International Research Journal of Engineering and Technology (IRJET)

Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
e ISSN: 2395 0056
p ISSN: 2395 0072

International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
e ISSN: 2395 0056
p ISSN: 2395 0072
1,2,3,4 Department of Computer Science and Engineering, Meerut Institute of Engineering and Technology, Meerut 250005, Uttar Pradesh, India
***
Abstract On the World Wide Web (www), when a query is searched by the user over a search engine, ranking is the way through which the importance of web pages is measured by a search engine. In today’s scenario, all the vital information is available online in the form of text documents. Various search engines are available for mining this available information, according to the user query, and giving appropriate and most relevant results to the user following his/her query. Search engines retrieve and show the documents according to their ranking. There are many search engines following page ranking for assignment of the weightage to the website’s pages. In this paper, content based matching is done along with the page ranking on hyperlink evaluation to display more accurate and relevant results following the user query.
Key Words: Hyperlinkevaluation,Ranking,Searchengine, Searchquery,content based.
Nowadays,thePage Rankmethodismostlyusedinbiblio metrics[7],information networks,social analysis,andlink prediction. It is also used for systems analysis of road networksandinScience,andneuroscience.Themainfactor isthatitdoesnotmatterhowlongthequeryis,theanswer will always come out in a particular order of links. Page Rank seems very simple. But when a simple calculation is appliedthousandsormillionsoftimesovertheresultscan seem complicated. The main purpose of this paper is to provideaneffectivewaytogetthequeryresultbyusingvery simplecodeforclarityandunderstanding.Thefuturework forstarterscanbe,thatweneedtooptimizeourmethodby creating what our target audience wants to see. This will attractlinksbetterthananythingelse.
A search query is a string of words a user enters in the searchbox,andthenthesearchenginegivestheresponse withinsub seconds.Asearchengineisanonlineapplication that gets a query input from the user and based on the keywordsorcatchphrasesreceivedbytheuser,itfetchesthe resultsbyonlinecrawling[8]thewebsiteswiththehelpof crawlers or spiders, and then sorts them to make a list of hyperlinkscorrespondingtothematcheddocuments.
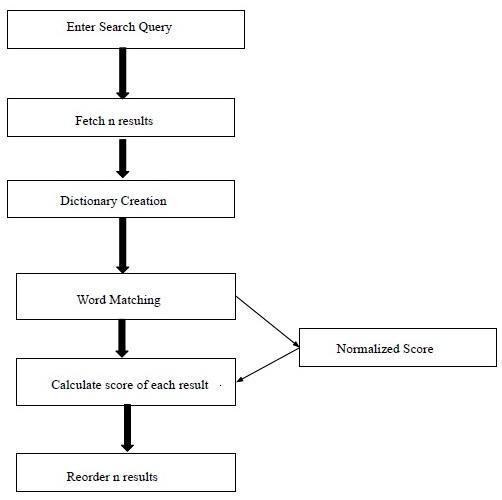
Inthispaper,Alongwiththecontent basedmatching,page ranking on hyperlink evaluation is done to display more accurateandrelevantresultsfollowingtheuserquery.First,
wehavefetchedoutthelinksalongwiththecontentpresent insidethetopmosttextdocumentsandpastedtheminsidea dictionary to evaluate a score to give the most relevant webpage, then the score is calculated for every document andataggedscoreisassignedtoeachofthem.Afterthat,the highestscoreisfoundtogetthebesttoppagesreorderedto improveuser fetchedresultsonthesearchengine.
TheresponsivesequenceoflistsisalsoknownastheSearch Engine Result Page(SERP). The sequence of responses providedbysearchenginesmayconsistofamixofvideos, images,articles,webpages, andmany othertypes offiles. The ranking of Web pages returned in response to a user querycombinesameasureoftherelevanceofthepagetothe query together with a query independent measure of the qualityofthepage.Theobjectiveofthisprojectistoreduce the uncertainty and un usefulness of the web pages that comeupatthetopofthedesiredresultsbyusingbothlink andcontentanalysis.
Thewebpagesshownatthetopofthesearchresultsbythe searchengineareattimesunwantedoruselessfortheuser throughcertainpractices.Mainly,webdocumentretrieval hasthreetypeswhichareexplainedas:
Organic search is termed as the search methodology by which the search pages are retrieved through the search engine’salgorithm.Inthesearchengine'salgorithmictest, web pages scoring exceptionally well are generally containingalgorithmsbaseduponfactorssuchasqualityand suitability of the content, specialization/expertise, authoritativeness,andtrustworthinessofthewebsiteandits respective content writer on the given topic. Usually, the organicsearchresultsaretheoneswhichareunpaidresults appearingextensivelyoverasearchenginewhentheresults page are popped up after the query gets searched by the user. For the sake of a relevant example, when user types "SouthIndianfood"inanysearchengine,say,Google,there arealltheunpaidresultsflashingwhichareallapartofthe organicsearch.Commonly,peopletendtoviewandopenup thetopmostresultsonthefirstpageofallthesearchresults. Eachpageofthesearchengineresults,usuallycontains10 organiclistings[1,2],however,someresultspagesmayhave
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
different observations and have fewer organic listings in common.
A quite large number of companies or profit making institutionsfindthemethodofshowinguptheirservicesand businesscapabilitiesintheformofadvertisementsonthe platform which is largely visited by interested users/customers.Therefore,awholelotofpopularsearch engines offer "sponsored results" to these organizations, who in turn pay these search engines for getting their productsorservicestoappearaboveothersearchhits.This is often done in the form of auction/bidding among the companies,inwhichthebidderpayingthelargestamountor bidding,inthiscase,getstheirhandsonthetopresultasa partoftheir businessgoodwill andprofit makingtactic.A sponsored search auction can also be called out as a keywordauction,whichislargelyanindispensablepartof thebusinessmodelbeingfollowedallovertheglobemainly bythemodernworldwebhosts.Here,thesponsoredsearch results are the results referring to the results obtained largelythroughasearchengineandarenotatallextracted out from the main search algorithm, but rather from this business trick followed by interested companies in sponsored search result technique, also these results are very much the separate advertisements paid for by third parties[4,7].Areportsubmittedin2018fromthehouseof EuropeanCommissionshowedthatgenerallytheconsumers avoid these top results, as they have an expectation and mentalitythatthetopmostresultsonasearchenginepage will be sponsored or baiting inthesensethatthey will be undesired,andthusquitelessrelevanttotheirinformation needs.
Manywebdocumentmakersframetheirwebpageinsucha waythatitcontainsamaximumnumberoflinkedpagestoit soastomakethewebdocumentseeminglyimportantand populartothesearchenginealgorithm.Also,thewebpages linked are blank and totallyunwanted at times. Here, The “about: blank” scenario comes into picture which is just a blank web page displayed when a user clicks on a highly attractiveorfreepremiuminformationwhichisalsoakind of bait to the user. Here, the browser finds itself in a situation where it shows up the user an empty web page. PageRankingisamethodofmeasuringthesignificanceof anyavailabledynamicwebpages.AspertheGoogle,Page Rankmechanismbycountingtheoccurrencenumberandits quality of links or relation to a page is to verify a rough approximationofhowsignificantthewebsite.Accordingtoa reportoverstatisticsfromStatist,Netmarketshare,andStat Counter, the top 5 search engines worldwide in terms of market share are namely, Google, Bing, Yahoo, Baidu, and YandexGoogle.Withapproximatelyover70%ofthesearch market share, Google is undoubtedly the most popular
value:
e ISSN: 2395 0056
p ISSN: 2395 0072
searchengine.Additionally,Googlecapturesalmost85%of mobiletraffic.But,herethecaseisthatthewebpagedoes not get served to you from an external source, so it isn’t harmfultoourcomputer.However,inmostofthecases,the causebehindshowingupablankpagecanbethemalware whichcanmakethebrowseropenablankpage.
The scoring of searched query results is done by a componentknownasqueryprocessorwhichisentitled with computing scores of web pages through the effective use of a ranking procedure that is highly dependent upon the retrieval model. Each and every rankingprocedureinnatelydependsonsucha model. Highly used form of finding the score in every web documentisasmentionedbelow[5]
Here,tj = jth weightofqueryterm, wj =jth weightofdocumentterm
And,thesummationisdoneforeachtermpresentinside thedictionaryofthecollectionfortherepository.
fig 1: Work flow of proposed methodology
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
First search a query or pattern (e.g.: Happy) and discoverthefirst3links.Andafterthat,pickupthe contentinsidethoselinksandexplorethesearching patternorquerywhetheritisonscreenornot.
1. Downloadthewordnetmoduleofpython fordictionaryusage.
2. Import that module to the main python programbyusingthefollowingcommands fromserp apiimportGoogleSearchfrom nltk.corpusimportwordnet.
importdictionarymodules { integertotal=0 q=inputqueryfromuser initializescore[]array total=0,sc=0 forinti=0ton: if(query[i]indictionary[words]): sc=sc+1 total=total+sc
Factor value: 7.529
e ISSN: 2395 0056
p ISSN: 2395 0072
elif(query[i] in dictionary[synonyms]):: score=score+0.5 total=total+score score[i]=sc; average_score=total/n if(score[i]>threshold_value) { score[i]=score[i]/average_score; }}
q=input("Enterthequerry:") #Takingquerry inputfromuser params={ "engine":"google", "q":q, "google_domain":"google.com", "api_key": "94a571b4a4482b0d19564027ebdc0bd28a6383f6 3a076a5829978637e65ddbdd"
} #parametersforgooglesearch search=GoogleSearch(params) #Avariblethat willstorethesearchresults results=search.get_dict() #Avariablewhich willstoresearchindictionaryform org_re=results['organic_results'] #weneedonly organicresults old={} #Anemptydictionary j=0 #Acountervariable foriinorg_re: old[j]={'rank':i['position'],'title':i['title'],'link': i['link'],'description':i["snippet"],'score':j} #store onlydesiredparameters j+=1 print("\n Theresultsare \n")#printingthesearchresults foriinold: print(old[i]['title']) print(old[i]['link']) print('\n') synonyms=[] #Avariableforstoring thesynonymsofthesearchedquerry q=q.split('') #forsetenceswesplitthe wordfortheirsysnonyms''l foriinq: forsyninwordnet.synsets(i): forlinsyn.lemmas(): synonyms.append(l.name()) synonyms=set(synonyms) print() #removeduplicatewordsbymaking theset total=0 foriinold: score=old[i]['score'] url=old[i]['link']
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
total=total+score try: request_result=requests.get(url) soup = bs4.BeautifulSoup(request_result.text,"html.parser" ) #Creatingsoupfromthefetchedrequest all_text=soup.get_text() score+=all_text.count(q) forjinsynonyms: score+=all_text.count(j)/2 old[i]['score']=score except: pass new={} #Anemptydictionary l=len(old) #noofsearchresults recived sc_l=[] foriinold: sc=old[i]['score'] ifscinsc_l: sc+=.1 sc_l.append(sc) average_score=total/(len(old)) new[sc]={'title': old[i]['title'],'link' : old[i]['link'] ,'description':old[i]["description"],'rank': old[i]['rank']} print("\n\n\n The Updated results are \n") #printing the Updated searchresults foriinsorted(new,reverse=True): print("prevrank:",new[i]['rank']) print(new[i]['title']) print(new[i]['link']) print("Score:",old[i]['score']) print('\n') print("Averagescoreis",average_score)
e ISSN: 2395 0056
p ISSN: 2395 0072
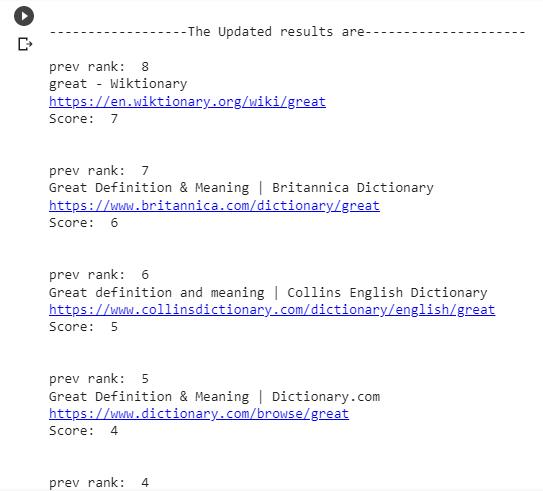
5.1 Demonstration of the algorithm with the help of an example
Step 1: Fetch the links related to entered query
fig 3: Fetched links of the entered query (here, query is ‘great’)
Step 2: Pick up the synonyms from word net dictionary
fig 4: Synonyms from wordnet dictionary (here, query is ‘great’)

© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3613

Step
International
Volume:
Journal of Engineering and Technology (IRJET)
Whatis Database Managem
system
Database Managem ent system
e ISSN: 2395 0056
p ISSN: 2395 0072
2,23,00,0 0,000 3.5 7 1
Essayon India Essay India 4,77,00,0 0,000 3.5 7 7
Download ing Python IDE
Downloa ding Python IDE
2,37,00,0 00 3.0 6 3
Hello Hello 3,26,00,0 0,000 3.0 6 7
Voting Resultsin UP
Voting Results UP
2,14,00,0 0,000 4.0 8 5
Election 2022 Election 2022 2,37,00,0 0,000 2.0 4 2
Uttar Pradesh Uttar Pradesh 2,11,00,0 0,000 2.5 5 3
fig
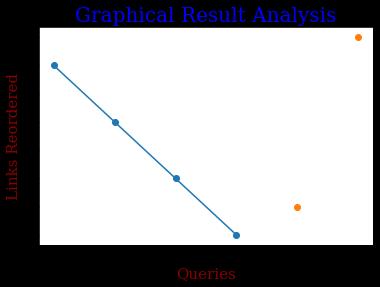
xpoints=np.array([1,2,3,4]) ypoints=np.array([6,4,2,0]) x2points=np.array([5,6]) y2points=np.array([1,7]) plt.plot(xpoints,ypoints,marker='o') plt.plot(x2points,y2points,'o') font1={'family':'serif','color':'blue','size':20} font2={'family':'serif','color':'darkred','size':15} plt.title("GraphicalResultAnalysis",fontdict=font1) plt.xlabel("Queries",fontdict=font2) plt.ylabel("LinksReordered",fontdict=font2) plt.show()
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
xpoints=np.array([1,3,5])
ypoints=np.array([4.5,4,3.5])
x2points=np.array([2,4,6])
y2points=np.array([3.5,4,3.5])
plt.plot(xpoints,ypoints,marker='o')
plt.plot(x2points,y2points,'o')
font={'family':'serif','color':'darkred','size':15}
plt.xlabel("Queries",fontdict=font2) plt.ylabel("N Score",fontdict=font2) plt.show()
Impact Factor value: 7.529
e ISSN: 2395 0056
p ISSN: 2395 0072
xpoints=np.array([1,3,5]) ypoints=np.array([9,8,7])
x2points=np.array([2,4,6]) y2points=np.array([7,8,7]) plt.plot(xpoints,ypoints,marker='o') plt.plot(x2points,y2points,'o')
font={'family':'serif','color':'darkred','size':15} plt.xlabel("Queries",fontdict=font2) plt.ylabel("Score",fontdict=font2) plt.show()
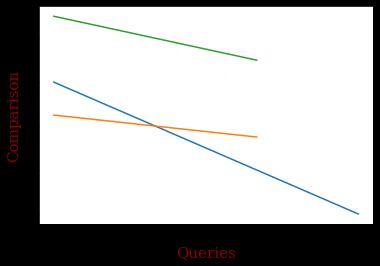
x1=np.array([1,2,3,4]) y1=np.array([6,4,2,0]) x2=np.array([1,2,3]) y2=np.array([4.5,4,3.5]) x3=np.array([1,2,3]) y3=np.array([9,8,7]) plt.plot(x1,y1,x2,y2,x3,y3)
font={'family':'serif','color':'darkred','size':15} plt.xlabel("Queries",fontdict=font)
ISO 9001:2008
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
plt.ylabel("Comparison",fontdict=font) plt.show()
AccordingtotheGraph,aftertheapplicationoftheranking algorithm,thepage’srankingischangingby4%accurately. Therefore,theabovealgorithmiseffectiveforbringingabout thetopresultsofsearchenginesintheuser'sdesiredorder. PageRankingisamethodofmeasuringthesignificanceof anyavailabledynamicwebpages.AspertheGoogle,Page Rankmechanismbycountingtheoccurrencenumberandits quality of links or relation to a page is to verify a rough approximationofhowsignificantthewebsite.
[1] Swati Jain,MukeshRawat (2020)Efficiencymeasures for ranked pages by Markov Chain Principle, InternationalJournalofInformationTechnology(2020), Volume13,Issue6
[2] Nandnee Jain, Upendra Dwivedi (2015) Ranking web pages based on user interaction time’’, International ConferenceonAdvancesinComputerEngineeringand Applications,IEEEXplore,pp.35 41,March19 20
[3] VojnovicM,CruiseJ,GunawardenaD,MarbachP(2009) Ranking and suggesting popular items. IEEE Trans KnowlDataEng21(8):1133 1146
[4] Nandnee Jain, Upendra Dwivedi (2015) Ranking web pages based on user interaction time’’, International ConferenceonAdvancesinComputerEngineeringand Applications,IEEEXplore,pp.35 41,March19 20
e ISSN: 2395 0056
p ISSN: 2395 0072
[5] Bruce Croft W, Metzler D, Strohman T (2015) Search engines information retrieval in practice. Pearson Education,London,pp25 26
[6] Ishii H, Tempo R (2014) The page rank problem, multiagentconsensus,andwebaggregation:asystems andcontrolview point.IEEEControlSystMag34(3):34 53
[7] Chakrabarti S, Dom B, Gibson D, Kleinberg J, Kumar R,RaghavanP,RajagopalanS,TomkinsA(1999)Mining thelinkstructureoftheworldwideweb.IEEEComputer SocPress32(8):60 67
Mr. Jagbeer Singh is the faculty assistant professor at Meerut Institute of Engineering and Technology,Meerut,U.P,India.

Anshika Jain is a final year graduateinComputerScienceand EngineeringatMeerutInstituteof Engineering and Technology, Meerut,U.P,India.
Anshita Bhardwaj is a final year graduateinComputerScienceand EngineeringatMeerutInstituteof Engineering and Technology, Meerut,U.P,India.


Amit Kumar is a final year graduateinComputerScienceand EngineeringatMeerutInstituteof Engineering and Technology, Meerut,U.P,India.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page3616
 Chart 4:ComparisonofallparametersvsQueries
Chart 4:ComparisonofallparametersvsQueries