International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
1-3 Student,Department of Information Technology, Vivekanand Education Society Institute of Technology, University of Mumbai
4 Professor,Department of Information Technology, Vivekanand Education Society Institute of Technology, University of Mumbai ***
Abstract -Theimageswhenpresentedtohumanscaneasily identify the objects, relationships among the objects of the givenimage.Similarly,ImagecaptioningisthemodelintheAI sector, wherethe image is sent as input, and then the objects, relationship between the objects are generated as captions. The model is based on encoder decoder architecture which is trained on flickr30k dataset. This paper describes the deep insights of deep learning techniques used for caption generationwithconvolutionalneuralnetworksandrecurrent neural networks. The results are then translated into Hindi. The model is prepared with focus to help visually impaired people with voice assistant functionality.
Key Words: Image captioning, deep neural networks, GRU & NLP, Artificial Intelligence.
In accordance with the fast growth of information technology and the Internet, usage of mobile phones and photoshop apps/tools have made more and more images appearonsocialnetworkingplatforms.Hence,greaterneed forimagecaptioning.
Image captioning is a process of generating image descriptions for a comprehensive understanding of the variouscomponentsofthegivenimagei.eobjectspresentin thegivenimage,thebackgroundofthegivenimage,andthe relationshipsbetweentheobjectspresent.Imagecaptionis inclusive of two most important aspects of the Artificial Intelligence (AI) field, one being computer vision and the otherbeingNaturalLanguageProcessing(NLP),anditisa very challenging problem until and unless we have a breakthroughsolutiontoit.
Humansuseanylanguagetodescribetheimagegivento them. This leads to a better understanding of the whole scenariobygeneratingcaptionsoutofthegivenimagesand laterusingthosecaptionstothoroughlydescribetheimage in a much easier manner. Various factors are required in ordertogetanin-depthunderstandingofanimagesuchas the spatial and semantic information about the various components present in the image, and the relationships betweenall theobjectsoftheimage. Thetwo majortasks thatarerequiredtogeneratecaptionsfromtheimagesareas follows:
1.Getting information about the world i.e collecting the dataset.2.Generatingsentencestodescribethegivenimage. Using the Convolutional Neural Network (CNN) [9]Recurrent Neural Network (RNN) [10] model, Different methodsofComputerVision,GatedRecurrentUnit(GRU), andNLPareusedforextractinginformationfromtheimages andrepresentingthemasmeaningfulsentences.
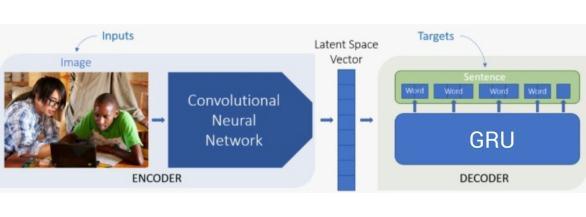
Inpaper[11],theCNN-RNNmodelisincorporatedwithLong ShortTermMemory(LSTM)[12]attheRNNpart.Butdueto the large number of gates the computational power is slightly increased as compared to GRU hence we have performedthetaskwithGRU.Thispaper’saimistocollect meaningfultextualdescriptionfromanygivenimages,inthe formofshortyetmeaningfulcaptions.Inordertomakeour model reach a vast number of users, these captions are further run into a text-to-speech model. This way, a fully independentandeasyexperiencecouldbeprovidedtousers with short-sightedness. With the rise of social media platforms,thesepeopledon’thavetofeelliketheyareleft outorlonely,especiallywhenitcomestotheirlovedones sharing pictures on social media.Thus, we have implementedourapproachofimagecaptioningmodelanda detailedanalysisoftheseapproacheshasbeendescribedin thispaper
Themainpurposeofourprojectintheoceanofmachine learningwastobasicallymakeavailableaproventechnique to avail the proper outcome from tons of algorithms and researchesproposed.Thethoroughresearchwasindeedto experimentinsolvingourproblemwithmachinelearningor deeplearningtechniques.Asalreadyalotofresearchwork is done in this area the primary focus was to develop a productionlevelsolutionwhichcanberuninalmostrealtime and can be integrated with any other application to
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
make best use of it. And hence, it has been made with integrationeaseinanobjectorientedapproach.
Themostcommondatasetsusedforimagecaptioningare MSCOCO,Flickr30k.Itisbecauseitcontainsalargenumber ofimages,andeachimagecontainsfivecaptionsassociated withit.Thehumandescriptionhelpstotrainthemodelwell.
MS-COCO (Microsoft Common Objects in Context): The datasetisrichinavarietyofimagescontainingobjectsand scenesofdifferentcategoriesandhenceitcan beusedfor real time object detection, object segmentation, key point detectionandimagecaptioning.Thedatasetislabeledandis available publicly. The recent version which has 328K images was released in the year 2017 which has around 118Ktrainingimages,5Kvalidationand41Ktestingimages andadditional123Kunannotateddataset[5].Italsoserves asasupplementtotransferlearningandiswidelyusedfor training,testingandpolishingthemodels.Thedatasethas around328Kimages.
LikeforexampleintheFig.3below,astheglassesarebound byapinkboxsotheword‘glasses’indescriptionisalsoin pink.Similarly,intherightmostimageinFig.3the‘bride’is enclosedinablueboxandhencetheword‘bride’isinblue colorinallthecaptions.Thishelpsthemodeltolearnhow theobjectsthatappearvisuallyintheimagescorrespondto howtheyarecalledincaptions.Forthispaper,Flickr30khas been used containing 30,000 images with 80:20 ratio for trainingandtesting.

Themostimportantphaseisthisphasebecauseifwe neglect this phase the results could be quite devastating from the presumed ones. Our model requires the preprocessingfortwoparts.Theonefortheencoderphase andtheotheroneforthedecoderphase.
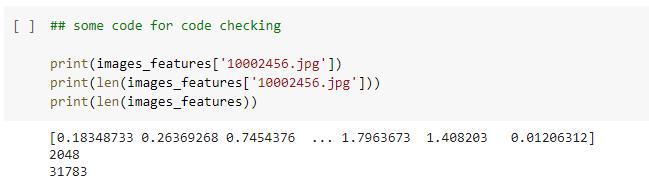
Let’sfirstunderstandpreprocessingforConvolutionNeural Networki.e.encoderphase.Theencodermodelisbasedon Resnet50architectureandhencetheinputimagesizemust be224x224.Itcanacceptanyimageformatfiles.Thekeras applicationmodulehelpsinpreprocessingtheimageswith the help of transfer learning on the Resnet50 model. The imagefeaturesarethusextractedandsavedinafile.While extractingimagefeatures,thesecondlastlayera.k.a
classification layer has been removed because of transfer learning.Thesefeaturesarereshapedtoanarrayofvalues between0and1ofthesize2048withnumpymodule.
Flickr30K: The Flickr30K dataset is used widely for sentence-basedimagedescription,whichhasatotalof158k captions with 244k coreference chains, where different captionsforthesameimagewithsameentitiesislinkedand associatedwith276kmanuallyannotatedboundingboxes.

For the data processing at the decoder part (Gated RecurrentUnit-GRU)thefollowingstepsareapplied:
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
Thecaptionsfromthedatasetaremadecleanerby removingpunctuations,spaces,numericalorspecial characters.
A‘<start>’and‘<end>’tokenisaddedtostartand endofthecaptionssothatduringthetrainingphase the decoder understands the starting and ending pointofaparticularcaption.
Captiontokenizationtocreatealistofuniquewords bydifferentiatingthemonthebasisofblankspaces presentbetweenthem.Aswehaveusedflickr30k datasetwhichgivesabout150kcaptionshencethe vocabularysizeisthresholdto18000words.
The above generated words are converted to 0’s and 1’s sequence. Later word map indexing followed by padding these sequences to form the largestsequencepossible.Inourcasethelengthof thelargestsequenceis74.
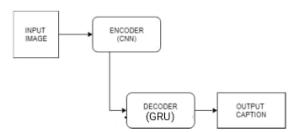
ThemostwidelyacceptedarchitectureisEncoder-Decoder architecture.InourcasetheencoderpartisConvolutional Neural Network (CNN) and the decoder part is Grated Recurrent Network (GRU) which is a type of Recurrent NeuralNetwork(RNN).Thegenericmodelrepresentationof thearchitectureisshownbelow.
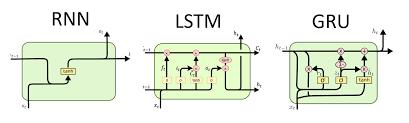
The most actively used decoder architecture is LSTM (Long Short Term Memory). On the other hand we have implemented it with GRU (Gated Recurrent Unit) because thereisn’tmuchdifferencebetweenLSTMandGRUbutthe lateronedoesn’thavethecellstatebutmakesuseofhidden statetotransfertheinformation.
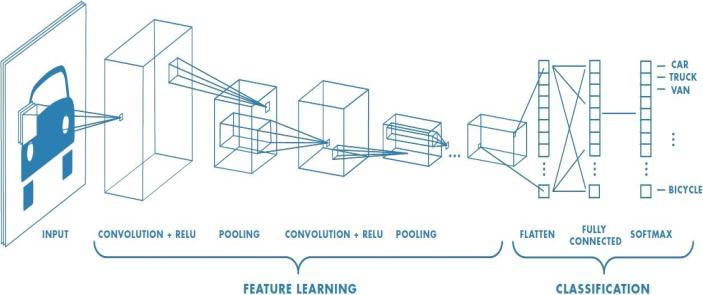
Intheaboveblockdiagram,theimagefeaturesareextracted intheCNNandactasinputtotheGRUwhichwillprocessthe features with word vocabulary and predict the output caption.
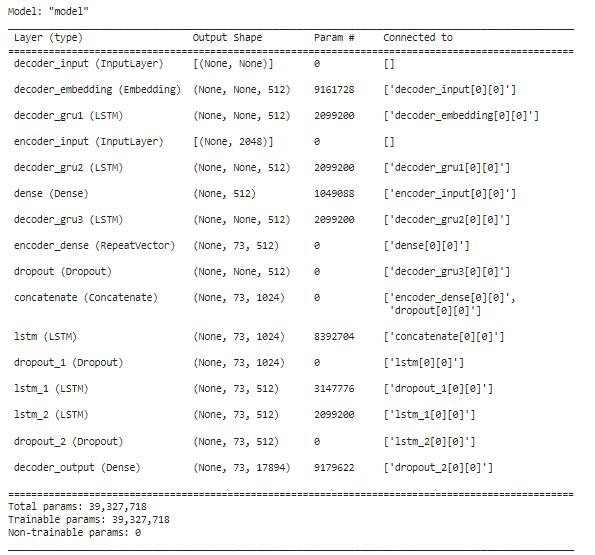
TheencoderinourmodelisConvolutionNeuralNetwork (CNN).Theimagefeaturesareextractedinthisstepwiththe help of preprocessing and transfer learning through Resnet50 architecture. The second last layer i.e. softmax layerhasbeenremovedasclassificationisnotrequired.The outputisavectorof(512,2048)shape
Thetrainingphasebeginswithsplittingthedatasetinto trainingandtestingphase.Sinceeachimagehas5captions soifwerandomlyshufflethemthensometraindatawillleak intotheValidationdata.Hencewewillusethekfoldgroup foldmethodtomakesureeachcaptionofthesameimage staysinthesameset.Theprocessisasdiscussedbelow.
Mixupthedatasetrandomly.
Divideitintonparts.
Foreachdistinctpart:
o Takethatpartastestdataset
o Whileconsidertheremainingpartsastraining dataset
o Considering the above training and testing parts,trainandevaluatethemodel.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
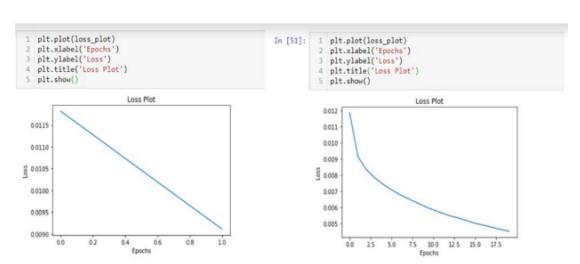
The model is trained for 36 epochs and it gives an accuracy of 0.8891 which is 88%. The training loss which indicatesincorrectpredictionsforthemodelis0.5948.The modelistestedontestingimagesaswellassomereal-world images.

Asthedatasetisquitelargeenoughwecan’tpassitintoa singlebatch.Thebatchbasicallysplittheentiredatasetinto equalpartsofbatchsizesothetrainingcanbedoneinthose batch parts. We have used the batch size of 64. Adam optimizerwasusedwithlearningrate(lr)of3e-4andthe lossfunctionusedisSparseCategoricalCrossentropypassing logisticsastrue.
Thetrainingphaseisassociatedwithacallbackfunctionfor early stop ping. If the accuracy is not increasing with the initiallearningratethenitwillbedecreasedbyafactorof 0.2untilthethresholdlr=1e-5doesn’treach.
Thelargertheepochsconsidereditisassumedthatthemore theaccuracywillbe.Thebelowdiagramexplainsthesame. In our model we have trained for 36 epochs. After every epochthetrainedweightsaresavedforbackupin‘pickle’ format.TheentiretrainingphasewasdoneonGPUofgoogle colabforfasterprocessing.
EachoutputispresentedinEnglishandconvertedintoHindi language.There’sanaudioassociatedwitheachthatspeaks out the result which is done using gTTS (Google Text to Speech) library as shown in the first output. The BLEU (Bilingual Evaluation Understudy) which is a metric to compare the output with the predicted one [8].For calculatingtheBleuscorewehaveusedtheNLTKlibraryof python.ForourmodelwehaveachievedtheBleuscoreof 0.5625.

(a)
(b)
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
text-to-speech model. In this paper, we have used the standard CNN-RNN model with an extension of GRU and natural language processing (NLP). Thus, we have implementedourapproachofimagecaptioningmodelanda detailed analysis of these approaches has been described here. Experimental results and analysis strongly demonstratetheeffectivenessoftheproposedmodel.Inthe future,wewillcontinuewithourworkinotheraspectsof themodel.


[1] M. M. Tsung-Yi Lin, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar and L. Zitnick, 2014, ”Microsoft COCO:CommonObjectsinContext,”ComputerVision–ECCV2014,8693.
[2] The COCO Dataset Website, Available online: http://cocodataset.org/#home.
[3] Bryan A. Plummer, Liwei Wang, Christopher M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and SvetlanaLazebnik,2017,“Flickr30KEntities:Collecting Region-to-PhraseCorrespondencesforRicherImage-to SentenceModels,IJCV”,123(1),pp.74-93.
[4] Adela Puscasiu, Alexandra Fanca, Dan-Ioan Gota, HonoriuValean,2020,“Automatedimagecaptioning”, 2020 IEEE International Conference on Automation, QualityandTesting,Robotics(AQTR).
Theoutputisexpected tobeshortandprecise which canbeseenfromtheFig.10(a).Althoughtheotherkidsseen intheimagecouldalsobementioned.IntheFig.10(b)&(c) showscorrectidentificationofanimal’s.Thegrammarcould be better like the bird flying “in” the air rather than “through”theair.Themodelrecognizesthegendercorrectly anddifferentiateshumansfromanimalstoo.Theoutputof Fig.10 (d) could have been more accurate like “woman in whiteshirtissittinginfrontofthecomputeronthetable”. Our model hence recognises humans and animals with gender specification with certain accuracy which can therebybeenhancedbyincreasingthetrainingepochs.
Some outputs are displayed having moderately good accuracyalthoughthemodelcanbetrainedmoretoachieve better results. A website has been developed for users to uploadanimageandfindthecorrespondingcaptionuseful for different purposes especially for visually impaired people.Also,anAPIhasbeencreatedsothatthisapplication canbereused.
Thispaperaimedtodevelopamodelforautomatedimage captioningusingdeeplearning.Toreachthegoalofhelping visuallyimpairedpeople,thisprototypeisintegratedwitha
[5] Lin, Tsung-Yi, et al., 2014, "Microsoft coco: Common objectsincontext." Europeanconferenceoncomputer vision.Springer,Cham.
[6] Md. Zakir Hossain, Ferdous Sohel, Mohd Fairuz Shiratuddin,andHamidLaga,2018,”AComprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv”, computing methodologies→Machine learning:Neuralnetworks.
[7] DProgrammer Lopez, 2019, RNN, LSTM GRU, http://dprogrammer.org/rnnlstm-gru.
[8] Jason Brownlee, 2020,”A Gentle Introduction to Calculating the BLEU Score for Text in Python”, Machine Learning Mastery, https://machinelearningmastery.com/calculate-bleuscore-for-text-python/.
[9] Yamashita, R., Nishio, M., Do, R.K.G. et al, 2018,” Convolutionalneuralnetworks:anoverviewand applicationinradiology”, Insights Imaging, 9,pp.611–629,https://doi.org/10.1007/s13244-018-0639-9.
[10] Kanagachidambaresan, G.R., Ruwali, A., Banerjee, D., Prakash, K.B, 2021, “Recurrent Neural Network”, In: Prakash, K.B., Kanagachidambaresan, G.R. (Eds) Programming with TensorFlow, EAI/Springer
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Innovations in Communication and Computing. Springer,Cham,https://doi.org/10.1007/978-3-03057077-4_7.
[11] Sehgal, S., Sharma, J., & Chaudhary, N., 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), IEEE. https://ieeexplore.ieee.org/document/9197977.
[12] Van Houdt, G., Mosquera, C. & Nápoles, G, 2020, ”A review on the long short-term memory model. Artif Intell Rev “, 53, pp. 5929–5955, https://doi.org/10.1007/s10462-020-09838-1
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072 © 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page535