International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
1Student, Dept of Electronics and Communication Engineering, University BDT College of Engineering, Karnataka, India. ***
2
Abstract - Nowadays detecting breast cancer is extremely important in the medical world. One of the major malignancies that may afflict women is breast cancer, which can be quite harmful. Breast cancer (BC) includes two types: benign (noncancerous) and malignant (cancerous). Malignant is listed as a type of cancer that can be cured, whereas benign is listed as a disease that cannot be cured. BC symptoms include changed genes, excruciating pain, size andshape, variations inthe color (redness) of the breasts, and changes in the texture of the skin. For the prediction, machine learning methods are employed. Six different classification techniques, which includes Decision Tree, Logistic Regression, Support Vector Machine (SVM), Random Forest, K Nearest Neighbor (KNN), Naive Bayes, and others, are used to identifybreast cancer. These algorithms fall under category of supervised machine learning. These methods are used to predict the development of breast cancer. These algorithms' accuracy results are assessed. When compared to the other algorithms utilized, it is found that Logistic Regression and Random Forest have the highest accuracy rate, reaching up to 96.49 percent.
Key Words: Breast Cancer, Machine Learning, Logistic Regression, SVM, Decision Tree, KNN, Naïve Bayes.
Changes or abnormalities in the genes that support cell developmentarewhatcausetheconditionknownascancer. Thesealterationsenablethecellstoproliferateandmultiply in an erratic and disorderly fashion. These modifications providethecellstheabilitytoreplicateandproliferateinan irregular and disordered manner. These abnormal cells eventually develop into a tumor. Even if the body doesn't requiretumor’s,theydon'tdielikeothercellsdo.Onetypeof cancerthatdevelopsinthebreastcellsisbreastcancer.This kindofcancermayshowupinbreastlobulesorducts.
Inaddition,thefattytissueandfibrousconnectivetissueof the breast can develop into cancer. These cancer cells become uncontrolled as they grow, invade other healthy breast tissues, and have been known to invade the lymph nodes beneath the arms. There are two types of cancer: malignant and benign. Cancers that are malignant are cancers. Thesecellskeepdividinguncontrollablyandstart affecting other cells and tissues in the body. This form of
cancer is challenging to treat since it has spread to every otherregionofthebody[1].
Thesetumors’canbetreatedwithchemotherapy,radiation therapy, and immunotherapy, among other types of therapies.Sincebenigncancerisnotcarcinogenicitdoesnot grow to other parts of body, it is far less harmful than malignant cancer. Such tumors frequently don't actually need to be treated. Women over 40 are the ones who get diagnosedwithbreastcancermostfrequently.Butanyageof womencancontractthisillness.Itmayalsohappenifbreast cancerrunsinthefamily.Accordingtodata,breastcancer aloneholdsaround25%ofwomendiagnosedwithcancer and15%ofwomen’sdeathduetothecancerglobally,andit hashistoricallyhadahighmortalityrate[2].Sincescientists havelongbeenawareofitsrisks,extensivestudyhasbeen doneinanefforttoidentifythebestcure.
Amachinelearnsprogressivelyonitsownthroughaprocess called machine learning (ML). The ML model serves as a mathematical tool for artificial intelligence. Artificial intelligenceisamachinethatthinksforitselfandemulates human intelligence. The machine improves at its job as it gains more "experience," just like a human does. Machine learning is described as "the mechanism by which a computeroperatesmorecorrectlyasitacquiresandlearns fromthedatagiven"whenviewedasamethodology.
Machine learning algorithm are classified into supervised and unsupervised algorithms. In this work classification algorithmsareusedwhichcomesundersupervisedtypeof learning.Withthehelpofthealgorithms,itisabletopredict theresult.
The author of [1] proposed that the breast cancer can be predictedbyusingdatasetextractedfromWisconsinBreast Cancerrepository.Thedatasethas569datapointswith30 Attributes.TheaccuracyobtainedbyLogisticRegressionis about96.5%.
In[2]theauthorgivesthecomparisonofMLalgorithmsfor breast cancer prediction. The paper employs the decision tree and logistic regression machine learning methods. In this paper WDBCdataset is used which contains570rows and 32 columns. The paper lists out that the logistic
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
regressiongave94.4%AccuracywhereasDecisionTreegave about95.14%accuracy,hence decisiontreealgorithmwas chosentomakethepredictionsmoreaccurately.
In[3]theauthorproposedworkonidentifyingbreastcancer riskfactorwiththehelpofMachinelearningalgorithms.The SupportVectorMachineclassifierisusedincomparisonwith naïveBayesclassifier.
For the breast cancer prediction, the Wisconsin diagnosis breast cancer dataset was utilized. The SVM algorithm performedExcellently,exhibitingaccuracyupto97.91%as comparedtoNBalgorithmwhichgave95.6%accuracy.
In[4]theauthorproposedworkonBreastCanceranalysis usingKNearestNeighboralgorithm.TheauthorusedKNN technique for making the prediction of breast cancer. By using Manhattan distance with K = 1, yields an accuracy around98.40%whereasEuclideandistancewithK=1,yields ahighaccuracyofabout98.70%.
In[5]theauthorworkedonanintelligentsystememploying SVMbasedclassifierforpredictivebreastcancerdetection and prognosis. Support vector machines (SVMs)-based classifiers outperform Bayesian classifiers and artificial neuralnetworksforthediagnosisandprognosisofbreast cancer sickness. The enhanced SVM method performed admirably, displaying high values for great significant to 96.91,specificityupto97.67percent,andsensitivityupto 97.84percent.
Breast cancer is a disease which we hear about a lot nowadays. It is one of the most widespread diseases. It is importanttoidentifythediseasesothatwomenmaystart treatmentassoonaspossible.Itisbestforacorrectandearly diagnosis.Theprimarygoalofthisworkistohelppathologist topredictthetypeofcanceratafasterrate.
Asmachinearecapableofcalculatingtheresultsfasterthan humansdoanditcanalsorepeatitselfthousandsoftimes withoutbeingexhausted.Sowheneverhugeamountofdata arrives machine can predict more than ten thousand iterations per second, which reduces the amount of time required for pathologist to analyze the biopsy report.Also resultsobtained byusingmachinelearningalgorithmsare moreaccurate.
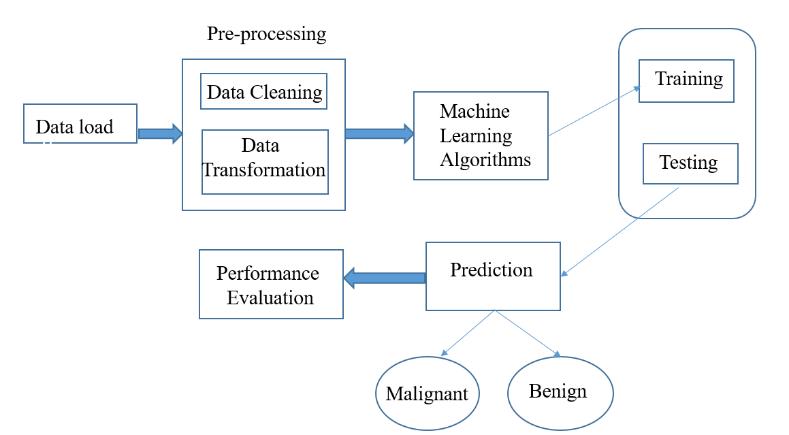
Thefigure1illustratestheblockdiagramoftheproposed work. The data is loaded, run over machine learning algorithms, the data is split into training set and test set. Finally,thetestsetdataisusedformakingthepredictions.
TheWBCDdatasetutilizedinthisstudywascreatedbyDr. WilliamH.WolbergoftheUniversityofWisconsinHospital inMadison,Wisconsin,inUnitedStates.
Thedatasetcontains357benignand212malignantbreast cancer patients, respectively. The dataset comprises 32 columns,withtheIDnumberbeingthefirstcolumnandthe diagnosis outcome (0-benign and 1-malignant) being the secondcolumn.worst)oftenfeatures.
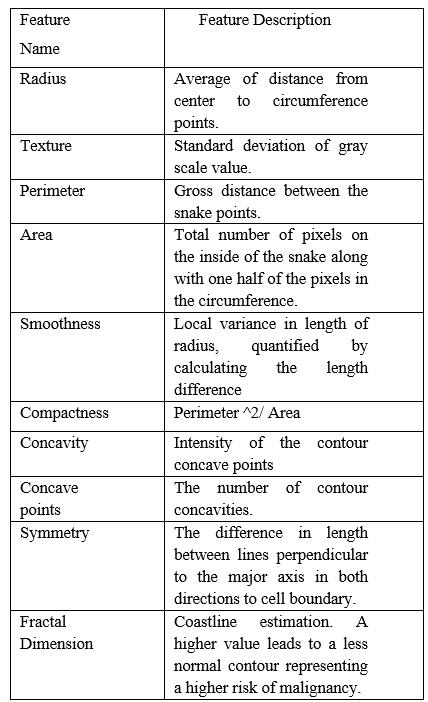
These features represent the shape and size of the target cancer cell nucleus.The sample of cells is collected from a breastthroughFineNeedleAspiration(FNA)procedurein biopsy test. For each cell nucleus, these features are determinedbyanalyzingunderamicroscopeinapathology laboratory.All values of the features are stored up to four significantdigits.Therewerenonullentriesinthedataset. The10real-valuefeaturesaredescribedintheTable1.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
takesshapeofa"S"curve.TheS-formcurveisalsoknownas the logistic function or sigmoid function. In logistic regression, we use the threshold value notion, which determinestheprobabilityofeither0or1.
DecisionTree(DT)isapowerfulmachinelearningalgorithm usedforbothclassificationaswellasregression.DTcanbea tree type of structure where each internal node is a test condition for the vector to move further and the terminal nodes represent the class or the prediction value to be predicted. DT is good for the classification of a few class labelsbutdonotproduceproperresultsiftherearemany classesandlesstrainingobservations.Andmoreover,DTs canbeexpensivetotraincomputationally.
K-NearestNeighbour(KNN)issaidtobethesimplestand themoststraightforwardclassificationalgorithm.Likemost machinelearningalgorithms,K-NNdoesnotlearnanything fromtheprovideddatasetanditsattributes,butsimplyuse thepointsfromthetrainingdataandfindstheKnumberof nearest neighbors to that data point using Euclidean Distance and classify it to the class which has the first K neighborsclosesttoit.
Table1:FeatureDescription
Whenitcomestocreatinga machinelearningmodel,data pre-processingisthefirststepmarkingtheinitiationofthe process. Typically, real world data is incomplete, inconsistent,inaccurate(containserrorsandoutliers),and oftenlacksspecificattributevalues/trends.Thisiswherethe data pre-processing enters the scenario- it helps to calm, format,andorganizetherawdata,therebymakingitreadyto-goformachinelearningmodels.
Logistic Regression is a mathematical function which is utilized to convert expected values into probabilities. Any true worth between 0 and 1 can be changed into another value.Thevalueofthelogisticregressionmustbebetween0 and1,anditcannotbemorethanthisvalue.Asaresult,it
Random Forest is a very well machine learning algorithm that is used in the supervised learning methodology. The Random Forest classifier aggregates the outcomes from several decisiontreesappliedtodistinctsubgroupsofthe inputdatasetinordertoincreasethepredictedefficiencyof the input dataset. Rather of depending on a decision tree classifier,therandomforestutilizespredictionsfromallof the trees to forecast the final result based on votes of the majorityofpredictions.
Supportvectormachine(SVM)isaquitesimpleclassification algorithm. This classifier is named so because it takes the helpofvectorsinthefeaturespacetoclassifytheclassofa new vector. The Maximum Margin Hyper-plane (MMH) decideswhetherthenewvectorbelongstoclassoneorclass two.Ifthedatapointliesbeyondthenegativehyper-planeor to the left of MMH then it belongs to the class one, else it belongstotheclasstwo,whereclassoneandtwoaretwo differentclassesinagivensituation.SVMscanalsobeusedif therearemorethantwoclasses.
NaïveBayes(NB)theoremisamachinelearningalgorithm thatworksontheprobabilityconcepts.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
Where P(A) is the Prior Probability, P(B) is the Marginal Likelihood, P(B|A) is the Likelihood and P(A|B) is the Posterior Probability. The NB algorithm follows the above equationforthedeterminationoftheclassofadatapoint.The posteriorprobabilityiscalculatedbasedonthepositionofthe vectorinthefeaturespaceandthenthedatapointisassigned totheclasswithgreaterposteriorprobability
Overfittingisaproblemthatarisesfrequentlyduringmodel training. This issue arises when a model performs remarkablywellonthedata,weusedtotrainitbutstruggles to generalize effectively to new, undiscovered data points. Contrarily,underfittinghappenswhenthemodelperforms poorlyevenwhentestedonthetrainingsetofdata.
Themostcommonapproachforidentifyingthesetypesof issuesistodevelopanumberofdatasamplesforthemodel's trainingphaseandtestingphase.Followingtheanalysis,we will train the machine with the 80% of the data. In this context,"training"referstoinstructingthecomputerwith data.
Aftertrainingthemachineonthefirst80%ofthedata,the remaining 20% of the data points are utilized to check its efficiency.Inotherwords,wemayalsoquantifyhowmuch specificprocessknowledgethemachineacquired.
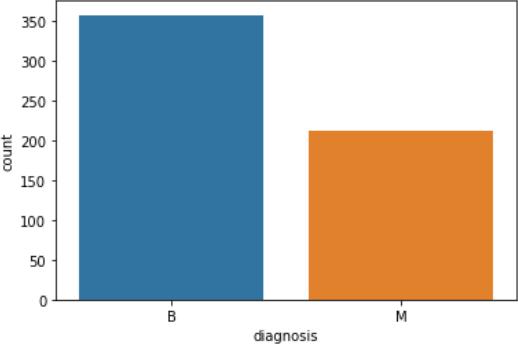
The patient's test results or the doctor's evaluation of the patient'smedicalhistoryarebothusedtomakethediagnosis ofbreastcancer.Inordertoidentifywhetherthepatienthas normal and cancerous cancer, here 32 characteristics are utilized.Where,B=357ANDM=212.
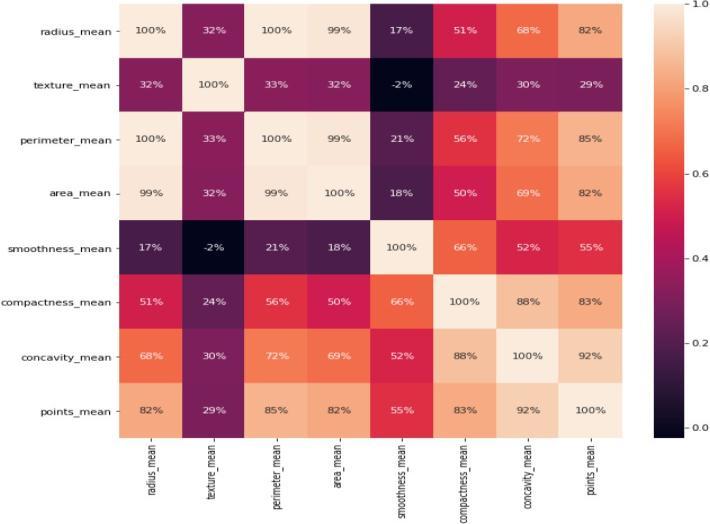
The heat map of the correlation between the WBCD dataset'sfeaturesetsisdisplayedinthefigure20asshown below.Thevalueofthefirstdimensionisseenastheheat map'srow,whilethevalueoftheseconddimensionisseen asitscolumn.Thiscreatesa two-dimensional correlation matrixbetweenthetwodiscretedimensions.
After Machine learning model is fit, the model can predict whether the patient has Malignant type that is patient is sufferingfromcancerorBenigntypethatispatientdoesnot havecancerbyimplementingsixdifferentmachinelearning algorithmsofavailabledataset.
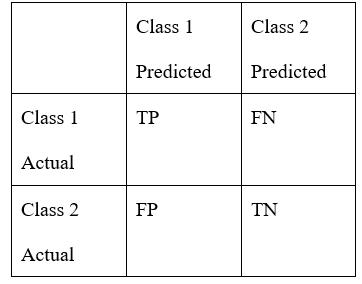
Aconfusionmatrixisatablethatisoftenusedtodescribethe performanceofaclassificationmodeloraclassifieronaset oftestdataforwhichthetruevaluesareknown.
ACCURACY
Where,
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072
TP=TruePositive
TN=TrueNegative
FP=FalsePositive
FN=FalseNegative
AconfusionmatrixmadeupofTP,FP,TN,&FNiscreated forthetrueandprojectedresultsinordertodeterminethe accuracyofeachmethodutilised.
Following the implementation of machine learning algorithm,thewholedatasetisdividedintotrainingsetand testset.Where80%ofdatasetthatisabout456samplesof dataisgivenfortrainingthemachineandremaining20%of datathatisabout113samplesofdataisgivenfortraining, whichisfurtherusedtopredicttheoutcome.
Machinelearningalgorithms'performanceisevaluatedand contrasted.Theresultrepresentedinthetabledemonstrate thepredictedaccuracyoftrainingand testingdatasetfor Logistic Regression, Decision Tree, KNN, Random Forest, SVMandNaïveBayes.
LogisticRegression 94.28% 96.49% DecisionTree 100% 92.98% KNearestNeighbor 94.72% 92.98% RandomForest 99.78% 96.49% SVM 97.14% 95.61% NaïveBayes 94.06% 92.10%
Fromthetable2,itisobservedthatLogisticRegressionand Random Forest algorithms has achieved higher accuracy thatisabout96.49%forthepredictionofbreastcancer.
WebApplicationusedtopredictBreastCancercanbedone usingFLASK,GraphicUserInterface(GUI)canbecreated usingHTML
INPUT:
The web application for prediction of breast cancer is created.Theuserneedtoenterthevaluesofthe30Features asincludedinthedatasetextractedfromWisconsinbreast cancerrepository.


Snapshot1:Inputofthemodel
The values entered by the user is given to the web application which is used to predict the result that is whetherthepatienthasbreastcancerorpatientdoesnot havebreastcancer.
Snapshot2:Outputofthemodel
Breast cancer is currently one of the most dangerous illnessesthataffectswomen.Itistheleadingcauseofdeath forwomen.ThisstudyutilizedtheWisconsinbreastcancer dataset,andseveralmachinelearningalgorithmswereused to incorporate the efficiency and usefulness of the algorithmsinordertoidentifythecategorizationofnormal andcancerousbreastcancerthathadthebestaccuracy.
Infutureitisableachievegreaterefficiencybyselectingthe best attribute from the dataset and by also increasing the numberofdataset.ArtificialNeuralNetworkscanbeapplied tomakethepredictionsbecauseitusesthehiddenlayerto makebetterandsmarterpredictions
1]S.Ara,A.DasandA.Dey, "MalignantandBenignBreast Cancer Classification using MachineLearning Algorithms," 2021 International Conference onArtificialIntelligence (ICAI), 2021.
2] A. Bharat, N. Pooja and R. A. Reddy, "Using Machine Learning algorithms for breast cancer risk prediction and
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
diagnosis," 2018 3rd International Conference on Circuits, Control, Communication and Computing (I4C), 2018.
3] Sultana, Jabeen, Abdul Khader Jilani, & "Predicting Breast Cancer Using Logistic Regression and Multi-Class Classifiers." International Journal of Engineering & Technology [Online], 7.4.20 (2018): 22-26. Web. 30 Nov. 2019.
4] P.Sathiyanarayanan, S.Pavithra, M.Sai Saranya, and M.Makeswari, “ Identification of breast cancer using The Decision Tree Algorithm,” 2019 IEEE International Conference on System, Computing, Automation and Networking(ICSCAN), 2019.
5] M.D. Bakthavachalam, Dr.S. Albert, Antony Raj, “Breast CancerAnalysisusingK-NearestNeighborAlgorithm”, 2020 InternationalConferenceonArtificialIntelligence(ICCS),2020.
6] Puneet Yadav et al. “Diagnosis of Breast Cancer using Decision Tree Models and SVM”, International Research JournalofEngineeringandTechnology,Vol.5,Issue3,Mar 2018.
7] Medjahed, Seyyid Ahmed, Tamazouzt Ait Saadi, and AbdelkaderBenyettou."Breastcancerdiagnosisbyusingknearestneighborwithdifferentdistancesandclassification rules."InternationalJournalofComputerApplications62.1 (2013).
[8]KritiJainetal.“BreastCancerDiagnosisUsingMachine learning Techniques”, International Journal of Innovative Science,Engineering&Technology,Vol.5,Issue5,May2018.
[9]Zheng,Bichen,SangWonYoon,andSarahS.Lam."Breast cancerdiagnosisbasedonfeatureextractionusingahybridof Kmeans and support vector machine algorithms." Expert SystemswithApplications41.4(2014):1476-1482.
[10] Puneet Yadav et al. “Diagnosis of Breast Cancer using Decision ree Models and SVM”, International Research JournalofEngineeringandTechnology,Vol.5,Issue3,Mar 2018.
[11] Medjahed, Seyyid Ahmed, Tamazouzt Ait Saadi, and AbdelkaderBenyettou."Breastcancerdiagnosisbyusingknearestneighborwithdifferentdistancesandclassification rules."InternationalJournalofComputerApplications62.1 (2013).
[12] Chaurasia, Vikas, Saurabh Pal, and B. B. Tiwari. "Predictionofbenignandmalignantbreastcancerusingdata miningtechniques."JournalofAlgorithms&Computational Technology12.2(2018):119-126.
Volume: 09 Issue: 11 | Nov 2022 www.irjet.net p-ISSN:2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page773