International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Rucha Jayantkumar Nikam1 , Vishakha Nitin Salunkhe2 , Asst.prof.S.S.Jadhav3
1stRucha Jayvantkumar Nikam, MCA YTC, Satara 2ndVishakha Nitin Salunkhe, MCA YTC Satara 3rdProf.S.S. Jadhav Dept,of MCA Yashoda Technical Campus, Satara-415003 ***
Abstract Inrecentyears,duetothetremendousgrowthof information,textclassificationbecomesaneedforhumans. In this project the data is to be classified into the various groupsaspertheexistingcontent.Thiscanbedonebythe trainingdatatothemachine.Asetoffull-textdocumentsis used to train the machine. This paper illustrates the classificationprocessbyusingautomatictextclassification. We have vectorized the training data using a count vectorizer. Then the TF-IDF (Term Frequency-Inverse Document Frequency) is used for the normalizing data. FinallytheStochasticGradientDescentMachinealgorithmis usedtoclassifythedata.
Keywords - component; Classification, Word2Vec conversion, TF-IDF information retrieval, text classifier
The machine learning technology is now playing an importantroleintheresearchanddevelopmentsector.Now aday’smanypeoplehavetheirbusyscheduleintheirdayto daylife.Duetothisitisdifficulttomanagetimeforthem. Machine learning will help them to reduce the time. This paperillustratesasystemwhichisproposedtosavetheuser timeandtheirtroubling.In thispapertheclassification of newsdatatakesplace.Asthenewsspreadinawiderange andithasagreatinfluenceonoursociety[9].Thereforethe classificationandprocessingofnewsbecomeanimportant factor. This system consists of the following processes: preprocessing, vectorization, normalization, and classification [1]. Previously the Chinese text has been classifiedbuttheclassificationoftheChinesetextisdifferent thantheEnglishtextclassification[4].Thispapersuggests theproperalgorithmoftextclassification.Itcanalsostate that the accuracy score of text classification in different algorithms.Theseaccuracyscoreswillbecalculatedbyusing mean functions in the python and different libraries of python.
TheM.Ikonomakis,Kotisiantis,TampakiasS.Vsuggestedthe textclassificationprocessusingmachinelearningalgorithms and gives an overview of all algorithms which can be preferable to implement text classification. Text classification plays an important role in information extraction, summarization, text retrieval, and question-
answering[1].MitaK.Dalal,MukeshA.Zaverisuggestedthat automatically classification of sports blog data, to the appropriate category of the sport by steps like preprocessing,featureextractionandNaïveBayesclassification [2].Cai-Zhi Liu, Yan-Xiu Sheng, Zhi-Qiang Wei, YongQuan Yang suggested a vector representation of feature words basedonthedeeplearningtoolWord2vec,andtheweightof the feature words is calculated by the improved TF-IDF algorithm. By multiplying the weight of the word and the word vector, the vector representation of the word is realized and finally the vector representation by accumulatingallthewordvector[3].FangMiao,PuZhang, Libiao Jin comparison of 3 different machine learning algorithmsusedfor textclassification. KnearestNeighbor, Naïve Bayes and Support Vector Machine, among the algorithmSVMismorecompatiblewiththebiggerdataset and smaller datasets as compared to K-nearest and Naïve Bayes[4].
Thissystemprovidesthefacilitiestouserssuchastosave theirtimebyusingautomatictextclassification.Thispaper suggests a supervised machine learning algorithm. This systemwilltrainthemachinewhichcontains20Lnewsdata which is in the tabular form. This training data holds the newsanditscategoriesitself.Firstlythemachinewillextract thefeaturesfromthetrainingdata,tokenizeitthenextracted data will be arranged in vector format by using count vectorizer,whichconvertstextdocumentsintotokens[2]. This count matrix is given to the TF or TF-IDF vectorizer (Term Frequency & Term Frequency Inverse Term Frequency).Thisvectorizertransformsacountmatrixtoa normalizedTForTF-IDFrepresentation.Thisisacomplete processoftrainingthemachine.Aftersuccessfulcompletion of the training, the machine will give the testing data to measuretheperformanceortocheckthemachineworking, whetherthemachineisbeentrainedaccuratelyornot.The accuracy ratio totally depends on the number of training data. As much bigger the training data that accurate the result might be given by the trained machine [6].After successfulcompletionofthetrainingofthemachine,testing dataispassedtothemachine.Thistestingdatawillconsist of news as well as the type or category of the news. This testingdatawillalsobepresentinthetabularformati.e.it canbein.csvfile.Wewillpassthetestingdatainthe.csvfile whichcanbeknownasacomma-separatedfile.Thisconsist
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
of only the data which will be passed to the machine for categorizingpurposeonly.Thisfileispassedtothepipeline in which the count vectorizer, TF-IDF vectorizer and SGD classifierwillworkparalleltoeachother.Incountvectorizer andTF-IDFthesameoperationwillbeperformed[3].This whole pipeline will cover the operations like tokenizing, creatingvectorbyusingthecountvectorizer,normalizethis vectorusingTF-IDFtransformer.Thenthisnormalizeddata is taken by the SGD Classifier. SGD Classifier is a linear classifier(SVM,logisticregression,)withSGDtraining[10].
The Automatic text classification uses different types of methods. This can include various phases of classification [5]. The phases mainly consist of preprocessing, vectorization,normalizationandclassification.Fig.(I)shows howthetextclassificationtakesplacebyusingthetraining and testing data. The training and testing data should be pipelinedtoformtheclassificationresult.Thistrainingset contains 20 Lac news. Which are stored in a CSV (Comma Separated Values) file. The training set consists of labels. These data is in a structured form because supervised machinelearningdoesn’tallowunstructureddata.

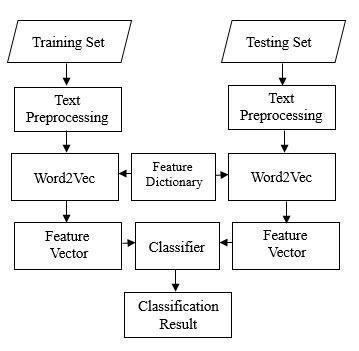
Insupervisedmachinelearning,thedataistobeextracted from the training dataset which is in the labeled form. A supervisedlearningalgorithmanalyzesthetrainingdataset and produces a conclude function which can be used for mapping a new example. Supervised text classification meansthatyouhaveasetofexampleswhereweknowthat thecorrectanswer.forexampleifwehavesetofflowerand colordatalike,‘Rose’,’Tulip’,’Sun-flower’]belongstoflower categoryand[‘Red’,’Black’,’Blue’]belongstoacolorcategory.
The text pre-processing is said to be a phase in which the dataispre-processedinsuchawaythatitispredictableto themachine.Thefirststepofpreprocessingislowercasing and stop-ward removal [8]. This pre-processing is very importantinnaturallanguageprocessing.
The next is the removal of punctuations and stemming. Stemming means to remove the stem from the word. The pre-processingalsocalledthecleaningofthetextdocument. Thecleaningofallthedocumentswilltakeplacehere.The pre-processingofatextdocumentisshowninthefollowing table:E.g.thisisatextclassification!!!
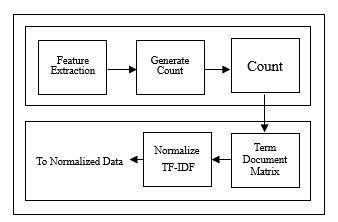
Thevectorizationistheprocessofmappingthewordsfrom thevocabulary.Thiscanthenconvertintothevectorform. These vectors can be used for finding semantics and to predicttheword.Forthisvectorization,acountvectorizeris used.Thiscountvectorizerismainlyusedinthebuildingof the vocabulary of the known datasets. By using count vectorizer raw data can be converted into the vector representation i.e. into the n-grams. Finally n number samples and n number of features will be displayed. The followingFigureshowstheprocessofvectorization.
Thenormalizationistheprocessofreducingtheweightof thetextsothatitbecomeseasytoclassifythetext.TheTFIDF(TermFrequency-InverseDocumentFrequency)isused
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
for the normalization process. The TF-IDF is said to be another way of representing text [3]. This TF-IDF can be calculatedbyusingthefollowingformulas:

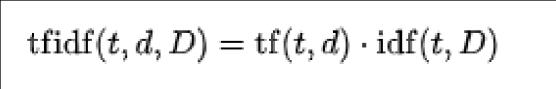
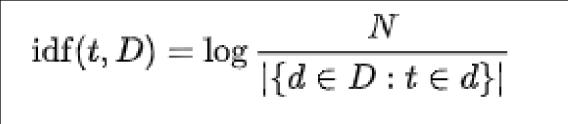
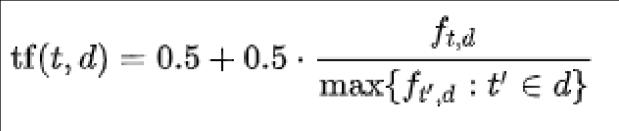
TF(TermFrequency)-
Where, TF(t,d):Termfrequencyinadocument.ft,d:Rawcount IDF(InverseDocumentFrequency)-
BasicallyTF-IDF isusedto transformthecountvectorizer intothenormalizeddata[3].TheTF-IDFcanvectorizethe documentuntilitfitsintothenormalizedform.TheTFisthe ternfrequencywhichcanreflecttheinternalfeatureofthe textdocumentandshowsinto0or1form.IDFistheinverse documentfrequency.ItistheinverseoftheTF.TheIDF is usedforthedistributionoffeaturesinthetextdocument.So that it shows the result in the n number of samples and n numberoffeatures.TF-IDFisanalgorithmthatisveryeasy and simple to learn. Therefore TF-IDF is suitable for the normalization.
Where, TF-IDF(Term Frequency-Inverse Document Frequency)-
TherearevariousclassificationalgorithmstherebuttheSGD (Stochastic Gradient Descent) is the most preferable algorithminthemachinealgorithm.TheSGDisbasedonthe gradient descent algorithm which is used to improve the speed. This can works on the iterations so that it is also calledaniterativemethod[10].TheSGDcanselectthedata points from a large number of datasets and calculates the gradient. Hence the speed is improved. The evaluation metricsofthedifferentmodelsareasfollows:
III.
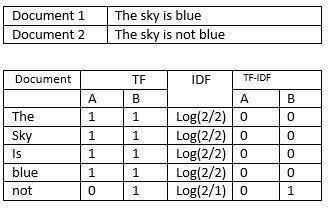
TheTF-IDFoffollowingdocumentisasfollows:
TheabovetableshowshowTF-IDFiscalculated.
TABLE II. TF IDF C
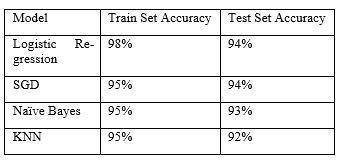
From the above evaluation it is cleared that the logistic regressionhashightrainingsetaccuracybuthaslowtesting setaccuracy[7].TheSGDhasthehighesttestsetsaccuracy and is near to training set accuracy. Others can’t fit in the accuracy matrics. So the SGD is the best for the text classification.
Fromthetable of evaluationmatricesi.e. TABLE(III),itis clearedthatstochasticgradientdescentisthebestalgorithm for the text classification. The experimental data which is usedforthetextclassificationistherawdata.Thisrawdata isthenpreprocessedandvectorizedbyusingvectorization algorithms.
FirsttheNaïveBayesalgorithmisusedfortheclassification butlateritisidentifiedthatthisalgorithmcantaketoomuch timeanditgiveslessaccuracythanthestochasticgradient descent.TheNaïveBayesclassifierisnotefficientforalarge
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
numberofdatasets.ThentheSGDalgorithmisusedforthe classification.Withthehelpofagradientdescentalgorithm, thelinearregressionproblemissolved.Gradientdescentis theiterativemethodthatcanbeusedtoincreasethespeed. Thisgradientdescentalgorithmisbasedontheslopeandthe gradient.
Thisalgorithmcanbeworkedinthefollowingsteps:
1. Computethegradientfunctionbyfindingtheslope oftheobjectivewithrespecttothefeatureset.
2. Takeanyrandominitialvaluefortheparameter(e.g. differentiate‘y’withrespectto‘x’.Iftherearemore features then take a partial derivative of ‘y’ with respecttoallfeatures).
3. By plugging the parameter update the gradient function.
4. Then calculate the step size for every feature. The stepsizeistheproductofgradientandlearningrate
5. Then calculate the new parameter and it is the differencebetweenoldparameterandthestepsize.
6. Finally repeat the steps 3-5 until the gradient becomesalmost0.
TheSGDcanrandomlypicktheonedatapointfromthesetof whole data so that computations are enormously reduced [10].
Theabovegraphclassifiesthecategoriesofnews.Thiscan be classified by using the SGD classifier and the graph is plottedbyusingthemarplotslibrary. Themarplotsarethe pythonlibrarywhichisusedinthepythonforplottinggraph. In testing data, there are several number of news will be passedinwhichthemachinelearnsthisdatawiththehelpof a training set and it will also identify which news is from whichcategory.Themachineunderstandsitandshowsthe countsofcategories.Soitcanbeidentifiedthatnewscanbe classifiedinadifferentcategory.
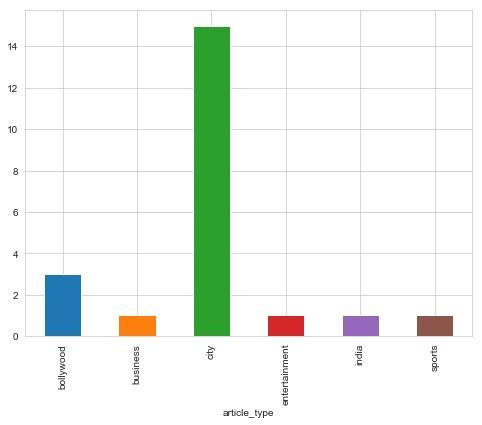
Thispapersuggeststhattherearevariousalgorithmsused forthetextclassification.Butsomeofthemtakemoretime toclassify;somecanworkonsmalldatasetsetc.TheSGDis thealgorithmsthatovercomeallthesepoints.TheStochastic GradientDescentissaidtobeaspeedyalgorithmbecauseit canworkwithslopeandgradient[10].Withthehelpofthe SGDalgorithmthetextclassificationsystemisdesigned.This systemconstructsamodulethatpredictstheaccurateratio ofthetestingdatawhichconsistsofdifferentnewsdata.The predictedratioisbetween0to1.Thisratiowillbeameans ofallthattestingdatai.e.news.Andfinallythenewsdatais classifiedwhichisshownbythegraph.Thegraphdenotes thespecificcategoryofthat news.Itcanbeconcludedthat SGDisthemostpreferablealgorithminthetextclassification fromthedifferentalgorithmslikenaïveBayes,KNN,logistic regressionetc.,sothesystemcanclassifythetextwithhigh accuracyandmorespeed.
[1] M.Ikonomakis,S.Kotisiantis,V.Tampakias(2005)“Text ClassificationUsingMachineLearningTechniques”
[2] MitaK.Dalal,MukeshA.Zaveri(2012)“Automatictext classificationofsportsblogdata”
[3] Cai-zhi Liu, Yan-xiu Sheng, Zhi-qiang Wei, YongQuan Yang(2018) “Research of Text Classification Based on ImprovedTF-IDFAlgorithm” .
[4] FangMiao,PuZhang,LibiaoJin(2018) “ChineseNews Text Classification Based on Machine learning algorithm”.
[5] IFIP conference paper (2006) on “comparison of SVM and some older classification algorithms in text classificationtasks”
Afterusingtheclassifierthetestingdataandtrainingdata arepipelinedforthesimultaneousexecution.Andtheresult oftheclassificationisasfollows:
[6] Zhenzhong Li, Wenqian Shang, Menghan Yan (2016)”NewsTextclassificationmodel basedontopic model”
[7] IOP Conference series (2018) “Comparison of Naïve Bayes and K Nearest Neighbour Methods to predict divorceissues”
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
[8] Mita K. Dalal, Mukesh A. Zaveri (2013) “Automatic Classificationofunstructuredblogtext”.
[9] Wu Da-Sheng, Yu Qin-fen, Liu Li-juan (2009) “An Efficient Text Classification Algorithm in ECommerce Application” .
[10] Sebastian Ruder (2017) “An overview of gradient DescentOptimizationalgorithms”
1. Then calculate the new parameter and it is the differencebetweenoldparameterandthestepsize.
2. Finally repeat the steps 3-5 until the gradient becomesalmost0.
TheSGDcanrandomlypicktheonedatapointfromthe set of whole data so that computations are enormously reduced[10].
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |