
Voice Enable Blind Assistance System -Real time Object Detection
Real time object detection is a difficult operation since it requires more computing power to recognise the object in real time. However, the data created by any real time system is unlabeled, and effective training frequently necessitates a huge quantity of labelled data. Single Shot Multi Box Detection is a quicker detection approach for real time object detection, based on a convolution neural network model proposed in this paper (SSD). The feature resampling stage was eliminated in this work, and all calculated results were merged into a single component. Still, a light weight network model is required for places with limited processing capability, such as mobile devices ( eg: laptop, mobile phones, etc). In this suggested study, a light weight network model called MobileNet is adopted, which uses depth wise separable convolution. The usage of MobileNet in conjunction with the SSD model increases the accuracy level in detecting real time household objects, according to the results of the experiments.
Words: Object Detection, TensorFlow object detection API, SSD with MobileNet
1. INTRODUCTION
Intoday'sadvancedhi techenvironment,theneedforself sufficiencyisrecognisedinthesituationofvisuallyimpaired people who are socially restricted [3]. Visually impaired peopleencounterchallengesandareatadisadvantageasa result of a lack of critical information in the surrounding environment, as visual information is what they lack the most[1].Thevisuallyhandicappedcanbehelpedwiththe use of innovative technologies. The system can recognise itemsintheenvironmentusingvoicecommandsanddotext analysistorecognisetextinahardcopydocument.Itmaybe an effective approach for blind persons to interact with othersandmayaidwiththeirindependence.Thosewhoare whollyorpartiallyblindareconsideredvisuallyimpaired. According to the World Health Organization (WHO), 285 millionpeopleworldwidesufferfromvisionimpairment,39 peopleareblind,andaround3%ofthepopulationofallages is visually impaired [1][4]. Visually impaired people go throughalotandencounteralotofdifficultiesintheirdaily lives, such as finding their way and directions, as well as goingtoplacestheydon'tgoveryoften.

2. Existing System
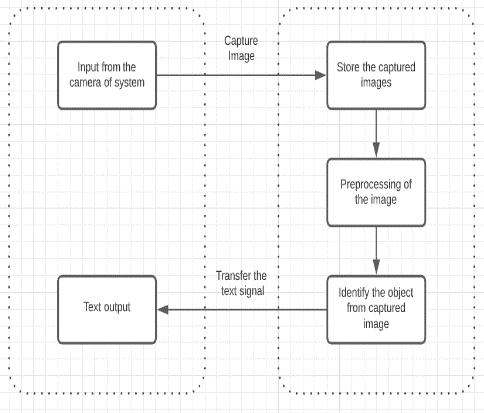
Fig 1:FlowChartOfExistingSystem
In existing system (Fig.1.), system take surrounding information with help of webcam and then store the captured images. These images under goes preprocessing stepandthenidentifytheobjectsfromthecapturedimage andafterthatsystemwillgiveoutputintextformat[1][3].
3. Working
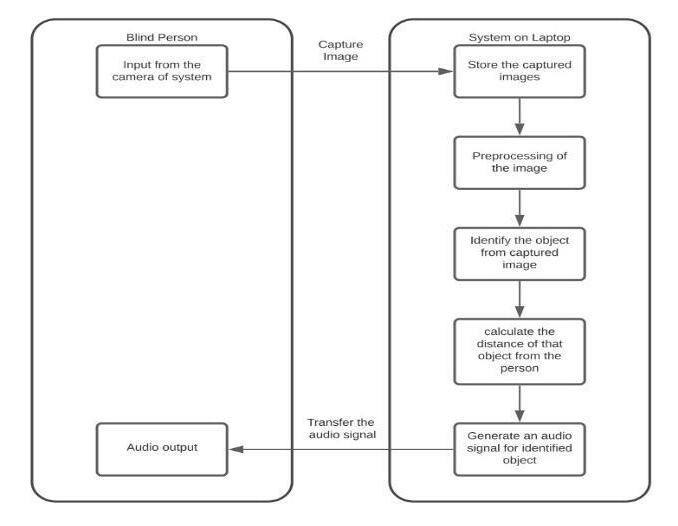
Visually challenged people, on the other hand, cannot readilygooutsideforwork.Theyarecompletelyrelianton others.Asaresult,whentheywishtowalkoutside,theywill wantassistance[12].Oursystem's(Fig.2.)proposeddesign isbasedontherecognitionofobjectsintheenvironmentofa blind person. The proposed object/obstacle detection technologyworksinsuchawaythatitrequiresvarioussteps fromframeextractiontooutputrecognition.Todetectitems in each frame, a comparison between query frame and databaseobjectsisperformed[3][8].Wepresentasystem
[1] The system is set up in such a way where an systemwillcapturereal timeframes.
[2] The Laptop Based Server will be using a pre trainedSSDdetectionmodeltrainedonCOCO DATASET[12].Itwillthentestandtheoutput classwillgetdetectedwithanaccuracymetrics.
[3] Aftertestingwiththehelpofvoicemodulesthe class of the object will be converted into a defaultvoicenoteswhichwill thenbesentto theblindvictimsfortheirassistance.
[4] Alongwiththeobjectdetection,wehaveused an alert system where approximate will get calculated.IfthatBlindPersonisverycloseto theframeorisfarawayatasaferplace,itwill generate voice based outputs along with distanceunits.
3.2 Tensor Flow
TensorFlowAPIswereusedtoimplementit.Thebenefitof using APIs is that they give a collection of common operations [5][9]. As a result, we don't have to write the program's code from start. They are both helpful and efficient,inouropinion.APIsaretimesaverssincetheygive uswithconvenience.TheTensorFlowobjectdetectionAPIis essentially a mechanism for building a deep learning networkthatcansolveobjectdetectionchallenges[5][11]. Theirframeworkincludestrainedmodels,whichtheyrefer to as Model Zoo [3]. This contains the COCO dataset, the KITTIdataset,andtheOpenImagesDataset,amongothers. COCODATASETSaretheprimaryfocushere.
of Engineering and Technology
2395
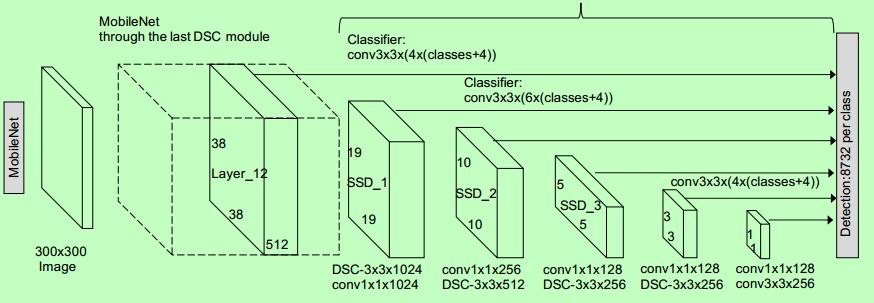
TheSSDconsistsoftwoparts:anSSDheadandabackbone model.
Asafeatureextractor,thebackbonemodelisessentiallya trainedimageclassificationnetwork.Thisisoftenanetwork trained on ImageNet that has had the final fully linked classificationlayerremoved,similartoResNet[3][1].
TheSSDheadisjustoneormoreconvolutionallayersadded tothebackbone,withtheoutputsreadasboundingboxes and classifications of objects in the spatial position of the finallayeractivations[3].
Asaresult,wehaveadeepneuralnetworkthatcanextract semantic meaning from an input image while keeping its spatialstructure,althoughatalesserresolution.
InResNet34,thebackboneproduces2567x7featuremaps for an input picture. SSD divides the image into grid cells, witheachgridcellbeinginchargeofdetectingthingsinthat region [1][7]. Detecting objects entails anticipating an object'sclassandplacementinsideagivenregion.
3.4 MobileNet
This model is based on the MobileNet model's idea of depthwiseseparableconvolutionsandgeneratesafactorised Convolutionsv[7].Thedepthwiseconvolutionsarecreated by converting a basic conventional convolution into a depthwiseconvolution.Pointwiseconvolutionsareanother name for these 1 * 1 convolutions. These depthwise convolutionsapplyageneralsinglefilterbasednotiontoeach of the input channels for MobileNets to work. These pointwiseconvolutionsuse1*1convolutiontocombinethe depthwiseconvolutions'outputs.Bothfilters,likeatypical convolution,combinetheinputsintoanewsetofoutputsina single step [1][7]. The depthwise identifiable convolutions partitionthisintotwolayers oneforfilteringandtheother for mixing. This approach of factorization has the effect of dramaticallyloweringcomputingtimeandmodelsize.
3.5. VOICE GENERATION MODULE
Followingthedetectionofanobject,itiscriticaltoinformthe person on his or her way of the presence of that object. PYTTSX3 is a crucial component of the voice generation module. Pyttsx3 is a Python conversion module for convertingtexttospeech [8].Thislibraryiscompatiblewith Python2and3.Pyttsx3isasimpletoolforconvertingtextto speech.
Thistechniqueworksinthefollowingway:everytimeanitem isidentified,anapproximatedistanceiscalculated,andthe textsaredisplayedonthescreenusingthecv2libraryand the cv2.putText() function.We utilise Python tesseractfor character recognition to find buried text in an image. OCR
recognisestextcontentonimagesandencodesitinaformat thatacomputercanunderstand[7].Thetextisdetectedby scanning and analysing the image. As a result, Python tesseract recognises and "reads" text encoded in images. Thesetextsarealsolinkedtoapyttsx.
Asanoutput,audiocommandsaregenerated."Warning:The object(classofobject)istooclosetoyou,"itsaysifthething istooclose.Andiftheobjectisatasafedistance,avoiceis generatedthatstates,"Theobjectisatasafedistance."Thisis accomplished using libraries like as pytorch, pyttsx3, pytesseract,andengine.io
Pytorch is a machine learning library first and foremost [7][8].Pytorchisprimarilyusedintheaudiofield.Pytorch aidswiththeloadingofthevoicefileinmp3format
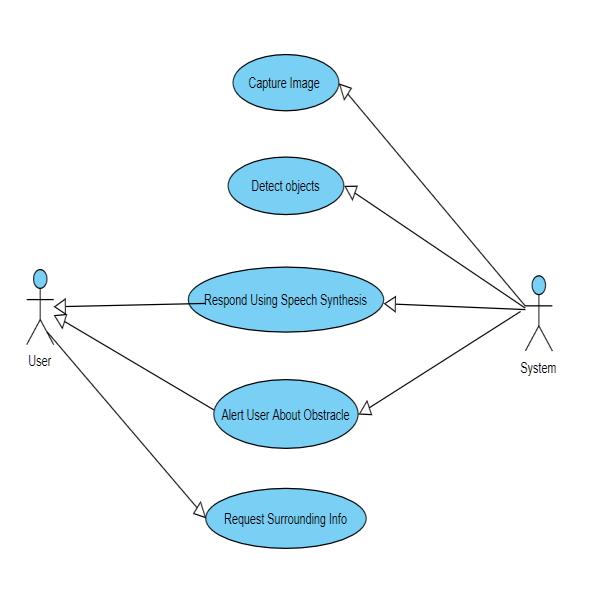
Fig 4:UseCaseDiagramOfSystem
InaboveFig.4.asyoucansee,therearetwocharacter,user andsystem.Userwillsendsurroundinginformationsystem. Andthensystemwillcapturetheimage,detecttheobject& respondusingaspeechsynthesis.Andinlastsystemwillgive analerttouserabouttheparticularobstracles.
3.6 Image Processing:
Imageprocessingisatechniqueforperformingoperations on a picture in order to improve it or extract relevant informationfromit[6].
"Imageprocessingisthestudyandmanipulationofadigital image, notably in order to increase its quality," says the fundamentaldefinitionofimageprocessing.
3.7 OPENCV:
OpenCVisafree,open sourcecomputervisionlibrary.This library includes functions and algorithms for motion
3.8 What is COCO?
The
Result
5. Conclusion & Feature
Inthis research, weattempted to recognisean object that was displayed in front of a webcam. TensorFlow Object
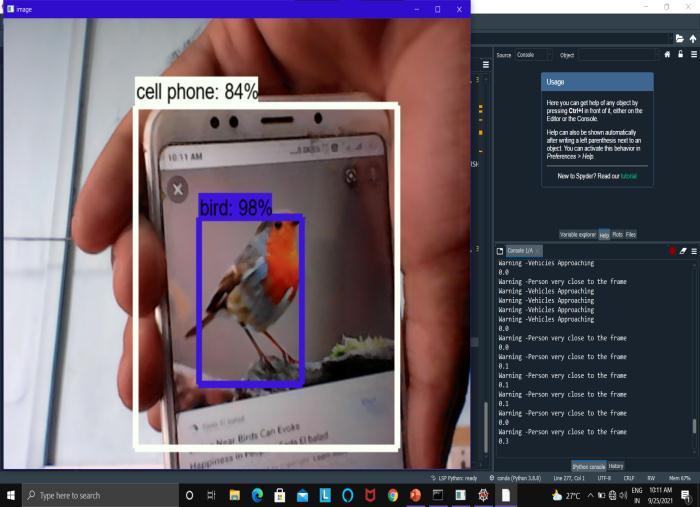
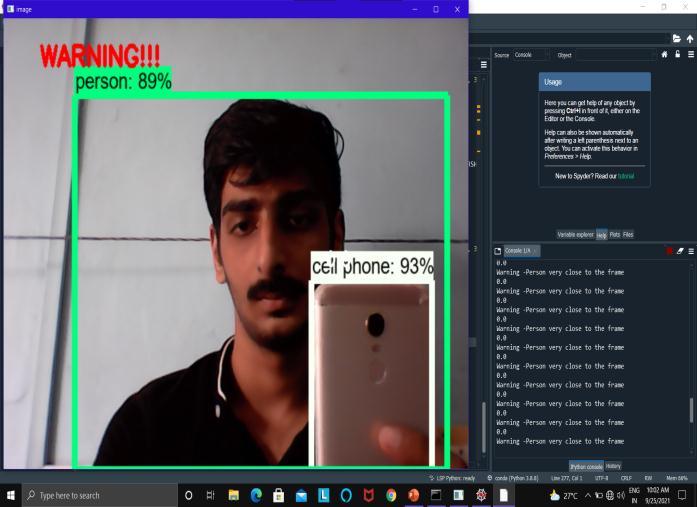
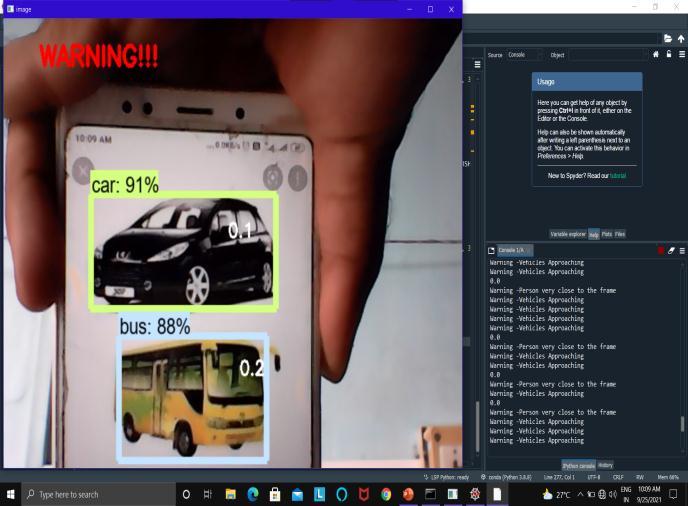
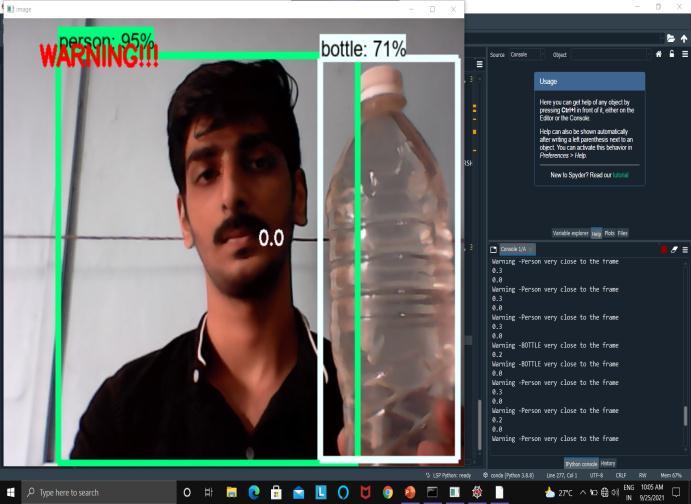
APIframeworkswereusedtotestandtrainthe created model. Reading a frame from a web camera generatesnumerousproblems,soagoodframespersecond solutionisrequiredtoreduceInput/Outputconcerns[3.As a result, we focused on threading methodology, which considerablyimprovesframespersecondandhencegreatly reducesprocessingtimeforeachitem.Despitethefactthat theapplicationaccuratelyidentifieseachthinginfrontofthe webcam,ittakesroughly3 5secondsfortheobjectdetected boxtomoveoverthenextobjectinthevideo.
Using this study, we will be able to recognise and track objects in a sports field, allowing the computer to learn deeply,whichisaDeepLearningapplication.
International Research Journal of Engineering and Technology (IRJET)
Volume: 09 Issue: 04 | Apr 2022 www.irjet.net
We can manage the traffic signals by detecting the AmbulanceVehicleinthetrafficusingthePublicSurveillance Camera. The technique could be beneficial in a variety of fields in the future, such as reading literature, currency checking,andlanguagetranslation,amongothers.
Asaresult,theprojectwillbebeneficialindetectingand trackingitems,makinglifeeasier.
Acknowledgement
Authors thanks Prof. Siddhesh Khanvilkar, Associate professor at University of Mumbai and Head of Department, Dr. Divya Chirayil at Pillai HOC College of EngineeringandTechnology,Rasayani,Panvel.
6. Reference
[1] Qianjun Shuai, Xingwen Wu “Object detection system basedonSSDalgorithm”.In IEEE,Oct2020
[2] Harish Adusumalli, D. Kalyani, R.Krishna Sri, M.Pratapteja,PVRDPrasadaRao“FaceMaskDetection UsingOpenCV”.InIEEE, 2021
[3] Kanimozhi S , Gayathri G , Mala T “Multiple Real time object identification using Single shot Multi Box detection”.InIEEE,2021
[4] World Health Organization, “Visual Impairment and Blindness,”WHOFactsheetno.FS282,Dec.2014.
[5] BNKrishnaSai;T.Sasikala“ObjectDetectionand CountofObjectsinImageusingTensorFlowObject DetectionAPI”.InIEEE,10February2020
[6] FaresJalled,“ObjectDetectionUsingImageProcessing”. InarXiv:1611.07791v1[cs.CV]23Nov2016
[7] Mr. Harshal Honmote, Mr. Pranav Katta, Mr. Shreyas Gadekar, Mr. Shreyas Gadekar, “Real Time Object Detection and Recognition using MobileNet SSD with OpenCV”. In IJERT ISSN: 2278 0181 Vol. 11 Issue 01, January 2022
[8] Ayushi Sharma,Jyotsna Pathak,Muskan Prakash,J N Singh,“ObjectDetectionusingOpenCVandPython”.In IEEE,09March2022
[9] Priyal Jawale, Hitiksha Patel, Nivedita Rajput, Prof. Sanjay Pawar , “Real Time Object Detection using TensorFlow”.InIRJET,Aug2020
[10] Shreyas N Srivatsa, Amruth, Sreevathsa , Vinay , Mr. Elaiyaraja,“ObjectDetectionusingDeepLearningwith OpenCVandPython”.InIRJET,JAN2021
ISSN: 2395 0056
ISSN: 2395 0072
[11] Tufel Ali Qureshi, Mahima Rajbhar, Yukta Pisat, Prof. VijayBhosale,“AIBasedAppforBlindPeople”.InIRJET, March2021
[12] Dr.S.V.Viraktamath,MadhuriYavagal,RachitaByahatti, “ObjectDetectionandClassificationusingYOLOv3”.In IJERT,February 2021
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008