International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
Aaditi Narkhede 1 , Prof. M.U.Kulkarni 2 , Prof. S.R.Naik 3
1 Student, aaditirajeshn99@gmail.com, Dept. Of Computer Science and Technology, VJTI, Mumbai, India 2 Professor, mukulkarni@ce.vjti.ac.in, Dept. Of Computer Science and Technology, VJTI, Mumbai, India 3 Professor, sraksha@it.vjti.ac.in, Dept. Of Computer Science and Technology, VJTI, Mumbai, India ***
Abstract - Asemanticnetworkthatdisplaystheconnections betweenentitiesisknownasaknowledgegraph.Datacanbe visualised to help with information analysis and comprehension through the use of the knowledge graph. Knowledge graphs can help professionals with complex analysis applications and deci- sion support while also erecting barriers in the market. A good construction system can help companies construct knowledge graphs efficiently andquickly.However,Extractionofvaluableinformationfrom suchhuge, complexand unstructureddata requiresahuman approachtohandleuserqueriesrelatedtodata,whichcauses delays and uncertainty in decision making and strategy planning. In this paper, we propose an approach for automatic knowledge graph construction and automated querying engine to answer user queries using generated knowledge graph. The proposed system will benefit Professionalswithfaster,easierunderstandingandanalysisof complex and huge unstructured data. Experimental results show that our proposed solution is more effective in constructing a generic knowledge graph.
Key Words: Knowledge graph, Question Answering system, spaCy, Natural Language Processing, Named Entity Recognition.
The goal of a knowledge graph is usually to collect, connect,andshowinformation.Itoffersahighlevelofinterpretability. Knowledge Graphs help in establishing purposefulrelationshipsoforganisationalknowledgethrough classifying various contentintodifferentcategories [1].By groupingdifferenttypesofcontentintodistinctcategories, knowledge graphs assist in establishing intentional relationships between organisational knowledge. Large volumes of unstructured data are produced daily. This informationispresentedinreports,researchpapers,patents, scholastic articles, book chapters, essays, and speeches, among other formats. Identifying key patterns in vast amounts of unstructured data is crucial in to- day’s environment.Itischallengingtounderstandandevaluatethe implications provided in an organization’s data since the essentialinformationisdispersedacrossthelargevolumesof data.
Duetotheabsenceofboundariesbetweentheitemsthat needtoberetrieved,thetargetentities’contextdependency, the variability in language patterns, and the limits of statisticalapproaches,automaticinformationextractionfrom suchvastamounts ofdata ischallenging. Thefact that this typeofdataisfrequentlyavailableasunstructuredtextsorin PDF format presents another challenge when trying to extract informationfrom it. As a result, either laborious manual preprocessing is required or sophisticated ETL (Extract,transform,load)systemsareusedtoautomatically ingestdata.Tohandlethischallenge,requireddatai.e.textual datawillbefirstextractedfromPDFsforourresearchwork usingFineTuneddetectron2basedmodelandpytesseractocr andwillbestoredinatextfilewhichwillbeusedfurtherfor informationextractionpurposeswhile building Knowledge Graph.
Theproposedapproachaimstoresolveissuesofambiguity,abbreviationsandsemanticsoftextwhileconstructinga knowledgegraph,achievedwiththeuseofspaCybasedNER for extracting the entity-pairs and relations from the data. Basedontripletsobtainedwhileinformationextraction,the Knowledgegraphisconstructed.IntheproposedQuestionAnsweringsystem,forQueryanalysisasimilarspaCybased approachisusedforentity-pairandrelationextractionfrom user query. In the Answer Extraction module, the combinationof approaches is used, such as information retrievalbasedonthefeatureinformationofrelevantentities insentencesandusestrainedfeatureclassifierstosortthe candidate answers and obtain the solutions; along with matching query triplets with knowledge graph database using generic linguistics rules designed to obtain the solutions.
Section2.ofthepaperdescribesthepreviousandcurrent studybeingcarriedoutinthe field of Knowledge Graphs and Question-Answering Systems. It also states the drawbacksand the problems faced in existing approaches. Section 3.ofthePaperexplains the proposed methodology and thestepbystepexecutionofthesamewiththehelpofa few examples. Section 4. of the Paper summarizes and analysestheResultsobtainedandgivesaninsightregarding how the proposed system can be deployed for Different
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
domain-data.Section5.ofthePaperconcludestheResearch regarding the generic approach for Knowledge graph Constructionandqueryansweringsystem.Section6.ofthe Paper summarizes the References used/followed for the survey purpose.
Our work is inspired by two threads of research: Key techniques in KG construction and Key techniques in QA system
Atypicalknowledge-graphconstruction process consists of three main components: information extraction, knowledgefusion, and knowledge graph building.
Information Extraction : The goal of information extractionistofindandseparateentitiesinadatasource,as wellastheirqualitiesandrelationshipswithotherentities withthemeansofentityrecognitionandrelationextraction.
Entityextraction,alsoknownasnamedentityrecognition (NER),referstotheprocessofidentifyingaccuratelynamed entitiesfromdata,especiallytextdata[7].Therearecertain paradigmsthathavebeendevelopedforNERactivitiessuch as Rule based, Machine learning based and Deep learning based approaches. The underlying concept behind most commonNERapproacheswastocreateasmallsetofrules byhand and thenlook for stringsin thetext thatfitthese criteria.Usage of RulebasedNER cannothandlemultiple unforeseen patterns and thus does not possess strong interpretability of semantics while information extraction [2]. Traditional NER approaches, such as rule-based and template-based, are expensive and rely too much on procedureslikeruledevelopmentandfeatureengineering. The machine learning based approach, tags the named entitiestothewordsevenwhenthewordsarenotlistedin thedictionary andthecontextisnotdescribed in the rule set. K. Khadilkar, S. Kulkarni and S. Venkatraman [1], proposed a method forsummarizing multilingual vocal as well as written paragraphs and speeches, using semantic KnowledgeGraphs.Fortheselectionofrelationextraction API, experiments were performed on NLTK and Stanford CoreNLP; out of which Stanford CoreNLP resulted with highest accuracy of 92.23% which uses CRF algorithm internallyhavingabilitytoconsidercontextofprevioustext in detecting entities and relation; but fails to consider context level dependency in relation extraction. Different from traditional machine learning, deep learning can automatically extract high-level abstract features from a large amount of data to perform model training [4]. In particular, word vector representation has provided a powerful driving force for the typical serialized labelling problems of NER. Z. Dai, X. Wang has discussed various neural network models [3], where the BERT-BiLSTM-CRF
modelachievedhigherF1scorecomparedtoothermodels. BERT, captures a general language representation from large-scale corpora, but lacks domain-specific knowledge. TwoapproachessuchasSpaCyandBERTarediscussedin [6] for NER task for Tourism dataset where experimental results shows that SpaCy NER outperforms BERT NER as achieved accuracies are 95% and 70% respectively. PerformanceofBERTisloweredasitisunabletotokenize specialmultiwordnameswhicharepropernounsverywell. Syntactic Dependency Parsing is also offered by SpaCy’s dependencyparser[6]forrelationextraction.
RelationExtractionisamajorfieldinNLP.UsingRelation Extraction,datacanbetransformedintoa3-tupleformatof [entity, relationship, entity]. The patterns are generated through text analysis and represent the unique language constructions which are used to describe a particular Entity/Relationin[2].Thesepatternsarethenmatchedwith processed text to discover and extract required pieces of information; extracted relationship names between two entities using object property of an ontological concept. RecognizingtherelationshipsusingthespaCymodelmaybe done in two ways. The first method is to utilise spaCy’s dependencyparser.Thesecondmethodistocreatenewtags based on relation keywords. [6] showed comparison between spaCy’s dependency parser and BERT with BIO taggingwherespaCyachievedhigheraccuracyof95%and also it was able to consider context level dependency in relationextraction.
Knowledge Fusion : InKnowledgefusion,laststepof knowledgegraphconstruction,EntityDisambiguationand entity linking is carried out to preserve the semantic information of text and handles uneven knowledge expression. During the Entity Disambiguation job, ambiguousentitymentionsareconnectedtotheirreferent entitiesintheKnowledgegraph,whichisaccomplishedby employingaclusteringtechniquein[9].Amethodbasedon Word2Veccosinesimilaritycalculationisproposedin[8]to completeentitylinkingforentitiesobtainedfromquestion sentences.Word2Vec isused in[8]toconvertrecognition entityandcandidateentityintocorrespondingwordvectors and implemented cosine similarity method to calculate similarity value between recognition entity and candidate entity.FortheQuestion-answeringsystemin[11],relevance scoringbasedonQAcontextisusedtolinkandfindrelevant entities from KG. To link the primary entities with their preposition occurrences in the text or their multiple reference entities, coreference resolution is used [1]. For topmost winning models described in [7], Coreference resolutionisachievedusingNeuralCorefofferedbyspaCy. Ratherthanadoptingcomprehensivecoreferenceresolution, [12]tackletheproblembyrecognisingthepronounsinthe input content and replacing them with the corresponding subjectorobject.further,accuracyofcoreferenceresolution is improved by analysing the gender of an entity. For the
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
coreference resolution task, it has been observed that NeuralCorefbyspaCydoesthejobinanefficientway.
Question-answeringresearchbasedonKnowledgegraphs is an important area of study. The basis of the knowledge graph’squestionansweringmechanismisquestionanalysis. The accuracy with which the semantic information in the questionsentenceisminedimpactstheactualeffectofthe question answering system. Research based on financial knowledge graph using ontology proposed Question Answering system [2] to sequentially perform linguistic analysisofquery,donamedentityextraction,entity/graph search, fusion and ranking of possible answers.SPARQL is usedforquerying.
To solve the problem of inadequate question’s semantic informationmining,[8]proposedBERTbasedKGQAsystem which mainly includes Entity recognition and Relation RecognitionforquestionanalysiswhereBERT-BiLSTM-CRF model is used and calculates the similarity between the entity obtained in the entity recognition and candidate entity, and takes the entity with highest similarity as the standardentitycontainedinthenaturallanguagequestion.
Themainstreamimplementationmethodsofaknowledge based question answering system can be divided into categories such as Semantic Parsing which involves some linguistics and traditional NLP methods, requires many manual design rules, and has high accuracy but lacks generalizationability;andInformationExtraction:Thiskind of approach extracts the feature information of relevant entitiesinsentences orknowledgebasesandusestrained featureclassifierstosortthecandidateanswersandobtain the solutions. It is closely related to the traditional NLP methodandfeatureengineering,withstronggeneralization ability but relatively weak accuracy. The combination of these techniques is used in [9]. The key entities and relationshipsarederivedfromtheuser’snatural language questions, which are categorised and evaluated. Finally, Cypherlanguageisbuilttoquerytheknowledgegraph via intentionprediction.Itusedquestionandanswermatching technology to calculate the semantic similarity score betweentheoriginalproblemandeachcandidatesolution, choosethebestanswerbasedonthehighestscore,andthen returntheuser’sresponsedirectly.Experimentalresultsof [9] shows that Question-Answer pairing achieves higher accuracythansimpleKGretrieval.
[12] introduces a graph-based QA system for reading comprehension tests that pick out the sentence in the passagethatbestanswersagivenquestionbyextractingthe relations. The proposed system consists of three main modules –Document Processing, Query Processing and Answer Extraction. In the Answer Extraction module, comparison between generated graph from Document
processing and query triplets obtained from Query processing is done to determine a set of matching subgraphs. A morphological analysis which includes a tense variantcheckfortheverbiscarriedoutifnomatchoccurs inthecomparisonstepwhichimprovestheaccuracyofthe model.modelachieveaccuracyof79.67%
Thechallengesinknowledgegraphconstructionare:
1)informationloss
2)informationredundancy
3)informationoverlapping.
4)
Informationlossoccurswheninformationextractionispoor, resulting in an incomplete output graph. Information redundancyreferstotherepetitionofthesameentitywith different abbreviations or prepositions, as well as extra conceptsandrelationsthatdonotexistintheinputtextbut do exist in the background knowledge. The information overlappingchallengereferstowhetheraknowledgegraph can encode the changing of an attribute. Too much knowledgeincorporationfromLMsmaydivertthesentence fromitscorrectmeaning, whichiscalledknowledgenoise (KN)issue.
Severalapproachesonwhichthesesystemsarebased,the bestknownofwhicharebasedonInformationExtraction usingNamedEntityRecognitionapproachesforknowledge graph construction and Traditional query processing and pattern matching approaches for Question-answering systems. The hybrid approach is an alternative trying to merge the advantages of these methods to fill the weak points.
Wehavedividedtheresearchworkbroadlyincertain phases.Allthephasesarediscussedseparatelyinthis paper.
The Knowledge Graph and Question-Answering System constructedinthispaperisbasedontheAnnualReportsof certainCompaniessuchasApple,Facebook,ACCandRIL,etc whichdiscussesvariousfinancialstatements,listedcompany executiveinformation,news,announcementsandresearch reports.Inthisresearchweareconsideringonlytextualdata for KG Construction. These Reports are generally in unstructuredformat,PDFformatsandalsoconsistofvarious graphics,charts,images,tablesandtextdatawhichareina
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
highlyunstructuredformat;makingitdifficultforextraction ofdatafromPDFreports.
Tohandlethis,weextracttherequiredtextualdatafor KGconstructionintoasingletextfileforallcompanies.
For the Data extraction, we use Layoutparser which performsDocumentImageAnalysiswiththehelpofstate-ofthe-art detectron2 deep learning model which enables identifyandextractcomplicateddocumentstructures.
A custom dataset is being created and annotated using labelImgtoolbygivingannotationsforportionsofdocument
to be extracted and fine tuned the pre-trained faster rcnn detectron2modelonourcustomdatasetandannotations. Finally, with the use of Fine Tuned model, Inferences are made and extracted outputs are saved in a single text file whichwillactasaninputdatafortheconstructionofKGand QASystem.
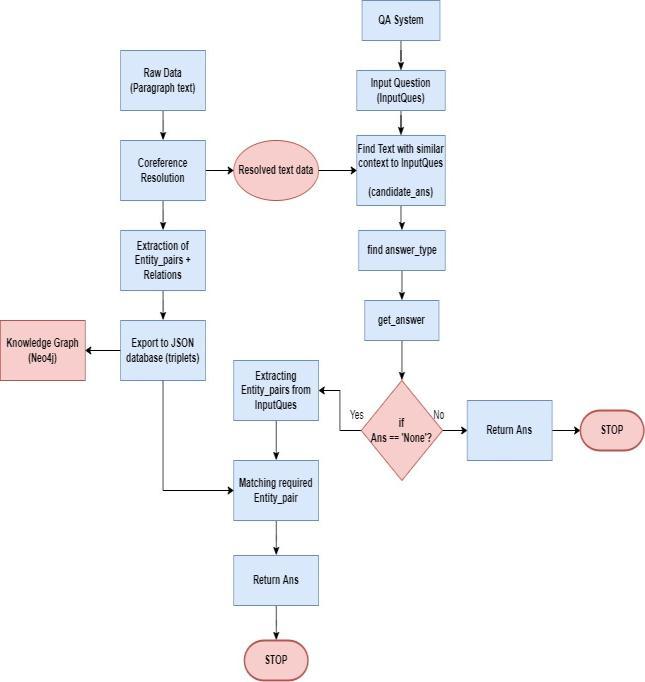
TheproposedSystemarchitecture,whichpresentshowthe userqueriesareprocessedandhowthesystemwillgenerate theresults,isshowninFig.1.
Fig.2.NeuralCorefidentifiesthecoreferencesforanentity TheACCCompany intheaboveexampleandresolvesthem byreplacingwithanentityname.
To connect the primary entities with the prepositional occurrences of those entities in the text, coreference resolutionisused.Withthisprocesspronounsgetreplaced withpropernounstherebygeneratingmoreinterpretable graphs.Additionally,itisemployedwhenaknowledgebase objectisconnectedtoseveralentityreferences.Forinstance, since ”President Modi” and ”Narendra Modi” relate to the sameperson,theyshouldbecombinedbeforebeinglinked toanentityintheknowledgebase.CoreferenceResolutionis alsoaheavyNLPtask.WehaveusedNeuralCoref;apipeline extension for spaCy 2.1+ which annotates and resolves coreferenceclustersusinganeuralnetwork.Itisintegrated inspaCy’sNLPpipeline.NeuralCorefhasbeenprovedtobe bothmoreefficientandaccurateforcoreferenceresolution tasks.ExampleofworkingofNeuralCorefpipelineisshown inFig.2.

The second phase in creating a knowledge graph is information extraction. The main challenge is identifying candidateknowledgeunitsbyautonomouslyextractingdata from data sources. Information extraction is challenging since natural language processing (NLP) technology is typically required when working with semi-structured or unstructureddata.EntityandRelationExtractionareamong theimportanttechnologies.
Thepurposeof entity extraction, sometimes referred to as named entity recognition (NER), is to create ”nodes” inknowledgegraphs.Anessentialcomponentofinformation extraction,entityextractionhasasignificantimpactonthe effectiveness and calibre of later knowledge acquisition. Entityclass which includes names of people, places, and insti-tutions timeclass whichincludesdatesandtimes and number class which includes terms like money and percent- age are the three basic classes. It is possible to expand these classes to accommodate various application areas.Inthisstep,weextractthepairsofentitieswhichare
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
related to each other from each sentence of the data. We employed the NLP library SpaCy, in order to categorise wordswiththeirappropriatepart-of-speech(POS)tagsand chunked noun and verb phrases extracted in accordance withspecifiedrules,whichareabletoconsideralldependent nounandverbsinasentencewiththehelpofdependency parserofferedbyspaCy.Averbchunkisdefinedastheverb andanyaccompanyingadpositionsorparticles,whereasa nounchunkisdefinedasthewordscharacterisingthenoun.
Afterobtainingtheentitiesi.e.nodesinagraphusing entity-pairextraction,theprocessthenmovesontorelation extractionforedgeconstruction.Extractingtherelationship
i.e. edge between entities is required to gain semantic information. In order to map pairings of entities, we first extracted relation terms from sentences, such as verbs, prepositions, and postpositions. We then combined each relation phrase with its source and target entities to generatetriplets.ExtractedtripletsbyusingSpaCyandaset oflinguisticrulesbasedonsubjects,objects,predicates,and prepositions so that it can work on domain independent data.Alongwithnormaltripletstructurei.e.<ent1,relation, ent2>;wehaveadditionallyextractedauxiliaryrelation,time and place such as <source, relation, aux rel, target, time , place>makingitbetterforfurtherQASystem.
Webuildknowledgegraphsusingabottom-upstrategy,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
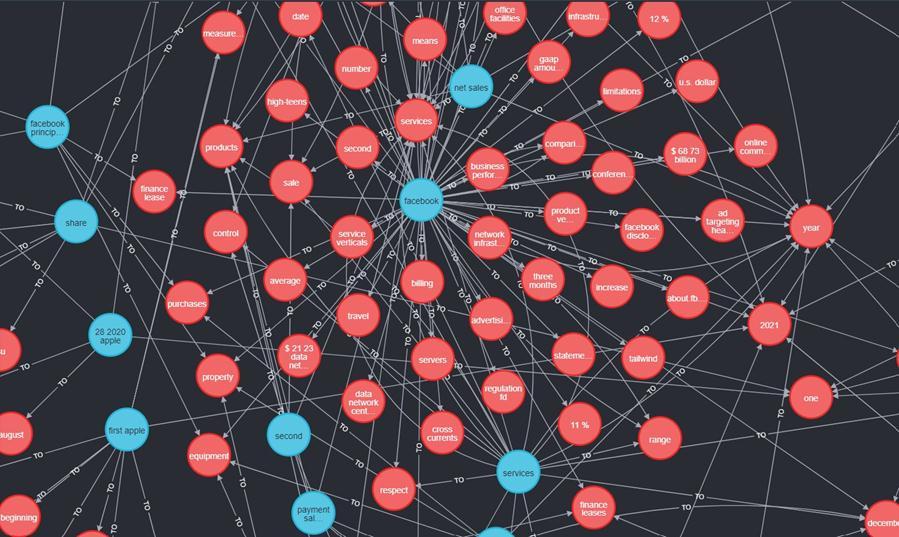
where entities and relationships are first pulled from the dataandtheuppermodellayerisgeneratedviadatadriving. After entities are recorded in triple form, the knowledge graphcanthenbevisualizedusingtheNeo4Jgraphdatabase. First,weencodethetripletsthatwererecordedintoaCSV file using UTF-8, and then we used the Cypher import commandLOADCSVtoputthetriplets’dataintheCSVfilein accordancewiththetriplet”ENTITY [r:RELATIONSHIP]-> ENTITY”inthegraphdatabase.FortheVisualizationofaKG forAnnualreportsfollowingCypherqueryisprocessed:
”’
LOAD CSV WITH headers from ”file:///Triplets Database.csv”asrowwithrowwhererow.sourceisnotnull merge (n:Source {id:row.source}) merge (m:Target {id:row.target}) merge (n)-[:TO{rel:row.relation}]- (m) return* ”’
Astheinputtripletdataislarge,thegeneratedKGis huge Here,Neo4jcomesasthebestsolutionasitallows userstotraverseandnavigatethroughtheentireKGand visualizeandinterpretvariouspropertiesandattributes ofnodesandedgesbyhoveringoverthem.Visualization resultsforKGforAnnualreportsareshowninFig.3
WecanVisualizetripletsonlyforthespecifiedrelation,for exampletovisualizetripletsonlyforrelation’excelled’using followingquery:
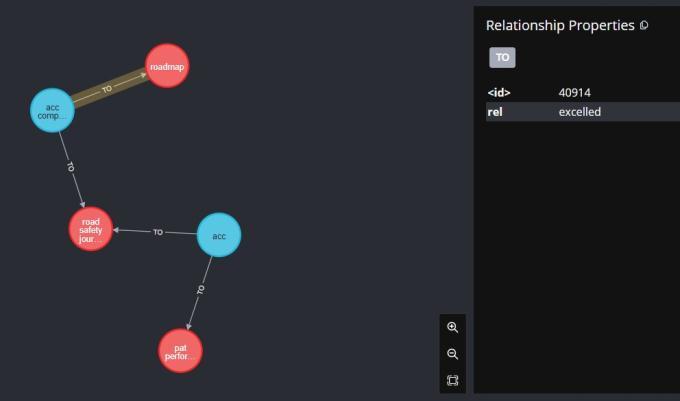
”’match(n)-[:TO{rel:’excelled’}]->(m)return*”’
Results of above query can be seen in Fig. 4. Also by hovering over the edges and nodes we can display and interprettheirattributesandproperties.
databasestoobtainthesolutions.Theprimaryentitiesand relationshipsaredeterminedbyanalysingtheuser’snatural language queries. Unlike other generalized QA systems which usually works only for processing Factoid-type Questions(‘Wh’typeobjectivequestions),TheproposedQA SystemcanworkforFactoidtypeaswellasDescriptivetype ofQuestionssuchasquestionsthatstartwiththekeywords of“why”and“how”.
1)QueryAnalysisandProcessing:Inrelationtothe
context of the query, the similarity computation is performedtoidentifycomparablesentencesfromdata. In this paper, the Cosine similarity discrimination method is adopted.Therecognitionentityandcandidateentitymustbe transformed into corresponding word vectors in order to assesshowsimilartheyaretooneanother.Cosinesimilarity is calculated by the angle between two vectors, given as follows:-
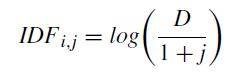
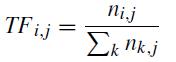
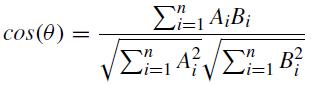
Twowords’vectordirectionsarenearlyidenticaliftheyare synonyms. Their vector directions are essentially the oppositeiftheyareantonyms.Asaresult,thecriteriaarethe sameifthetwowords’semanticsaremoresimilarandtheir vectordirectionsfrequentlycoincide.
TermFrequency-InverseDocumentFrequencyisreferred toasTF-IDF.AnumericalstatisticcalledtheTF-IDFratesthe significanceofeachwordinadocument.Tocounttheword occurrence in each document, we use TfidfVectorizer functions that are provided by Scikit-Learn library. Term Frequency: Number of times a word appears in a text document.Itsformulaisasfollows:-
Inverse Document Frequency: Measure the word is a rare wordorcommonwordinadocument.
Thequestion-answeringsystemsuggestedinthispaper is built using a combination of two approaches: semantic parsing,whichinvolvessomelinguisticsandtraditionalNLP methods, requires rules; and another is extracting the featureinformationofpertinententitiesinthequestionand finding matching triplets for the query from knowledge
Finally,multiplyingthemcanobtainTF-IDFvalues,
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
Usingthecosinesimilarity,theindexesoftextwithsimilar contextasthatofquestionarereturnedwhichgivesthe sentences which are supposed to be candidate answers. Once the candidate answers are obtained, the Query processingiscarriedout.
IntheQueryProcessingpart,InputQueryisprocessedto findouttheexpectedanswertypeaccordingtothequestion usingPOStagsandNERtagsofthequestionsentence.With thehelpofvariouslinguisticsbaseddesignrules,thetaskof determining required entity type is carried out such as in shortway,followingdescribesthedesignrulesforfinding answertypeforrequiredsolution:
“WHO”:“PERSON”or“ORG”
“WHEN”:“TIME”
“WHERE”:“GPE”
“HOWMUCH”:“MONEY”
“HOWMANY”:“QUANTITY”
“HOW”:“DESCRIPTION”
“WHAT”:“DESCRIPTION”
“WHY”:“DESCRIPTION”
2)AnswerMatching:Oncetheanswertypeisestimated, forAnswerExtraction,thecorrespondingequivalententities aresearchedfromcandidateanswersand returnedasthe final solution to the query. In case, if the system cannot identify the correct candidate answer and hence fails to extracttherequiredentities,thenSystemwillmoveforward toknowledgedatabaseretrieval.IntheKnowledgedatabase retrieval method, first the triplets are extracted from a question which defines what information the user is demanding.Thentheanswerisextractedbytripletmatching wherethequestiontripletistraversedandmatchedoverthe triplets database. For Descriptive Kind of questions, the candidate answer found with usage of cosine similarity featureisreturnedasthesolutionbysystem.
We implemented the Knowledge Graph and Question answering System for the Annual Financial Reports of various organizations, such as Facebook, Apple, RIL, and ACC,etc.WehaveconstructedasingleKnowledgegraphfor textualdatacomprisingdatafromallcompany’sReports.In the Knowledge graph Construction Process, the proposed systemisabletoidentifyandextractatotal77,575triplets comprising entity-pairs and relations. With the use of spaCy’sDependencyParser,itachievedtheextractionofall possibleentity-pairsandrelationsbetweentheminabetter
way for the complex grammar structured data of Annual reports.Fig. 3.Showsthe KnowledgeGraphgenerated for AnnualFinancialreportsofCompanies.
IntheactualuseoftheQAsystem,thecombinationof informationretrievalfromdocumentandKnowledgegraph basedQuestion-Answertripletmatchingisused.Withthe useofthesecombinedapproach,ProposedQAachievesthe functionalitytoworkforbothFactoidaswellasDescriptive type of questions. User queries’ results are relatively accurate due to high quality data and strong Knowledge fusion(Coreferenceresolution)steps.Currently,accuracyis usedas the basisforthe performance testof the question answeringsystem.Theaccuracyincreaseswiththenumber of correct questions the question-answering system answers.TohandleQAsystemevaluation’ssubjectivity,test data is collected from users through Google Forms where userswereaskedtoprovidequestionandanswerforgiven paragraph data. For the Annual Financial reports, the proposed system achieved the accuracy of 81.34% by answering327questionscorrectlyoutof402questions.
FortestingtheGeneralizationcapabilityoftheproposed system,performanceofthesystemistestedonother-domain datasuchasAyurvedaandWildlifeManagement.PDFdata for Ayurveda and Wildlife Management is collected from https://www.ayurveda.com/pdf/intro ayurveda.pdf and https://old.mgkvp.ac.in/Uploads/Lectures/49/859.pdf respectively.Ithasbeenobservedthatthesystemisableto identifyandextractallpossibleentity-pairandrelations.For Empiricalverification,Question-Answerdatasetiscollected fromusersforAyurvedaandWildlifemanagementdomain throughtheGoogleForms.Followingtablesummarizesthe results:
Table -1: Results Domain Correctly Answered Questions
Total Questions Accuracy
Ayurveda 128 150 85.33% Wildlife Management 121 150 80.66% Financial Annual Reports 327 402 81.34%
Accuracy of 85.33% and 80.66% is achieved for other domains, Ayurveda and Wildlife Management data respectively.
Forthecomparativeevaluation,wecomparedoursystem with existing system [12], which uses a graph-based approach for answer retrieval for QA system handling readingcomprehensiontestswithaccuracy79.67%.Existing
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
system performs the Document processing and Query Processingparallely.Graphisgeneratedfortripletsobtained fromthedocument,extractsthetripletsfromuserquestions using spaCy and at last answer is extracted by subgraph matching.So,theexistingsystemfailsiftheexactmatching subgraph is not found. Also, it works for Factoid-type questionsonlyandcan’tanswer descriptive questions. To address these issues, the proposed system uses cosine similarityfeaturetofindthecandidateanswersthatmatch the context of questions along with the answer retrieval based on knowledge database triplet matching and addressesdescriptivequestionsaswell.
However, the proposed system fails to answer the analyticalandconfirmation(yes/no)typeofquestions.Fig.5 shows the summary of comparative analysis for graphbased(existing system) and Combination of Knowledge graph QA along with retrieval based on the feature information(proposedsystem).
for the descriptive queries. Also, the system is unable to answerconfirmationandanalyticalquestionscorrectly.In the future work, more advancement can be done to the systemtoprovisionprocessingofvarioustypesofquestions andinferencebasedanswerretrieval.
[1] K.Khadilkar,S.KulkarniandS.Venkatraman,”AKnowledgeGraphBasedApproachforAutomaticSpeechand EssaySummarization,”2019IEEE5thInternationalConferenceforConvergenceinTechnology(I2CT),2019,pp. 1-6, doi: 10.1109/I2CT45611.2019.9033908.
[2] S. Zehra, S. F. M. Mohsin, S. Wasi, S. I. Jami, M. S. Siddiqui and M. K. -U. -R. R. Syed, ”Financial Knowledge Graph Based Financial Report Query System,” in IEEE Access,vol.9,pp.69766-69782,2021,doi:10.1109/ACCESS.2021.3077916.
[3] Z. Dai, X. Wang, P. Ni, Y. Li, G. Li and X. Bai, ”Named Entity Recognition Using BERT BiLSTM CRF for Chinese Electronic Health Records,” 2019 12th InternationalCongressonImageandSignalProcessing, BioMedical Engineering and Informatics (CISP-BMEI), 2019, pp. 1- 5, doi: 10.1109/CISPBMEI48845.2019.8965823
[4] R. Miao, X. Zhang, H. Yan and C. Chen, ”A Dynamic Financial Knowledge Graph Based on Reinforcement Learning and Transfer Learning,” 2019 IEEE International
[5] Liu,W.,Zhou,P.,Zhao,Z.,Wang,Z.,Ju,Q.,Deng,H.,Wang, P. (2019, September 17). K-Bert: Enabling language representationwithknowledgegraph.arXiv.org.
This system establishes a generalized approach for constructingKnowledgeGraphandanautomatedquerying engine to answer user queries for faster and better understandingofhugedata.Thesystemresolvestheissues of ambiguity and semantics of text by Named Entity Recognition using spaCy which has been observed to be successful for extracting entities from complex structured text.Experimentalresultsshowthattheproposedapproach works efficiently for the different domain data. The combined approach, Knowledge graph QA along with retrieval based on the feature information used in the proposedQAsystemwidenssystemscope,asitallowsthe system to process and answer descriptive questions. However,thesystemgeneratesonlyonesentenceanswers
[6] C. Chantrapornchai and A. Tunsakul, ”Information ExtractionbasedonNamedEntityforTourismCorpus,” 201916thInternationalJointConferenceonComputer Science and Software Engineering (JCSSE), 2019, pp. 187-192,doi:10.1109/JCSSE.2019.8864166.
[7] X.Wu,J.Wu,X.Fu,J.Li,P.ZhouandX.Jiang,”Automatic KnowledgeGraphConstruction:AReportonthe2019 ICDM/ICBK Contest,” 2019 IEEE International Conference on Data Mining (ICDM), 2019, pp. 15401545,doi:10.1109/ICDM.2019.00204.
[8] H.Jiang,B.Yang,L.JinandH.Wang,”ABERT-Bi-LSTMBasedKnowledgeGraphQuestionAnsweringMethod,” 2021 International Conference on Communications, InformationSystemandComputerEngineering(CISCE), 2021, pp. 308-312, doi: 10.1109/CISCE52179.2021.9445907
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
[9] Z. Jiang, C. Chi and Y. Zhan, ”Research on Medical Question Answering System Based on Knowledge Graph,”inIEEEAccess,vol.9,pp.21094-21101,2021, doi:10.1109/ACCESS.2021.3055371.
[10] Z. Chen, S. Yin and X. Zhu, ”Research and ImplementationofQASystemBasedontheKnowledge Graph of Chinese Classic Poetry,” 2020 IEEE 5th InternationalConferenceonCloudComputingandBig Data Analytics (ICCCBDA), 2020, pp. 495-499, doi: 10.1109/ICCCBDA49378.2020.9095587.
[11] Yasunaga,M.(2021,April13).QA-GNN:Reasoningwith Language Models and Knowledge Graphs for. . . ArXiv.Org.https://arxiv.org/abs/2104.06378
[12] G.Veena,S.Athulya,S.ShajiandD.Gupta,”Agraphbased relation extraction method for question answering system,”2017InternationalConferenceonAdvancesin Computing,CommunicationsandInformatics(ICACCI), 2017,pp.944-949,doi:10.1109/ICACCI.2017.8125963.
[13] Ostendorff, M. (2019, September 18). Enriching BERT with Knowledge Graph Embeddings for Document Classification. ArXiv.Org. https://arxiv.org/abs/1909.08402
[14] K. Guo, T. Jiang and H. Zhang, ”Knowledge Graph Enhanced Event Extraction in Financial Documents,” 2020 IEEE International Conference on Big Data (Big Data), 2020, pp. 1322-1329, doi: 10.1109/BigData50022.2020.9378471
[15] Hsu,C.(2019,December3).Knowledge-EnrichedVisual Storytelling. ArXiv.Org. https://arxiv.org/abs/1912.01496
[16] X. Yang et al., ”A General Solution and Practice for AutomaticallyConstructingDomainKnowledgeGraph,”
2020IEEE6th International Conferenceon Computer andCommunications(ICCC),2020,pp.1675-1681,doi: 10.1109/ICCC51575.2020.9344946.