International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056

Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072

International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
1Department of Computer Engineering and Information Technology, Veermata Jijabai Technological Institute, Mumbai, India
2 Department of Computer Engineering and Information Technology, Veermata Jijabai Technological Institute, Mumbai, India *** -
Abstract - Multiple Choice Question (MCQ) is a versatile question type where respondents select one correct answer from the other choices. Generation of such MCQs along with different implausible options is tedious and time-consuming work. Existing automated question generation systems reduce manual efforts to some extent as they were at only sentence level information. By looking widespread usage of MCQs from school exams to competitive exams, automated generation of more reliable questions is required. The proposed system generated questions based on an Extractive summary using the BERT model which holds paragraphlevel context. BLEU score is used as an evaluation matrix to demonstrate the quality of model-generated questions across the human generated questions. The achieved BLEU score is 0.66. Though the proposed system focuses on Fill-inthe-blank questions scope can be extended to various different types of objective questions.
Key Words: Bidirectional Encoder Representation from Transformers, Wordnet, Bilingual Evaluation Understudy, Constituent Likelihood Automatic Wordtagging System, Python Keyword Extraction, Recurrent Neural Network, Recall-Oriented Understudy for Gisting Evaluation
In today’s world of online education, Multiple Choice Question (MCQ) tests play an important role. These questions help to assess students’ basic to complex level knowledge.Generationofsuchquestionsonspecifictopics is a time-consuming and hectic task. It received tremendous interest in recent years from both industrial and academic communities. These MCQ evaluation tests are focused on research perusing, have functional significance for understudy situations, and furthermore empower instructors to follow enhancements all through the scholarly year. Question generation task which takes a specific situation and replies as info and produces an inquiry that objectives the offered response. MCQ generator System helps to generate these questions. The existing question generation models mainly rely on recurrentneuralnetworks(RNNs)augmentedbyattention
mechanisms. The inherent sequential nature of RNN models suffers from the problem of handling long sequences.Existingsystemsmainlyuseonlysentence-level information as context. When applied to a paragraph-level context, the existing models show significant performance degradation. The latest development is BERT, which has shown significant performance improvement over various NLP tasks. The power of BERT is able to simplify neural architecturedesignfornaturallanguageprocessingtasks.
Forgeneratingquestionsmanysystemsareimplemented. The vocabulary evaluation question generator system [1] creates questions in six different categories, including definition, synonym, antonym, hypernym, hyponym, and cloze questions. Also makes different decisions and word bank question designs. English nouns, verbs, adjectives, andadverbsarecategorizedintosetsinWordnet,alexical knowledge base (synsets). Synsets from wordnet are extractedinordertobuildthequestions.Thecriterionfor the selection of distractors and the phrasing or presentation of the questions are the two main problems encountered while producing multiple choice questions. Thealgorithmselectsdistractionsthathavethesamepart of speech (POS) and same frequency as the correct response. The Kilgarriff word recurrence data set, which depends on the English Public Corpus, is utilized by this technique to choose distractor words (BNC) [2]. The system randomly selects the distractors from a set of 20 wordsfromthisdatabasethathavethesamePOSandthe same or similar frequency as the right response. The CLAWStaggerappliesPOSlabelstothewordsintheBNC and Word Recurrence data sets. For 75 low-frequency English words, the validity of the machine-generated vocabulary questions was evaluated in comparison to questions created by humans. This study compares students'performanceonquestionscreatedbycomputers and by humans in terms of accuracy and reaction speed. As per trial discoveries, these consequently created questions give a proportion of jargon expertise that is profoundly related with subject execution on questions that were freely evolved by people. As per the resulting
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
study,questioncreationerrandsaredealtwithbythepreprepared BERT language model [3]. The paper presents neuronal architecture created with BERT. The first one is a straightforward BERT employment which reveals the defects of directly using BERT for text generation and anotheris a remedy for the first one by restructuring the model into a sequential manner for taking input from previous results. Utilizing the SQuAD question answering dataset,modelsaretrainedandevaluated[4].TheSQuAD datasetcontains536Wikipediaarticlesandaround100K readingcomprehensionquestions.Twodatasplitsettings used. The first one is SQuAD73K were training (80%), development set (10%), test set (10%) and the second is SQuAD 81K where development data set is divided into developmentset(50%)andtestset(50%).Forevaluation results are compared with RNN models i.e. NQG [5] and PLQG [6] models based on the sentence level and paragraphlevelcontextusingstandardmetricsBLEUand ROUGE-L. Results show that the model improves the BLEU 4 score from 16.85 to 21.04 in comparison with existingsystems.
The goal of this research is to implement a system that automatically generates Multiple choice questions, targetingthebelowobjectives:
• UseofBERTmodelforquestiongeneration.
• Use of Wordnet and Conceptnet as knowledge basesfordistractorgenerationtasks.
• Generation of MCQ by considering the paragraph levelcontext.
BLEUscoreisusedasanevaluationmetricforevaluatinga proposedmodel.
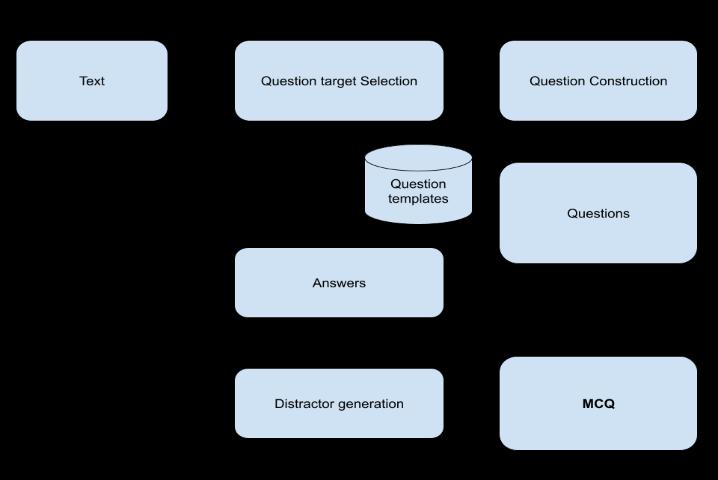
The MCQ generator system takes input as a passage and generatesquestionsbasedonthat.Textpassageisgivenas themaininputtothesystem.From whichstemisselected (Stem means sentence from which question is to be formed).Aquestionanditsanswerareareframedutilizing thisstem.Fordistractors,wordnetandconceptknowledge basesareused.Wordspresentinthesynsetsofthecorrect answer are extracted and used as distractors. The general systemarchitectureisgivenasshowninFig.1.
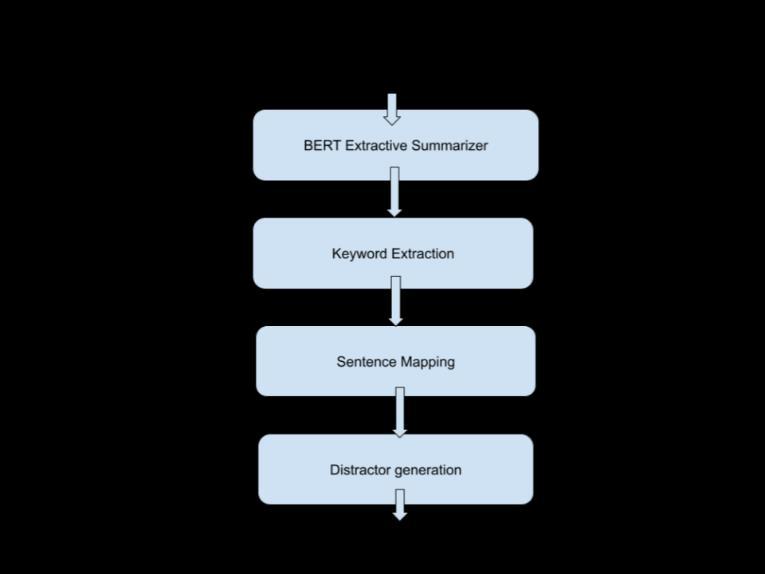
The proposed system generates the Fill-in-the-blank questions which are knowns as cloze questions. A paragraphisprovidedasinputtooursystem,fromwhich we must produce questions. The proposed system architectureisgivenasshowninFig.2.
To achieve our objective to generate questions thatholdparagraph-levelcontextweneedtofirst generate a summary for a given passage. So for this purpose, an extractive summarizer is used. Abstractive and Extractive are two summarization strategies. The abstractive summarization technique closely emulates humansummarization.Extractivesummarization aims at identifying the main information that is
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
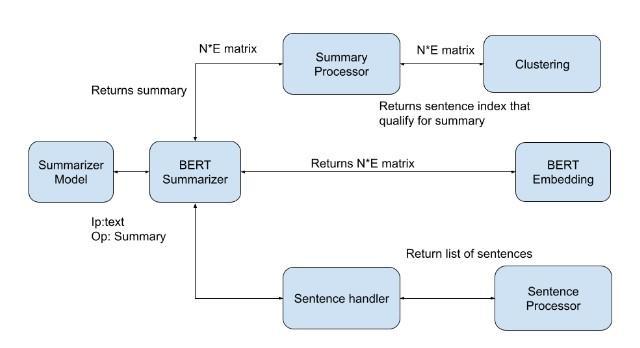
then extracted and grouped together to form a proper summary. The extractive technique selects the top N sentences which represent the main points of the article. The Outline acquired contains accurate sentences from the first message. Different modules in BERT Extractive SummarizerareasshowninFig.3.
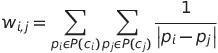
• Extractive text summarization using BERT and kmeans:
For creating summaries from input passages an extractivesummarizerisused.Inputentriesare tokenized into sentences. After tokenization, these sentences are fed to the BERT model for extracting embedding then clustered the embedding with Kmeans. Sentences that are closetocentroidareselectedforasummary.
• BERTfortextembedding:
Duetosuperiorperformanceoverothermodels inNLP,theBERTmodel(BERT-LARGE)isused. Using the default pre-trained BERT model one canselectmultiplelayersforembeddings.BERT model produces N*E matrix where N is No. of sentences in input passage and E is embedding dimension (For BERT-BASE=768 and BERTLARGE=1024)
• Clusteringembeddings:
One generation of the embedding matrix is completedthenitisforwardedtotheclustering module. During experimentation, both k-means andGaussianMixture Modelsare used. But due toverysimilarperformance,Kmeanswasfinally selected for clustering. For the clusters, the sentences which are closest to the centroid wereselectedforafinalsummarygeneration.
In this stage, we extract all the important keywords from the original text. Then we check whether those keywords are present in the summary. Then, at that point, keep just those catchphrases that are available in the summed up text.ForextractingkeywordsweareusingPKEi.e. Python Keyword Extraction Toolkit. PKE is an open-source python-based keyphrase extraction toolkit. In our system Multipartite rank, an unsupervised graph model [8] is used. Inside the settingofamultipartitechartstructure,itencodes effective information. In order to increase candidateranking,themodelcombineskeyphrase candidates and subjects into a single graph and makes use of their mutually reinforcing interaction. The keyphrase candidates are represented by nodes in a fully directed multipartite graph, and only those nodes that belongtoseparatesubjects areconnected. Weight edges as per the distance between two competitors in the record. More formally, the weight wij fromnodeitonodejiscomputedasthe sum of the inverse distances between the occurrencesofcandidatesci andcj:
where P(ci)isthesetofthewordoffsetpositions ofcandidateci
This weighting scheme gives comparable results to window-based co-occurrence counts. The resulting graph is a complete k-partite graph in which nodes are partitioned into k different independentsetswherekrepresentsthenumber oftopics.Afterthechartisbuilt,adiagrambased positioning calculation is utilized to rank keyphrase competitors, and the top N are then pickedaskeyexpressions.
Inthisstageforeachofthekeywords,thesystem will extract corresponding sentences that have the word from the summarized text. This text is called Stem. From this stem, a question is generated.
The system will extract distractors (options for MCQ) from Wordnet and Conceptnet to generate final MCQ Questions. Wordnet is a lexical
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
databaseofsemanticrelationsbetweenwordsin more than 200 languages [9]. It is freely available.Wordnet joins words into semantic relations including equivalents, hyponyms, and meronyms.SynonymsaregroupedintoSynonym Sets (Synsets) with short definitions and usage examples as shown in Fig.4. It is used for Word Sense Disambiguation, Information retrieval, Automatic text classification, and Text summarization. Synsets are interlinked through conceptual relations. For given answer from corresponding synsets synonyms are extracted whichisusedasoptions(i.e.Distractors)forMCQ. Intheextractionofsynsetswordsenseisneeded. To find wordsense Wu Palmer similarity and adapted lesk is used. Wu Similiarity basically calculates relatedness between two synsets considering depth of LCS. And adapted lesk is used to find similarity between context in sentence and its dictionary meaning. At the end lowest index is calculated between Wup similarity index andadaptedlesk output. Lowest index is more closer to its exact meaning. These synonyms are related to the original word so we will get all relevant distractors at the end which holdsimilarsemanticmeanings.
Our proposed system focuses on generating Fill-in-theblank type of questions. For evaluating the questions generated by our proposed system some set of standard questions is needed. But there is no such standard questiondatasetisavailable.Soforthis purpose,wehave to make our own dataset by collecting questions through the survey. We have conducted a survey based on 5 passages from SQuAD (Standford Question answering dataset)dataset.ThissurveywasconductedusingGoogle Forms. This google form was circulated among undergraduateandpostgraduatestudents.
Atotalof50respondentsrespondedtothisform.Statistics ofthissurveyarementionedinTable1.
Fig-4:WordnetSynsetStructure
Table-1:Statisticsofconductedsurveywhichisusedfor makingmanualdataset
SQuAD Psgs (Sents, words) #ques formed by 50 respon -dents
#unique and #repeated ques
#types of ques generated
Chicago (4,115) 156 113,43 6 Kenya (5,112) 153 125,28 8 Oxygen (7,136) 162 129,33 9 Immune (4,101) 152 124,28 4 Construction (4,74) 152 105,47 5
Total ques 775
To achieve the objective of generating the questionswhichholdparagraphcontextsummary isgeneratedontheinputpassage.BERTextractive summarizer is used for generating the summary. Later this summary is compared with the summary generated by another online summarizer to see the efficiency of our summarizer. Results of this comparison are given intheresultssection.
After generating the questions in summary we compared these questions with our dataset which was gathered using a survey. For Quantitative analysis, we found out how many questions were generatedbyourmodelcomparedtohumans.Also
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
individual analysis for coverage of questions on input passage and summary to see whether summarylimitstheno.ofquestions.Differentsize inputssuchassinglepassage,multipassage,multipage, and book are given to the system to find coverage.ForQualitativeanalysis,wecomparethe system generated questions with humangenerated questions gathered through a survey using the BLEU score to see the quality of the questions. Also, we conduct one more survey in which respondents rate each question generated bythesystemonascaleof1-5toseethequalityof the question from the human perspective. This surveywastakenontwosetsofquestionsoneset is questions generated by the system on technical passage and another question on literature passage. These two sets are used to see if the systemisusefulforwhichtypeofpassageandhow many questions are formed. For distractors analysis, we found out coverage on no. of unique distractors generated using Wordnet and Conceptnet for passages which we are using for ouranalysis.
BLEU score stands for Bilingual evaluation understudy. It is a calculation for assessing the nature of text which hasbeenmachine-interpretedstartingwithonenormal language then onto the next. Quality is viewed as the correspondence between a machine's resultand that of a human. BLEU's result is dependably a number somewhere in the range of 0 and 1. This worth shows how comparative the applicant message is to the referencemessages,withvaluesmorelike1addressing more comparative messages. Those scores are then arrived at the midpoint of over the entire corpus to arrive ata gauge of the interpretation'sgeneral quality. BLEUscoreismathematicallydefinedas:
1. Evaluating efficiency of Extractive summarizer Summary generated on input text using extractive summarizer is base for MCQ generation. So this summary is compared with other online summarizers i.e. Sassbook extractive summarizer. Sassbook summarizer is a very popular tool for researchers for generating summaries. ROUGE score is used as an evaluation metric for showing the efficiency of our summarizer. 5 passages are taken from the standard dataset SQuAD and their summary is generated using our extractive summarizer. These generated summaries are compared with online summarizergeneratedsummaries.ROUGEscoreis between 0to 1. Ascorecloserto1meansgeneratedsummaryismore identical to the online summarizer-generated summary. Table 2 shows the comparison between the ROUGEscoreforthesummarygeneratedforoneofthe passages from the SQuAD dataset by our extractive summarizervsanotheronlinesummarizer.
Table-2:Similarnessbetweenourextractivesummarizer andSassbookonlinesummarizer
Score Sassbook Extractive
ROUGE-1 0.807 ROUGE-2 0.774 ROUGE-3 0.789 ROUGE-4 0.789 ROUGE-L 0.804
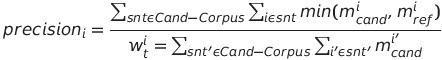
With where
micand is the count i-gram in candidate matching thereferencetranslation
miref is the count of i-gram in the reference translation
wi t is the total number of i-grams in candidate translation
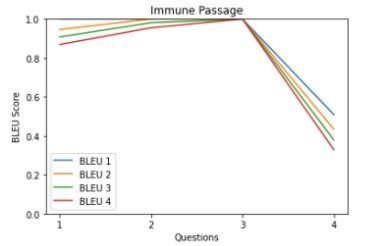
• Qualitative analysis using BLEU score As mentioned in the dataset section, we are using our own dataset for checkingthe qualityofthesystem-generatedMCQ.The own dataset contains questions that are collected from respondents through the survey. Table 3 shows the similarity between the model-generated questions and human-generated questions for 5 passages from the SQuAD dataset. Table 3 values presented in graphical formatinChart1-5.
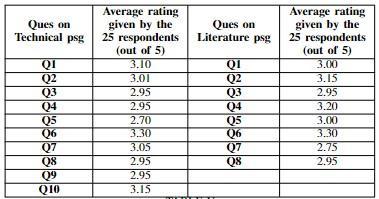
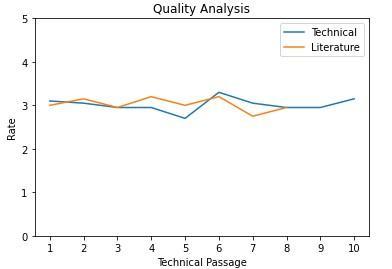
• Qualitative analysis using rating survey In addition to the above experiment, the survey is conducted to rate the questions generated by our system. Respondents are undergraduate and postgraduate students. A total of25responsesaregathered.Table4showstheresults ofthisexperiment.Thiscanbepresentedasagraphas showninChart6.
2022, IRJET | Impact Factor value: 8.529 | ISO 9001:2008 Certified Journal | Page152
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
Table-3:BLEUscoreshowsthesimilaritybetweenmodel generatedquestionswithhuman-generatedquestions
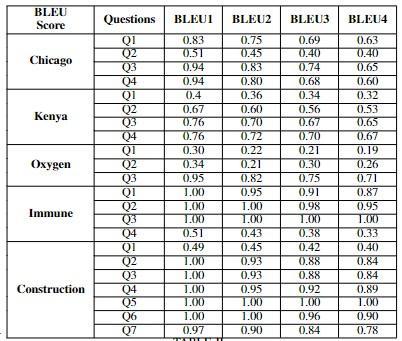
Chart 1-5: Similarity between model-generated questions andhuman-generatedquestions
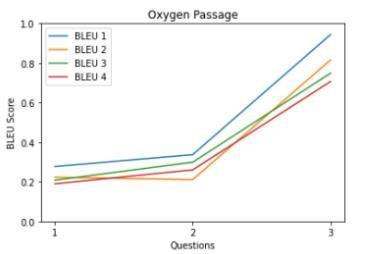
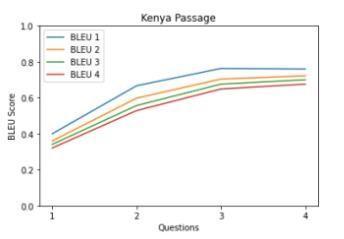
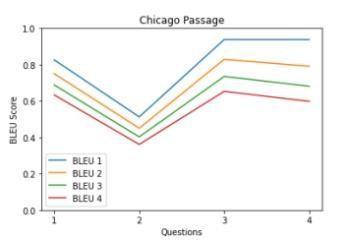
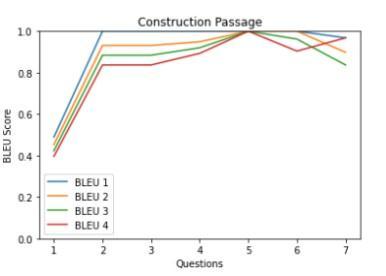
Table-4:Averageratinggiventothemodelgenerated questionsbysurveyrespondents
Chart-6: Average rating given by respondents on model generatedquestions
• Quantitative analysis for coverage of human vs modelgeneratedquestions
As mentioned in the experimental setup, the experimentisconductedtoseethetypesofquestions generatedbyhumansincomparisonwithoursystem. Table5showstheresultsofthisexperiment.
• Quantitative analysis for coverage of the different sizesofinput
As mentioned in the experiments section different sizesofinputaregiventothesystemtoseehowno.of questions depends on input size. Also to see more questions formed on direct input passage than summaryinput. Table 6showssignificant differences between no. of questions formed on summary and directinput.
International Research Journal of Engineering and Technology (IRJET) e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
Table-5:Coverageontypesofquestionhuman-generated vsmodel-generated
Passage #types of ques generated by human
#types of ques generated by model
Chicago 6 4 Kenya 8 4 Oxygen 9 3 Immune 4 4 Construction 5 7
Table-6:Coverageondifferentinputsize
Types of input #ques formed on input #ques formed on summary
Singlepassage 20 8 Multipassage 20 9 Multi-page 20 9 Book 20 12
• Qualityofdistractors
Table 7 shows a number of unique distractors generated using Wordnet and Conceptnet for the questions generatedon5SQuADpassages.
Table-7:Coverageondistractors
Passage #unique distractors generated Chicago 47 Kenya 40 Oxygen 46 Immune 17 Construction 53
According to Table 2, it is observed that the ROUGE score for sassbook extractive is closer to 1 which means sassbook also uses a similar extractive summarizationtechniquei.e.clustering.Itshowsthat our summarizer generates a good summary for the input passage which is used as a base for question generation.Also,anextractivesummarizerisusedfor a wide range of passages. It does not depend on a specific domain like abstractive, because it does not require any type of training on some specific domain dataset.
• QualitativeanalysisusingBLEUscore
From graphs in Table 3, it is observed that most of the questions have a BLEU score greaterthan0.6.TheaverageBLEUscoreover the dataset is 0.66. It means our system generates human-like MCQs by achieving gold standards.
• Qualitativeanalysisusingratingsurvey
The survey is taken among graduate students. The average rating for system-generated questions is Also, this system works fine for both technical and literature-based input passages. Here technical passage is from an online technical blog and the literature passage isfromthenovel.Soweclaimedthatoursystem can generate questions on any type of input from any domain hence it is domainindependent.
• Quantitative analysis for coverage of human vs modelgeneratedquestions
From Table 5 it is observed that for some passageshumangeneratesmorequestions.This is because respondents have generated questions on the overall passage where the system generates the questions on a summary to achieve the objective of holding paragraph context. This result will get more clear in the nextanalysis.
• Quantitative analysis for coverage of the different sizesofinput
FromthevaluesfromTable6,itisobservedthat thesystemalwaysgeneratesmorequestionson input passage compared to summary. In this table,thehighestnumberofquestionsisalways 20becauseintheimplementationofthismodel weareconsideringthetop 20keywordsfrom a passage in the keyword extraction stage. There can be a large number of questions. But in summary,willgetlessnumberofquestionsthan input. Because there is a loss of information while building the summary. This loss of information can be compromised by holding paragraph-levelcontext.
• Qualityofdistractors
From Table 7 it is observed that the system generates a good amount of distractors for comparatively small passages. As the input size grows summary will be more so the number of unique distractors will be formed in large numbers. So our system simplifies the tedious
International Research Journal of Engineering and Technology (IRJET)
e-ISSN:2395-0056
Volume: 09 Issue: 10 | Oct 2022 www.irjet.net p-ISSN:2395-0072
taskofgeneratingoptionsforMCQs.Also,these options are similar in meaning to the original answers which can be used to confuse the one whogavetheexam.
MCQ generator system considers paragraph level context for question generation task which improves performance over existing systems which only consider sentence level context. The implemented system is domain independent which generates questions for any input irrespective of domain, but it limits the number of questions because of the loss of information while generating a summary. A BERT extractive summarizer is used to generate a summary for input passage which is compared with an online summarizer which gives a ROUGE score of around 0.80. Due to the unavailability of standard datasets, we havebuiltourowndatasetbycollectingquestionsthrough a survey. These questions are compared with modelgenerated questions using the BLEU score to see if our systemisreachinggoldstandardsandbuildinghuman-like questions.ThesystemachievedaBLEUscoreof0.66.Inthe future, we'll be able to create various kinds of question types.
[1] J. C. Brown, G. A. Frishkoff, and M. Eskenazi, “Automatic question generation for vocabulary assessment,” in Proceedings of the conference on HumanLanguage TechnologyandEmpirical Methods in Natural Language Processing - HLT ’05, (Vancouver, British Columbia,Canada), pp. 819–826, AssociationforComputationalLinguistics,2005
[2] “Read-meforKilgarriff’sBNCwordfrequencylists.”
[3] Y.-H. Chan and Y.-C. Fan, “BERT for Question Generation,” in Proceedings of the 12th International Conference on Natural Language Generation, (Tokyo, Japan), pp. 173–177, Association for Computational Linguistics,2019.
[4] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ Questions for Machine Comprehen-sionofText,”inProceedingsofthe2016 Conference on Empirical Methods in Natural LanguageProcessing,(Austin,Texas),pp.2383–2392, AssociationforCompu-tationalLinguistics,2016.
[5] X.Du,J.Shao,andC.Cardie,“LearningtoAsk:Neu-ral Question Generation for Reading Comprehension,” in Proceedings of the 55th Annual Meeting of the AssociationforComputational Linguistics(Volume 1: Long Papers), (Vancouver, Canada), pp. 1342–1352, AssociationforComputationalLinguistics,2017.
[6] Y.Zhao,X.Ni,Y.Ding,andQ.Ke,“Paragraph-level NeuralQuestionGenerationwithMaxoutPointerand GatedSelf-attentionNetworks,”inProceedingsofthe 2018 Conference on Empirical Methods in Natural Lan-guageProcessing,(Brussels,Belgium),pp.3901–3910, Association for Computational Linguistics, 2018.
[7] D. Miller, “Leveraging BERT for Extractive Text Summa- rization on Lectures,” June 2019. arXiv:1906.04165 [cs,eess,stat]
[8] Boudin, “Unsupervised Keyphrase Extraction with Mul- tipartite Graphs,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), (New Orleans, Louisiana), pp. 667–672, Association forComputationalLinguistics,2018.
[9] G.A.Miller,“WordNet:alexicaldatabaseforEnglish,” Communications of the ACM, vol. 38, pp. 39–41, Nov.1995.
2022, IRJET | Impact Factor value: 8.529 | ISO 9001:2008 Certified Journal | Page155