International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056

Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
M.Tech. Student Dept. Of Electronics and Telecommunication Engineering, TPCT’s college of engineering, Osmanabad, Maharashtra, India ***
Abstract - Analysis Modification Synthesis (AMS) plays a key role in many audio signal processing applications, separating the audio stream into time intervals with speech activity and time intervals without speech. Manyfeatures have been introduced into the literature that reflect the existence of language. Therefore, this article presents a structured overview of several established speech enhancement features targeting different characteristics of speech. Categorize features in terms of their exploitable properties. B. Evaluate performance in a background noise environment, different input SNR categories, and some dedicated functions. Our analysis shows how to select promising VAD features and find reasonable tradeoffs between performance andcomplexity. To estimate clean speech usingthe Fast Fourier Transform(FFT), we emphasize the noise spectrum estimated during speech, subtract it from the noisy speech spectrum, and consider the average amplitude of the clean spectrum. and tried to develop a new method to minimize the spectrum of loud sounds. The noise reduction algorithm uses MATLAB software to semiduplicate the noisy speech data (overlap-add processing) and use FFT to calculate the corresponding amplitude spectrum to remove noise from the noisy speech. and performed by reversing the audio in time. Reconstructed with the Inverse Fast Fourier Transform (IFFT).
Key Words : Analysis Modification Synthesis (AMS), Inverse Fast Fourier Transform (IFFT), Fast Fourier Transform (FFT) etc.
Animportantgoal ofspeechcommunicationsystemsis to transmit speech signals in a way that is correctly understoodbytherecipient.Examplescanbefoundinthe fieldoftelephonyandpublicaddresssystems.Unfortunately, speech intelligibility can be affected by background noise. For example, poor speech intelligibility can be disruptive duringatelephoneconversation,butpotentiallydangerous in the context of a toll collection system voice alarm. as shown. At 1, background noise from either side of the communicationchannelcanimpairspeechintelligibilityfor near-endlisteners.Inotherwords,noisecancomefromboth the far end and the near end. To eliminate the negative effects of far-end noise, we usually apply single-channel noise reduction algorithms (see [1] for an overview).
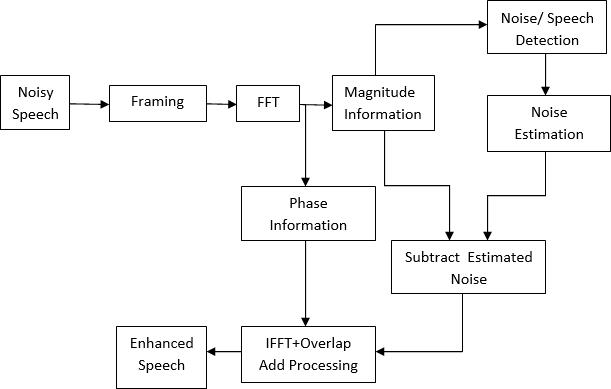
However, speechcanalsobepreprocessedbeforeplayback to make it more audible in the presence of near-end backgroundnoise,whichisthefocusofthiswork.Thereare manywaystobreakfreefromringingsignals.Telephones areincreasingly usedinnoisyenvironmentssuchascars, airports,streets,trainsandstations.Nowlet'spullbackthe noiseusingthespectralminimizationmethod.Thepurpose ofthisworkistobuildareal-timesystemthatcanreducethe backgroundcausedbyaudiosignals.Thisprocessiscalled speech enhancement. In many language systems, the background lowers the language standard. It is usually difficult to remove noise without distorting the audio. Therefore,theperformanceofspeechenhancementdevices is limited between speech distortion and noise reduction. fromtheloudsoundspectrum.Inthismethod,thefollowing heassumesthreesituations.Channelsareonthemarketin whichthesoundaddstotheaudiosignalandthesoundis uncorrelated.Duringthiswork,weusedspectralsubtraction techniquestotrytoreducenoisespectrumestimationerrors andimprovecorruptedspeech.Weproposedamethodthat was tested on a real language data framework in the MATLABenvironment.Realspeechsignalsfromthespeech datadatabasewereusedforvariousexperiments.Wethen proposea techniqueto reducethedifferencebetweenthe estimated noise spectrum and the noise spectrum. In general,wefindthatsystemswithonlyonemediumperform under the most difficult conditions in response to varying audio data and unwanted noise, where advanced noise intelligence is not available. Usually, when the speech is polite, men consider the noise to be steady. They usually tolerate non-stationary noise during periods of speech activity, but in practice the power of speech signals decreasesdramaticallywhenthenoiseisnon-stationary.
Beforeyoustartformattingyourwork,firstwriteandsave the content as a separate text file. Please complete all content and organization edits before formatting. See SectionsA-Dbelowforadditionalproofreading,spelling,and grammarinformation.
Keep textandgraphicfilesseparateuntilyouhavefinished formatting and styling the text. Do not use hard tabs and limittheuseofhardlinebreakstothesinglelinebreakatthe endofaparagraph.Donotadd paginationanywhereonthe
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
paper. Do not number text headers. The template will numberthemforyou.
Manyadditionalmodificationsofvariousconclusionswere invented to improve the language. The single we use is consideredtheconclusionofphantomsubtraction.Thisguy works withintheEpidemic BureauandtrustsPhantom of Aid to be mentioned when Sound Phantom and Noise Phantomareadded.Theactionisshownintheimagebelow andintwomainpartsIthasbeenconstructed.
Aminimumstatisticalnoiseestimateisusedtoestimatethe backgroundnoise.
where*meanstheconvolutionprocessandisthebiasvalue
Backgroundspectrumestimation.Subtractnoisespectrum from noisyspeech
ConsideranadditivenoisescenariolikeEquation(1).One equationinarow.
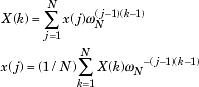
x(n) =s(n) +N(n) (1)
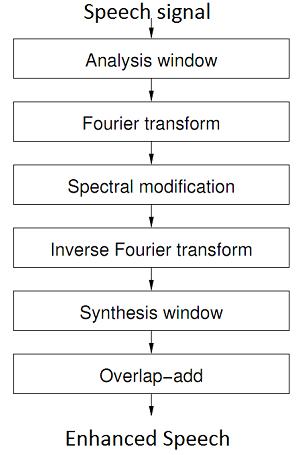
wherex(n),s(n),andN(n)arewindowedsamplesofnoisy speech, clean speech, and spurious noise, respectively. n Discretetimeindex.Sincespeechsignalsareinherentlynonstationary,speechin AMSframesisprocessedover short framedurationsusingshort-termFouriertransforms.From theSTFTdefinition,thespectrumofnoisedegradesspeech.
Notall spectralmagnitudevaluesappeartobepositiveafter subtraction. There are several ways to remove unwanted components.AninverseFouriertransformusingthephase componentsdirectlyfromtheFouriertransformunitandan overlap-addarethenperformedtoreconstructthespeech estimate in the time domain. The basic concept is to minimizethenoiseoftheinputnoisesignal.
Figure1showstheconventionalspectralsubtractionusing theoverlapaddmethod.
The AMS method [6], shown in Figure 1, is an efficient method of signal amplification. AMS uses the following procedure: We first frame the input audio signal using a suitable window function, then perform his STFT of the windowedframesusingsomeframeshifts.Thethirdisthe inverse Fourier transform, and the fourth is signal acquisitionbytheoverlap-and-addition(OLA)method[7].
(2),(3)
Unfortunately, we don't know the exact level of the noise signal,sowereducetheamplitudeandleavethelevelofX unchanged. After subtraction, the spectral magnitude is definitelynotpositive.Thereareseveralwaystoremovethe negativecomponentpresentinthespectrum.Toconvertthe frequency-domain signal to the time-domain signal, the phase of the noisy speech signal is combined with the processed amplitude spectrum and an inverse discrete Fouriertransform(IDFT)isinitiated.timedomain.
InputSNR(dB)
Noisy s 0dB 5dB 10dB 15dB LLR=0.624 LLR=0.543 LLR=0.497 LLR=0.4542
Ses01M_sc ript01 SNRseg=-1028139 SNRseg=1.450995 SNRseg=2.853354 SNRseg=3.937311 WSS=9223PESQ=1.98 WSS=8182PESQ=2.18 WSS=7746PESQ=2.29 WSS=74119PESQ=2.40
Table 1. shows composite objective measure (COM) at different input SNR (dB) using di erent noise estimation techniquesforNOIZEUSutterances
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
Figure. 2. shows the generalised Short Time Fourier Transformincorporatingspectralsubtraction
comparedthespectralbehaviorofrepresentativefeatures from time-frequency spectrogram analysis. Capturing an enhanced audio signal compared to a noisy spectrum at variousinputSNRssuchas0dB,5dB,10dB,15dBwithout exploitingthetemporalcontextoftheaudioinformationwas observed.
Spectrograms,inparticular,havedifferentcolors.Herered and yellow indicate two different intensity phases. The entire loud audio input signal is full of extreme intensity colors because yellow is loud, red is high in the center intensity, and black is a weak crowd with little intensity. Especiallyduringquiettimesoftheresultingaudiosignal, thenoiseresult canbemore.
Input SNR (dB)
Fig. 2. Conventional Spectral Subtraction
Fig. 3. Short Time Fourier Transform of speech Enhancement incorporating Overlap-Add Processing
Therearemanypublicorcommerciallyavailablespeechand noise databases for evaluating speech enhancement algorithms. In this work, we used the language corpus database NOIZEUS [7] for our experiments. The basic premiseofdatabaseslikeNOIZEUSistoprovideresearchers withmorerealistic noiserecordingsatvariousinputSNRs. Thespeechcorpusconsistsof30phoneticallybalancedher IEEE sentences from 6 speakers (3 male, 3 female). The experimentsusedcorpusnoisestimuliconstructedbyrealtime noise environments at different input SNRs, such as airport, chatter, car, restaurant, station, and train background noise. Thirty sets of mean values for the NOIZEUS corpus were calculated for each treatment type, noise type,andinput SNR.C.Complexobjective measures SpeechqualityisalsoassessedbytheCompositeObjective Scale (COM). Several objective measures of composite quality arederivedfrommultipleregressionanalysis. We
Noisy s 0dB 5dB 10dB 15dB Csig=2.816 Csig=3.113 Csig=3.270 Csig=3.4063 Cbak=1.87 Cbak=2.19 Cbak=2.37 Cbak=2.510 Covl=2.224 Covl=2.499 Covl=2.647 Covl=2.7754 loss=0.8467 loss=0.8073 loss=0.7759 loss=0.75763
Table 2 shows PESQ scores for proposed speech enhancementtechniqueatdifferentinputSNR(dB)usingdi erentnoiseestimationtechniquesforNOIZEUSutterances
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
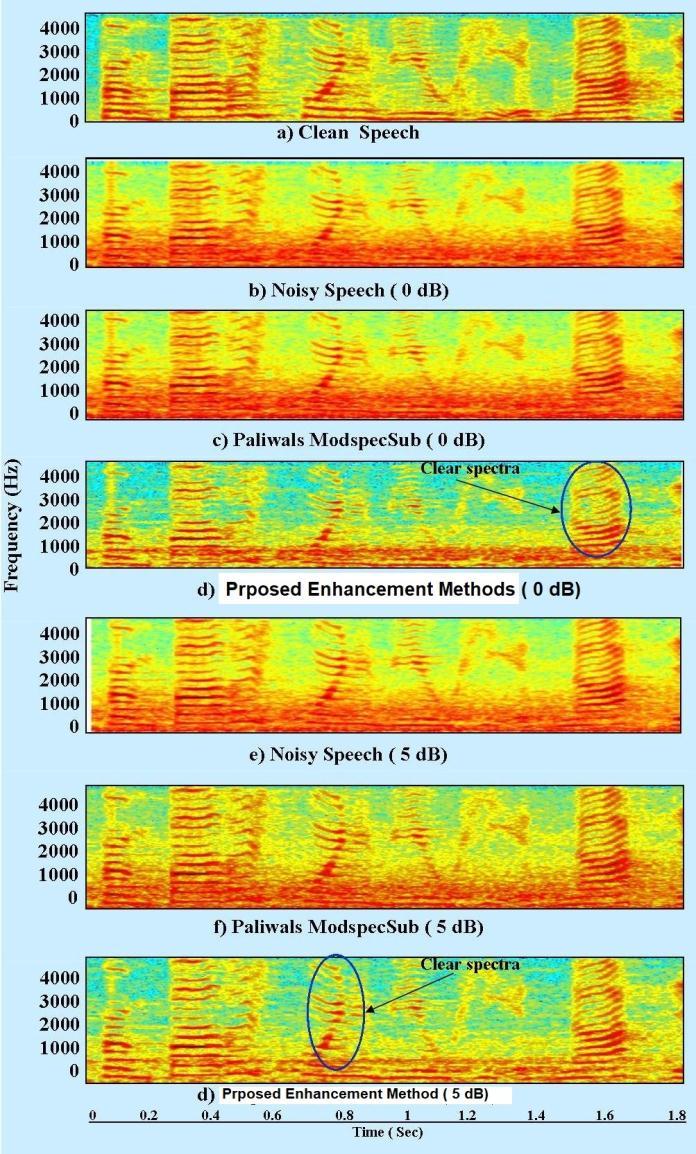
We compared the spectral behavior of representative features from time-frequency spectrogram analysis. Capturing an enhanced audio signal compared to a noisy spectrum at various input SNRs such as 0dB, 5dB, 10dB, 15dBwithoutexploitingthetemporalcontextoftheaudio information was observed. To illustrate the proposed performance, consider the spectrogram plot in Figure 5. Spectrogramsareshownforcleanspeech(5.5a)andnoisy speech (5.5b, 5.5e) with input SNRs of 0 dB and 5 dB, respectively. Figure 5.5b shows that the low frequencies, wheremostoftheaudioenergyresides,arecorrectedmore than the high frequencies. For speech stimuli constructed withtheproposedmethod(5.5d),asignificantreductionin noise isobservedatcertain lowfrequenciescompared to theMod-SpecSubmethod(5.5c).
Fig. 5. Spectrogram analysis of speech signal at 0db input SNR noise: a) clean b) noisy signal 0dB c) Paliwals Modspecsub 0dB d) proposed enhancement method 0dB e) noisy signal 5dB f) Paliwals Modspecsub 5dB g) proposed enhancement method 5dB
Inthisarticle,we summarizedandanalyzedseveralspectral subtractionfunctionsusingdifferentnoisyenvironments.We have outlined established approaches for the purpose of classifying features according to the language extension propertiesused.Ouranalysisshowedthatperformancewas takenintoconsideration.Weidentifiedobjectiveevaluations such as the Perceived Speech Quality Score (PESQ), Csig, Cbak,overallsignalqualityCovlandlossofsignalcontextas important aspects for improving speech enhancement performance..
[1] S. Kamath, and P. Loizou, A multi-band spectral subtractionmethodforenhancingspeechcorruptedby colorednoise,ProceedingsofICASSP-2002,Orlando,FL, May2002.R.Nicole,“Titleofpaperwithonlyfirstword capitalized,”J.NameStand.Abbrev.,inpress.
[2] S.F.Boll,Suppressionofacousticnoiseinspeechusing spectral subtraction, IEEE Trans. on Acoust. Speech & SignalProcessing,Vol.ASSP-27,April1979,113-120.
[3] M.Berouti,R.Schwartz,andJ.Makhoul,Enhancementof speechcorruptedbyacousticnoise,Proc.IEEEICASSP, WashingtonDC,April1979,208-211.
[4] H.Sameti,H.Sheikhzadeh,LiDeng,R.L.Brennan,HMMBased Strategies for Improvement of Speech Signals EmbeddedinNon-stationaryNoise,IEEETransactions on Speech and Audio Processing, Vol. 6, No. 5, September 1998. International Research Journal of EngineeringandTechnology(IRJET)e-ISSN:2395-0056 Volume:04Issue:03|Mar-2017www.irjet.netp-ISSN: 2395-0072
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN: 2395-0072
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008CertifiedJournal|Page2488
[5] Yasser Ghanbari, Mohammad Reza Karami-Mollaei, Behnam Ameritard “Improved Multi-Band Spectral Subtraction Method For Speech Enhancement” IEEE International Conference On Signal And Image Processing,august2004.
[6] Pinki,SahilGupta“SpeechEnhancementusingSpectral Subtraction-typeAlgorithms”IEEEInternationalJournal ofEngineering,Oct2015.
[7] PLoizou.Noizeus:Anoisyspeechcorpusforevaluation of speech enhancement algorithms.Speech Commun, 49:588{601,2017..
[8] Ganga Prasad, Surendar “A Review of Different Approaches of Spectral Subtraction Algorithms for SpeechEnhancement”CurrentResearchinEngineering, ScienceandTechnology(CREST)Journals,Vol01|Issue 02|April2013|57-64.
[9] LalchhandamiandRajatGupta“DifferentApproachesof SpectralSubtractionMethodforSpeechEnhancement” International Journal of Mathematical Sciences, Technology and Humanities 95 (2013) 1056 – 1062 ISSN22495460.
[10] Ekaterina Verteletskaya, Boris Simak “Enhanced spectral subtraction method for noise reduction with minimal speech distortion” IWSSIP 2010 - 17th InternationalConferenceonSystems,SignalsandImage Processing.
[11] D.Deepa,A.Shanmugam“SpectralSubtractionMethod of Speech Enhancement using Adaptive Estimation of NoisewithPDEmethodasapreprocessingtechnique” ICTACTJournalOfCommunicationTechnology,March 2010,Issue:01.
[12] M.Berouti,R.Schwartz,&J.Makhoul,“Enhancementof SpeechCorruptedbyAcousticNoise,”Proc.ICASSP,pp. 208-211,1979.
[13] Prince Priya Malla, Amrit Mukherjee, Sidheswar Routary, G Palai “Design and analysis of direction of arrival using hybrid expectation-maximization and MUSICforwirelesscommunication”IJLEOInternational JournalforLightandElectronOptics,Vol.170,October 2018.
[14] Pavan Paikrao, Amit Mukherjee, Deepak kumar Jain “Smartemotionrecognitionframework:AsecuredIOVT perspective”,IEEEConsumerElectronicsSociety,March 2021.
[15] Amrit Mukhrerjee, Pratik Goswani, Lixia Yang “DAI based wireless sensor network for multimedia
applications” Multimedia Tools & Applications, May 2021,Vol.80Issue11,p16619-16633.15p.
[16] Sweta Alpana, Sagarika Choudhary, Amrit Mukhrjee, Amlan Datta “Analysis of different error correcting methodsforhighdataratescognitiveradioapplications based on energy detection technique” , Journal of Advanced Research in Dynamic and Control Systems, Volume:9|Issue:4.
© 2022, IRJET | Impact Factor value: 7.529 | ISO 9001:2008 Certified Journal | Page262