International Research Journal of Engineering and Technology (IRJET)

Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
e ISSN: 2395 0056
p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
e ISSN: 2395 0056
p ISSN: 2395 0072
1,2,3 Dept. of Computer Science and Technology, Usha Mittal Institute of Technology, Maharashtra, India
4Professor, Dept. of Computer Science and Technology, Usha Mittal Institute of Technology, Maharashtra, India
***
Abstract - The information mining process has a wide scope of uses. This exploration uncovered key regions like information planning, highlight designing, model preparation, andassessment procedures inside the setting of CRISP DM, an information mining project. Opinion investigation/assessment digging is a strategy for sorting and characterizing computationally the sentiments or sentiments communicated in a piece of message to decide if individuals' mentalities toward a theme, premium, or item are positive, negative, or impartial. Profound learning is one of the most well known approaches in numerous normal language handling undertakings. On normal language handling undertakings, profound learning calculations beat conventional AI calculations. It is normal practice these days for individuals to utilize online entertainment to impart their considerations and insights on an assortment of subjects, with legislative issues being quite possibly the most famous themes among numerous social medium posts or recordings. Consistently, an enormous number of political recordings are transferred to YouTube, and most of individuals express their perspectives on ideological groups in the remarks part of these recordings. The review analyzes how well profound gaining strategies remove the political inclinations of YouTubers from the Hinglish dataset. This study will act as an establishment for giving helpful data to ideological groups during the political decision crusading by understanding andfollowing up onelectors' feelings.
Key Words: Social Media, Sentiment Analysis, Supervised Machine LearningModels.
INDIA is a political entity comprised of partially self governing provinces, states, and other regions united under a central federal government governed by parliamentary systems governed by the Indian constitution[1](A.a.N.S.Kaushik).ThePresidentofIndia serves as the supreme commander in chief of all Indian armedforcesandasthecountry'sceremonialhead [2](P. a.R.S.Chakravartty).However,thePrimeMinisterofIndia, who exercises the majority of executive authority over matters requiring country wide authority under a federal system, is the leader of the party or political alliance that wonamajorityinthecountry'sLokSabhaelections[3](S. a.J.K.a.C.J.Ahmed)Weareattemptingto analyzeone of
India'smosthistoricelectionsinthisresearch[4](S.a.J.K. a.C.J.Ahmed)
The aim is to assess the efficacy of deep learning approachesanddetermine whether deeplearning models applied to political datasets in the Hinglish language provide useful insights that can aid political parties in theircampaigning.
Thespecificgoalofthisresearchistoidentifyapromising classifier capable of effectively classifying the sentiments of Hinglish comments made on YouTube. It may provide some useful statistical data for improving the political campaign.
Along with the success of deep learning in many other application domains, deep learning is also popularly used in sentiment analysis in recent years [5](L. a. L. Y. Deng), [6](A.a.G.D.a.S.S.a.S.P.P.Garg)implementedCNNof4 convolutional layers on MNIST data set (having a huge number of handwritten text data) MNIST data set with 98.45% accuracy to show how deep learning can achieve high performance in digit or character recognition[7](H. Li)Mi crosoft Researcher, proposed a Fast Region based Convolutional Network method (Fast R CNN) for object detection achieved high accuracy of 66% to 68% compared to previous work on difficult objects. [8](L. a. M. G. a. M. K. R. a. S. W. Arras)applied the extended LRP version to a bi directional LSTM model for the sentiment predic tionofsentences,demonstratingthattheresulting wordrelevance’strustworthyrevealwordssupportingthe classifier’s decision for or against a specific class, and perform better than those obtained by a gradient based decomposition[9](Y.a.L.Y.a.O.A.a.L.S.a.W.S.a.L.M.S. Guo) implemented regional CNN LSTM model to predict the VA ratings of texts. By capturing both local (regional) information within sentences and long distance dependency across sentences, the proposed method outperformed regression and conventional NN based methods presented in previous studies. These researches showthatthereisscopeforexploringthesemodelsonthe politicaldomaindataset.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 3953
Ruchira Nehete1 , Amisha Paralkar2 , Osheen Pandita3, Prof. Amrapali Mhaisgawali4International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
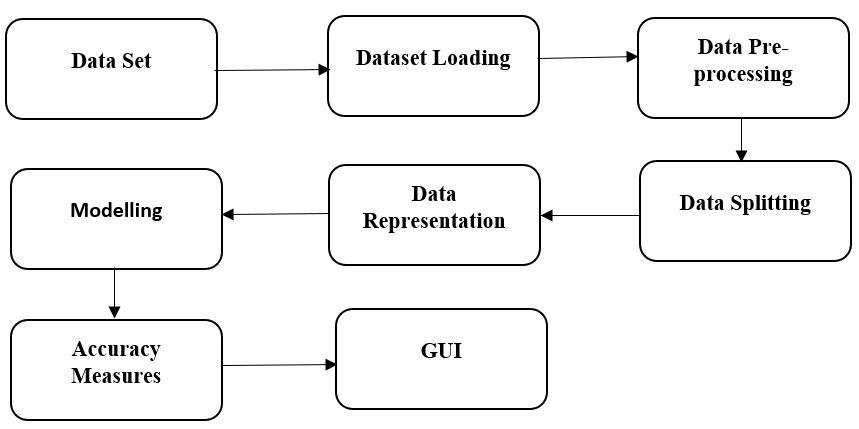
The working of the system is divided into the following parts as shown in Fig 1 [10](A. a. W. A. a. M. A. Botzenhardt)
Thebusinessissueistoevaluatefromadatasetof YouTube remarks, which partners the perspectives of the balloter on the political circumstances during the 2014 Indiangeneralpoliticaldecision.Theobjectiveistoutilize profoundlearningtechniquestoinvestigatetheopinionof the citizens, whether they are leaning toward a party or against them, and to observe how well these elector's feelingsdecide
The results of the race. The general business objective of this venture is to observe the best prescient profound learningmodelamongConvolutionbrainorganizationand MultilayerPerceptrontoorderthecitizen'sopinions.
The data interpretation phase begins with data collection and gaining first insights into the data to get acquaintedwiththedata.Inthisresearchdataisavailable fromgatheredfrompoliticalcommentsonapoliticalvideo published on YouTube.The datasets are taken from Various YouTube videos of the top two Indian political parties named Indian National Congress (INC) and Bhartiya Janata Party (BJP). Both the datasets are divided intotwocategories:
Label1 Positive
Label0 Negative
Label2 Neutral
All the labeling has been done manually by us In the dataset, each remark is appropriately named with paired numbers 1(one) and 0(zero). One method in favor and 0 methodsremark isagainst thepolitical gathering. Dataset isseparatedintotwoCSVdocuments,foreveryoneofthe
e ISSN: 2395 0056
p ISSN: 2395 0072
ideologicalgroupsreferencedpreviously.Aftergettingthe information,forthedisplayingreasonboththedatasethas beenconvertedtoasolitarydataset.
In pre processing on both the datasets, which included removal of stop words, null values, numbers, special characters, and punctuation, converting the entire text into lower case, tokenization, and stemming. In the pre processing phase, some steps d to be taken to access the data better. All the comments without subjects are modified by attaching political party names so that the model canlearneasily.Forexample,In theBJPcomments dataset, ”nice” a comment in favor is modified like this:” BJPisnice”.Therearesomecommentswhichincludeonly political leader names, to identify those comments better, concatenated with political party names BJP or Congress. Forinstance,“ModiisbetterthanRahul”willbeconverted to ”BJP Modi is better than Congress Rahul.” If the commentisa singlewordorwithout nouncommentslike ”Nice” and in favor of BJP, then ”BJP” is added at the beginningofthatcomment.similarly,if”Nice”isinfavorof congress ” Congress” is added to at the beginning of the comment.Afterremovingsuchambiguities,thecomments can be easily understandable by the model. Afterward, differentwordvectorizationtechniques:TF IDFandKeras token izer prepare data into deep learning require a format. After pre processing, various techniques of deep learningandtheirperformancecomparisonaredonewith adifferentconfigurationoflayersandnodes.
1)Removing Stop Words: Stop words are the words that add no importance to the sentences. For instance, "is", "am", "we", and so forth. It likewise incorporates accentuation. Such stop words ought to be eliminated from the text corpora before preparing a model.Inanycase,itisprudenttoinitiallypreparemodels without eliminating stop words to get the believability of text information. If the model neglects to give preferred exactnessoverjust,weoughttoattempttoeliminatestop words and take a look at execution. One explanation for thisisthatwecan'tcomprehendthemainimpressionthat which words are significant and which words are of less significance for building a model. In the investigation, subafteriminating the stop words model gave terrible showing contrasted with the model prepared on information with stop words. Thus, not all stop words howeverjustaccentuationsweretakenoutfromthecrude textinformation.
2) Stemming: Stem is also referred to as a root form of a word. So, a stemming sentence converts each word of a sentence to its original form after removing suffixes and prefixes. For Example: changing to change, played to play. The experiment stemming reduced model performance because of the Hinglish nature of the data. Nltk or Keras does not pose the functions to work with
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 3954
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
Hinglishlanguagedata.Hence,stemmedwordschangethe meaningofHinglishwords.Thatreducestheperformance ofthemodel.
3)Lemmatization: Then again, morphological examinationofthewordisaconsiderationwhilechanging the world over to its root structure. The stem probably won't be a genuine word though, the lemma is a real language word. To do such, nitty gritty word references are expected for lemmatization calculations to glance throughandconnectthewordstructurebacktoitslemma.
4)Tokenizing: Involves breaking each sentence into the word or character level tokens in N grams after filtering and removing words that do not add meaning to thesentences VectorizingtechniqueslikeTF IDF orKeras text to sequence converts this raw text data into vectors representingeachwordas anintegervalue [1]((A.a.N.S. Kaushik).Bylimitingmaximumwords,thevectorizeddata trains deep neural networks and are classified with deep learning techniques. [11](A. a. A. M. R. a. M. N. a. A. A. Hassan), [12] (Y. a. W. B. Zhang)In the end, they categorizedeitherin favoroftheBJPoragainsttheBJPin favorofCongress.
After the data is prepared, it is divided into training and test data with 75% and 25% respectively, using the Hold Out technique to evaluate the models on unseen/differentdatathanitwastrainedon,becauseifwe use the same data that we used to create the model, the model will simply remember the entire training set and will always predict the correct label, resulting in overfitting.
N gram is a feature extraction method that is carriedoutbymergingN wordsintoasinglesetandusing eachsetasafunctioninthedataset.Likethis, thebi gram approach looks at every pair of terms, and the tri gram approach looks at every triplet, etc. In this research, we aretryingtocomparethemodelperformancefordifferent N gramsandhowitaffectstheaccuracyofbothmodels.
1)TF IDF: The aim behind TF IDF is that not all words occurring most frequently in a document are important or related to documents. Instead of just countingtheoccurrenceofwords,thisalgorithmallocates weightsorimportancetoeachwordandcreatesatabular formofwordsanddocuments [13](S.Robertson).Inverse DocumentFrequencydefinesameasureoftheimportance ofa word.Thetermslike”is”,“of”, and”that”whichoccur inmanydocumentsshouldbelessimportantthanonelike ”election”whichoccurinafewpolitics relateddocuments. [13] (S. Robertson). TF (Term Frequency) measures the frequency of the term in the document itself. The
e ISSN: 2395 0056
p ISSN: 2395 0072
importance ofthewordisnow themultiplicationofthese twovaluesIDFandTF.ItiscalledaTF IDFweight.
IDF(t)=loge(Totalnumberofrecords/Numberofreports withtermtinit).
TF(t) = (Number of times term t shows up in a record)/(Totalnumberoftermsinthereport).
TF IDF weight = TF(t) * IDF(t)We have around 5324 featuresmaximum,werestrictedvectorsizeto5300most frequent words generated by TF IDF trigrams.
2)KerastexttoSequence: Change eachtextinthe summary into an entire number progression. Simply the primary ten most often used words will be thought of. Simply words that the tokenizer sees will be considered. We've kept the best language size at 5300 experiencing thesamethingaswell.
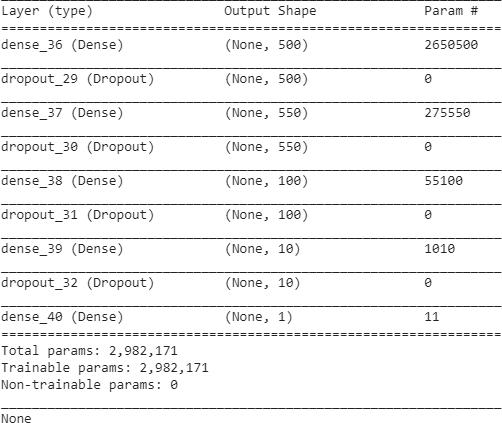
4.6.1. Multilayer Perceptron: Every neuron in the input layer, an output layer, and hidden layers are connected to each neuron in the next and previous layer neuronsinMLParchitectures.Itisthemostcommontype of deep neural network framework and is indeed a nonlinearclassifiermodeltofithighorderdimensionsfor binaryclassificationofpoliticalcomments.Thecomplexity of the model increases with three hidden layers, although theyarehopefullyhigh performance.Foreachinputword or dimension, it learns weights for each connection to achieve the lowest error. During the training process, the loss function is minimized by updating weights in each iteration with back propagation techniques like Adams, adamax. Lack of neurons means a lack of the connections that can cause the problem of underfitting and less accuracy. While more layers can lead to the problem of overfitting. With proper hyperparameters, it learns the weightssuchthatthelossfunctionisminimumtoachieve the best accuracy. in this research, we examine how the different number of layers and the different number of neurons affect the accuracy of the binary classifier network.Asshowninfigure2,weoptimizethenumberof
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
hidden layers and the number of neurons in each hidden layer so that the developed model can achieve the best performance. MLP used in the experiment was developed andtestedfordifferentnumberlayerscontainingdifferent neurons. The best performance was achieved on Multilayer perceptron as shown in figure 2.I/P layers of 500 neurons. Each hidden layer holds neurons with Relu (Rectified Linear Unit) activation function with maximum features of 5300. The first hidden layer contained 550 neurons. The second hidden layer occupied 150 neurons andthethirdhiddenlayercontained10hiddenneurons.
e ISSN: 2395 0056
p ISSN: 2395 0072
mentioned before, we must specify the number of filters theconvolutional layershave.Thefilterscanthink ofas a relatively small matrix with several rows and columns. Thevalueswithinthematrixareinitializedwitharandom number. When the layer receives an input, the filter considers3by3sizewillslideovereach3*3setpixelfrom the input until it slides overall 3by3 block pixels in the entire image. This sliding is referred to as convolving. We can say that filter is going to convolve over each input image. When the filter starts convolving, the dot product of each input 3by3 pixel set and filter matrix values is generated and stored in the convolution layer. The resultant matrix or output of the dot product is passed to the next convolutional layer as an input. And same dot product is repeated for the input matrix and filter matrix. Thegeneratedoutputvaluesareconvertedintocolorsours tovisualizepredictednumbers.
ii)Pooling Layer: Pooling is added after a convolutional layer. The convoluted matrix would contain a lot of pixel values. If the matrix or previous layer result is very large (ex. Large pixel matrix), the network will result in a slow learner. Typically, it is easy for any network to learn the features if the convoluted matrix size is necessarily reduced. The pooling layer replaces certain locations of input representation with values computed from nearby values. This operation is processed on every slice of the input representation or convoluted matrix. Finally, reducingor
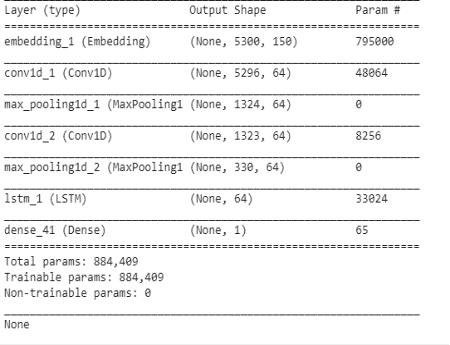
4.6.2 Convolutional Neural Network with Long Short Term Memory: CNNisaformofanartificialneural network. But it differs from standard Multilayer Perceptron (MLP). CNN has a hidden layer called the convolutional layer. It can also have other non convolutional layers. But the basis of the CNN is the convolutionallayer.
i)Convolutional Layer and filters: The function of the convolutional layer is Just like any other layer, it receives input,performsoninput,andtransfersittothenextlayer neurons in its network. This transformation is a convolutional operation within the convolutional layer. Convolutionallayerscandetectpatternsandimages.Tobe precise,theconvolutionallayermustbespecifiedwiththe number of filters. These filters are what detects the patterns. The precise meaning of patterns could be edged in mages, words in sentences, objects like eyes, a nose of faces, etc. The deeper the network is the more sophisticated is the network. And deeper networks can detect even full objects like a dog, cats, or birds [14](R. Girshick).Let’sconsideranetworkdetectingdigits0to9in the MNIST dataset. Our network is classifying them into imagesof1,2,3[6](A.a.G.D.a.S.S.a.S.P.P.Garg).solet’s assume the first layer is a convolutional; layer. As
transformed representation reduces the required computation. There are several functions for pooling. For example,representationbyselectingthemaximumvalues of the input matrix. It can also downsample based on averagingontheinputmatrix.Butmostoftheapplications use max pooling operations. And the pooled matrix is passed to the fully connected layers. Flatten layer used after pooling layer to pass the data to fully connected layers. In this experiment, CNN LSTM was developed and tested for different number layers containing different neurons.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page 3956
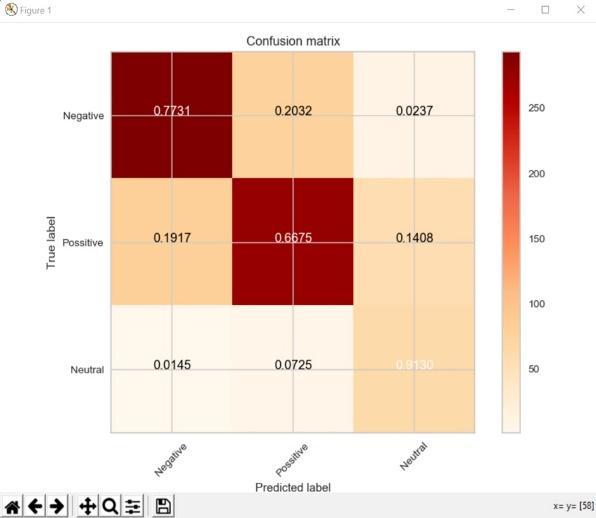
Graph.1.ConfusionmatrixofMultilayerperceptronInternational Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
e ISSN: 2395 0056
p ISSN: 2395 0072
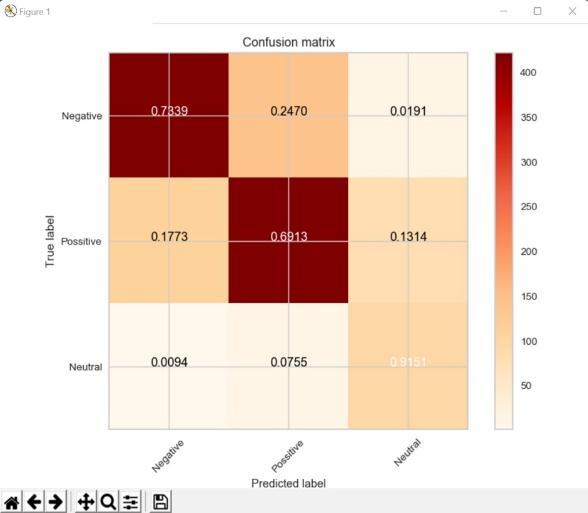
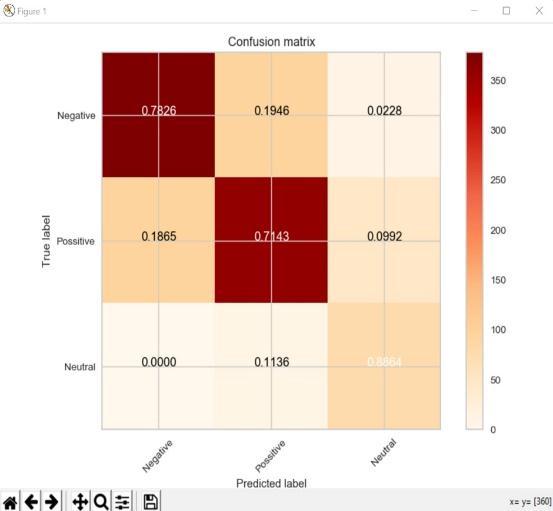
4.6.3. Long Short Term Memory: The LSTM comprisesunitsormemoryblocksintherepetitivesecret layer, which contains memory cells with self association putting away the fleeting condition of the organization. Notwithstanding this, the organization has exceptional multiplicative units called entryways to control the progression of data in the organization. Here we make a record planning word reference so that your often happening words are allowed lower files. The primary layeristheEmbeddedlayerthat

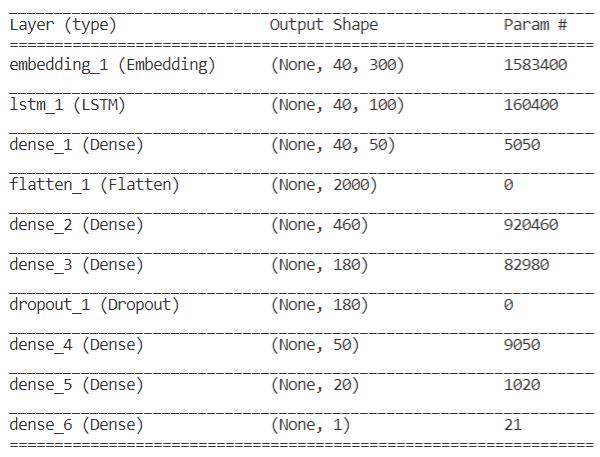
1)Word Embedding: The information from the message feed is inserted into a mathematical structure for the contribution of the CNN. Each word is addressed by a genuineworthvector.Thecirculatedportrayalofwordsis learnedbytheprocedureofmovelearning.
Vectors produced by word inserting are the contribution of the brain network layers. The convolution layer is the primary layer of CNN resultof thislayer isgivenasfar as possible pooling layer and a completely associated network is created. Softmax work is utilized after the completelyassociatedlayertocreatetheresult.
utilizes 300 length vectors to address each word. The following layer is the LSTM layer with 100 memory units (savvyneurons).Atlonglast,sincethisisanarrangement issueweutilizeaDenseresultlayerwithasolitaryneuron anda sigmoidinitiationcapacitytomakeexpectationsfor thethreeclassesintheissue.Sinceitisaparallelgrouping issue, misfortune is utilized as the misfortune work (binary_crossentropy in Keras). The proficient ADAM enhancement calculation is utilized. Utilizing model designated spot and callbacks, we are saving the model loads when approval exactness is greatest. A number of epoch we utilized are 10, cause we notice that the approvalexactnessrapidlybeginsfalling,showingthatthe modelisoverfitted.
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
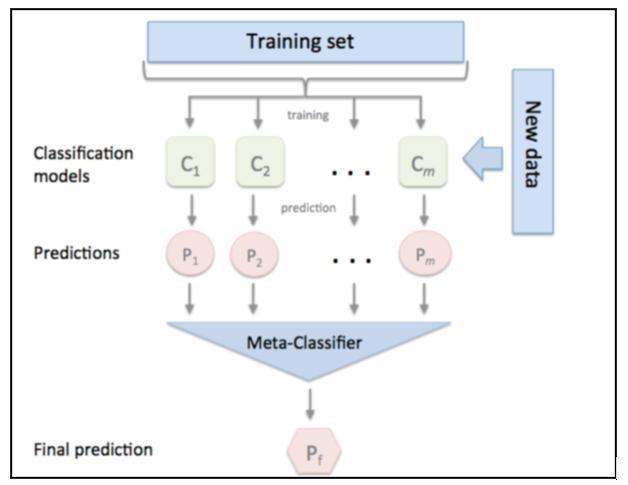
4.6.5. Stacking Classifier: Stacking is a group learningmethodtoconsolidatenumerousmodelsthrough a meta classifier. Dissimilar to helping, stacking isn't ordinarilyused toconsolidatemodelsofa similarsortfor instance a bunch of choice trees. Rather it is applied to models worked by various learning calculations. Assume youhaveachoicetreeinducer,aNaïveBayesstudent,and anoccurrence based learningplan andyou need toframe a classifier for a given dataset. The standard method is to gauge the normal mistake of every calculation by cross approval and to pick the best one to shape a model for expectationoffutureinformation.Inanycase,ratherthan doing this would we be able to simply join every one of them for expectation and consolidate the result. This should be possible by stacking, stacking presents the idea of a meta student, which replaces the past system. Stackingattemptstorealizewhich classifiersarethesolid ones, utilizing another learning calculation the meta student to find how best to join the result of the base students.
Fig.6.ThearchitectureofStackingClassifier
e ISSN: 2395 0056
p ISSN: 2395 0072
Theaccuracymeasureiscalculatedasthetotalno of correct predictions divided by the total number of records
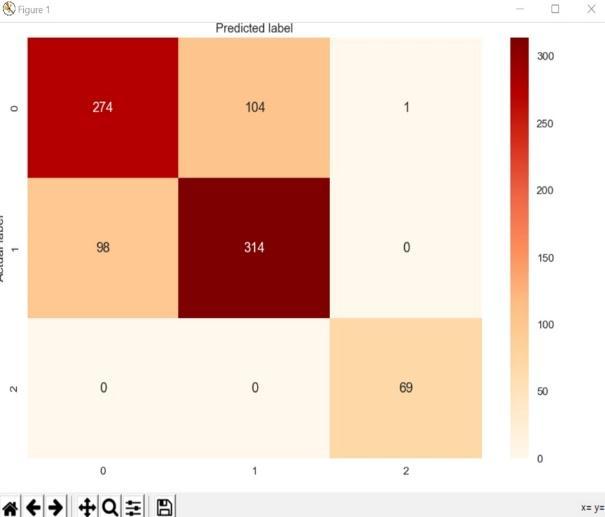
Here, the accuracies of all five models were obtained and analyzed which model has the highest accuracy. As mentioned in fig. 7, Convolution Neural Network with Long Short Term Memory has the highest accuracy.
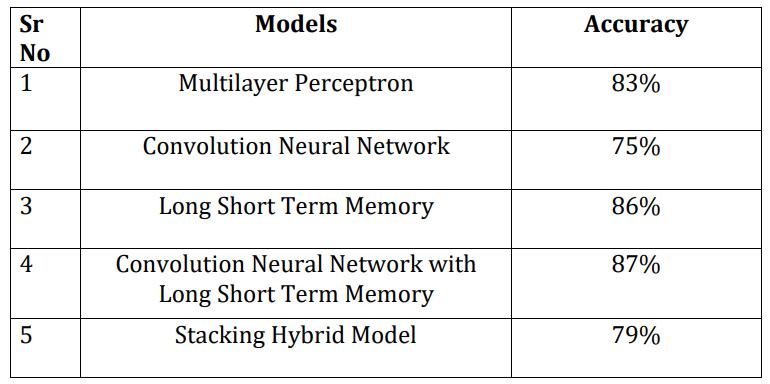
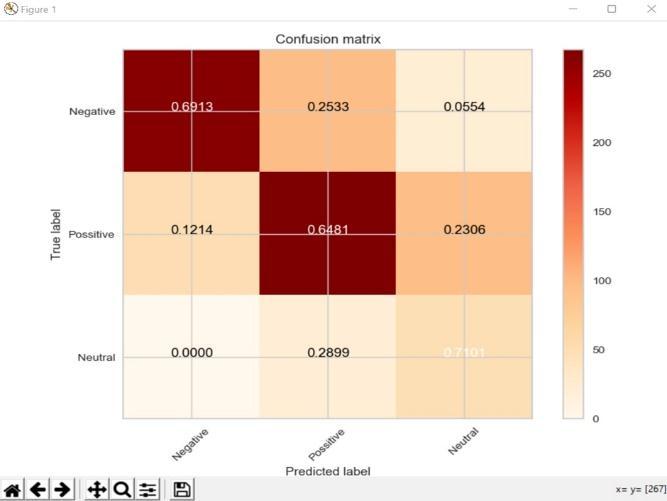
For Graphical User Interface, Convolution Neural NetworkwithLongShortTermMemoryhastobeusedas it has the best accuracy but, after performing it was noticedthatitdoesnotgivecorrectoutputasitseemedto be over fitted, so Stacking Classifier was used and correct outputwasobtained.

International
Volume:
Issue:
Journal
Engineering and Technology (IRJET)
e ISSN: 2395 0056
p ISSN: 2395 0072
Sentiment analysis goes under the class of text and assessment mining. It centers around dissecting the opinions of the tweets and taking care of the information to a machine learning model to prepare it and afterward actuallytakealookatitsexactnesssothatwecaninvolve this model for later use as indicated by the outcomes. It includes steps like data collection, text preprocessing, sentimentdetection,sentimentclassification,training,and testing of the model. However, it comes up short on the aspectofvarietyintheinformation.Additionally,it'sasyet nottriedhowexactthemodelwillbeforpointsotherthan the one in thought. Thus sentiment analysis has a very splendidextentofadvancementinfuture.

[1] A. a. N. S. Kaushik, "A study on sentiment analysis: methods and tools," Int. J. Sci. Res.(IJSR), pp. 2319 7064,2015.
[2] P. a. R. S. Chakravartty, "Mr. Modi goes to Delhi: Mediated populism and the 2014 Indian elections," Television \& New Media, vol.4,pp.311 322,2015.
[3] S.a.J.K.a.C.J.Ahmed,"The2014Indianelectionson Twitter: A comparison of campaign strategies of political parties," Telematics and Informatics, pp. 1071 1087,2016.
[4] A. Kalra, "Twitter to take India election innovations global.Reuters,"2014.
[5] L. a. L. Y. Deng, "Deep learning in natural language processing,"2018.
[6] A.a.G.D.a.S.S.a.S.P.P.Garg,"Validationofrandom dataset using an efficient CNN model trained on MNIST handwritten dataset," in 2019 6th International Conference on Signal Processing and IntegratedNetworks (SPIN),2019,pp.602 606.
[7] H. Li, "Proceedings of the Ninth IEEE International ConferenceonComputerVision,"2003.
[8] L. a. M. G. a. M. K. R. a. S. W. Arras, "Explaining recurrent neural network predictions in sentiment analysis," arXivpreprint arXiv:1706.07206, 2017.
[9] Y. a. L. Y. a. O. A.a.L. S. a.W. S. a. L. M. S. Guo, "Deep learning for visual understanding: A review," Neurocomputing, vol.187,pp.27 48,2016.
[10] A. a. W. A. a. M. A. Botzenhardt, "A Text Mining ApplicationforExploringtheVoiceoftheCustomer," 2011.


[11] A. a. A. M. R. a. M. N. a. A. A. Hassan, "Sentiment analysisonbanglaandromanizedbanglatext(BRBT) using deep recurrent models," arXiv preprint arXiv:1610.00369, 2016.
[12] Y. a. W. B. Zhang, "A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification," arXiv preprint arXiv:1510.03820, 2015.
[13] S. Robertson, "Understanding inverse document frequency:ontheoreticalargumentsforIDF," Journal of documentation, 2004.
[14] R. Girshick, "Fast r cnn," in Proceedings of the IEEE internationalconference on computer vision,2015.