1,2, 3,4
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072

1,2, 3,4
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
Rakshitha HS1 , Neha K T2 , Rakshitha S3 , Kavitha M4, Sonia Das 5
Abstract - With the development of communication technologies and social media, the fake news phenomena is expanding quickly. A new field of research that is receiving a lot of attention is fake news detection. Due to the restricted resources, including datasets, processing, and analysis methods, it does, nevertheless, confront some difficulties.
In this work, we provide a machine learning-based approach for detecting fake news. As a feature extraction strategy, we employed term frequency-inverse document frequency (TF-IDF) of a collection of words and n-grams, and Support Vector Machine (SVM) as a classifier. We also suggest a dataset of real and fraudulent news for the suggested system's training. Results obtained demonstrate the system's effectiveness.
Key Words: Fake news, Social media, Web Mining, Machine Learning, Support Vector Machine, TF-IDF.
The Fake News epidemic has grown significantly over the past ten years, helped along by social media. Various motives can be used to broadcast this false information. Some are created solely to enhance the amount of clicks and site visitors. Others seek to sway public opinion regarding political or financial market decisions. For instance, through affecting the online reputation of businesses and institutions. Social media fake news about health poses a threat to overall health. The COVID-19 outbreakhadbeenaccompaniedbyamassive"infodemic," or an abundance of information, some of which was accurate and some of which was not, which made it challenging for people to find trustworthy sources and trustworthy information when they needed it, the WHO warnedinFebruary2020.
In this study, we introduce a novel approach and technology for identifying fake news that includes: • Text pretreatment, which entails steamingand textanalysis by removingstopwordsandunusualcharacters.
• Encoding of the text: utilising bag of words and N-gram thenTF-IDF.
• Characteristic extraction: This enables the accurate identification of bogus information. The author, date, and feelingconveyedbythetextareusedasfeaturesofanews item.
Support vector machine is a technique for supervised machine learning that enables the classification of new data.
The main goal is to identify bogus news, which is a straightforwardsolutiontoatraditionaltextclassification problem. It is necessary to create a system that can distinguish between "genuine" and "false" news. Children'sabilitytothink criticallywill improve,andthey will be more willing to work to stop the spread of false information. The participants will receive knowledge of, for instance, how to effectively communicate in an online forum.
Python offers stability, versatility, and a wide range of tools, all of which are necessary for a machine learning project.Pythonenablesdeveloperstoworkefficientlyand with confidence throughout the whole product development process, from design through deployment andmaintenance.
Python is a simple and trustworthy programming language that enables programmers to create reliable, readablesoftware.
Python was primarily employed as the programming language for projects involving many developments and cooperativeimplementation.Prototypesarecreatedmore quickly because testing and the challenging machine learningtaskmaybecompletedswiftly.
The incredible libraries and frameworks of Python are anotheranotherreasontomasteritformachinelearning.
The modern world has been profoundly affected by machinelearning.
Newapplicationsarealwaysbeingdevelopedintheworld we live in. Python is being used by developers for every phaseofproblemsolving.
Python practitionersassert thatthey believe thelanguage iswellsuitedforAIandmachinelearning.
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
According to study [2], fake news has been surfacing frequently and widely in the internet world lately due to the rising development of online social networks for variouseconomicandpoliticalgoals.Usersofonlinesocial networks can easily become infected by these online fake news with deceptive language, and this has already had a significant impact on offline culture. Finding bogus news quickly is a crucial step in raising the credibility of information in online social networks. This study seeks to investigate the theories, approaches, and algorithms for identifying fake news sources, authors, and subjects from online social networks and assessing the performance in thisregard.
This essay tackles the difficulties caused by the unknowable traits of fake news and the varied relationshipsbetweennewssources,authors,andsubjects. Inthisresearch,theFAKEDETECTORautomatic fakenews credibilityinferencemodel isintroduced.FAKEDETECTOR creates a deep diffusive network model based on a set of explicit and latent properties collected from the textual material to simultaneously learn the representations of newsarticles,producers,andsubjects.
A real-world dataset of false news has been used in extensive trials to compare FAKEDETECTOR with a numberofstate-of-the-artalgorithms,andtheresultshave shownthatthesuggestedmodeliseffective.
According to study [5], there are several technologies available to identify bogus news thatcirculates by looking atthelinguisticchoicesthatappearinheadlinesand(Chen, Conroy, and Rubin 2015b) Various intense linguistic structures. According to Atodiresei, Tnăselea, and Iftene (2018),anothertechnologydesignedtoidentifyfakenews on Twitter contains a component known as the Twitter Crawler that gathers and archives tweets in a very informationalmanner.WhenaTwitteruserwantstocheck the veracity of the news they have found, they copy the URL into this programme, where it is evaluated for false news identification. The NER (Named Entity Recognition) approach,whichisbasedontheassociatedegreerule,was developed(Atodiresei,Tănăselea,andIftene2018).
According to study[8] ,states that research on false news detection is still in its early stages because this subject is relatively new, at least in terms of the interest it has generated in society. The following is a review of some of the published works. Fake news can generally be divided into three categories. Fake news, or news that is wholly madeupbytheauthorsofthepieces,isthe firstcategory. Thesecondcategoryisphoneysatirenews,whichismade primarilywith the intention ofmakingreaderslaugh.The third category consists of badly written news items that containsomegenuinenewsbutarenottotallyaccurate.
In essence, it refers to news that fabricates entire stories while quoting political people, for instance. This type of newsistypicallyintendedtoadvanceaparticulargoalora prejudicedopinion[3].
Accordingtostudy[10],HadeerAhmedetal.[4]compare two distinct feature extraction strategies and six different classificationtechniquestodevelopafalsenewsdetection model using n-gram analysis and machine learning techniques.Theresultsofthetestsconductedindicatethat the so-called features extraction method yields the best results (TF-IDF). They employed the 92% accurate Linear SupportVectorMachine(LSVM)classifier.
TheLSVMusedinthismodelisrestrictedtohandlingonly thesituationwheretwoclassesarelinearlyseparated.
A naive Bayesian classifier is used by Mykhailo Granik et al. [7] to offer a straightforward method for detecting bogus news. On a set of data taken from Facebook news posts, this strategy is tested. They assert that they can reach a 74% accuracy rate. This model's rate is good but not the greatest because many other research have used differentclassifierstoreachbetterrates.
Thissurvey,accordingtostudy[11],isanevaluationofthe manymethodsorsystemsthathavebeenemployedinthe past to identify fake news. This paper's main goal is to observe and identify the most effective and objective solutions to the given situation. Additionally, the survey below examines each approach used in the literatures mentioned (see References). Fake news has puzzling root reasonsandiswidelyspread.
Numerous strategies can and have been adopted by both people and organisations [9]. However, our survey shows that(1)factchecking,(2)rumouridentification,(3)stance detection, and (4) sentiment analysis are given prominenceregardingthesemethodologies.
Thesolutionwesuggestbuildsadecisionmodel based on thesupportvectormachine methodusinga newsdataset. The model is then used to categorise recent news as authenticorfraudulent.
The suggested system accepts a dataset of comments and their associated data, such as date, source, and author, as input.Itthenconvertsthemintoadatasetoffeaturesthat may be utilised for learning. Preprocessing is the name given to the transformation, which includes a number of steps like cleaning, filtering, and encoding. The preprocessed dataset is split into two sections: a training section and a testing section. The training module creates a decision model that can be used with the test dataset
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
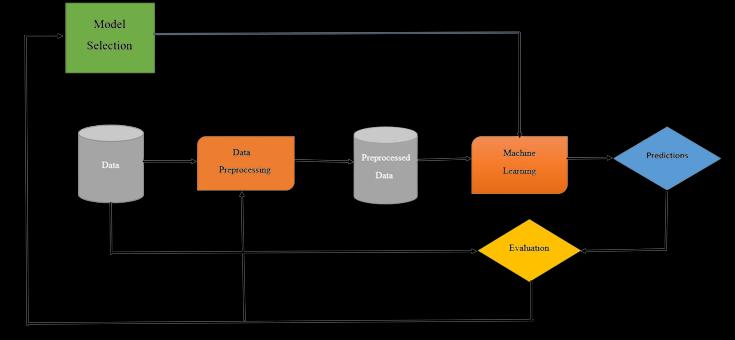
using the training dataset and support vector machine technique. The training process is complete after the modelhasbeenaccepted(i.e.,ithasbeenabletoattainan acceptable accuracy rate). If not, the learning algorithm's settings are changed in attempt to increase accuracy. The suggestedsystem'sgenerallayoutisshowninFigure1.
negativedecisionfunctionvaluedesignatesbotha fakenewsanditsleveloffakeness.
2) Validation: We set aside some of the instances to be used as test models in order to gauge the model's ability to recognise new cases. Then, a trainingpartandatestpartarecreatedusingthe features dataset. Its value comes from preventing over-fitting,whichiswhenamodelistestedusing the same training dataset. By applying the cross validation method, the subdivision is done according to a specific sample rather than at random[12].
By adjusting or modifying the support vector machine algorithm's parameters, notably Cost, E, and the crossvalidation variation, this process seeks to increase the model'saccuracy[6].
Figure1.Theproposedfakenewsdetectionsystem architecture’s
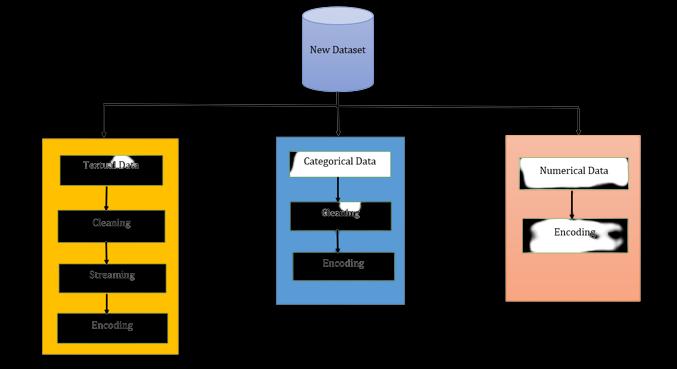
Three categories textual data, category data, and numerical data are used to classify the features of news in the news dataset. A series of processes are used to preprocesseachcategory,asshowninFigure2:
This is the system's final and most crucial stage. We may nowusethebestmodel,whichwebuiltafterachievingthe best recognition rate, to new unlabeled news in order to predict their classes wrong or true with a certain degreeofconfidence.
In an effort to identify the most effective features and methods for spotting fake news, this research provides a way for doing so using a support vector machine. We began by researching fake news, its effects, and the techniques used to identify it. Then, using a dataset of newsthathasbeenpreprocessedusing cleaningmethods, steaming,N-gramencoding, bagofwords,andTF-IDF,we created and implemented a solution that extracts a set of features that can identify fake news. Then, using our dataset of features, we applied the Support Vector Machinetechniquetocreateamodelthatwouldallowthe categorizationoffreshdata.
It combines two modules, namely the training and validationones.
1) Training: We have selected the support vector machine approach to train our model [15]. This enables the decision function value assigned to a news item to be used as a measure of the classification's degree of confidence: a positive decision function value designates both a true news and its level of truth, and vice versa; a
[1]CristinaMPulido,LauraRuiz-Eugenio,GiselaRedondoSama,and BeatrizVillarejo-Carballido. Anewapplication ofsocialimpactin socialmediaforovercomingfakenews in health. International journal of environmental research and public health,17(7):2430,2020.
[2] Detecting Fake News in Social Media Networks https://doi.org/10.1016/j.procs.2018.10.171
[3] Schow, A.: The 4 Types of ‘Fake News’. Observer (2017). http://observer.com/2017/01/ fake-news-russiahacking-clinton-loss/
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page1015
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 09 Issue: 12 | Dec 2022 www.irjet.net p-ISSN: 2395-0072
[4]HadeerAhmed,IssaTraore,andSherifSaad.Detection of online fake news using n-gram analysis and machine learning techniques. In International Conference on Intelligent,Secure,andDependableSystemsinDistributed andCloudEnvironments,pages127–138.Springer,2017
[5] Parikh, S. B., & Atrey, P. K. (2018, April). Media-Rich Fake News Detection: A Survey. In 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)(pp.436-441).IEEE
[6] Chih-Chung Chang and Chih-Jen Lin. LIBSVM – A LibraryforSupport VectorMachines,July15,2018.
[7] Mykhailo Granik and Volodymyr Mesyura. Fake news detection using naive bayes classifier. IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON),pages900–903.IEEE,2017
[8] Lemann, N.: Solving the Problem of Fake News. TheNewYorker(2017).http://www.newyorker.com/news /news-desk/solving-the-problem-of-fake-news
[9] Fatmeh Torabi Asr, Maite Taboada:“Big Data and qualitydataforFakeNewsandmisinformationdetection”, Big Data & Society, 2019, Article-14, DOI:10.1177/2053951719843310.
[10] Florian Sauvageau. Les fausses nouvelles, nouveaux visages,nouveauxdéfis.Commentdéterminerlavaleurde l’informationdanslessociétésdémocratiques?Presses de l’UniversitéLaval,2018
[11] MeichangGuo, ZhiweiXu, Limin Liu, MengjieGuo, and YujunZhang:“AnAdaptiveDeepTransfer LearningModel for Rumor Detection without Sufficient Identified Rumors”, Mathematical Problems in Engineering, 2020, articleID-7562567,DOI:10.1155/2020/7562567.
[12] Refaeilzadeh Payam, Tang Lei, and Liu Huan. Crossvalidation. Ency- clopedia of database systems,pages532–538,2009.
[13] Niall J Conroy, Victoria L Rubin, and Yimin Chen. Automatic deception detection: Methods for finding fake news. Proceedings of the Association for Information Science and Technology,52(1):1–4,2015.
[14] Florian Sauvageau. Les fausses nouvelles, nouveaux visages, nouveaux défis. Comment déterminer la valeur de l’information dans les sociétés démocratiques? Presses de l’UniversitéLaval,2018.
[15]LechevallierY. WEKA, un logiciel libre d’apprentissage et de data mining” INRIA-Rocquencourt.
[16] S. B. Parikh and P. K. Atrey, "Media-Rich Fake News Detection: A Survey," IEEE Conference on Multimedia
Information Processing and Retrieval (MIPR), Miami, FL, 2018.
[17] Dewey, C.: Facebook has repeatedly trended fake news since firing its human editors. Washington Post (2016)
[18] DSKR Vivek Singh and Rupanjal Dasgupta. Automated fake news detection using linguistic analysis andmachinelearning
[19] Florian Sauvageau. Les fausses nouvelles, nouveaux visages, nouveaux défis. Comment déterminer la valeur de l’information dans les sociétés démocratiques? Presses de l’UniversitéLaval,2018.
[20] Gerard Salton and J Michael. Mcgill. 1983. Introduction to modern information retrieval,1983.
2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal |