International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
1,2,3,4 B.Tech Student, Dept. of Information Technology, VJTI College, Mumbai, Maharashtra, India 5Associate Professor, Dept. of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra, India ***
Abstract - Mutual funds provide a higher return on investment in spite of having high risk factors as compared to other investment options. Consequently, investors are in a dilemma while choosing the right funds for investing. As a result, an efficient recommendation system along with an explanation for the same is required to aid the investors make the correct choice. In this paper we intend to review various existing models, theories and discussions stressing on mutual funds’ investments and their returns. Further, we propose a model that can give an explanation for the recommendations made by using a knowledge graph machine learning model. Also, we aim to personalize these recommendations based on the user investment propensity.
Key Words: Mutual Fund, Knowledge Graph, recommendation system, Deep Learning
Afinancialentitythatgathersthemoneyofseveralinvestors and invests them in different financial securities such as bonds, stocks and short term debt is termed as ‘Mutual Fund’. The prediction and estimation of mutual funds’ performanceisakeyingredientforinvestorsandfinancial institutionstoday,butparallellyfiguringoutthebestfunds to invest becomes challenging. In this paper, weintend to develop a machine learning model that can provide recommendationsalongwithexplanationsforthesamewith thehelpofknowledgegraphmachinelearningmodel.The proposedmodelwillconsidermultiplehiddenfactorsalong with factors such as ratio of expense, fund manager experience,pastperformanceandassetsundermanagement that influence the general performance of mutual funds’ markets.
Commonmutualfundrecommendationsystemsbasetheir resultsonmarketperformanceratherthanpersonalizingthe investment portfolio of the investors. Additionally, the recommendationsystemsdon’thaveanabilitytoprovidean explicitexplanationofwhyafundwasrecommendedtothe user.
Mutualfundsareapopularinvestmentchoiceforinvestors today.Individualinvestorsoftenlackskillstoinvestinthe market directly. They have limited ability to manage the market fluctuations. Hence, mutual funds become a straightforwardinvestmentoptionforinvestorsintendingto invest in equities and other complex asset classes. Mutual funds need to be professionally managed, should reduce risksandofferreturnsthatcanbeatinflationaswellasbe sufficient enough to provide good returns. Due to these reasons mutual funds are examined extensively for their performance.
A mutual fund scheme should be able to take care of the financial requirements of wealth creation according to an investor.Butinthepresentscenario,choosingagoodmutual fundschemehasbecomeverychallenging,justlikestocks. Therapidgrowthofmultipleschemesofmutualfundshas created a dilemma for investors. Although investment in schemes of a mutual fund is a good idea for sustainable wealthcreation,choosinga goodmutualfundhasbecome theoneofthebiggestchallengesforanordinaryinvestor.
Sincerecommendersystemsarebasedonhighqualitydata, ifwearenotabletocrunchandanalyzeitproperly,wemay notbeabletomakethemostoftherecommendationsystem. Public datasets are scarcely available for the use-case. Severalsmalldatasetshavetobecombinedtocreatealarger dataset. This, however, poses a huge challenge of data preprocessing as the format of data is different in all the databases.
Thecoldstartproblem: When werelyonuserdata,ithas severaldown-sidestoit.Whenanewuseraddsnewitemsto thecatalog,itbecomesdifficultforthealgorithmtopredict the taste and preferences of the new user leading to less accuraterecommendations.
[1] In this paper authors have used a knowledge graph–based structure to develop an explainable mutual fund recommendationsystembasedondeeplearningtechniques. Theproposedrecommendationsystembasedonknowledge
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
graph and deep personalized recommendation system exhibited a considerably high accuracy and it is easy to interpret.Theyhavealsodemonstratedtheeffectivenessof theproposedmodelforprovidingcustomizedexplanations byusingacasestudy.Theyhavenotonlygeneratedsimple explanationswiththeoriginalmodelbutalsogeneratedthe compositionofexplanationswithcustomizedratings.They have also generated special recommendations for a customer in the data set to demonstrate the ability of the proposedmodeltoproducecustomizedrecommendations.
[2] The paper proposes a method of personalized equity recommendation system based on transfer learning. This includesseveralsteps.Firstly,aportfolioiscreatedforboth equityfundsaswellastheinvestor(usingmodernportfolio theory).Secondly,a profile ofthe stock marketiscreated. Theconceptoftransferlearningisthenusedwiththisprofile in the equity market. Finally, a recommendation system whichisutilitybasediscreatedusingtheideaofprospect theory.Thisapproachisbestforinvestorsthathaveavery limited past history of investing. The output of this paper showssignificantincrementinaccuracywhencomparedto thetraditionalmethodssuchascollaborativefiltering(which is a form of similarity based recommendation system). However, overall accuracy is low(0.32), due to various factors.
[3]Thispaperfocusesonusingatime-seriesmodelnamed Prophet model instead of traditional RNN or LSTM for predictionofthefundprice. Tobeginwith,aninvestment propensity diagnostic list is prepared based on the Korea Council for Investor Education. The fund information also contains the risk level that can be matched with the investmentpropensityoftheuser.Fordeterminingthefund risk level, K-means algorithm is suggested along with an elbowmethodwith4classes(Highrisk,highreturn,highrisk lowreturnandsoon).Theprophetmodelfurtheraccurately predictsthefuturepriceofthefund.Thetrainingtimefor thismodelissignificantlylessthantraditionalMLmodels. (1.4s for Prophet model) and 2.1 seconds for LSTM with similaraccuracy.
[4]Thispaperfocusesonbuildingaportfoliorecommender systemespeciallyfornoviceand1st-timeinvestors.Network analysis is the proposed method in this paper which generates2typesofnetworksnamely1-modenetworkand 2-modenetwork.Dependingonuserpreferences,amutual fund portfolio is selected and analyzed. The credibility of externalfundsisgivenbyanexternalagency.Basedonthe2 types of graphs created after completing previous steps, individualstocksofthefundsareanalyzedusingcentralized measuresandthesestocksarerecommendedtotheuser.
[5]Inthispaper,thesystematizedmachine-learningbased approaches for Stock Market Prediction (SMP) were surveyed and explained. Different methodologies, developmentsandfuturedirectionswerestudied.Astudy forNASDAQpricepredictioncomparedthreeANNmodels
namely MLP, dynamic artificial neural network and autoregressivecontrolheteroscedasticitywhichconcluded thatmulti-linearperceptron surpassedDAN2andGARCH. The two methods used for SMP were Classification and Regression. It was also observed that SVM was the most accepted SPM technique. ANN and DNN provided high accuracyalongwithfasterpredictions.
[6] The paper it was observed that deep learning and ensemblemethodsprovidedfavorableandviablesolutions for the problem of forecasting performances of multiple mutual funds which are measured by Sharpe ratios. The monthly-basedtimeseriesdatawasformorethan600openend mutual funds was used to calculate the year-to-year Sharperatios.Higheraccuracyinforecastingfund’ssharpe ratioswasobservedwithlong-shorttermmemory(LSTMs) and gated recurrent units (GRUs) deep learning methods both trained with modern Bayesian optimization. The purpose of this paper was to address various challenges facedwhileforecastingpredictionsofvariousmutualfunds with the help of deep learning approaches with a comparison against popular traditional statistical approaches.Basedonmodelqualitytherankingorderwas Ensemble,LSTM,GRUs,ARIMA,ETSandThetarespectively.
[7] Krist Papadopoulos (2019), in his paper investigates various collaborative filtering approaches with latent variablemodelsforpredictingsparseandlargemutualfund redemptions by advisors. It tests different advisor characteristicsforapplicabilityinthecollaborativefiltering framework. The paper provides a technique for financial institutions to predict large mutual fund redemptions to prepare more effective client sales interactions with advisors. It uses models like WLR-MF (Weighted Logistic RegressionMatrixFactorization),WLS-MF(WeightedLeast SquaresMatrixFactorization)andWMF(WeightedMatrix Factorization) for prediction and concludes that WMF producedhighesttestperformanceinallmetrics.
[8]Pendaraki,BeligiannisandLappa(2016)intheirpaper discuss approaches for prediction of mutual funds’ performance and net asset value using artificial neural networks and genetic programming. They compare the forecasting results of the ANN approach with that of GP approach to predict the mutual fund performance and concludesthatANN’sresultsoutperformsthatofGP’sresults forpredictionofmutualfunds’netassetvaluewhereasGP’s results outperforms that of ANN’s results in prediction of mutualfunds’returns.Thispredictioncanfurtherbeused for our mutual fund recommendation system. The paper presentssamplingandgroupingofinputdata,ANNapproach concerning the application of multilayer perceptrons methodologyandGPapproachforprediction.
[9] This paper proposes an innovative methodology to construct a mutual fund portfolio in order to increase the profitovertimeandavoidrisks.Theproposedmethodology analyzesthehistoricaldatabasedonregressionanalysis.It
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
helpsingroupingofstockstominimizeriskandmaximize returnsusingacurvefittingtechnique.
[10] AI has made banking services more personalised. Marketing strives to provide precise financial services. Precision marketing faces scalability challenges, delayed starts, and a lack of transaction data for many clients and commodities. Deep learning was used to improve collaborativefilteringbysomeacademics.Thetypicalmatrix factorizationapproachismoreefficient,butithaslimitedthe recommendation model's capacity to account for nuanced iteminteractions.Inthisarticle,theyhavesuggestedusinga Graph DCF algorithm to make tailored suggestions for mutualfunds.Usingthesequentialperspective,wecanbuild the graph-structured network by joining the nodes representing our customers with those representing their purchasesandthecorrespondingredeemedtradeorders.By doing so, we may construct a wide variety of hidden connectionsbetweenshopperswhosharesimilartastesand preferences. Next, an aggregate function that takes into account similarities in buying patterns produces an embedding vector for each customer node. Finally, the suggested deep embedded collaborative filtering system forecastsacustomer'swillingnesstopurchaseamutualfund based on a variety of qualities and attributes of both the mutual fund and the consumer. DECF approaches outperformeddeeplearningmethodslikeDCFandNCF,as evidencedbyexperimentalresultsonareal-worlddataset from Taiwan Commercial bank. Compared to commonly used methods, the suggested GraphDCF algorithm performedbetter(byupto2.3%).
This project aims to propose an explainable mutual fund recommendation system that provides precise recommendationswithpersonalizedexplanationswherethe knowledgeofdeepneuralembeddingtechniquesalongwith thetraitsofknowledgegraphisleveragedtodesignamodel to obtain high accuracy recommendation and appropriate explanations.
Currently, the existing mutual fund recommendation systemspresentaremajorlybasedonthebestperforming mutualfundinthemarket.Thepersonalizationofthemutual fundalong withpredictingtheperformance ofthemutual fund is not considered in depth. Not considering all the factorstogetherreducestheaccuracyanddoesn’ttakeinto accounttheamountofriskaninvestorcantake.Wewould like to develop a model that takes into account all the associated factors to give better accuracy and also personalizetherecommendations.
We aim to research about the hidden factors affecting the performance of the mutual fund market and therefore explainwhyaspecificfundisrecommended.
Aftergatheringallthefactorsaffectingthefunds,thefactors will be ranked in descending order of their impact and accordinglygiveaweighttoeachfactor.
The proposed model can be developed by combining and preprocessingseveraldatabasesofmutualfunds.Amachine learningmodelrelatedtoknowledgegraphscanbeusedfor explaining why a recommendation is made. For personalizationofrecommendation,differentportfolioscan becreatedfordifferentinvestorsandforthefundsaswell. Then,bycomparingtheseportfolios,differentfundscanbe recommendedtotheuser.
Therequirementofdataisofprimaryimportanceandcanbe fulfilledbyusingvariousopensourcedatabasesaswellas scrapingdatafromcrediblesources.Weneedtodevelopa strategytostorethiscopiousamountofdataandeffectively performanalyticsonitatthesametime.Onceamodelhas beendevelopedusingthisdata,auser-friendlywebinterface needs to be developed so that the end user can use the functionalities provided with ease. The web interface will contain the profile of each user and personalized recommendations for them along with the explanation of whythefundwasrecommendedtoincreasetheuser’strust inthesystem.Forevaluatingtheprofileoftheuserandtheir investmentpropensity,aquestionnairewillbeprovidedto alltheusersduringtheregistrationprocessofthewebsite.
Sellersofafundmustgiveafundrecommendationforthe nextmonthattheendofeachandeverymonth.Theseller reliesonthefeaturesofthepreviousstatusandpredictsthe funds the customer will buy during the following month. Generally, the manager of customer relationship should respond to why a fund is recommended to a customer. Moreover, customers cannot be told that a fund is recommended for them because it has a high score in the recommendation system. Such a response may reduce customers’confidenceintheseller’sperception.Hence,the manager of customer relationship should target to give precise recommendations along with personalized explanations.Everyoneshouldbeabletoreceivecustomized recommendations based on their distinct traits and behavioralhistoryaswellascustomizedexplanationsforthe recommendations.
We will use Deep neural embedding techniques and the traits of the knowledge graph leveraged in the model to obtain a high recommendation accuracy and appropriate explanations. To obtain multi condition explanations, the training process of the model will be modified and a
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
calculationmethodwillbeaddedfortheuniquenessofthe explanations, which means that the explanation model should tend to provide those explanations that are less frequentlygenerated.Thismechanismwillshowourbelief thatthelessfrequentlytheexplanationgenerates,themore confidencethattheexplanationispersuasive.Ingeneral,the developedmodel willcompriseoftwoprocesses:utilizing the deep neural embedding of the knowledge graph and producing the reasons and other uses of related recommendations.Inthedeepneural embeddingprocess, featuresofcustomersandfundswillbeextracted.Moreover, theknowledgegraphenablesthemodeltolearnstructural details.Thesevectorswillbetrainedtomatchtheimplicit feedbackfromtheuser,theknowledgegraphcanbeusedto determine the missing relations between entities. Consequently, the system can determine the appropriate fundstoberecommended.
UI:
Weaimtocreateaninterfacewhereuserswillbeabletoget personalizedinvestment(mutualfunds)recommendations on the basis of their constraints. We will require financial capital,riskcapacityetc.asinputfromtheuser.Weaimto provide a generated explanation to the user to back our recommendation. Thus the user will be confident that the recommendationisnotjustaresultofanybiasedmodel.
Building
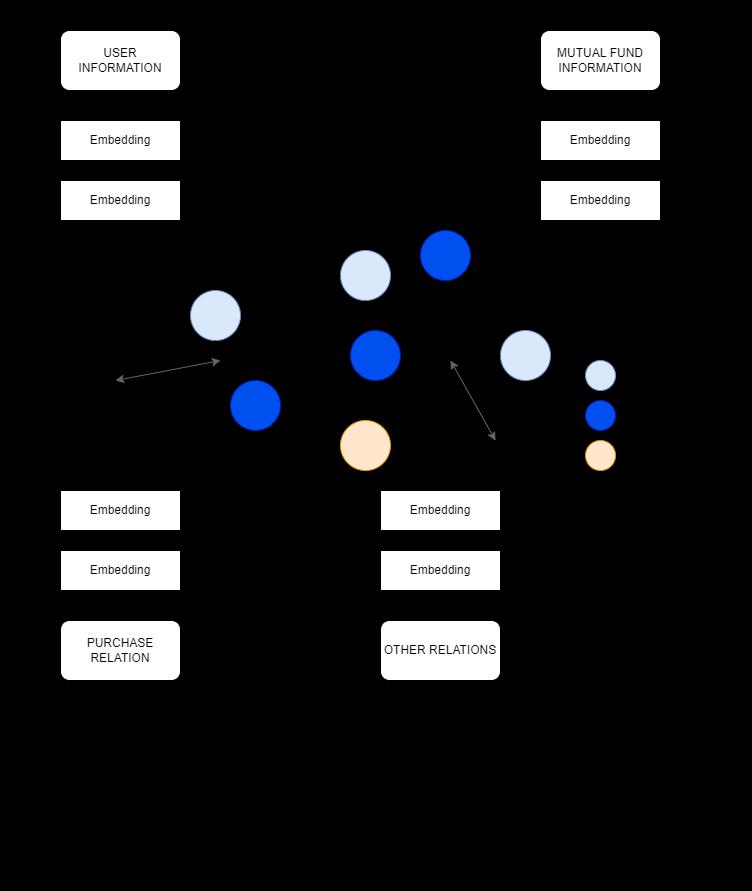
LetusdenotetheknowledgebaseasG={E,R},where E= {e1,...,e|E|}isthesetofallentitiesandR={r1,...,r|R|}isthe setofrelationsbetweenthese.The,wecanconstructS⊆E× R ×t asa setoftriplets.S= {h,r,t}, whichshowsthat the headentityhhasarelationrwiththetailentityt.Consider,S ={Joe,bought,Book1} indicatesthattheentityBook1was bought by head entity Joe. We can complete the graph by knowledgegraphembedding.Knowledgegraphcompletion hastwomaingoals:(1)topredicttherelationshipbetweena givenheadentityandtailentity{h,unknown,t} and(2)to predictthetailentitiesmostlikelytohavearelationwitha given head entity {h,r, unknown} .We will use a series of translation-basedmethods.Alltheentitiesandrelationswill beprojectedtoalow-dimensionallatentspace.Let V∈Rd, Vt∈ Rd,and Vr∈ Rddenote thelatentvectorsofthe head entity, tail entity, and relation, respectively. Translationbasedmethodsviewtherelationasatranslationfunctionto translatetheheadentitytothecorrespondingtailentity,as trans(Vh,Vr)=Vt.
All entities and relations should be projected to a unified latent space because our aim is to utilize heterogeneous information for different types of relations to explain our recommendations. Therefore, we will adopt a modified version,whichgivesusthefollowingprobabilityestimation:
P( Vt | trans (Vh , Vr)) e( Vh + Vr ). Vt (1) Σ Vt ∈ Vt e (Vh , Vr ).Vt
where trans(Vh,Vr).Vt denotesthedotproductof(Vh+Vr) andVt.BecausecomputingΣVt∈Vt e(Vh,Vr).Vt isinfeasible,we canchangeourtargetintoarankingproblemsuchthatwe would like the probability of V with relation exists with trans(Vh ,Vr ) greaterthanotherVt'.Sothatwecanignore thedenominatorsharedandfocusonimprovingthevalueof:
P( Vh ,Vr ,Vt ) = trans( Vh ,r).Vt (2)
We can then define the loss function as negative loglikelihoodasfollows:
L(S)= − Σ (Vh ,Vr ,Vt ) ∈ S log σ (trans( Vh ,Vr).Vt ) + (Vh ,Vr ,Vt ) S log(trans( Vh ,Vr).Vt' ) (3)
whereσdenotesthe sigmoid function,whichcanconvertthe valuetoprobabilitiesthatfallintherange(0,1).Wewillbe considering8typesofentitiesand10typesofrelations.The 8entitiesare:
1. User: A user is one who purchases or interacts with fundsthroughtherecommendersystem.
2. Fund: A fund refers to a mutual fund that a user purchasesandistheitemto berecommendedinthe recommendersystem.
3. IncomeRange:Theincomerangeistherangethatthe user’sincomefallsinto.Fourincomerangesexist.
4. Occupation:Occupationreferstotheuser’soccupation.
5. Product:Aproductreferstotheproductthattheuser tradeswith.
6. Market type: The market type refers to the type of marketthatthemutualfundisinvestedin.
7. Risktype:Itreferstothelevelofriskinamutualfund.
8. Top5funds:Itreferstothefundswiththetop5selling volumesduringthepreviousmonth.
The 10 types of relations can be divided into three categories:
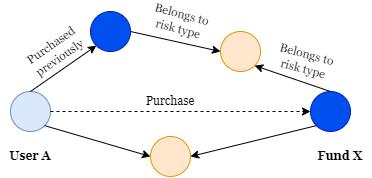
Relationsbetweentheuserandthefund,relationsrelatedto theuser,andrelationsrelatedtothefund.
Theserelationsare:
1. Purchase: The user purchases the fund during the currentmonth.
2. Redeem:Theusermayredeemthemutualfundunits orsharesduringthemonth.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
3. Purchase last month: The user purchases the fund duringthelastmonth.
4. Purchasethemonthbeforelast:Theuserpurchases thefundduringthemonthbeforethelastmonth.
5. Incomerangeas:Thisrelationbetweentheuserand incomerangedescribestheuser’sincomerange.
6. Work as: This relation between the user and occupationdenotestheoccupationoftheuser.
7. Tradewithlasttime:Thisrelationbetweentheuser andproductdenotestheproductthattheusertraded withtheprevioustime.
8. Belongstowhichmarket:Thisrelationbetweenthe fundandmarkettypedescribesthemarkettypeofthe fund.
9. Belongstowhichrisktype:Thisrelationdescribesthe risktypethatthefundbelongsto.
10. BelongstoTop5fundsornot:Thisrelationindicates whetherafundbelongstotheTop5best-sellingfunds.
Thuswecanhavetripletssuchas(Joe,purchasedlastmonth, FundA)thatcanhelplearnknowledgegraphembeddingsof eachentityandrelation.
After constructing the knowledge base S according to the entitiesandrelationsdescribedintheprevioussection,we moveontotrainingandbuildingourmodel.
Theknowledgegraphisnotfixedinoursystem.Weregard the user and fund entities for every month as different nodes.Severalentitiesexistinourknowledgegraphbecause we can add numerous statuses of users and funds to the graph. Each entity and relation is represented as an embedded vector to construct the knowledge graph. This relation is the linear translation from the head to the tail entity. Our goal is to make the embedded entities and relations approximate Eq. 2 as much as possible for the triplets that exist in S = {h,r, t} , and to minimize them otherwise.Consideringthedeepneuralnetworkembedding layers, the computation procedure should consider the featuresoftheuserandfundentitiesasinitializationvectors. Tointegratetheknowledgegraphintoa recommendation system, wewill first,traintheknowledge graphto embed eachentityinthelatentvector.Next,thelatentvectorwillbe usedastheinputoftherecommendersystem.Thisstrategy is called one-by-one learning. We will regard the recommender system as a part of the knowledge graph, whichindicatesthepurchaserelation.Also,wewillusethe deeplearning-basedknowledgegraphconstructionlearning rather than simply adding latent vectors to fit the
optimizationfunction,whichcanadoptthesituationofthe dataset that the numbers of triples connected by each relationvariesgreatly.
Our recommender model's goal is to find the missing connectionsbetweenthetargetuserandfundcandidates.In ourproposedsystem,weusea neural network defined as F(⋅) withparametersΘtodothetask.
For recommendations, the aim is to obtain explicit and implicit feedback from the target user. Explicit feedback includes rating predictions, which correctly reflect the preferences of the items that users interact with. With regard to implicit feedback, we only know whether interactions exist between users and items. Existing interactions are regarded as positive feedback, whereas othersareregardedasnegativefeedback.Suchfeedbackis implicit because positive feedback does not indicate that users like the items. Moreover, the absence of interaction betweenusersanditemsdoesnotindicatethattheusersdo not like the items; rather, these could be disliked or potentiallypreferreditems.ThefeedbackRcanbeexpressed asfollows: (4)
In the proposed method, implicit feedback is considered because we only know whether the user purchases the funds.Afterthefeedbackisconvertedintoknowledgebase form,itcanberepresentedasaprobabilityof{Vh,Vr,Vt}as follows:
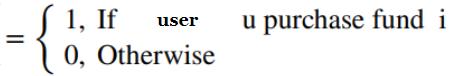
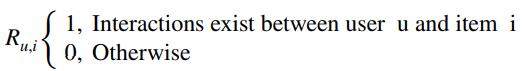
P({Vuser,Vpurchase,Vfund}S)
(5)
Thenegativesamplingmethodwillbeusedtominimizethe lossdefinedinEq.3fortrainingourknowledgegraph.Our graphisextendedwheneveranewentityentersit.Listing every possible link between entities is unfeasible. This processisnotonlyexhaustingbutalsodefeatsthepurpose of knowledge graph completion. Therefore, negative sampling will be performed on the dynamic triplets. Considertheexampleofpurchase-relatedtriplets.Foreach transaction, the tail entity of the observed triplet {user u, purchase, fund i}, which represents the type of funds, is replaced with other funds that are not purchased by the user.Thenewtripletisdenotedas{useru,purchase,fundi’}. By repeating the aforementioned procedure k times, k negativesampleswillbeobtainedforeachpositivesample. The selection of k in the experiment is discussed in the followingsection.Althoughincreasedsamplingmayimprove theaccuracyofthemodel,thecorrespondingtrainingcost wouldalsoincreasesharply.Theentiretrainingprocedureof thedevelopedmodelispresentedinAlgorithm1.Afterthe
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
model is well trained, we can determine the funds recommendedbythemodel.Theprocedureofobtainingthe recommendedfundsispresentedinAlgorithm2.First,the target user’s features are fed into the model and the embedding of the purchase relation is obtained. Next, to acquiretheembeddingsofallthecandidatefunds,thefunds’ featuresarefedintothetraineddeepneuralnetwork.The Eq.2valuesareobtainedfordifferentfunds,whicharethen rankedaccordingtotheobtainedvalues.
After the recommended funds are determined, the knowledgegraphisusedtogenerateexplanationsforpairs of arbitrary users and funds. We regard the process of generatinganexplanationasfindingthelatentexplanation path in the latent space. Our recommendation approach involves finding the fund entities that may have purchase relations with the user entity. To obtain explanations, we attempttofindotherlatentrelationsbetweentheuserentity andthefundentities,whichmaybelinkedtootherentities. It may be a sequence that passes through several intermediate entities and relations. The concept of an explanationpathisdisplayedinWesearchforalltheentities that the head and tail entities can reach, irrespective of whether explicit relations exist between them. The procedure is repeated until all possible paths have been identified,afterwhichwecomputethestrengthofeachpath byusingEq.1.Westartwithbothsidesoftheuserandfund, regardthemasheadentities,sumupalltherelationsfrom theheadentitiestotheintermediateentityalongthepath, regarding the intermediate entity as the tail entity, and multiplythetwoproductscomputedusingEq.1.Inageneral form,thescorecanbecomputedasfollows: (6)
where m indicatesthemiddleentity,Vmdenotesthevector oftheintermediateentity,andRfromentityxrepresentsthe sumoftherelationsalong entity x totheintermediateentity. After all thepossibleexplanationpaths arecomputed,the onewiththehighestvalueisadoptedtoobtainexplanations. The entire computation procedure of constructing explanationsispresentedinAlgorithm3
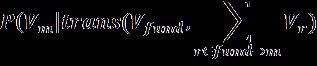
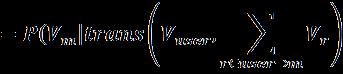
Fig -1: Flowofproposedalgorithm
Fig -2: Explanationofcomposition
Aftercarefullyconsideringandreviewingseveralrelevant papers, we have provided relative analysis of various machine learning model approaches for mutual fund recommendation systems. We have thus identified issues facedinthecurrentMutualFundrecommendationdomain. To provide an efficient solution, we have proposed a KnowledgeGraphbasedrecommendationmodelcombined with Deep Learning embeddings to provide personalized recommendations. The developed model will comprise of twoprocesses:utilizingthedeepneuralembeddingofthe knowledgegraphandgeneratingtheexplanationsandother applicationsofrelatedrecommendations.Inthedeepneural embeddingprocess,featuresofcustomersandfundswillbe extracted.Moreover,theknowledgegraphenablesthemodel tolearnstructuraldetails.Consequently,thesystemwillbe abletorecommendmostappropriatefundsaspertheneeds
of the user along with a valid explanation to back the recommendation claim. Further, personalized recommendation will be influenced by investment propensityofthecustomer.
[1] Pei-Ying Hsu, Chiao-Ting Chen, Chin Chou & Szu-Hao Huang,“Explainablemutualfundrecommendationsystem developed based on knowledge graph embeddings”, publishedinAppliedIntelligenceVolume52Issue9on1st July2022
[2] Li Zhanga, Han Zhanga, SuMin Hao, “An equity fund recommendationsystembycombingtransferlearningand theutilityfunctionoftheprospecttheory”,publishedinthe Journal of finance and data science on Volume 4, Issue 4, December2018
[3]Chae-eunPar,Dong-seokLee,Sung-hyunNam,Soon-kak Kwon, “Implementation of FundRecommendationSystem UsingMachineLearning”publishedinJournalofmultimedia informationsystem,Sept30,2021
[4]PremSankarCa,R.Vidyarajb,K.SatheeshKumarb,“Trust based stock recommendation system - a social network analysisapproach”,publishedinInternationalConferenceon InformationandCommunicationTechnologies-ICICT2014
[5]NusratRouf,MajidBashirMalik,TasleemArif,Sparsh Sharma,SaurabhSingh,SatyabrataAichandHee-CheolKi, “Stock Market Prediction Using Machine Learning Techniques: A Decade Survey on Methodologies, Recent Developments,andFutureDirections“publishedinMDPI, Nov8,2021
[6]NghiaChu,BinhDao,NgaPham,HuyNguyen,HienTran “Predicting Performances of Mutual Funds using Deep LearningandEnsembleTechniques“publishedinarXiv.org SchoolofStatisticalFinance,CornellUniversityarchive,Sept 18,2022
[7] K. Pendaraki, Grigorios Beligiannis, A. Lappa, “Mutual fundpredictionmodelsusingartificialneuralnetworksand geneticprogramming”
[8] Krist Papadopoulos “Predicting Mutual Fund RedemptionswithCollaborativeFiltering”
[9] Yi-ChingChoua, Chiao-TingChen, Szu,HaoHuang, “Modeling behavior sequence for personalized fund recommendationwithgraphicaldeepcollaborativefiltering” publishedinExpertSystemswithApplicationsVolume192, April15,2022
[10]GiridharMaji,DebomitaMondal,NilanjanDey,Narayan C.Debnath,SoumyaSen,“Stockpredictionandmutualfund portfolio management using curve fitting techniques”
publishedinJournalofAmbientIntelligenceandHumanized Computing,Jan2,2021
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056 Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page808
Aayush N Shah, B. Tech Student, Dept. of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra, India.
Aayushi Joshi, B. Tech Student, Dept. of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra, India.
Dhanvi Sheth, B. Tech Student, Dept. of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra, India.
Miti Shah, B.TechStudent,Dept.ofComputerEngineering andIT,VJTICollege,Mumbai,Maharashtra,India.
Prof. Pramila M. Chawan,is working as an Associate ProfessorintheComputerEngineeringDepartmentofVJTI, Mumbai.ShehasdoneherB.E.(ComputerEngineering)and M.E.(Computer Engineering) from VJTI College of Engineering, Mumbai University. She has 30 years of teaching experienceandhas guided 85+M. Tech. projects and130+B.Tech. projects.Shehaspublished148papersin the International Journals, 20 papers in the National/InternationalConferences/Symposiums.Shehas worked as an Organizing Committee member for 25 International Conferences and 5 AICTE/MHRD sponsored Workshops/STTPs/FDPs. She has participated in 17 National/InternationalConferences.WorkedasConsulting Editor on – JEECER, JETR,JETMS, Technology Today, JAM&AEREngg.Today,TheTech.WorldEditor–Journalsof ADRReviewer-IJEF,Inderscience.ShehasworkedasNBA Coordinator of the Computer Engineering Department of VJTIfor5years.ShehadwrittenaproposalunderTEQIP-Iin June2004for‘CreatingCentralComputingFacilityatVJTI’. Rs.EightCroreweresanctionedbytheWorldBankunder TEQIP-Ionthisproposal.CentralComputingFacilitywasset upatVJTIthroughthisfundwhichhasplayedakeyrolein improvingtheteachinglearningprocessatVJTI.Awardedby SIESRPwithInnovative&DedicatedEducationalistAward Specialization: Computer Engineering & I.T. in 2020 AD Scientific Index Ranking (World Scientist and University Ranking2022) – 2ndRank-BestScientist,VJTIComputer Science domain 1138th Rank- Best Scientist, Computer Science,India.