International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072
5
1 Associate Prof. and Head, Dept. of Computer Science and Engineering, T John Institute of Technology, Bengaluru 2,3,4,5 Department of Computer Science and Engineering, T John Institute of Technology, Bengaluru ***
Abstract - Legal assistance is an automated approach to providing accurate references, predictions and judgements to lawyers and legal professionals for case preparation using Machine Learning and Artificial intelligence. It reduces the time spent by the lawyer in the preparation of a case study for the client's representation in court. It also improves the overall quality of the case study by providing better references and best case-related judgments. This also helps the judiciary in its decision-making process. This research work is a critical analysis of various AI and Machine Learning approaches used to provide legal assistance to judicial systems all over the world.
Key Words: Artificial Intelligence (AI), Machine Learning, Courts of India, Lawyers, IPC, Legal, Judgements, Natural Language Processing (NLP), Ontologies etc.
ThelawsysteminIndiaishavingaslowpacewhenitcomes totheresolutionofcases,SupremeCourtofIndiaalonehasa listof71,411pendingcasesasofAugust2nd,2022,outof which56,365arecivil casesand15,076criminal cases.In the High courts of India, the average hearing time for one caseisonlyabout300to500secondswiththenexthearing to be conducted after 16 to 80 days. This increases the pressureonlawyersandLegalProfessionalsinpreparation for their case studies for cases and trials. Even small negligencecanbethedifferencebetweenwinningandlosing thecase.Thus,sometimesjusticecouldbedeniedbecauseof Humanerror.Theonlypresentoptionistostretchthetime ofdurationofthecasetogetproperevidenceandprevent misjudgments.
ThemajorityofworkinthelegalsystemofIndiaisstillbeing done manually which includes data collection for a case study, referencing, searching for the right judgements to referforthecasesetc.[11]IntheDistrictandTalukascourts ofIndiamorethan31millioncasesarepending.IntheHigh CourtsofIndia,thetallyreachesupto4.5millionpending cases.
WecanuseAI/MLtoassistlawyersintheircasestudiesand reduce human error and inefficiency, resulting in less pressureonlawyersandadvocates,betterinfographicsfor
judgement,andlesstimespentdealingwithandfinishinga case or trial. This study is a critical review of existing research and development for providing legal assistance using Artificial Intelligence and Machine Learning techniques.MachineLearningandArtificialIntelligencehave transformedeverymajorfield'sworkingmodel.AIandML have automated the work that was previously done manually, it saves time, increases quality, and improves overallefficiency.TheAI-basedpredictionmodelwillhelp theLawyerandAdvocatedecidethelevelofexpertisethatis neededinacase.
FollowingaretheAIandMachinelearningtechniquesthat areusedforbuildingalegalassistant.
• TextAnalysis
• SentimentalAnalysis
• NeuralNetworkModel
• DecisionTree
• Clustering
The motivation for this research is to identify optimal techniques that could aid in the development of an AIpoweredAssistantforlegaluse,whichcouldspeedupthe process of case completion while also providing better representationtoclients.
Asacountrywithapopulationofover1.3billionpeople,itis critical to optimize the resources available in the legal systemsothateveryonecanexercisethefundamentalrights guaranteedbytheIndianConstitution.
There are no mainstream automation strategies implemented in today's Indian legal system that helps lawyers and legal professionals prepare for the representation of their client. Due to the high number of casesthatarependinginIndianjudicialcourts,thisproblem amplifies furthermore and could lead to underrepresentation due to human limited capabilities, increasingtimeinresolutionofcasesandmakingthelegal systemoutofreachforthemajorityofthecitizens.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072
PythonisusedforthedevelopmentofMachinelearningand ArtificialIntelligenceprojectbecauseofitsmassivelibraries thatareusefulfordataanalysis,datamanipulation,easier implementation of Machine learning and AI models etc. Pythonframeworksarereferredinthis researchworkfor theimplementationofdifferenttechniquesusedbyalegal assistant.
Text analysis is a process to analyze text and find out the indented of the text. This process helps the machine understandthetruemeaningofthetextandcangeneralize thetextintodifferentcategories.[12]SomemodelsuseNLP for legal document classification. The techniques used in those models are Tokenization, Lowercasing, Punctuation removal, Part of Speech tagging, Numeral normalization, Name normalization, Lemmatization, and Non-ASCII characterremoval.[3]Afterinformationextractionfortext analysis, we need to perform normalization. The normalizationprocessfindstheguessedentities,andaliases forthoseguessedentitiesandgroupsthoseentitiestogether. Aliasesareentitiesthataremisspelttoacertaintolerance levelfromtherootentityorarewritteninthescriptsthat definetwoentitiesasaliases.
TheNaturallanguageprocessingrequiredfortextanalysisof legaldocumentsare:-
Tokenization
Stopwordsremoval
Stemming
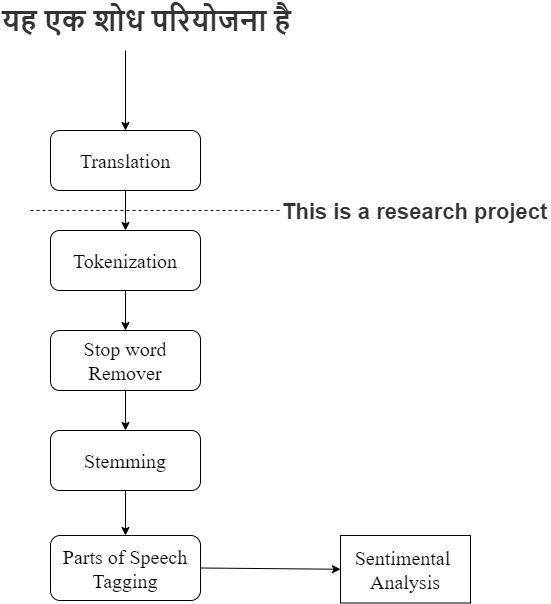
In Figure 1 We can see the sequential process of text analysis.First,thetextistranslatedintoacommonlanguage, in this case, Hindi text (legal text can be in any of the 22 scheduled languages in India) is translated into English. Afterthetranslationprocess,tokenizationtakesplace.The list of tokens generated then goes for stop word removal. Aftertheremovalofstopwordsstemmingfromthetextis performed. The root words then go for part of speech tagging.Nowthetextisreadyforthesentimentalanalysis.
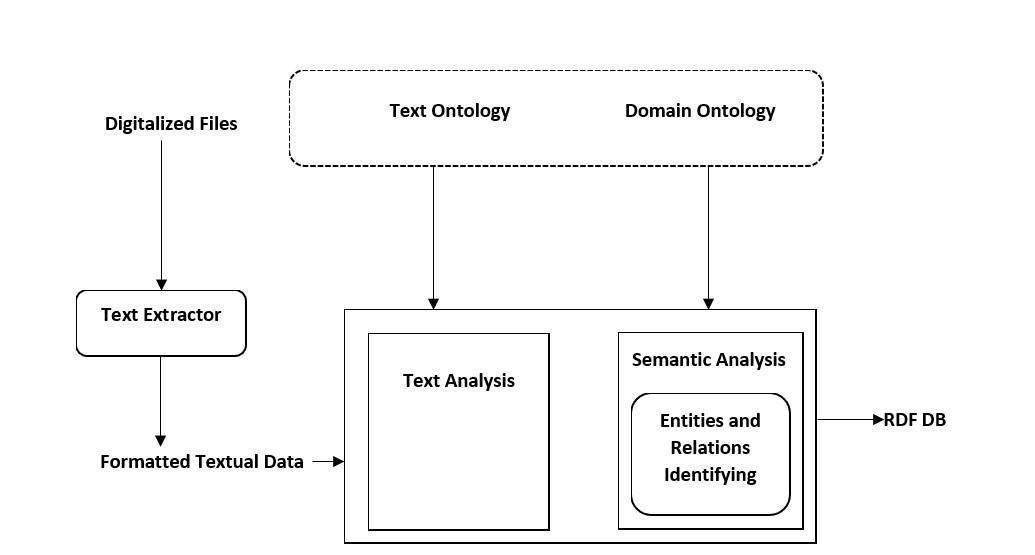
[15]InFigure2wecanseedifferentlevelsofontologyand NLP techniques to transform semi-structured documents into structured RDF triples and we described suitable algorithmsthatcanabletosegmentandextracttherequired informationfromlegaldocuments.Theexperimentalsection hasshownveryencouragingresults
Figure 1. SequentialuseofNaturalLanguageProcessing Techniques.
Tokenizingisapre-processingprocesswhichisusedtosplit thetextinto small chunksorblockssuchasa word,term, letters etc. Each chunk or block is called a token. Tokenization is the most basic step for Natural Language Processing.Itisimportantbecausewecanidentifydifferent kindsofwordsinatext.itwillhelpinfurtherprocessingthe texttoanalyzethemeaningofthetext.Furtherprocessingof tokenscanleadtomanyNaturalLanguageapplicationssuch assentimentalanalysis,removingstopwordsetc.
The set of commonly used words in a text of any given languageiscalledstopwords.Stopwordsindataminingand textfilteringareusedtoremovecommonoccurringwordsto focusonimportantorspecialwords.Someofthestopwords inEnglishare:-the,is,are,if,canetc.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072
Stemming is a form of data pre-processing in which an inflicted word or derived word is filtered back to its base word.Thebasewordisalsoknownasthe"stemword"thus derivingthewordStemming.Stemmingisimportantindata processingandanalysisbecausesometimesmanyvariations of the stem words may be present in a text file including suffixesandprefixesbutthemeaningofthewordisthesame in every context [19]. It would be a waste of processing powerandtimetoconsidereachwordwiththesamestem asaseparateentity.
WecanuseNLTK(NLTKstandsfornaturallanguagetoolkit isapythonpackageusedfornaturallanguageprocessing) for tokenizing the text as per the part of speech that they belong to. This type of tokenizing can hugely help the machinetounderstandnotonlytheliteralmeaningofthe textbutalsothetrueintendedmeaningofthetext.
Sentimental analysis is a process in which we can deduce howthetextisbeenpresentedandwhatsentimentsthetext shows.Forcriminallegaltext,thesystemcandeducewhich category the case belongs based on the sentiments of the legal text.Analysisofthesentimentscouldfurtherhelp in the grouping of the case with other cases with the same sentiments.
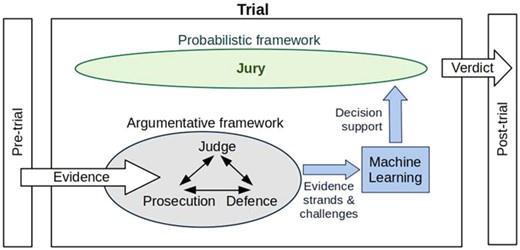
[4]InFigure3MachineLearningisusedasasupportsystem for the jury. The prosecution and defence and judge are givenasanArgumentframeworkthatwillbeusedasinput fortheMachinelearningmodelaswellasbeacriticalpartof jurydecision-making.
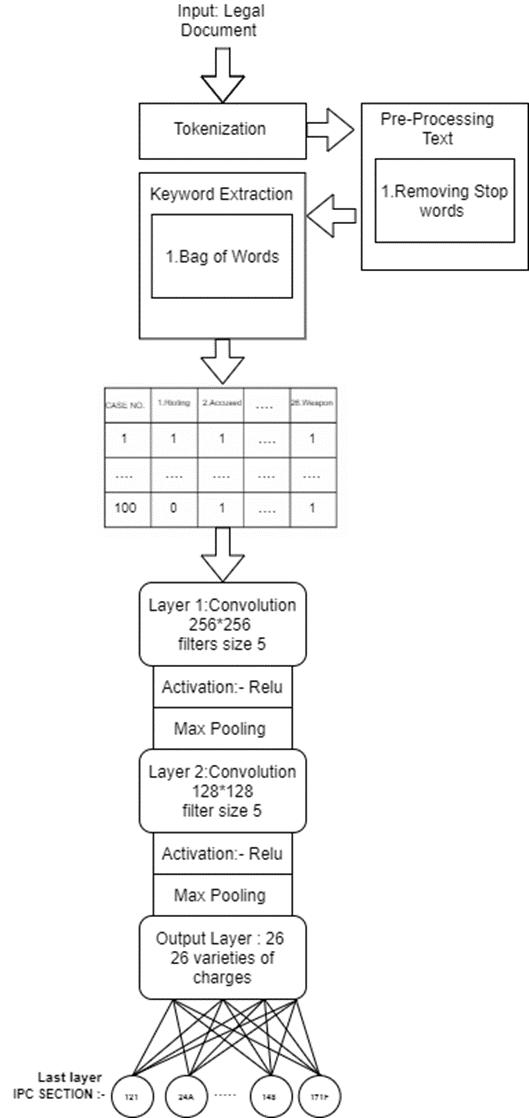
[7] The following model uses CNN for the classification of law tex. This model uses the K-fold cross-validation technique. K=4 then it means that the model will perform trainingandtesting4times.75%ofthedatacanbetakenas atrainingsetand25%ofthedatacanbetakenasatestset. The last layer includes the IPC section into which the law casesareclassified.Theaccuracyofthemodelis85%.
KNNcanbeusedasacrimepredictiontoolthatcanhelplaw enforcement. The prediction accuracy is significantly increased.[17]ThereisamodelthatusestheKNNsystemto traversethroughthecrimedatatofinddifferentreasonsthat led to crime. Mean Absolute Error and Root Mean Square Error are used to measure the errors in the set of predictions.Forthetrainingdataset,80%ofthedataisused andfortheTestdataset,20%ofthedataisused.
Figure 3.MachineLearningSupportModelforthe generationofVerdict.Imageref.[4]
Figure 4.CNNmodelwithNLPextractionand Classificationoftext.ImageRef.[7]
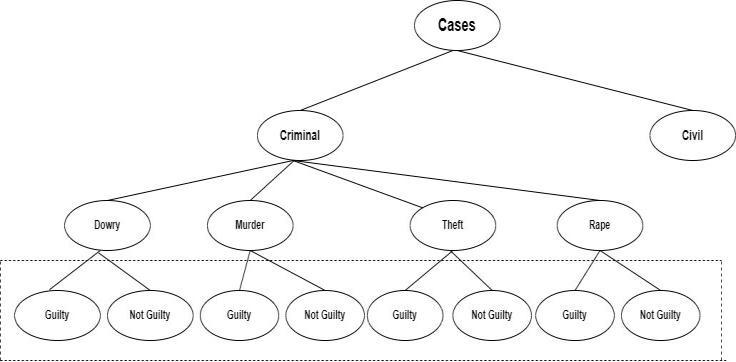
Decisiontreecanbeusedto findoutthe"guilty" and"not guilty"statusofsimilarkindsofcaseswhichcanbeusedasa winning percentage calculator, better referencing, finding out missing points in those cases etc. Figure 5. Shows the classification of a court case into different groups and in thosegroupsfindingouttheverdictasguiltyornotguilty.
[11]Furtherderivationofthedecisiontreewillhelpbuildan
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072
ontology-basedintelligentQuestionAnsweringmodel,oneof itsusecasescanbeonlinelearningwheretheansweringcan be made more intelligent by using semantic query processing.
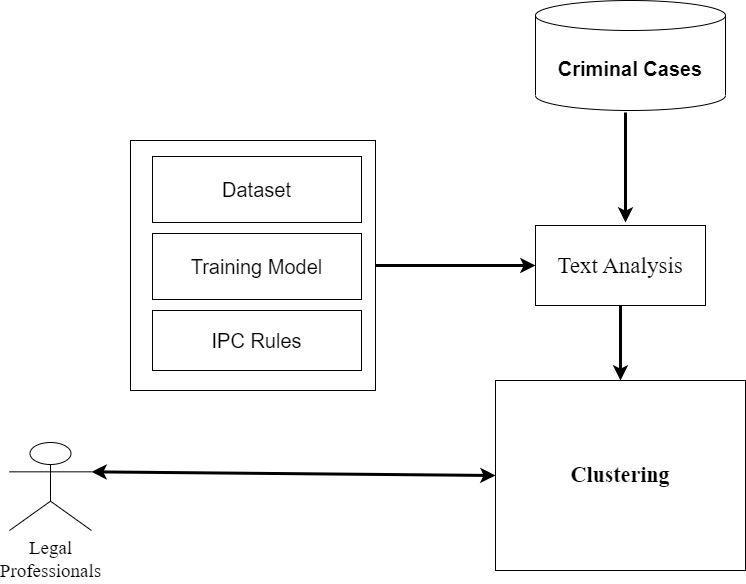
Clustering legal judgements could help us to identify the different clusters of judgements that could be used as the base for similar kinds of cases. Due to the high volume of judgements present in the Indian Judicial System with SupremeCourt'sJudgementhas
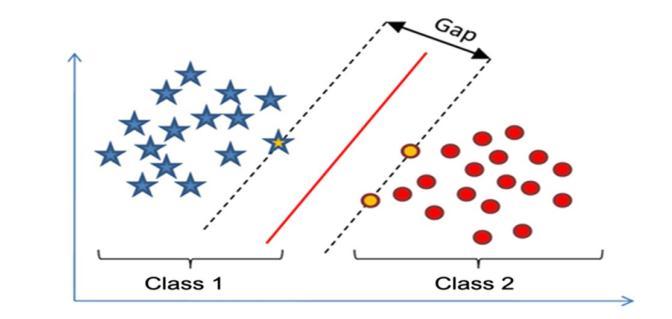
[5]Fortheclusteringofdata,theremaycomeasituationin whichitishardtoidentifythegrouptowhichtheparticular informationbelongs.Forthatpurpose,wehavetoconsider thegapintheclusters.Thedatapointthatcomesbetween thegaplinesisthedatathathavetobeconsideredagainto findouttowhatgroupitbelongs.InFigure6.Wecanseethe gapidentifywhatvaluescanbeidentifiedasdogsandcats andwhatvaluescant'bedecided.
[11]ThereisaChineselegaljudgementpredictionsystem thatincludesphysiological featuresandthedescription of facts to predict the judgements. Yinglong Ma, Peng Zhang and Jiangang Ma have proposed a system that uses ontologically driven knowledge blocks to summarize and compute documents. The proposed system uses a KNNbasedapproachfordocumentclassification.Figure7isthe IllustrationoftheChineselegaljudgementpredictionsystem thatisbeenmodifiedtobeusedintheIndianjudicialsystem.
Legal Assistance is the need of the hour. Research and developmentaregoingoninthisfieldtomakeanautomated system.TheresearchmostlyfocusesonNatural Language ProcessingfortextanalysisandDeeplearningtechniquesfor clustering of text into different groups. AI and Machine Learningmodelshaveproventobeusefulinpreparationof case studies as well as providing assistance to decision makerssuchasthejury[4].
Therearemanymodelswhicharecurrentlyattheresearch stageandwillsoonbeappliedinrealworldapplications.
The current development mostly focuses on legal text segmentationforfurtheranalysis.CNNandKNNmodelsare usedforclusteringcasesintogroups[7][17]andDecision Tree is used for classifying the groups to which a case belongs[11].Fewsuccessfulmodelsworkattheefficiencyof 75%to85%.
[1] Masha Medvedeva, Michel Vols and Martijn Wieling." Using machine learning to predict decisions of the European Court of Human Rights". Published on Springer on 26 June 2019 open access, Creative Commons Attribution 4.0 International License. link.springer.com/article/10.1007/s10506-019-09255y
[2] SandeepBhupatiraju,DanielL,ChenandShareenJoshi." The Promise of Machine Learning for the Courts of India".ThePromiseofMachineLearningfortheCourts ofIndia.NationalLawSchoolofIndiaReview,2021,33 (2),pp.462-474.⟨hal-03629734⟩
[3] JonathanBrettCrawleyandGerhardWagner."Desktop Text Mining for Law Enforcement".2010 IEEE
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12| Dec 2022 www.irjet.net p-ISSN: 2395-0072
International Conference on Intelligence and Security Informatics.10.1109/ISI.2010.548476.
[4] JaneMitchell,SimonMitchellandCliffMitchell."Machine learningfordeterminingaccurateoutcomesincriminal trials". Law, Probability and Risk, Volume 19, Issue 1, March 2020, Pages 43–65, https://doi.org/10.1093/lpr/mgaa003
[5] Riya Sil and Abhishek Roy. "A Novel Approach on ArgumentbasedLegalPredictionModelusingMachine Learning".ProceedingsoftheInternationalConference on Smart Electronics and Communication (ICOSEC 2020).10.1109/ICOSEC49089.2020
[6] HuseyinUmutcanAy,AlimeAysuOnerandTolgaKaya. "AMachineLearning- Based Decision SupportSystem Design for Restraining Orders in Turkey".2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC). 10.1109/COMPSAC51774.2021.00226
[7] V Gokul Pillai and Lekshmi R Chandran. "Verdict Prediction for Indian Courts Using Bag of Words and Convolutional Neural Network". Proceedings of the ThirdInternationalConferenceonSmartSystemsand Inventive Technology (ICSSIT 2020). 10.1109/ICSSIT48917.2020.9214278
[8] HuiWang,TiekeHe,ZhipengZou,SiyuanShenandYu Li". Using Case Facts to Predict Accusation Based on Deep Learning".2019 IEEE 19th International ConferenceonSoftwareQuality,ReliabilityandSecurity Companion(QRS-C).10.1109/QRS-C.2019.00038
[9] ] Haitham Hmoud Alshibly and Mohammad atwah Alma'aitah. "Artificial Intelligence in Law Enforcement". International Journal of Advanced Information Technology (IJAIT) Vol. 4, No. 4, August 2014. 10.1109/5254.653229
[10] Kevin D, Ashley." Artificial Intelligence and Legal Analytics(NewToolsforLawPracticeintheDigitalAge) Machine Learning with Legal Texts". University of Florida,Book-ArtificialIntelligenceandLegalAnalytics (NewToolsforLawPracticeintheDigitalAge)Machine LearningwithLegalTexts
[11] NishantJainandGauravGoel."AnApproachtoGetLegal Assistance Using Artificial Intelligence". 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO) Amity University, Noida, India. June4-5,2020.10.1109/ICRITO48877.2020.9198029
[12] MarianaY.Noguti,EduardoVellasques,LuizS.Oliveira. "LegalDocumentClassification:AnApplicationtoLaw Area Prediction of Petitions to Public Prosecution
Service".2020InternationalJointConferenceonNeural Networks(IJCNN).10.1109/IJCNN48605.2020.9207211
[13] HemlataSharma,Aakanksha."ArtificialIntelligenceand Law: An Effective and Efficient Instrument".2021 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO). 10.1109/ICRITO51393.2021.9596503
[14] VishuMadaan,SubrathoKumarDas,PrateekAgrawal, CharuGuptaandDhruvGoel."FusionofMLmodelsto Identify Sexual Harassment Cases".2021International Conference on Computing Sciences (ICCS). 10.1109/ICCS54944.2021.00058'
[15] Flora Amato, Antonino Mazzeo, Antonio Penta and AntonioPicariello."UsingNLPandOntologiesforNotary Document Management Systems".2008 19th International Workshop on Database and Expert SystemsApplications.10.1109/DEXA.2008.86
[16] SuncanaRoksandic,NikolaProtrkaandMarcEngelhart. "TrustworthyArtificialIntelligenceanditsusebyLaw Enforcement Authorities: where do we stand?" 2022 45thJubileeInternationalConventiononInformation, Communication and Electronic Technology (MIPRO). 10.23919/MIPRO55190.2022.9803606
[17] Akash Kumar, Aniket Verma, Gandhali Shinde, Yash Sukhdeve and Nidhi Lal. "Crime Prediction Using KNearest Neighboring Algorithm".2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE). 10.1109/icETITE47903.2020.155
[18] Saqueeb Abdullah, Farah Idid Nibir, Suraiya Salam, Akash Dey, Md Ashraful Alam and Md Tanzim Reza. "Intelligent Crime Investigation Assistance Using Machine Learning Classifiers on Crime and Victim Information".2020 23rd International Conference on Computer and Information Technology (ICCIT). 10.1109/ICCIT51783.2020.9392668
[19] Marijn Schraagen, Floris Bex. "Extraction of Semantic Relations in Noisy User-Generated Law Enforcement Data".2019 IEEE 13th International Conference on Semantic Computing (ICSC). 10.1109/ICOSC.2019.8665497
[20] Jishitha Kuppala, K. Kalyana Srinivas, P. Anudeep, R. SravanthKumarandP.AHarshaVardhini."Benefitsof Artificial Intelligence in the Legal System and Law Enforcement".2022InternationalMobileandEmbedded Technology Conference (MECON). 10.1109/MECON53876.2022.9752352
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page515