecompaniesandorganizationstheupperhandin screening different web based entertainment locales progressively.
The dataset being used is the sentiment140 dataset. This datasethas1,600,000tweetsfetchedfromTwitter API.The sentimentvaluesarerangedfrom0to4(where0isnegative and4ispositive)whichareusedtorepresentsentiment.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056 Volume:09Issue:05|May2022 www.irjet.net p ISSN:2395 0072
Thisdatasethasthefollowingsixfields: sentiment:whichshowspolarityoftweets(0=negative,4= positive)
ids:Theidofthetweet date:thedateofthetweet flag: The query. If there is no query, then the value is NO_QUERY. user:theuserthattweeted text:thetextofthetweet Hereweonlyrequirefields'sentiment'and'text',sowewill removeotherfields.
Again,we'retransformingsentimentvalues(0to4)to(0to 1).(0=Negative,1=Positive)
Review Paper on Sentiment Analysis Strategies for Social Media. This Review paper published by Shaikh Sayema AnwerandV.S.Karwandefocusesonsentencecompression usingNLPwithoutanylossofimportantdataandusesNaive Bayesclassifiertocategorizethesentimentsofdata.
SentimentAnalysisofTwitterData:ASurveyofTechniques VishalA.KhardeandS.S.Sonawaneprovidedasurveyand studyoversomeexistingtechniquesusedforopinionmining which includes machine learning and lexicon based approaches,whilefinallygettingthemostaccuratemodels asSVMandNaiveBayesClassifier.
TheBernoulliNaive Bayesisa type of NaiveBayesthat is particularlybeneficialtouseinabinarydistributionofdata points:especiallywhentheoutputlabeliseitheravailableor missingtousandhelpfultobeemployedwhenthedatasetis in a parallel dispersion where the result data points are either missing or available. The primary benefit of this particularalgorithmisthatthefeaturesittakesasinputare acceptedonlyintheformofbinaryvalues.Forexample:
0or1
TrueorFalse
LeftorRight
PresentorAbsent
YesorNo
Benefitsofusingthisalgorithmforbinaryclassification:
It is exceptionally quick compared to other classificationalgorithms.
Sometimes machine learning algorithms don't function well if the dataset is small and less data formatting,however,thisisn'taccurateinthiscase
becauseitgivesmorepreciseoutcomescompared withotherclassificationalgorithmsinthecaseofa smalldataset.
It's quick and can also handle and deal with irrelevantfeatures.
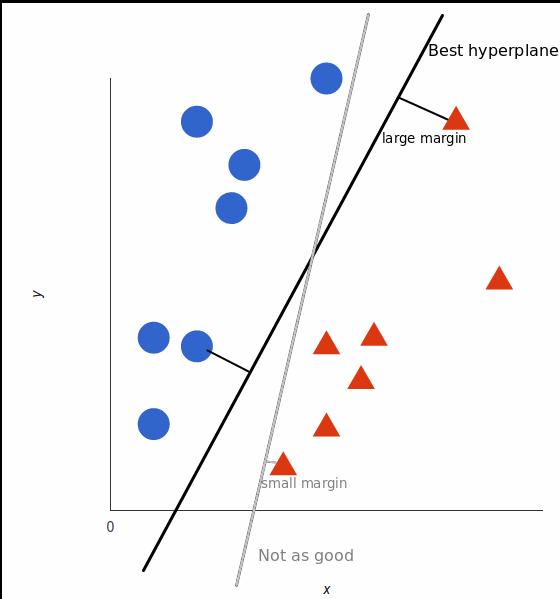
SVM (support vector machine) is a supervised machine learningmodelthatinvolvestheclassificationofdatainto2 differentcategories.Aftertrainingoversomeinputdata,for newdata,itoutputsthecategorywherethisnewdatafalls in.ThebasicfunctioningoftheSupportVectormachinescan bebestunderstoodwiththehelpofabasicmodel.Consider thatwehavetwotaglabels:blueandred.Ourinformation dataconsistsof2features:xandy.Ouraimistoprocurea classifierthat,forapairof(x,y)coordinates,organizesand producesoutputsbasedontheassumptionthatitisblueor red, below you can see that the plot is previously been labeledtrainingdataonaplane.
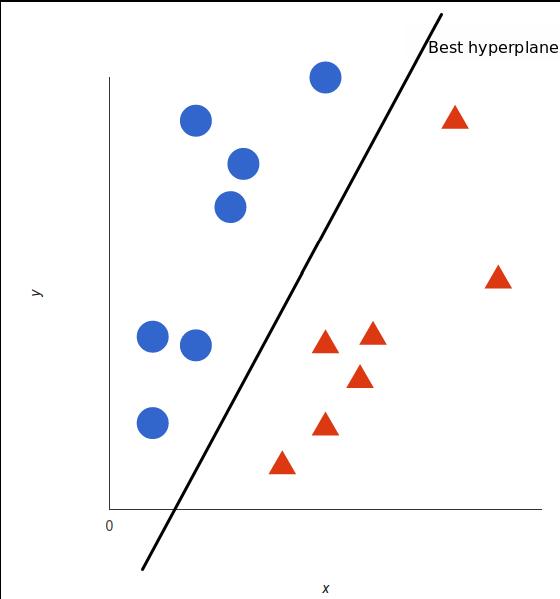
A support vector gives an output which is a hyperplane studying all input data points which as we can see representedin2 dimensionalformgivesasimplelinethat separates the two tags of a particular aspect. This line is calledadecisionboundary.Thisthenclassifiesthedatainto different categories based on which side data points are presentfromthehyperplane.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008
International
Journal of Engineering
Volume:09Issue:05|May2022
LogisticRegression(LR)isaclassificationtechniqueusedin machinelearning.Tomodelthedependentvariable,itusesa logisticfunction.Thedependentvariableusedcanbedivided dichotomousinnature,i.e.,therecouldonlybepresenttwo possibleclassessection(e.g.:eitherthepredictioncouldbe cancer is malignant or not). This technique is more often usedwhenwedealwithbinarydata.
Technology (IRJET) e ISSN:2395 0056
p ISSN:2395 0072
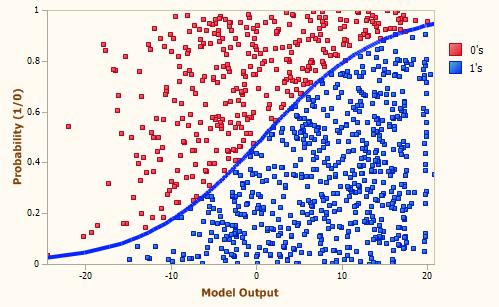
LogisticRegressionisgenerallyusedforpredictingbinary data targetvariables,itcanbefurtherclassifiedintothree differenttypesbelow:
a) Binomial: Where the target data variable has only two possibleclassificationtypes.e.g.:Predictingamailasspam ornot,OutputisYesorNo,1or0.
b)Multinomial:Wherethetargetdatavariablehasatleast threepossibletypes,whichmightnothaveanyquantitative importance.e.g.:Predictingillness.
c)Ordinal:Wherethetargetdatavariableshaveanordered numberofcategories.e.g.:Movieratingsfrom1to10.
In logistic regression, the sigmoid function maps and combinesthepredicteddatavaluestothedataprobabilistic function.Thissigmoidfunctionmapsandcombinesanyreal significant data value into another value in the range between0to1only.Thisfunctionhasapositivesubordinate ateachfixedpointandexactlyoneinflectiondatapoint.
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056
Volume:09Issue:05|May2022 www.irjet.net p ISSN:2395 0072
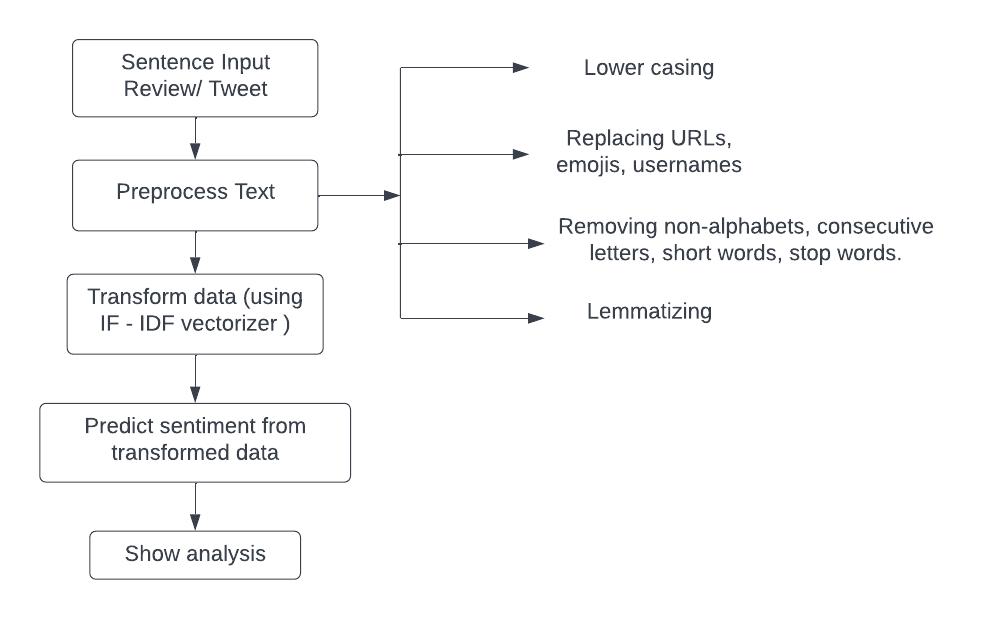
NLP(NaturalLanguageProcessing)isusedfortextpre processingwhichisthenforwardtoMachineLearning algorithms.
Textpre processinghelpstotransformtextdataintoamore digestible form so that machine learning algorithms can performbetter.FollowingarePre processingSteps:
1.Lowercasing:Eachtextisconvertedintolowercase.
2.Replacing URLs: Links starting with ‘http’ or ‘https’ or ‘www’arereplacedby‘URL’keyword.
3.ReplacingEmojis:Replaceemojisbyusingapre defined dictionarycontainingemojiswithmeaning.E.g.,‘:)’toEMOJI smile
4.ReplacingUsernames:Replacing@Usernameswithword USERe.g.,@KaggletoUSER.
5. Removing Non Alphabets: Replacing characters except DigitsandAlphabetswithaspace.
6. Removing Consecutive letters: 3 or more consecutive lettersarereplacedby2letters.E.g.,‘Heyyyy’to‘Heyy’.
7.RemovingShort Words:Wordswith lengths lessthan2 areremoved.
8. Removing Stop words: Stop words are English words whichdoesnotaddmuchmeaningtoasentence.Thesecan besimplyremovedfromthetextwithoutanylossofweight carryingwords.E.g.,‘the’,‘he’,‘have’.
9.Stemmingisthemethodwherewordsarereducedtotheir corestem.E.g.,‘Writing’to‘Write’
10 Lemmatizationisthemethodwhereawordisconverted toitsroot/baseform.E.g.,‘Better’to‘Good’.
WordCloudsareplottedonpositiveandnegativereviewsso astounderstand the weightageofparticularwordsinthe respective sentiment reviews.TF IDF is a vectorizer that convertsacollectionofrawtextintoanumericalformwith TF IDFfeatures.
TheproposedsystememploysNaturalLanguageProcessing anddifferentmachinelearningclassificationalgorithmsto deriveananalysisoncustomerfeedbackandreviews.This method has recently gained popularity and is being employedbymanye commercecompaniestoupleveltheir game. The said system analyzes the feedback and suggestionsreceivedanddetermineswhetheroneispositive ornegative.Amongthethreealgorithms Bernoulli’sNaive Bayes, Linear Support Vector Classifier, and Logistic Regression Classifier the highest accuracy was given by LogisticRegression.
[1] Che, Wanxiang, Yanyan Zhao, Honglei Guo, Zhong Su, andTingLiu."SentenceCompressionforAspect Based Sentiment Analysis." Audio, Speech, and Language Processing, IEEE/ACM Transactions on 23, no. 12 (2015):2111 2124
[2] David Zajic1, Bonnie J. Dorr1, Jimmy Lin1, Richard Schwartz. “Multi Candidate Reduction: Sentence Compression as a Tool for Document Summarization Tasks.”UniversityofMarylandCollegePark,Maryland, USA, 2BBN Technologies 9861 Broken Land Parkway Columbia,MD21046.
[3] TrevorCohnandMirellaLapata.“SentenceCompression Beyond Word Deletion”. Proceedings of the 22nd InternationalConferenceonComputationalLinguistics (Coling2008),pages137 144Manchester,August2008.
[4] . Seyed Hamid Ghorashi, Roliana Ibrahim, Shirin Noekhah, and Niloufar Salehi Dastjerdi. “A Frequent Pattern Mining Algorithm for Feature Extraction of Customer Reviews” IJCSI International Journal of ComputerScienceIssues,Vol.9,Issue4,No1,July2012 ISSN(Online):1694 0814.
[5] Dipanjan Das Andre, F.T. Martins. “A Survey on AutomaticTextSummarization”LanguageTechnologies Institute Carnegie Mellon University, November 21, 2007.
[6] Kapil Thadani and Kathleen McKeown. “Sentence Compression with Joint Structural Inference”.DepartmentofComputerScienceColumbia UniversityNewYork,NY10025,USA
[7] LuWang,Hema Raghavan,VittorioCastelli.“ASentence Compression Based Framework to Query Focused Multi Document Summarization”.Cornell University, Ithaca, NY 14853, USA ,T. J. Watson Research Center, YorktownHeights,NY10598,USA.
[8] Ghorashi, Seyed Hamid, Roliana Ibrahim, Shirin Noekhah, and Niloufar Salehi Dastjerdi. "A frequent pattern mining algorithm for feature extraction of customer reviews." In IJCSI International Journal of ComputerScienceIssues.2012
[9] Jin, Jian, Ping Ji, and Ying Liu. "Translating online customer opinions into engineering characteristics in QFD: A probabilistic language analysis approach." Engineering Applications of Artificial Intelligence 41 (2015):115 127.
[10] Kim, Soo Min, and Eduard Hovy. "Automatic identificationofproandconreasonsinonlinereviews." InProceedingsoftheCOLING/ACLonMainconference poster sessions, pp. 483 490. Association for ComputationalLinguistics,2006.
[11] Go,Alec&Bhayani,Richa&Huang,Lei.(2009).Twitter sentiment classification using distant supervision. Processing.150.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008
International Research Journal of Engineering and Technology (IRJET) e ISSN:2395 0056 Volume:09Issue:05|May2022 www.irjet.net p ISSN:2395 0072
ProfPrajaktaA Khadkikar
AssistantProfessorat PuneInstituteof ComputerTechnology RohanShiveshwarkar StudentatPuneInstitute ofComputerTechnology

OmShende
StudentatPuneInstitute ofComputerTechnology


SoudagarLondhe StudentatPuneInstitute ofComputerTechnology


SiddheshRamane StudentatPuneInstitute ofComputerTechnology
Impact Factor value: 7.529
9001:2008